可解释多层时间序列预测的时间融合Transformers
可解释多层时间序列预测的时间融合Transformers

关注人工智能学术前沿 回复 :ts28
5秒免费获取论文pdf文档,及项目源码
摘要
多水平预测通常包含复杂的输入组合,包括静态(即时不变)协变量、已知的未来输入和其他仅在过去观察到的外生时间序列,没有任何关于它们如何与目标相互作用的事先信息。已经提出了几种深度学习方法,但它们都是典型的黑盒模型,并没有阐明它们如何使用实际场景中呈现的全部输入。在本文中,我们介绍了时域融合Transformer (TFT),一种新的基于注意力的架构,它结合了高性能的多水平预测和可解释的时间动态洞察力。为了学习不同尺度上的时间关系,TFT使用了局部处理的循环层和长期依赖的可解释自我注意层。TFT利用专门的组件来选择相关的功能和一系列的门控层来抑制不必要的组件,从而在广泛的场景中实现高性能。在各种真实世界的数据集上,我们展示了相对于现有基准的显著性能改进,并展示了TFT的三个实际可解释性用例。
1.介绍
多水平预测,即对未来多个时间步长的兴趣变量进行预测,是时间序列机器学习中的一个关键问题。与一步预测相比,多视角预测为用户提供了对整个路径的评估,允许他们在未来的多个步骤中优化自己的行为(例如,零售商优化整个即将到来的季节的库存,或临床医生优化患者的治疗计划)。多视角预测在零售业[1,2]、医疗保健[3,4]和经济领域有许多有影响力的现实应用,在这些应用中对现有方法的性能改进是非常有价值的。
图1:静态协变量、过去观测和先验已知的未来时间相关输入的多水平预测的说明。
实际的多水平预测应用程序通常可以访问各种数据源,如图1所示,包括关于未来(如即将到来的假期日期)的已知信息,其他外生时间序列(如历史客户客流量),以及静态元数据(例如,商店的位置),而事先不知道它们是如何交互的。数据源的异质性以及关于它们相互作用的信息很少,使得多视距时间序列预测特别具有挑战性.
深度神经网络(DNNs)越来越多地用于多水平预测,与传统时间序列模型相比,表现出了较强的性能改进[6,7,8]。虽然许多体系结构关注于递归神经网络(RNN)体系结构的变体[9,6,10],但最近的改进也使用了基于注意的方法来增强过去[11]中相关时间步长的选择,包括基于Transformer的模型[12]。然而,这些方法往往没有考虑到多水平预测中普遍存在的不同类型的投入,或者假设所有外生投入在未来都是已知的[9,6,这是自回归模型的一个常见问题,或者忽略了重要的静态协变量[10],这些协变量在每一步简单地与其他时间相关的特征连接在一起.时间序列模型最近的许多改进都源于具有独特数据特征的架构的对齐[13,14]。我们论证并证明,通过设计具有适当归纳偏差的网络进行多水平预测,也可以获得类似的性能增益。
在本文中,我们提出了时域融合变压器(TFT),这是一种基于注意的DNN体系结构,用于多级预测,在实现高性能的同时实现了新的可解释性形式。为了在最先进的基准测试中获得显著的性能改进,我们引入了多种新颖的想法,以使体系结构与多视域预测共同的全部潜在输入和时间关系相一致,具体地包括:
(1)静态协变量编码器,它对网络的其他部分使用的上下文向量进行编码,
(2)整个门控机制和样本依赖变量选择,以最小化不相关输入的贡献,
(3)序列到序列层局部处理已知和观察的输入,
(4)时间自注意解码器,以学习数据集中存在的任何长期依赖。
这些专门组件的使用也有助于解释;特别地,我们展示了TFT实现了三个有价值的可解释性用例:帮助用户识别(i)预测问题的全局重要变量,(ii)持久的时间模式,和(iii)重大事件。在各种真实世界的数据集上,我们演示了TFT如何可以实际应用,以及它提供的见解和好处。
2.模型概述

图2:TFT架构。TFT输入静态元数据、时变的过去输入和时变的先验已知的未来输入。变量选择用于基于输入的最显著特征的明智选择。通过跳过连接和门控层,网络块使有效的信息流动成为可能。时变处理是基于lstm进行局部处理,多头注意对任意时间步长的信息进行集成。
我们设计TFT是为了使用规范组件有效地为每个输入类型(即静态的、已知的、观察到的输入)构建特征表示,以在广泛的问题上实现高预测性能。TFT的主要成分是:
1.Gating mechanisms
涉及GatedResidual Network (GRN) 公式推导
2.Variable selection networks
对于类别变量,我们使用entity embeddings[31]作为特征表示,对于连续变量,我们使用线性转换将每个输入变量转换为一个(dmodel)维向量,该向量与后续层的维度相匹配,用于跳跃连接
3.Static covariate encoders
基于transformer的架构中的多头注意加以改进[17,12],以增强可解释性。
4.Temporal processing
5.Prediction intervals
关注人工智能学术前沿 回复 :ts28
5秒免费获取论文pdf文档,及项目源码
3.实验概述
基线模型
Direct methods:直:由于TFT属于这类多视界模型,我们主要关注直接生成未来视界预测的深度学习模型的比较,包括:1)具有全局上下文的简单序列到序列模型(Seq2Seq), 2)多视界分位数循环预测(MQRNN)[10]。
Iterative methods:为了对迭代模型的大量工作进行定位,我们对电力和交通数据集使用与[9]相同的设置来评估TFT。这将[12]的结果扩展到
1)DeepAR [9],
2) DSSM[6],
3)[12]基于transformer的架构与局部卷积处理,称为ConvTrans。
数据集
Electricity: UCI电力负荷图数据集,包含370个客户的电力消耗——按小时计算,如[32]。根据[9],我们使用过去一周(即168小时)来预测未来24小时。
Traffic:交通UCI pemf -SF交通数据集描述了440条SF湾区高速公路的占用率(yt∈[0,1]),如[32]。它还根据电力数据集以每小时的水平进行聚合,具有相同的回顾窗口和预测水平。
Retail: 零:来自Kaggle竞争[33]的Favorita杂货店销售数据集,该数据集结合了不同产品和商店的元数据,以及其他在每日级别采样的外生时变输入。我们利用过去90天的信息预测未来30天的产品销售。
Volatility (or Vol.): OMI实现库[34]包含31个股票指数的日实现波动性值,计算从日内数据,以及他们的日回报。在我们的实验中,我们使用过去一年中(即252个工作日)的信息来考虑下一周(即5个工作日)的预测。
实验结果
表2:一系列真实数据集上的P50和P90分位数损失。括号中的百分比反映了与TFT (q-Risk越低越好)相比分位数损失的增加,TFT在所有实验中都优于其他竞争方法,在次优替代方法(下划线)上的改进介于3%到26%之间。
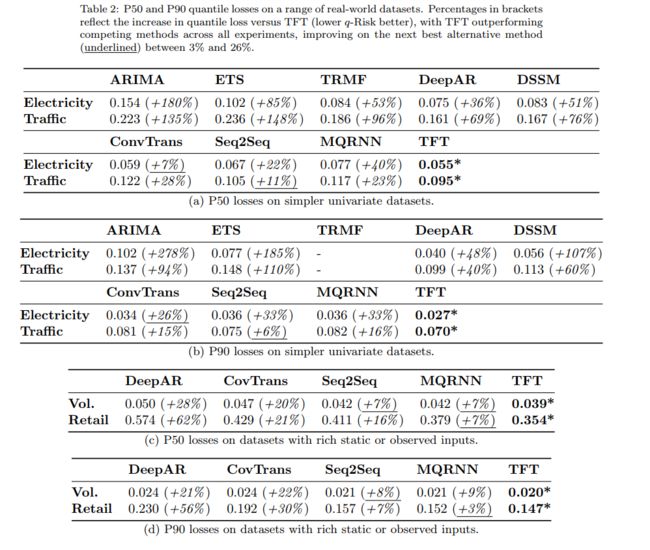
表2显示,在章节6.1中描述的各种数据集中,TFT显著优于所有基准测试。对于中值预测,TFT的P50损失平均比下一个最佳模型低7%,P90损失平均低9%。
结论
我们介绍了TFT,一种新的基于注意的深度学习模型,用于可解释的高性能多层预测。为了有效地处理静态协变量、先验已知的输入和跨大范围的多水平预测数据集的观测输入,TFT使用了专门的组件。具体地说,这些包括:
(1)序列到序列和基于注意力的时间处理组件,捕获不同时间尺度上的时变关系,
(2)静态协变量编码器,允许网络在静态元数据上限制时间预测,
(3)门控组件,允许跳过网络的不必要部分,
(4)变量选择,在每个时间步长选取相关的输入特征;
(5)分位数预测,获得所有预测视域的输出区间。在广泛的真实世界任务中,无论是包含已知输入的简单数据集,还是包含所有可能输入的复杂数据集,我们都表明TFT实现了最先进的预测性能。
最后,我们通过一系列可解释性用例研究TFT学习到的一般关系,提出了使用TFT的新方法
(i)分析给定预测问题的重要变量,
(ii)可视化学习到的持久时间关系(例如季节性),和
(iii)识别重要的制度变化。