何恺明组新论文:只用ViT做主干也可以做好目标检测

来源:机器之心
本文约3100字,建议阅读5分钟
arXiv上上传了一篇新论文,证明了将普通的、非分层的视觉 Transformer 作为主干网络进行目标检测的可行性。做目标检测就一定需要 FPN 吗?昨天,来自 Facebook AI Research 的 Yanghao Li、何恺明等研究者在 arXiv 上上传了一篇新论文,证明了将普通的、非分层的视觉 Transformer 作为主干网络进行目标检测的可行性。他们希望这项研究能够引起大家对普通主干检测器的关注。
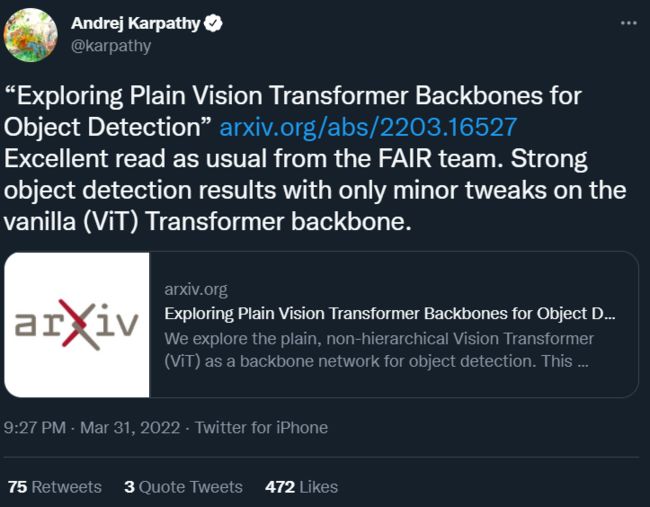
研究概览

论文链接:
https://arxiv.org/pdf/2203.16527.pdf
当前的目标检测器通常由一个与检测任务无关的主干特征提取器和一组包含检测专用先验知识的颈部和头部组成。颈部 / 头部中的常见组件可能包括感兴趣区域(RoI)操作、区域候选网络(RPN)或锚、特征金字塔网络(FPN)等。如果用于特定任务的颈部 / 头部的设计与主干的设计解耦,它们可以并行发展。从经验上看,目标检测研究受益于对通用主干和检测专用模块的大量独立探索。长期以来,由于卷积网络的实际设计,这些主干一直是多尺度、分层的架构,这严重影响了用于多尺度(如 FPN)目标检测的颈 / 头的设计。
在过去的一年里,视觉 Transformer(ViT)已经成为视觉识别的强大支柱。与典型的 ConvNets 不同,最初的 ViT 是一种简单的、非层次化的架构,始终保持单一尺度的特征图。它的「极简」追求在应用于目标检测时遇到了挑战,例如,我们如何通过上游预训练的简单主干来处理下游任务中的多尺度对象?简单 ViT 用于高分辨率图像检测是否效率太低?放弃这种追求的一个解决方案是在主干中重新引入分层设计。这种解决方案,例如 Swin Transformer 和其他网络,可以继承基于 ConvNet 的检测器设计,并已取得成功。
在这项工作中,何恺明等研究者追求的是一个不同的方向:探索仅使用普通、非分层主干的目标检测器。如果这一方向取得成功,仅使用原始 ViT 主干进行目标检测将成为可能。在这一方向上,预训练设计将与微调需求解耦,上游与下游任务的独立性将保持,就像基于 ConvNet 的研究一样。这一方向也在一定程度上遵循了 ViT 的理念,即在追求通用特征的过程中减少归纳偏置。由于非局部自注意力计算可以学习平移等变特征,它们也可以从某种形式的监督或自我监督预训练中学习尺度等变特征。
研究者表示,在这项研究中,他们的目标不是开发新的组件,而是通过最小的调整克服上述挑战。具体来说,他们的检测器仅从一个普通 ViT 主干的最后一个特征图构建一个简单的特征金字塔(如图 1 所示)。这一方案放弃了 FPN 设计和分层主干的要求。为了有效地从高分辨率图像中提取特征,他们的检测器使用简单的非重叠窗口注意力(没有 shifting)。他们使用少量的跨窗口块来传播信息,这些块可以是全局注意力或卷积。这些调整只在微调过程中进行,不会改变预训练。
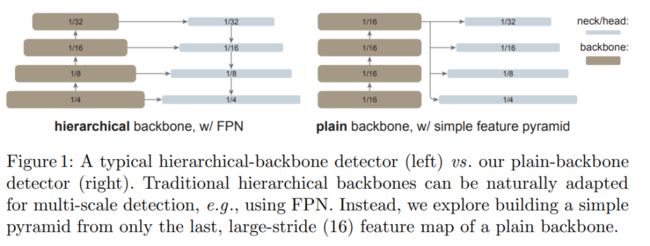
这种简单的设计收获了令人惊讶的结果。研究者发现,在使用普通 ViT 主干的情况下,FPN 的设计并不是必要的,它的好处可以通过由大步幅 (16)、单一尺度图构建的简单金字塔来有效地获得。他们还发现,只要信息能在少量的层中很好地跨窗口传播,窗口注意力就够用了。
更令人惊讶的是,在某些情况下,研究者开发的名为「ViTDet」的普通主干检测器可以媲美领先的分层主干检测器(如 Swin、MViT)。通过掩蔽自编码器(MAE)预训练,他们的普通主干检测器可以优于在 ImageNet-1K/21K 上进行有监督预训练的分层检测器(如下图 3 所示)。
在较大尺寸的模型上,这种增益要更加显著。该检测器的优秀性能是在不同的目标检测器框架下观察到的,包括 Mask R-CNN、Cascade Mask R-CNN 以及它们的增强版本。
在 COCO 数据集上的实验结果表明,一个使用无标签 ImageNet-1K 预训练、带有普通 ViT-Huge 主干的 ViTDet 检测器的 AP^box 可以达到 61.3。他们还在长尾 LVIS 检测数据集上展示了 ViTDet 颇具竞争力的结果。虽然这些强有力的结果可能部分来自 MAE 预训练的有效性,但这项研究表明,普通主干检测器可能是有前途的,这挑战了分层主干在目标检测中的根深蒂固的地位。
方法细节
该研究的目标是消除对主干网络的分层约束,并使用普通主干网络进行目标检测。因此,该研究的目标是用最少的改动,让简单的主干网络在微调期间适应目标检测任务。经过改动之后,原则上我们可以应用任何检测器头(detector head),研究者选择使用 Mask R-CNN 及其扩展。
简单的特征金字塔
FPN 是构建用于目标检测的 in-network 金字塔的常见解决方案。如果主干网络是分层的,FPN 的动机就是将早期高分辨率的特征和后期更强的特征结合起来。这在 FPN 中是通过自上而下(top-down)和横向连接来实现的,如图 1 左所示。
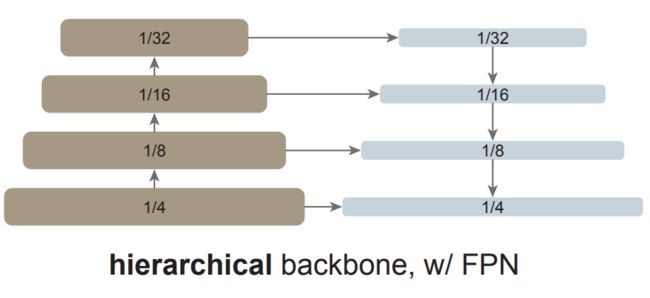
如果主干网络不是分层网络,那么 FPN 动机的基础就会消失,因为主干网络中的所有特征图都具有相同的分辨率。该研究仅使用主干网络中的最后一张特征图,因为它应该具有最强大的特征。
研究者对最后一张特征图并行应用一组卷积或反卷积来生成多尺度特征图。具体来说,他们使用的是尺度为 1/16(stride = 16 )的默认 ViT 特征图,该研究可如图 1 右所示,这个过程被称为「简单的特征金字塔」。
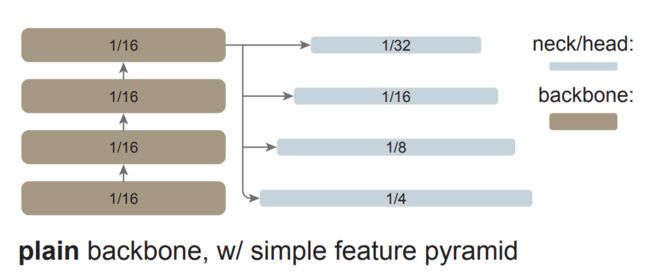
从单张特征图构建多尺度特征图的策略与 SSD 的策略有关,但该研究的场景涉及对深度、低分辨率的特征图进行上采样。在分层主干网络中,上采样通常用横向连接进行辅助,但研究者通过实验发现,在普通 ViT 主干网络中横向连接并不是必需的,简单的反卷积就足够了。研究者猜想这是因为 ViT 可以依赖位置嵌入来编码位置,并且高维 ViT patch 嵌入不一定会丢弃信息。
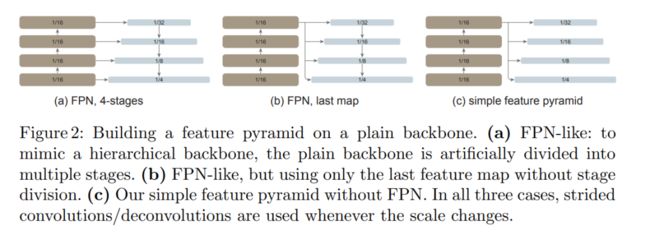
如下图所示,该研究将这种简单的特征金字塔与同样建立在普通主干网络上的两个 FPN 变体进行比较。在第一个变体中,主干网络被人为地划分为多个阶段,以模仿分层主干网络的各个阶段,并应用横向和自上而下的连接(图 2(a))。第二个变体与第一个变体类似,但仅使用最后一张特征图(图 2(b))。该研究表明这些 FPN 变体不是必需的。
主干网络调整
目标检测器受益于高分辨率输入图像,但在整个主干网络中,计算全局自注意力对于内存的要求非常高,而且速度很慢。该研究重点关注预训练主干网络执行全局自注意力的场景,然后在微调期间适应更高分辨率的输入。这与最近使用主干网络预训练直接修改注意力计算的方法形成对比。该研究的场景使得研究者能够使用原始 ViT 主干网络进行检测,而无需重新设计预训练架构。
该研究探索了使用跨窗口块的窗口注意力。在微调期间,给定高分辨率特征图,该研究将其划分为常规的非重叠窗口。在每个窗口内计算自注意力,这在原始 Transformer 中被称为「受限」自注意力。
与 Swin 不同,该方法不会跨层「移动(shift)」窗口。为了允许信息传播,该研究使用了极少数(默认为 4 个)可跨窗口的块。研究者将预训练的主干网络平均分成 4 个块的子集(例如对于 24 块的 ViT-L,每个子集中包含 6 个),并在每个子集的最后一个块中应用传播策略。研究者分析了如下两种策略:
全局传播。该策略在每个子集的最后一个块中执行全局自注意力。由于全局块的数量很少,内存和计算成本是可行的。这类似于(Li et al., 2021 )中与 FPN 联合使用的混合窗口注意力。
卷积传播。该策略在每个子集之后添加一个额外的卷积块来作为替代。卷积块是一个残差块,由一个或多个卷积和一个 identity shortcut 组成。该块中的最后一层被初始化为零,因此该块的初始状态是一个 identity。将块初始化为 identity 使得该研究能够将其插入到预训练主干网络中的任何位置,而不会破坏主干网络的初始状态。
这种主干网络的调整非常简单,并且使检测微调与全局自注意力预训练兼容,也就没有必要重新设计预训练架构。
实验结果
消融研究
在消融研究中,研究者得到了以下结论:
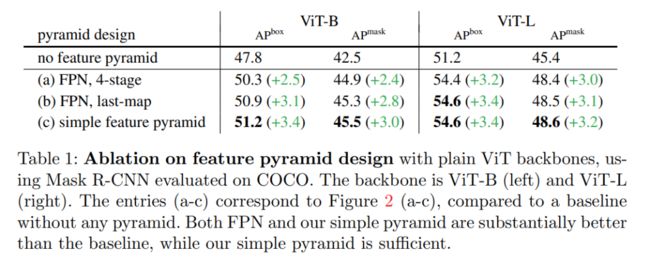
1、一个简单的特征金字塔就足够了。在表 1 中,他们比较了图 2 所示的特征金字塔构建策略。
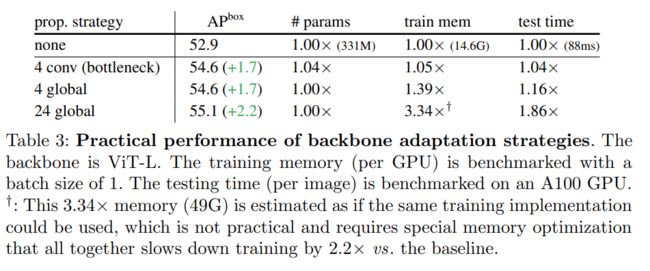
2、在几个传播块的帮助下,窗口注意力就足够了。表 2 总结了本文提出的主干调整方法。简而言之,与只有窗口注意力、无跨窗口传播块的基线(图中的「none」)相比,各种传播方式都可以带来可观的收益。

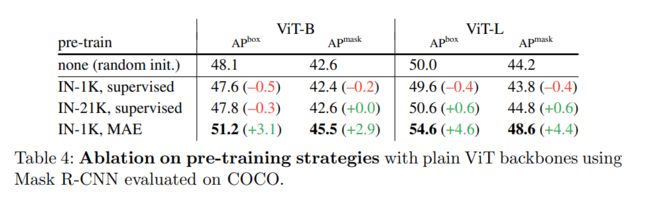
3、掩蔽自编码器可以提供强大的预训练主干。表 4 比较了主干预训练的策略。
与分层主干的对比
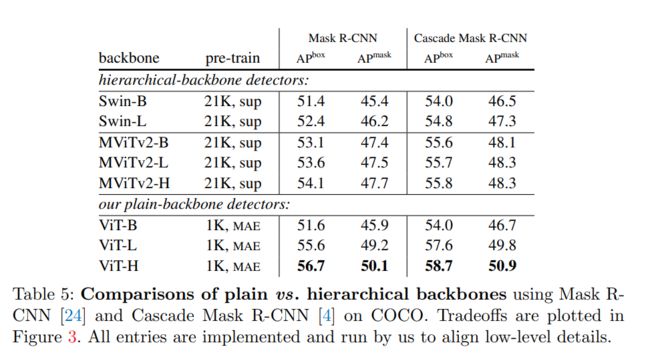
下表 5 显示了与分层主干网络的比较结果。
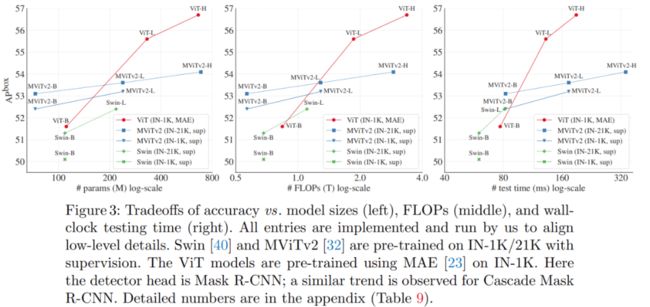
下图 3 显示了几种模型的准确率与模型尺寸、FLOPs 和测试时间三者的关系。
与之前系统的对比
下表 6 给出了几种方法在 COCO 数据集上的系统级比较结果。

编辑:王菁

