细粒度识别 DCL 论文及代码学习笔记
论文部分
论文链接:CVPR 2019 Open Access Repository
动机
在过去几年,通用目标识别在大规模注释数据集和复杂模型的帮助下取得了重大进展。然而,识别诸如鸟类和汽车等细粒度的目标类别仍然是一项具有挑战性的任务。粗略一看,细粒度的目标看起来是相似的,但它们可以通过有区别的局部细节来进行区分。
从具有区分度的目标部分学习判别特征表示在细粒度图像识别中起着关键作用。现有的细粒度识别方法可分为两类 (如下图所示):1)首先定位可区分的目标部分,然后对可区分区域进行分类。这类方法需要对目标或目标部分进行额外的边界框注释,成本高;2)通过注意力机制以无监督的方式自动定位判别区域,因此不需要额外的注释。然而,这些方法通常需要额外网络结构(如注意力机制)的辅助,从而增加了计算开销。
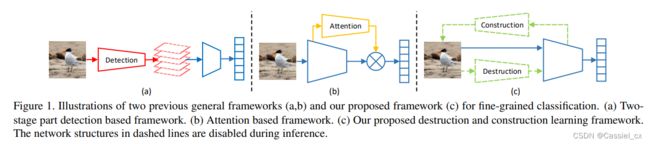
创新点
提出了“破坏和构建学习 (Destruction and Construction Learning,DCL)”框架用于细粒度识别。 对于 destruction,区域混淆机制 (region confusion mechanism,RCM) 迫使分类网络从判别区域中学习,对抗性损失可防止网络过拟合 RCM 引起的噪声。对于 construction,区域对齐网络通过对区域之间的语义相关性进行建模来恢复原始区域布局。此外,DCL 不需要额外的注释以及辅助网络。
方法论
DCL 的整个框架如下图所示,由四部分组成 (RCM、分类网络、对抗学习网络、区域对齐网络),但在推理阶段只需要使用分类网络即可。

(1) Destruction Learning
对于细粒度的图像识别,局部细节比全局信息更重要。在大多数情况下,不同的细粒度类别通常具有相似的全局结构,仅在某些局部细节上有所不同。因此作者提出了 RCM,以便更好地识别判别区域和学习判别特征。为了防止网络学习从破坏学习中引入的噪声模式,作者还提出了对抗学习来拒绝与细粒度分类无关的 RCM-induced 模式。
RCM:如下图所示,RCM 可以破坏局部图像区域的空间布局。给定输入图像 I,首先将图像均分成 N×N 个区域,记为 ![]() ,其中 i 和 j 分别是水平和垂直的索引。对于 R 的第 j 行,先生成一个大小为 N 的向量
,其中 i 和 j 分别是水平和垂直的索引。对于 R 的第 j 行,先生成一个大小为 N 的向量 ![]() ,其中第 i 个元素以下面的规则进行移动:
,其中第 i 个元素以下面的规则进行移动: 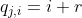 ,r 服从均匀分布 U(-k,k),k 的范围是 [1,N)。列元素移动同理。移动行和列的元素后可以得到一个新的区域组合:
,r 服从均匀分布 U(-k,k),k 的范围是 [1,N)。列元素移动同理。移动行和列的元素后可以得到一个新的区域组合:


将原始图像  ,打乱后的图像
,打乱后的图像 ![]() 以及标签
以及标签 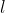 组成一个三元组
组成一个三元组 ![]() 作为训练的输入。分类网络将输入图片映射为一个概率分布向量
作为训练的输入。分类网络将输入图片映射为一个概率分布向量 ![]() ,
,![]() 是网络中可训练的参数。分类网络的损失函数如下:
是网络中可训练的参数。分类网络的损失函数如下:
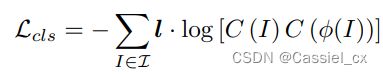
由于全局结构已被破坏,为了识别这些随机打乱的图像,分类网络必须找到判别区域并学习它们之间的差异。
对抗学习:由 RCM 打乱的图片不一定都有助于细粒度识别,RCM 会引入噪声,作者因此提出对抗学习。使用 one-hot 码标记每张图片,0 代表打乱后的图片,1 代表原图。作者在框架中添加一个判别器作为一个新的分支来判断图像 I 是否被破坏,公式如下:

其中,![]() 表示从骨干网络中第 m 层的输出中提取的特征向量,另一个参数为判别器中的可训练的参数。该网络的损失函数如下:
表示从骨干网络中第 m 层的输出中提取的特征向量,另一个参数为判别器中的可训练的参数。该网络的损失函数如下:

(2) Construction Learning
作者提出了提出了一个带有区域重构损失的区域对齐网络,它通过度量图像中不同区域的定位精度来诱导分类网络对区域间的语义关联进行建模。
公式如下:


(3) Destruction and Construction Learning
在 DCL 框架中,分类、对抗和区域对齐损失以端到端的方式进行训练,其中网络可以利用增强的局部细节和良好建模的目标部分相关性来进行细粒度识别。具体来说,希望最小化以下目标:

破坏学习主要帮助模型从判别区域学习,而构建学习根据区域之间的语义相关性重新排列学习到的局部细节。因此,DCL 基于来自判别区域的细节特征产生了一组复杂多样的视觉表示。
实验结果


作者提出了 DCL 框架来进行细粒度的图片识别。其中的 destruction 部分提高了网络学习判别区域特征的能力,construction 部分构建了各部分的空间语义关联信息,模型不再需要额外的监督信息即可端到端训练。此外,模型参数较小,容易训练和应用。
代码
代码链接:GitHub - JDAI-CV/DCL: Destruction and Construction Learning for Fine-grained Image Recognition
环境配置
环境配置参考GitHub,
conda create --name DCL file conda_list.txt
pip install pretrainedmodels克隆下来后,把在imagenet上预训练好的模型放到./models/pretrained目录下,预训练模型的下载链接:https://download.pytorch.org/models/resnet50-19c8e357.pth
接下来就是数据集下载,可以参考:细粒度数据集:CUB-200-2011 CUB,百度云下载_画外人易朽的博客-CSDN博客_cub数据集下载
下载好数据集后,为了和代码中的路径对齐,可以把全部图片copy到data文件夹中,参考代码如下:
import os
import sys
import shutil
dir = r'D:\Projects\Data_Augmentation\CUB_200_2011\images'
for i in os.listdir(dir):
path1 = os.path.join(dir, i)
for j in os.listdir(path1):
path2 = os.path.join(path1, j)
# print(path2)
# sys.exit()
shutil.copy(path2, os.path.join(r'D:\Projects\DCL\datasets\CUB\data', j))由于克隆下来的项目中只有train.txt文件而缺少ct_train.txt等文件,所以我就直接读取train.txt文件,并对源码做了修改,
首先是配置脚本的修改,主要修改路径位置,修改后的config.py脚本如下:
import os
import pandas as pd
import torch
from transforms import transforms
from utils.autoaugment import ImageNetPolicy
# pretrained model checkpoints
pretrained_model = {'resnet50' : './models/pretrained/resnet50-19c8e357.pth',}
# transforms dict
def load_data_transformers(resize_reso=512, crop_reso=448, swap_num=[7, 7]):
center_resize = 600
Normalize = transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
data_transforms = {
'swap': transforms.Compose([
transforms.Randomswap((swap_num[0], swap_num[1])),
]),
'common_aug': transforms.Compose([
transforms.Resize((resize_reso, resize_reso)),
transforms.RandomRotation(degrees=15),
transforms.RandomCrop((crop_reso,crop_reso)),
transforms.RandomHorizontalFlip(),
]),
'train_totensor': transforms.Compose([
transforms.Resize((crop_reso, crop_reso)),
# ImageNetPolicy(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]),
'val_totensor': transforms.Compose([
transforms.Resize((crop_reso, crop_reso)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]),
'test_totensor': transforms.Compose([
transforms.Resize((resize_reso, resize_reso)),
transforms.CenterCrop((crop_reso, crop_reso)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]),
]),
'None': None,
}
return data_transforms
class LoadConfig(object):
def __init__(self, args, version):
if version == 'train':
get_list = ['train', 'val']
elif version == 'val':
get_list = ['val']
elif version == 'test':
get_list = ['test']
else:
raise Exception("train/val/test ???\n")
###############################
#### add dataset info here ####
###############################
# put image data in $PATH/data
# put annotation txt file in $PATH/anno
if args.dataset == 'product':
self.dataset = args.dataset
self.rawdata_root = './../FGVC_product/data'
self.anno_root = './../FGVC_product/anno'
self.numcls = 2019
elif args.dataset == 'CUB':
self.dataset = args.dataset
self.rawdata_root = '/root/projects/DCL/datasets/CUB/data'
self.anno_root = '/root/projects/DCL/datasets/CUB/anno'
self.numcls = 200
elif args.dataset == 'STCAR':
self.dataset = args.dataset
self.rawdata_root = './dataset/st_car/data'
self.anno_root = './dataset/st_car/anno'
self.numcls = 196
elif args.dataset == 'AIR':
self.dataset = args.dataset
self.rawdata_root = './dataset/aircraft/data'
self.anno_root = './dataset/aircraft/anno'
self.numcls = 100
else:
raise Exception('dataset not defined ???')
# annotation file organized as :
# path/image_name cls_num\n
if 'train' in get_list:
self.train_anno = '/root/projects/DCL/datasets/CUB/anno/train.txt'
if 'val' in get_list:
self.val_anno = '/root/projects/DCL/datasets/CUB/anno/test.txt'
if 'test' in get_list:
self.test_anno = '/root/projects/DCL/datasets/CUB/anno/test.txt'
self.swap_num = args.swap_num
self.save_dir = './net_model'
if not os.path.exists(self.save_dir):
os.mkdir(self.save_dir)
self.backbone = args.backbone
self.use_dcl = True
self.use_backbone = False if self.use_dcl else True
self.use_Asoftmax = False
self.use_focal_loss = False
self.use_fpn = False
self.use_hier = False
self.weighted_sample = False
self.cls_2 = True
self.cls_2xmul = False
self.log_folder = './logs'
if not os.path.exists(self.log_folder):
os.mkdir(self.log_folder)
接下来就对数据读取脚本进行修改,主要修改数据集的读取方式,修改后的dataset_DCL.py脚本如下:
# coding=utf8
from __future__ import division
import os
import torch
import torch.utils.data as data
import pandas
import random
import PIL.Image as Image
from PIL import ImageStat
import sys
import pdb
def random_sample(img_names, labels):
anno_dict = {}
img_list = []
anno_list = []
for img, anno in zip(img_names, labels):
if not anno in anno_dict:
anno_dict[anno] = [img]
else:
anno_dict[anno].append(img)
for anno in anno_dict.keys():
anno_len = len(anno_dict[anno])
fetch_keys = random.sample(list(range(anno_len)), anno_len//10)
img_list.extend([anno_dict[anno][x] for x in fetch_keys])
anno_list.extend([anno for x in fetch_keys])
return img_list, anno_list
class dataset(data.Dataset):
def __init__(self, Config, anno, swap_size=[7,7], common_aug=None, swap=None, totensor=None, train=False, train_val=False, test=False):
self.root_path = Config.rawdata_root
self.numcls = Config.numcls
self.dataset = Config.dataset
self.use_cls_2 = Config.cls_2
self.use_cls_mul = Config.cls_2xmul
# if isinstance(anno, pandas.core.frame.DataFrame):
# self.paths = anno['ImageName'].tolist()
# self.labels = anno['label'].tolist()
# elif isinstance(anno, dict):
# self.paths = anno['img_name']
# self.labels = anno['label']
f = open(anno)
self.data_lists = f.readlines()
# if train_val:
# self.paths, self.labels = random_sample(self.paths, self.labels)
self.common_aug = common_aug
self.swap = swap
self.totensor = totensor
self.cfg = Config
self.train = train
self.swap_size = swap_size
self.test = test
def __len__(self):
return len(self.data_lists)
def __getitem__(self, item):
# print(self.data_lists)
# sys.exit()
img_label = self.data_lists[item].strip('\n').split(' ')
img_path = os.path.join(self.root_path, img_label[0])
img = self.pil_loader(img_path)
if self.test:
img = self.totensor(img)
label = int(img_label[1]) - 1
return img, label, img_label[0]
img_unswap = self.common_aug(img) if not self.common_aug is None else img
image_unswap_list = self.crop_image(img_unswap, self.swap_size)
swap_range = self.swap_size[0] * self.swap_size[1]
swap_law1 = [(i-(swap_range//2))/swap_range for i in range(swap_range)]
if self.train:
img_swap = self.swap(img_unswap)
image_swap_list = self.crop_image(img_swap, self.swap_size)
unswap_stats = [sum(ImageStat.Stat(im).mean) for im in image_unswap_list]
swap_stats = [sum(ImageStat.Stat(im).mean) for im in image_swap_list]
swap_law2 = []
for swap_im in swap_stats:
distance = [abs(swap_im - unswap_im) for unswap_im in unswap_stats]
index = distance.index(min(distance))
swap_law2.append((index-(swap_range//2))/swap_range)
img_swap = self.totensor(img_swap)
# one-hot编码从0开始
label = int(img_label[1]) - 1
if self.use_cls_mul:
label_swap = label + self.numcls
if self.use_cls_2:
label_swap = -1
img_unswap = self.totensor(img_unswap)
return img_unswap, img_swap, label, label_swap, swap_law1, swap_law2, img_label[0]
else:
label = int(img_label[1]) - 1
swap_law2 = [(i-(swap_range//2))/swap_range for i in range(swap_range)]
label_swap = label
img_unswap = self.totensor(img_unswap)
return img_unswap, label, label_swap, swap_law1, swap_law2, img_label[0]
def pil_loader(self,imgpath):
with open(imgpath, 'rb') as f:
with Image.open(f) as img:
return img.convert('RGB')
def crop_image(self, image, cropnum):
width, high = image.size
crop_x = [int((width / cropnum[0]) * i) for i in range(cropnum[0] + 1)]
crop_y = [int((high / cropnum[1]) * i) for i in range(cropnum[1] + 1)]
im_list = []
for j in range(len(crop_y) - 1):
for i in range(len(crop_x) - 1):
im_list.append(image.crop((crop_x[i], crop_y[j], min(crop_x[i + 1], width), min(crop_y[j + 1], high))))
return im_list
def get_weighted_sampler(self):
img_nums = len(self.data_lists)
l = []
for i in range(img_nums):
l.append(int(self.data_lists[i].strip('\n').split(' ')[-1]))
weights = [l.count(x) for x in range(self.numcls)]
return torch.utils.data.sampler.WeightedRandomSampler(weights, num_samples=img_nums)
def collate_fn4train(batch):
imgs = []
label = []
label_swap = []
law_swap = []
img_name = []
for sample in batch:
imgs.append(sample[0])
imgs.append(sample[1])
label.append(sample[2])
label.append(sample[2])
if sample[3] == -1:
label_swap.append(1)
label_swap.append(0)
else:
label_swap.append(sample[2])
label_swap.append(sample[3])
law_swap.append(sample[4])
law_swap.append(sample[5])
img_name.append(sample[-1])
return torch.stack(imgs, 0), label, label_swap, law_swap, img_name
def collate_fn4val(batch):
imgs = []
label = []
label_swap = []
law_swap = []
img_name = []
for sample in batch:
imgs.append(sample[0])
label.append(sample[1])
if sample[3] == -1:
label_swap.append(1)
else:
label_swap.append(sample[2])
law_swap.append(sample[3])
img_name.append(sample[-1])
return torch.stack(imgs, 0), label, label_swap, law_swap, img_name
def collate_fn4backbone(batch):
imgs = []
label = []
img_name = []
for sample in batch:
imgs.append(sample[0])
if len(sample) == 7:
label.append(sample[2])
else:
label.append(sample[1])
img_name.append(sample[-1])
return torch.stack(imgs, 0), label, img_name
def collate_fn4test(batch):
imgs = []
label = []
img_name = []
for sample in batch:
imgs.append(sample[0])
label.append(sample[1])
img_name.append(sample[-1])
return torch.stack(imgs, 0), label, img_name
接下里便可进行训练和测试了,
python train.py --tb 16 --tnw 16 --vb 16 --vnw 16 --detail training_descibe --cls_mul --swap_num 7 7
