TFT时间序列预测
from torch import nn
import math
import torch
import ipdb
class GLU(nn.Module):
#Gated Linear Unit
def __init__(self,input_size):
super(GLU, self).__init__()
self.fc1=nn.Linear(input_size,input_size)
self.fc2=nn.Linear(input_size,input_size)
self.sigmoid=nn.Sigmoid()
def forward(self,x):
sig=self.sigmoid(self.fc1(x))
x=self.fc2(x)
return torch.mul(sig,x)
class TimeDistributed(nn.Module):
## Takes any module and stacks the time dimension with the batch dimenison of inputs before apply the module
## From: https://discuss.pytorch.org/t/any-pytorch-function-can-work-as-keras-timedistributed/1346/4
# 模块化用来改变输入大小,考虑到直接用Linear层对多维数据处理可能出问题,单独处理
def __init__(self, module, batch_first=False):
super(TimeDistributed, self).__init__()
self.module = module
self.batch_first = batch_first
def forward(self, x):
if len(x.size()) <= 2:
return self.module(x)
# Squash samples and timesteps into a single axis
x_reshape = x.contiguous().view(-1, x.size(-1)) # (samples * timesteps, input_size),view变换原矩阵的大小,需要原矩阵的内存是整块的。
# print(x_reshape.device)
y = self.module(x_reshape)
# We have to reshape Y
if self.batch_first:
y = y.contiguous().view(x.size(0), -1, y.size(-1)) # (samples, timesteps, output_size)
else:
y = y.view(-1, x.size(1), y.size(-1)) # (timesteps, samples, output_size)
return y
class GRN(nn.Module):
# GatedResidualNetwork
def __init__(self,input_size,hidden_state_size,output_size,drop_out,hidden_context_size=None,batch_first=False):
super(GRN, self).__init__()
self.input_size=input_size
self.output_size=output_size
self.hidden_context_size=hidden_context_size
self.hidden_state_size=hidden_state_size
self.drop_out=drop_out
if self.input_size!=self.output_size:
self.skip_layer=TimeDistributed(nn.Linear(self.input_size,self.output_size))
self.fc1=TimeDistributed(nn.Linear(self.input_size,self.hidden_state_size),batch_first=batch_first)
self.elu1=nn.ELU()
if self.hidden_context_size is not None:
# 如果c能够传递的话,将c的大小化为和a的大小一致
self.context=TimeDistributed(nn.Linear(self.hidden_context_size,self.hidden_state_size),batch_first=batch_first)
self.fc2=TimeDistributed(nn.Linear(self.hidden_state_size,self.output_size),batch_first=batch_first)
# self.elu2=nn.ELU()#做不做问题不大
self.dropout=nn.Dropout(self.drop_out)
self.ln=TimeDistributed(nn.LayerNorm(self.output_size),batch_first=batch_first)#层归一化归一化最后k个维度
self.gate=TimeDistributed(GLU(self.output_size),batch_first=batch_first)
def forward(self,x,context=None):
if self.input_size!=self.output_size:
residual=self.skip_layer(x)
else:
residual=x
x=self.fc1(x)
if context is not None:
context=self.context(context)
x=x+context
x=self.elu1(x)
x=self.fc2(x)
x=self.dropout(x)
x=self.gate(x)
x=x+residual
x=self.ln(x)
return x
class PositionalEncoder(nn.Module):##仿照transformer层添加位置编码,有点多此一举
def __init__(self,d_model,max_seq_len=160):
super(PositionalEncoder, self).__init__()
self.d_model=d_model#Embedding大小,输入为(seq_len,batch_size,index)-->(seq_len,batch_size,input_size)
pe=torch.zeros(max_seq_len,d_model)
for pos in range(max_seq_len):
for i in range(0,d_model,2):
pe[pos, i] = \
math.sin(pos / (10000 ** ((2 * i) / d_model)))
pe[pos, i + 1] = \
math.cos(pos / (10000 ** ((2 * (i + 1)) / d_model)))
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self,x):
with torch.no_grad():
x=x*math.sqrt(self.d_model)
seq_len=x.size(0)
pe=self.pe[:,:seq_len].view(seq_len,1,self.d_model)
x=x+pe
return x
class VSN(nn.Module):
# Variable Selection Network
def __init__(self,input_size,num_inputs,hidden_size,drop_out,context=None):
super(VSN, self).__init__()
self.hidden_size=hidden_size
self.input_size=input_size
self.num_inputs=num_inputs
self.drop_out=drop_out
self.context=context
#num_inputs*input_size的原因是这里将所有的变量摊平了,原来先将num_inputs中的每个变量都做了embedding
self.flattened_grn=GRN(input_size=self.num_inputs*self.input_size,hidden_state_size=self.hidden_size,output_size=self.num_inputs,drop_out=self.drop_out,hidden_context_size=self.context)
self.single_variable_grns=nn.ModuleList()
for i in range(self.num_inputs):
self.single_variable_grns.append(GRN(self.input_size,self.hidden_size,self.hidden_size,self.drop_out))#为每一个展开变量均添加一个GRN
self.softmax=nn.Softmax()
def forward(self,embedding,context=None):
sparse_weights=self.flattened_grn(embedding,context)#将embedding铺平+grn+softmax cat embedding
sparse_weights=self.softmax(sparse_weights).unsqueeze(2)#强制加入第二个维度,【seq,bs,1,num_inputs]
var_outputs=[]#对每一个emb计算GRN并化为列表
for i in range(self.num_inputs):
# 每个对应的输入维度的embedding分别求GRN,这里embedding后的维度为(seq,bs,input_size*num_inputs)
var_outputs.append(self.single_variable_grns[i](embedding[:,:,(i*self.input_size):(i+1)*self.input_size]))
var_outputs=torch.stack(var_outputs,dim=-1)#在最后一个维度上进行堆叠,结果为[seq,bs,input_size,num_inputs]
# print(var_outputs.shape)
# print(sparse_weights.shape)
'''
ggg
ggg
'''
outputs=var_outputs*sparse_weights
outputs=outputs.sum(axis=-1)
return outputs,sparse_weights
class TFT(nn.Module):
def __init__(self,config):#传入config字典
super(TFT, self).__init__()
self.device=config['device']
self.batch_size=config['batch_size']
self.static_variables=config['static_variables']
self.encode_length=config['encode_length']
self.time_varying_categorical_variables=config['time_varying_categorical_variables']#随时间变化的离散型变量(分类型)
self.time_varying_real_variables_encoder=config['time_varying_real_variables_encoder']#encoder中随时间变化的连续型变量
self.time_varying_real_variables_decoder=config['time_varying_real_variables_decoder']#decoder中随时间变化的连续型变量
self.num_input_series_to_mask=config['num_masked_series']
self.hidden_size=config['lstm_hidden_dimension']
self.lstm_layers=config['lstm_layers']
self.drop_out=config['drop_out']
self.embedding_dim=config['embedding_dim']
self.attn_heads=config['attn_heads']
self.num_quantiles=config['num_quantiles']#分位数的个数
self.valid_quantiles=config['valid_quantiles']#有效分位数
self.seq_length=config['seq_length']
self.static_embedding_layers=nn.ModuleList()#对每一个变量分别做embedding,[bs,1]对应着所有bs的第i个变量
for i in range(self.static_variables):
emb=nn.Embedding(config['static_embedding_vocab_sizes'][i],config['embedding_dim']).to(self.device)#有可能static_embedding_vocab_sizes不为1?
self.static_embedding_layers.append(emb)
self.time_varying_embedding_layers=nn.ModuleList()#随时间变化的变量的编码
for i in range(self.time_varying_categorical_variables):
emb=TimeDistributed(nn.Embedding(config['time_varying_embedding_vocab_sizes'][i],config['embedding_dim']))
self.time_varying_embedding_layers.append(emb)
self.time_varying_linear_layers=nn.ModuleList()
for i in range(self.time_varying_real_variables_encoder):
emb=TimeDistributed(nn.Linear(1,config['embedding_dim']),batch_first=True).to(self.device)
self.time_varying_linear_layers.append(emb)
self.encoder_variable_selection=VSN(config['embedding_dim'],
(config['time_varying_real_variables_encoder']+
config['time_varying_categorical_variables']),
self.hidden_size,
self.drop_out,
config['embedding_dim']*config['static_variables'])
self.decoder_variable_selection = VSN(config['embedding_dim'],
(config['time_varying_real_variables_decoder'] + config['time_varying_categorical_variables']),
self.hidden_size,
self.drop_out,
config['embedding_dim']*config['static_variables'])
self.lstm_encoder_input_size = config['embedding_dim']*(config['time_varying_real_variables_encoder'] +
config['time_varying_categorical_variables'] +
config['static_variables'])#输入lstm的变量应当是三个不同变量分类的和
self.lstm_decoder_input_size = config['embedding_dim']*(config['time_varying_real_variables_decoder'] +
config['time_varying_categorical_variables'] +
config['static_variables'])
self.lstm_encoder=nn.LSTM(input_size=self.hidden_size,hidden_size=self.hidden_size,num_layers=self.lstm_layers
,dropout=self.drop_out)
self.lstm_decoder=nn.LSTM(input_size=self.hidden_size,hidden_size=self.hidden_size,num_layers=self.lstm_layers
,dropout=self.drop_out)
self.post_lstm_gate=TimeDistributed(GLU(self.hidden_size))
self.post_lstm_norm=TimeDistributed(nn.LayerNorm(self.hidden_size))
self.static_enrichment=GRN(self.hidden_size,self.hidden_size,self.hidden_size,self.drop_out,config['embedding_dim']*self.static_variables)#最后一项是static_context_size
self.position_encoding=PositionalEncoder(self.hidden_size,self.seq_length)
self.multihead_attn=nn.MultiheadAttention(self.hidden_size,self.attn_heads)#第二项是头的数量
self.post_attn_gate=TimeDistributed(GLU(self.hidden_size))
self.post_attn_norm=TimeDistributed(nn.LayerNorm(self.hidden_size))
self.pos_wise_ff=GRN(self.hidden_size,self.hidden_size,self.hidden_size,self.drop_out)#Position_wise_Feed_forward
self.pre_output_norm=TimeDistributed(nn.LayerNorm(self.hidden_size))
self.pre_output_gate=TimeDistributed(GLU(self.hidden_size))
self. output_layer=TimeDistributed(nn.Linear(self.hidden_size,self.num_quantiles),batch_first=True)
def init_hidden(self):
return torch.zeros(self.lstm_layers,self.batch_size,self.hidden_size,device=self.device)#初始化隐藏层大小
def apply_embedding(self,x,static_embedding,apply_masking):#连续型变量
###x should have dimensions (batch_size, timesteps, input_size)
if apply_masking:#判断是否进行masking
time_varying_real_vectors=[]
for i in range(self.time_varying_real_variables_decoder):
emb=self.time_varying_linear_layers[i+self.num_input_series_to_mask](x[:,:,i+self.num_input_series_to_mask].view(x.size(0), -1, 1))
# print(emb.device)
time_varying_real_vectors.append(emb)
time_varying_real_embedding=torch.cat(time_varying_real_vectors,dim=-1)
else:#正常的进行embedding[bs,time_steps,input_size]-->[bs,time_step,input_size*num_inputs]
time_varying_real_vectors = []
for i in range(self.time_varying_real_variables_encoder):
emb = self.time_varying_linear_layers[i](x[:,:,i].view(x.size(0), -1, 1))
time_varying_real_vectors.append(emb)
time_varying_real_embedding = torch.cat(time_varying_real_vectors, dim=-1)
##Time-varying categorical embeddings (eg:hour),时序离散型变量
time_varying_categorical_vectors=[]
for i in range(self.time_varying_categorical_variables):
# print(x[:,:,self.time_varying_real_variables_encoder+i].view(x.size(0),-1,1).long().device)
emb=self.time_varying_embedding_layers[i](x[:,:,self.time_varying_real_variables_encoder+i].view(x.size(0),-1,1).long())
time_varying_categorical_vectors.append(emb)
time_varying_categorical_embedding=torch.cat(time_varying_categorical_vectors,dim=-1)
# 对static_embedding在时间步上进行扩维
static_embedding = torch.cat(time_varying_categorical_embedding.size(1)*[static_embedding])
static_embedding = static_embedding.view(time_varying_categorical_embedding.size(0),time_varying_categorical_embedding.size(1),-1 )
#连接所有的embeddings
embeddings=torch.cat([static_embedding,time_varying_categorical_embedding,time_varying_real_embedding],dim=-1)
return embeddings.view(-1,x.size(0),embeddings.size(-1))#最后一项返回的是num_inputs*inputs_size的大小
def encode(self, x, hidden=None):
if hidden is None:
hidden = self.init_hidden()
output, (hidden, cell) = self.lstm_encoder(x, (hidden, hidden))
return output, hidden
def decode(self, x, hidden=None):
if hidden is None:
hidden = self.init_hidden()
output, (hidden, cell) = self.lstm_decoder(x, (hidden,hidden))
return output, hidden
def forward(self,x):
#输入的顺序为:static,time_varying_categorical,time_varying_real
embedding_vectors=[]
for i in range(self.static_variables):
#静态变量只需要从第一个时间步获取即可 x:-->[bs,time_step,num_inputs]
emb=self.static_embedding_layers[i](x['identifier'].to(self.device)[:,0,i].long())
embedding_vectors.append(emb)#[bs,inputs]*number_inputs-->[bs,inputs*num_inputs]
# Embedding和variables selection
static_embedding=torch.cat(embedding_vectors,dim=-1).to(self.device)#[bs,inputs*num_inputs]
# print(static_embedding.device)
# print(x['inputs'][:,:self.encode_length,:].float().to(self.device).device)
embeddings_encoder=self.apply_embedding(x['inputs'][:,:self.encode_length,:].float().to(self.device),static_embedding,apply_masking=False)#
embeddings_decoder=self.apply_embedding(x['inputs'][:,self.encode_length:,:].float().to(self.device),static_embedding,apply_masking=True)
embeddings_encoder,encoder_sparse_weights=self.encoder_variable_selection(embeddings_encoder[:,:,:-(self.embedding_dim*self.static_variables)],embeddings_encoder[:,:,-(self.embedding_dim*self.static_variables):])
embeddings_decoder,decoder_sparse_weights=self.decoder_variable_selection(embeddings_decoder[:,:,:-(self.embedding_dim*self.static_variables)],embeddings_decoder[:,:,-(self.embedding_dim*self.static_variables):])
#进行位置编码
pe=self.position_encoding(torch.zeros(self.seq_length,1,embeddings_encoder.size(2)).to(self.device)).to(self.device)
embeddings_encoder=embeddings_encoder+pe[:self.encode_length,:,:]##[seq_len_encoder,bs,num_inputs*inputs_len]
embeddings_decoder=embeddings_decoder+pe[self.encode_length:,:,:]##[seq_len_decoder,bs,num_inputs*inputs_len]
##LSTM
lstm_input=torch.cat([embeddings_encoder,embeddings_decoder],dim=0)#在时间序列上对编码和解码后的数据进行拼接
encoder_output,hidden=self.encode(embeddings_encoder)#对encoder部分的数据进行编码,并传回hidden层的数据给下一步解码
decoder_output,_=self.decode(embeddings_decoder,hidden)
lstm_output=torch.cat([encoder_output,decoder_output],dim=0)#将lstm的输出在序列维度上进行拼接[sq,bs,hidden_len]
#进行残差连接并通过gate(GLU)+Norm
lstm_output=self.post_lstm_norm((self.post_lstm_gate(lstm_output)+lstm_input))
##static enrichment
static_embedding=torch.cat(lstm_output.size(0)*[static_embedding]).view(lstm_output.size(0),lstm_output.size(1),-1)#[bs,inputs*num_static_inputs]-->GRN(inputs,se)-->context
attn_input=self.static_enrichment(lstm_output,static_embedding)
#求一个LN
## Attention层(Multihead Attention)
attn_output,atten_output_weight=self.multihead_attn(attn_input[self.encode_length:,:,:],attn_input[:self.encode_length,:,:],attn_input[:self.encode_length,:,:])#结果大小同查询,也就是Q的大小,weights的大小为:(N, num_heads, L, S),L为Q的大小,S为K,V的大小
## gate
attn_output=self.post_attn_gate(attn_output)+attn_input[self.encode_length:,:,:]
# print(attn_output.shape)
attn_output=self.post_attn_norm(attn_output)
output=self.pos_wise_ff(attn_output) #[self.encode_length:,:,:]
# resurial
output=self.pre_output_gate(output)+lstm_output[self.encode_length:,:,:]
output=self.pre_output_norm(output)
#Final output layers(Dense)
output=self.output_layer(output.view(self.batch_size,-1,self.hidden_size))#这里batch_first=ture
return output,encoder_output,decoder_output,attn_output,atten_output_weight,encoder_sparse_weights,decoder_sparse_weights
#损失:
class QuantileLoss(nn.Module):#--》input:-->->,计算损失如下:
## From: https://medium.com/the-artificial-impostor/quantile-regression-part-2-6fdbc26b2629
def __init__(self, quantiles):
##takes a list of quantiles
super().__init__()
self.quantiles = quantiles
def forward(self, preds, target):
assert not target.requires_grad
assert preds.size(0) == target.size(0)#检验程序使用的,如果不满足条件,程序会自动退出
losses = []
for i, q in enumerate(self.quantiles):
errors = target - preds[:, i]
losses.append(
torch.max(
(q-1) * errors,
q * errors
).unsqueeze(1))
loss = torch.mean(
torch.sum(torch.cat(losses, dim=1), dim=1))
return loss
import pandas as pd
from torch.utils.data import Dataset
import numpy as np
构建数据集
#生成演示数据
df=pd.read_csv('LD2011_2014.txt',index_col=0,sep=';',decimal=',')
df.index=pd.to_datetime(df.index)
df.sort_index(inplace=True)#inplace是使用排序后的数据来代替现有数据
#定义时间步
output=df.resample('1h').mean().replace(0,np.nan)
earliest_time=output.index.min()
df_list=[]
for label in output:
print('Processing {}'.format(label))
srs = output[label]
start_date = min(srs.fillna(method='ffill').dropna().index)
end_date = max(srs.fillna(method='bfill').dropna().index)
active_range = (srs.index >= start_date) & (srs.index <= end_date)
srs = srs[active_range].fillna(0.)
tmp = pd.DataFrame({'power_usage': srs})
date = tmp.index
tmp['t'] = (date - earliest_time).seconds / 60 / 60 + (
date - earliest_time).days * 24
tmp['days_from_start'] = (date - earliest_time).days
tmp['categorical_id'] = label
tmp['date'] = date
tmp['id'] = label
tmp['hour'] = date.hour
tmp['day'] = date.day
tmp['day_of_week'] = date.dayofweek
tmp['month'] = date.month
df_list.append(tmp)
Processing MT_001
Processing MT_002
Processing MT_003
Processing MT_004
Processing MT_005
Processing MT_006
Processing MT_007
Processing MT_008
Processing MT_009
Processing MT_010
Processing MT_011
Processing MT_012
Processing MT_013
Processing MT_014
Processing MT_015
Processing MT_016
Processing MT_017
Processing MT_018
Processing MT_019
Processing MT_020
Processing MT_021
Processing MT_022
Processing MT_023
Processing MT_024
Processing MT_025
Processing MT_026
Processing MT_027
Processing MT_028
Processing MT_029
Processing MT_030
Processing MT_031
Processing MT_032
Processing MT_033
Processing MT_034
Processing MT_035
Processing MT_036
Processing MT_037
Processing MT_038
Processing MT_039
Processing MT_040
Processing MT_041
Processing MT_042
Processing MT_043
Processing MT_044
Processing MT_045
Processing MT_046
Processing MT_047
Processing MT_048
Processing MT_049
Processing MT_050
Processing MT_051
Processing MT_052
Processing MT_053
Processing MT_054
Processing MT_055
Processing MT_056
Processing MT_057
Processing MT_058
Processing MT_059
Processing MT_060
Processing MT_061
Processing MT_062
Processing MT_063
Processing MT_064
Processing MT_065
Processing MT_066
Processing MT_067
Processing MT_068
Processing MT_069
Processing MT_070
Processing MT_071
Processing MT_072
Processing MT_073
Processing MT_074
Processing MT_075
Processing MT_076
Processing MT_077
Processing MT_078
Processing MT_079
Processing MT_080
Processing MT_081
Processing MT_082
Processing MT_083
Processing MT_084
Processing MT_085
Processing MT_086
Processing MT_087
Processing MT_088
Processing MT_089
Processing MT_090
Processing MT_091
Processing MT_092
Processing MT_093
Processing MT_094
Processing MT_095
Processing MT_096
Processing MT_097
Processing MT_098
Processing MT_099
Processing MT_100
Processing MT_101
Processing MT_102
Processing MT_103
Processing MT_104
Processing MT_105
Processing MT_106
Processing MT_107
Processing MT_108
Processing MT_109
Processing MT_110
Processing MT_111
Processing MT_112
Processing MT_113
Processing MT_114
Processing MT_115
Processing MT_116
Processing MT_117
Processing MT_118
Processing MT_119
Processing MT_120
Processing MT_121
Processing MT_122
Processing MT_123
Processing MT_124
Processing MT_125
Processing MT_126
Processing MT_127
Processing MT_128
Processing MT_129
Processing MT_130
Processing MT_131
Processing MT_132
Processing MT_133
Processing MT_134
Processing MT_135
Processing MT_136
Processing MT_137
Processing MT_138
Processing MT_139
Processing MT_140
Processing MT_141
Processing MT_142
Processing MT_143
Processing MT_144
Processing MT_145
Processing MT_146
Processing MT_147
Processing MT_148
Processing MT_149
Processing MT_150
Processing MT_151
Processing MT_152
Processing MT_153
Processing MT_154
Processing MT_155
Processing MT_156
Processing MT_157
Processing MT_158
Processing MT_159
Processing MT_160
Processing MT_161
Processing MT_162
Processing MT_163
Processing MT_164
Processing MT_165
Processing MT_166
Processing MT_167
Processing MT_168
Processing MT_169
Processing MT_170
Processing MT_171
Processing MT_172
Processing MT_173
Processing MT_174
Processing MT_175
Processing MT_176
Processing MT_177
Processing MT_178
Processing MT_179
Processing MT_180
Processing MT_181
Processing MT_182
Processing MT_183
Processing MT_184
Processing MT_185
Processing MT_186
Processing MT_187
Processing MT_188
Processing MT_189
Processing MT_190
Processing MT_191
Processing MT_192
Processing MT_193
Processing MT_194
Processing MT_195
Processing MT_196
Processing MT_197
Processing MT_198
Processing MT_199
Processing MT_200
Processing MT_201
Processing MT_202
Processing MT_203
Processing MT_204
Processing MT_205
Processing MT_206
Processing MT_207
Processing MT_208
Processing MT_209
Processing MT_210
Processing MT_211
Processing MT_212
Processing MT_213
Processing MT_214
Processing MT_215
Processing MT_216
Processing MT_217
Processing MT_218
Processing MT_219
Processing MT_220
Processing MT_221
Processing MT_222
Processing MT_223
Processing MT_224
Processing MT_225
Processing MT_226
Processing MT_227
Processing MT_228
Processing MT_229
Processing MT_230
Processing MT_231
Processing MT_232
Processing MT_233
Processing MT_234
Processing MT_235
Processing MT_236
Processing MT_237
Processing MT_238
Processing MT_239
Processing MT_240
Processing MT_241
Processing MT_242
Processing MT_243
Processing MT_244
Processing MT_245
Processing MT_246
Processing MT_247
Processing MT_248
Processing MT_249
Processing MT_250
Processing MT_251
Processing MT_252
Processing MT_253
Processing MT_254
Processing MT_255
Processing MT_256
Processing MT_257
Processing MT_258
Processing MT_259
Processing MT_260
Processing MT_261
Processing MT_262
Processing MT_263
Processing MT_264
Processing MT_265
Processing MT_266
Processing MT_267
Processing MT_268
Processing MT_269
Processing MT_270
Processing MT_271
Processing MT_272
Processing MT_273
Processing MT_274
Processing MT_275
Processing MT_276
Processing MT_277
Processing MT_278
Processing MT_279
Processing MT_280
Processing MT_281
Processing MT_282
Processing MT_283
Processing MT_284
Processing MT_285
Processing MT_286
Processing MT_287
Processing MT_288
Processing MT_289
Processing MT_290
Processing MT_291
Processing MT_292
Processing MT_293
Processing MT_294
Processing MT_295
Processing MT_296
Processing MT_297
Processing MT_298
Processing MT_299
Processing MT_300
Processing MT_301
Processing MT_302
Processing MT_303
Processing MT_304
Processing MT_305
Processing MT_306
Processing MT_307
Processing MT_308
Processing MT_309
Processing MT_310
Processing MT_311
Processing MT_312
Processing MT_313
Processing MT_314
Processing MT_315
Processing MT_316
Processing MT_317
Processing MT_318
Processing MT_319
Processing MT_320
Processing MT_321
Processing MT_322
Processing MT_323
Processing MT_324
Processing MT_325
Processing MT_326
Processing MT_327
Processing MT_328
Processing MT_329
Processing MT_330
Processing MT_331
Processing MT_332
Processing MT_333
Processing MT_334
Processing MT_335
Processing MT_336
Processing MT_337
Processing MT_338
Processing MT_339
Processing MT_340
Processing MT_341
Processing MT_342
Processing MT_343
Processing MT_344
Processing MT_345
Processing MT_346
Processing MT_347
Processing MT_348
Processing MT_349
Processing MT_350
Processing MT_351
Processing MT_352
Processing MT_353
Processing MT_354
Processing MT_355
Processing MT_356
Processing MT_357
Processing MT_358
Processing MT_359
Processing MT_360
Processing MT_361
Processing MT_362
Processing MT_363
Processing MT_364
Processing MT_365
Processing MT_366
Processing MT_367
Processing MT_368
Processing MT_369
Processing MT_370
output=pd.concat(df_list,axis=0,join='outer').reset_index(drop=True)
output['categorical_id'] = output['id'].copy()
output['hours_from_start'] = output['t']
output['categorical_day_of_week'] = output['day_of_week'].copy()
output['categorical_hour'] = output['hour'].copy()
# Filter to match range used by other academic papers
output = output[(output['days_from_start'] >= 1096)
& (output['days_from_start'] < 1346)].copy()
##查看数据格式:
import expt_settings.configs
ExperimentConfig = expt_settings.configs.ExperimentConfig
config = ExperimentConfig('electricity', 'outputs')
data_formatter = config.make_data_formatter()
print("*** Training from defined parameters for {} ***".format('electricity'))
data_csv_path = 'hourly_electricity.csv'
print("Loading & splitting data...")
raw_data = pd.read_csv(data_csv_path, index_col=0)
train, valid, test = data_formatter.split_data(raw_data)
train_samples, valid_samples = data_formatter.get_num_samples_for_calibration(
)
*** Training from defined parameters for electricity ***
Loading & splitting data...
Formatting train-valid-test splits.
Setting scalers with training data...
# Sets up default params
fixed_params = data_formatter.get_experiment_params()
params = data_formatter.get_default_model_params()
# train#对部分数据进行了标准化
len(train.id.unique())
369
##定义time_step dataset-->[bs,ts,num_inputs]
class TSDataset(Dataset):#继承Dataset,核心在于__getitem__和__len__
def __init__(self,id_col,static_cols,time_col,input_col,target_col,time_steps,max_samples,input_size,num_encoder_steps,num_static,output_size,data):
self.time_steps=time_steps
self.input_size=input_size
self.output_size=output_size
self.num_encoder_steps=num_encoder_steps
data.sort_values(by=[id_col,time_col],inplace=True)#将数据根据id和时间轴进行排序
valid_sampling_locations=[]
split_data_map={}
for identifier,df in data.groupby(id_col):#group本质上是一个聚合函数,按照需求进行分类,将数据切分成i个df,每个df的聚合指标的值都是相同的
num_entries=len(df)
if num_entries>=self.time_steps:#将数据进行切片
valid_sampling_locations+=[(identifier,self.time_steps+i) for i in range(num_entries-self.time_steps+1)]#第identifier个元组列表,长度为时间轴-时间序列的长度(这里是做项的切割)
split_data_map[identifier]=df#第identifier的字典存放第identifier的项目数据
self.inputs=np.zeros((max_samples,self.time_steps,self.input_size))#大小为samples*ts*input_num
self.outputs=np.zeros((max_samples,self.time_steps,self.output_size))#samples*ts*output_num
self.time=np.empty((max_samples,self.time_steps,1))
self.identifiers=np.empty((max_samples,self.time_steps,num_static))
if max_samples>0 and len(valid_sampling_locations)>max_samples:#基本限制
print(f'Extracting {max_samples} samples')
ranges=[valid_sampling_locations[i] for i in np.random.choice(len(valid_sampling_locations),max_samples,replace=False)]
# 随机在数据集中抽取max_samples个数据
# replace是指允许出现相同的值(拿球后需要放回去),replace为flase是指禁止出现相同的值,此时所选取的数列长度必须要小于数据集合的元素数量
else:
print(f'Max samples ={max_samples} available segments={len(valid_sampling_locations)}')
ranges=valid_sampling_locations
for i,tup in enumerate(ranges):#ranges内为随机切割的(identifier,self.time_step+i)的元组
if ((i+1)%10000)==0:
print(i+1,'of',max_samples,'samples done....')
identifier,start_idx=tup
sliced=split_data_map[identifier].iloc[start_idx-self.time_steps:start_idx]#默认先选第一维
self.inputs[i,:,:]=sliced[input_col]
self.outputs[i,:,:]=sliced[[target_col]]
self.time[i,:,0]=sliced[time_col]
if static_cols:
self.identifiers[i,:,:]=sliced[static_cols]
self.sample_data={
'inputs':self.inputs,
'outputs':self.outputs[:,self.num_encoder_steps:,:],
'active_entries':np.ones_like(self.outputs[:,self.num_encoder_steps:,:]),#np.ones_like函数直接生成某大小的全为1的float数组
'time':self.time,
'identifier':self.identifiers
}
def __getitem__(self,index):
s={
'inputs':self.inputs[index],
'outputs':self.outputs[index,self.num_encoder_steps:,:],
'active_entries': np.ones_like(self.outputs[index, self.num_encoder_steps:, :]),
'time': self.time[index],
'identifier': self.identifiers[index]
}
return s
def __len__(self):
return self.inputs.shape[0]#max_samples
id_col = 'categorical_id'
time_col='hours_from_start'
input_cols =['power_usage', 'hour', 'day_of_week', 'hours_from_start', 'categorical_id']
target_col = 'power_usage'
time_steps=192
num_encoder_steps = 168
output_size = 1
max_samples = 1000
input_size = 5
elect=TSDataset(id_col=id_col,time_col=time_col,input_col=input_cols,target_col=target_col,time_steps=time_steps,max_samples=max_samples,input_size=input_size,num_encoder_steps=num_encoder_steps,output_size=output_size,data=train,static_cols=None,num_static=1)
Extracting 1000 samples
batch_size=128
from torch.utils.data import DataLoader
loader=DataLoader(
elect,
batch_size=batch_size,
)
t=next(iter(loader))
for batch in loader:
break
static_cols = ['meter']
categorical_cols = ['hour']
real_cols = ['power_usage', 'hour', 'day']
config = {}
config['static_variables'] = 1#静态变量的数量
config['time_varying_categorical_variables'] = 1#离散变量的数量
config['time_varying_real_variables_encoder'] = 4#连续变量的数量
config['time_varying_real_variables_decoder'] = 3#解码层连续变量的数量
config['num_masked_series'] = 1#解码层需要mask的变量的数量(4-3)
config['static_embedding_vocab_sizes'] = [369]
config['time_varying_embedding_vocab_sizes'] = [369]
config['embedding_dim'] = 8
config['lstm_hidden_dimension'] = 160
config['lstm_layers'] = 1
config['drop_out'] = 0.05
config['device'] = 'cuda:0'
config['batch_size'] = 128
config['encode_length'] = 168
config['attn_heads'] = 4
config['num_quantiles'] = 3
config['valid_quantiles'] = [0.1, 0.5, 0.9]
config['seq_length']=192#168+24
device=torch.device('cuda:0')
model=TFT(config).to(device)
output,encoder_output,decoder_output,attn_output,atten_output_weight,encoder_sparse_weights,decoder_sparse_weights = model(batch)
D:\anaconda3\envs\pytorch\lib\site-packages\torch\nn\modules\rnn.py:65: UserWarning: dropout option adds dropout after all but last recurrent layer, so non-zero dropout expects num_layers greater than 1, but got dropout=0.05 and num_layers=1
"num_layers={}".format(dropout, num_layers))
D:\anaconda3\envs\pytorch\lib\site-packages\ipykernel_launcher.py:134: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
output.shape
torch.Size([128, 24, 3])
q_loss_func=QuantileLoss([0.1,0.5,0.9])
import torch.optim as optim
optimizer = optim.Adam(model.parameters(), lr=0.0001)
model.train()
epochs=100
losses = []
for i in range(epochs):
epoch_loss = []
j=0
for batch in loader:
output, encoder_ouput, decoder_output, attn, attn_weights,encoder_sparse_weights,decoder_sparse_weights = model(batch)
# print(output.device,)
loss= q_loss_func(output[:,:,:].view(-1,3), batch['outputs'][:,:,0].flatten().float().to(device))
loss.backward()
optimizer.step()
epoch_loss.append(loss.item())
j+=1
if j>5:
break
losses.append(np.mean(epoch_loss))
print(np.mean(epoch_loss))
D:\anaconda3\envs\pytorch\lib\site-packages\ipykernel_launcher.py:134: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
0.8006416956583658
0.7999884088834127
0.7668151756127676
0.7319403886795044
0.726747582356135
0.7607065538565317
0.8135423362255096
0.8432016670703888
0.8231969078381857
0.761721005042394
0.6956829130649567
0.6592607200145721
0.6720658640066782
0.7302353382110596
0.7924310863018036
0.8072405358155569
0.7689102192719778
0.7168515821297964
0.6805834372838339
0.6649592419465383
0.6662554542223612
0.678734670082728
0.6953920423984528
0.7107692460219065
0.7225532829761505
0.729248841603597
0.7277947465578715
0.7171043356259664
0.700122614701589
0.6821212271849314
0.6697695453961691
0.6694994668165842
0.6816134452819824
0.7033764322598776
0.725969264904658
0.7419355611006418
0.7459502319494883
0.7388339142004648
0.7245846688747406
0.7101153830687205
0.7013588547706604
0.703824390967687
0.7168124715487162
0.7370895445346832
0.7601349651813507
0.7801720400651296
0.7943577965100607
0.8007777631282806
0.7973537842432658
0.7844546735286713
0.7637931108474731
0.7376755177974701
0.7090499997138977
0.6818542381127676
0.6595257719357809
0.645796130100886
0.6428835491339365
0.6525691449642181
0.6745708882808685
0.7062879502773285
0.7445076505343119
0.7836808959643046
0.8192594250043234
0.8472486337025961
0.8637207349141439
0.8675130009651184
0.8589732150236765
0.8392985363801321
0.8106586337089539
0.7769776284694672
0.7424585918585459
0.7098000744978586
0.6822504798571268
0.661311407883962
0.6473604043324789
0.6410616636276245
0.6426865061124166
0.6523745556672415
0.6679417590300242
0.6892276406288147
0.7145460347334543
0.743001401424408
0.7725268006324768
0.801397830247879
0.8284187217553457
0.8512799839178721
0.868938128153483
0.8796140054861704
0.8833309511343638
0.8803511659304301
0.8718405067920685
0.8586658835411072
0.8424527943134308
0.8235893646876017
0.8035478393236796
0.7830379406611124
0.7635184427102407
0.7448866168657938
0.7281776269276937
0.7138447066148123
output, encoder_ouput, decoder_output, attn, attn_weights,encoder_sparse_weights,decoder_sparse_weights = model(batch)
D:\anaconda3\envs\pytorch\lib\site-packages\ipykernel_launcher.py:134: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
output.to(torch.device('cpu'))
import matplotlib.pyplot as plt
import numpy as np
ind = np.random.choice(128)
print(ind)
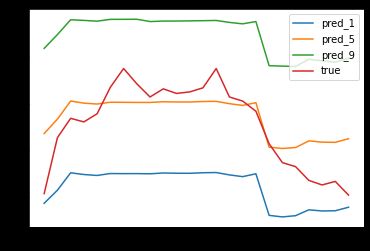
plt.plot(output[ind,:,0].detach().cpu().numpy(), label='pred_1')
plt.plot(output[ind,:,1].detach().cpu().numpy(), label='pred_5')
plt.plot(output[ind,:,2].detach().cpu().numpy(), label='pred_9')
plt.plot(batch['outputs'][ind,:,0], label='true')
plt.legend()
53