
背景
Alluxio 的数据引擎性能,并没有与 Trino 相关的性能为大数据引擎领域提供服务,为 S3、hdfs 等数据提供温暖的计算层,如 Hive、Spark、Spark 的集成,做大数据引擎的集成,做大数据引擎的集成加速是一个不可多得的功能组件。
Alluxio 社区与 Amazon EMR 服务有集成的辅助和集成,官方提供了 Amazon EMR 的集成方案,参见 Alluxio 社区文档,亚马逊云科技也提供了快速安装部署的引导脚本及,参见亚马逊云科技官方博客。
以上文档基于 emr 5.2x 版本,其 hive,Spark 等组件版本较旧,且没有考虑 EMR 的多主,Task 计算实例组的集成场景,在客户使用高版本 Amazon EMR,启用 HA 及 Task 计算的时候,安装其部署存在导致部署失败。
文档从整体架构作为切入架构,深入了解亚马逊 EMR 的集成架构,能够深入理解亚马逊 MR 集成的集成方法,同时更设计并集成了 Alluxio 在亚马逊 EMR 上的所有组件的集成方法,新增加了对 EMR 上更高的支持组的支持,新增加了对 EMR 客户支持的所有主客户的所有生产环境。
Alluxio 社区文档:
https://docs.alluxio.io/os/us...
亚马逊云科技官方博客:
https://aws.amazon.com/cn/blo...
Alluxio 架构概述
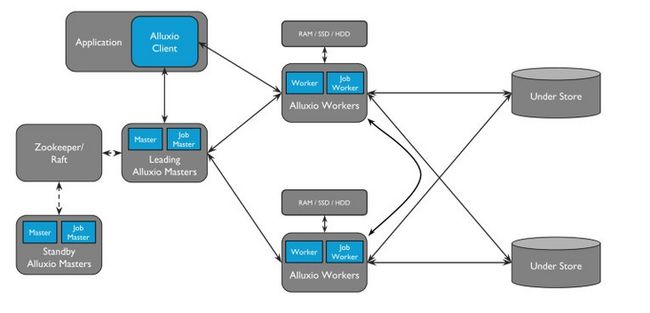
主要功能组件有:
Master节点:类似NN的设计,同样有standby Master(HA)和secondary Master(元数据镜像)概念, Jounary 日志随节点 master,做为快速恢复

Worker节点:与 DataNode 类似,缓存层,提供 Tier Storage(MEM,HDD 连接),短读和经常缓存,3种写缓存模式(仅内存,cache_通过可以同步和异步,通过不写缓存)

Job master & Job worker:类似缓存数据的整理,alluxio 提供了一个框架,由 job master 资源分配,job worker 执行数据的管道管道,缓存默认为1
Alluxio 的主要业务场景有:
- hdfs/S3 加速缓存,查询
- 多对象存储统一 UFS 路径
- 跨 bucket, hdfs 集群数据缓存
主要功能特点:
- 针对 hdfs, s3 多层的后端存储
- 写入,通过写入缓存,支持异步更新支持后端存储;读推送下压模式,缓存击穿缓存后直接读取后端存储
- ttl 缓存过渡时间配置
e.g:
alluxio.user.file.create.ttl = -1
alluxio.user.file.create.ttl.action = DELETE
alluxio.master.ttl.checker.interval = 1hour- Impersonal/Acl/SASL HDFS 类似的权限管控功能同样适用于 Alluxio
- 缓存同步与清理
e.g:
缓存清理:Alluxio rm -r -U alluxio:///
缓存同步:alluxio load alluxio:/// Amazon EMR 上的 Alluxio 集成
集成架构
Alluxio 在 Amazon EMR 上的架构如下所示:

如上图所示,Alluxio Master 组件作为管理模块,安装部署在 Amazon EMR 主实例组,如果需要 Alluxio HA 高可用,可以通过将 EMR 部署为多主,在 bootstrap 中打开 alluxio HA(-h) 的开关,部署部署脚本 Alluxio Master 部署到每个 EMR 主节点实例,并在 S3 目录以供 Alluxio 主节点故障转移时做 Raft 选举。
Alluxio Worker 上面的组件安装部署在 Amazon EMR 的核心及任务组中,由于任务实例组可能配置扩展,增加任务计算节点时 Alluxio 工作也会缩小,有时会造成客户节点的重新平衡,造成缓存节点性能层,因此提供了组所以对于任务实例是否安装部署 Alluxio,在引导脚本中也同样了开关 (-g)。
Alluxio tier storage 配置为 mem layer,UFS backend 配置为 S3 数据湖存储。
相应的 Alluxio job master、job worker 组件,以及 master、worker 节点同样的部署方式,部署安装在 EMR 主实例组和核心、任务实例组中。
集成步骤
下面详细介绍 Alluxio 在 Amazon EMR 上集成的实施步骤
- alluxio 官网下载社区版tar安装包(本文采用7.3 )
- 可以通过 Amazon cli 或者 emr 控制台,指定初始化配置 json 和 bootstrap 方式进行 EMR 上 alluxio 的集成安装和部署
- 亚马逊 emr cli 方式:
aws emr create-cluster \
--release-label emr-6.5.0 \
–instance-groups '[{"InstanceCount":2,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"SizeInGB":64,"VolumeType":"gp2″},"InstanceGroupType":"CORE","InstanceType":"m5.xlarge","Name":"Core-2″}, \
{"InstanceCount":1,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"SizeInGB":64,"VolumeType":"gp2″},"VolumesPerInstance":2}]},"InstanceGroupType":"MASTER","InstanceType":"m5.xlarge","Name":"Master-1″}]' \
--applications Name=Spark Name=Presto Name=Hive \
--name try-alluxio \
--bootstrap-actions \
Path=s3://xxxxxx.serverless-analytics/alluxiodemobucket/alluxio-emr.sh,\
Args=[s3://xxxxxx.serverless-analytics/alluxiodemobucket/data/,-d,"s3://xxxxxx.serverless-analytics/alluxiodemobucket/install/alluxio-2.7.3-bin.tar.gz",-p,"alluxio.user.block.size.bytes.default=122M|alluxio.user.file.writetype.default=CACHE_THROUGH",-s,"|"] \
--configurations s3://xxxxxx.serverless-analytics/alluxiodemobucket/ \
--ec2-attributes KeyName=ec203.pem- emr分析上方式:
boostrap初始化参数
s3://xxxxxx.serverless-analytics/alluxiodemobucket/data/ -d s3://xxxxxx.serverless-analytics/alluxiodemobucket/install/alluxio-2.7.3-bin.tar.gz -p alluxio.user。 block.size.bytes.default=122M|alluxio.user.file.writetype.default=CACHE_THROUGH -s |
boostrap初始化参数
s3://xxxxxx.serverless-analytics/alluxiodemobucket/data/ -d s3://xxxxxx.serverless-analytics/alluxiodemobucket/install/alluxio-2.7.3-bin.tar.gz -p alluxio.user.block.size.bytes.default=122M|alluxio.user.file.writetype.default=CACHE_THROUGH -s |
配置文件及boostrap脚本:
s3://xxxxxx.serverless-analytics/alluxiodemobucket/install:安装tar包
s3://xxxxxx.serverless-analytics/alluxiodemobucket/data:测试under store底层存储
s3://xxxxxx.serverless-analytics/alluxiodemobucket/*.sh|*.json : bootstrap脚本及initial 配置
初始化Alluxio json集群配置:
{"Classification":"presto-connector-hive","Properties":{"hive.force-local-scheduling":"true","hive.metastore":"glue","hive.s3-file-system-type":"PRESTO"}},{"Classification":"hadoop-env","Configurations":[{"Classification":"export","Properties":{"HADOOP_CLASSPATH":"/opt/alluxio/client/alluxio-client.jar:${HADOOP_CLASSPATH}"}}],"Properties":{}}Boostrap 启动脚本说明
- Bootstrap 主要完成 alluxio 集成步骤,包括解压 allioux tar 安装,等等待启动组件,然后解压修改 alluxio 配置文件,启动 alluxio 组件和组件进程
- Alluxio 社区官方提供了和 Amazon emr 的集成 boostrap,但只有 HA 没有扩展 27 ,高(例如:emr6.5)上组件组件表明会出现冲突,并且需要考虑任务节点不同实例的类型的版本,等场景,本方案将原先的脚本主要升级和优化为:Bootstrap 脚本在任务节点启动,因为找不到 DataNode 进程类型,官方脚本内没有判断任务,会等待循环实例
wait_for_hadoop func需要修改,如果是task,不再等待datanode进程,进入下一步骤
local -r is_task="false"
grep -i "instanceRole" /mnt/var/lib/info/job-flow-state.txt|grep -i task
if [ $? = "0" ];then
is_task="true"
fi- 如果不需要扩展 Task 实例上的 Alluxio worker,需要 boostrap 脚本中指定参数以便识别放过 Task 实例上的 alluxio 安装部署过程
e)ignore_task_node="true"
;;
if [[ "${ignore_task_node}" = "true" ]]; then
"don't install alluxio on task node, boostrap exit!"
exit 0
fi- 没有支持HA的bootstrap脚本,需要在bootstrap里面判断多个master节点并默认启动standby alluxio master。这里采用嵌入式 JN 节点的形式,不占用 EMR 上 Zookeeper 的资源:Alluxio HA 模式下任务列表节点需要增加 HA rpc 访问地址
if [[ "${ha_mode}" = "true" ]]; then
namenodes=$(xmllint --xpath "/configuration/property[name='${namenode_prop}']/value/text()" "${ALLUXIO_HOME}/conf/hdfs-site.xml")
alluxio_journal_addre=""
alluxio_rpc_addre=""
for namenode in ${namenodes//,/ }; do
if [[ "${alluxio_rpc_addre}" != "" ]]; then
alluxio_rpc_addre=$alluxio_rpc_addre","
alluxio_journal_addre=$alluxio_journal_addre","
fi
alluxio_rpc_addre=$alluxio_rpc_addre"${namenode}:19998"
alluxio_journal_addre=$alluxio_journal_addre"${namenode}:19200"
done
set_alluxio_property alluxio.master.rpc.addresses $alluxio_rpc_addre
fi验证 Alluxio 的工作原理
EMR 启动,会自动拉起 Alluxio 的管理员,工人进程,Alluxio 的管理员 29999 等端口的信息管理控制台上,可以方便的查看到集群的状态及后容量、UFS 的能力
Alluxio 控制台


计算框架集成
create external table s3_test1 (userid INT,
age INT,
gender CHAR(1),
occupation STRING,
zipcode STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
LOCATION 's3://xxxxxx.serverless-analytics/alluxiodemobucket/data/s3_test1'
Hive alluxio读写
0: jdbc:hive2://xx.xx.xx.xx:10000/default> shwo create table alluxiodb.test1;
| createtab_stmt |
+----------------------------------------------------+
| CREATE EXTERNAL TABLE `alluxiodb.test1`( |
| `userid` int, |
| `age` int, |
| `gender` char(1), |
| `occupation` string, |
| `zipcode` string) |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' |
| WITH SERDEPROPERTIES ( |
| 'field.delim'='|', |
| 'serialization.format'='|') |
| STORED AS INPUTFORMAT |
| 'org.apache.hadoop.mapred.TextInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' |
| LOCATION |
| 'alluxio:/testTable' |
| TBLPROPERTIES ( |
| 'bucketing_version'='2') |
+----------------------------------------------------+
0: jdbc:hive2://xx.xx.xx.xx:10000/default>INSERT INTO alluxiodb.test1 VALUES (2, 24, 'F', 'Developer', '12345');
0: jdbc:hive2://xx.xx.xx.xx:10000/default> select * from test1;
--+
| test1.userid | test1.age | test1.gender | test1.occupation | test1.zipcode |
+---------------+------------+---------------+-------------------+----------------+
| 1 | 24 | F | Developer | 12345 |
| 4 | 46 | F | Developer | 12345 |
| 5 | 56 | A | Developer | 12345 |
| 2 | 224 | F | Developer | 12345
Trino alluxio query:
trino:alluxiodb> select * from test1;
userid | age | gender | occupation | zipcode
--------+-----+--------+------------+---------
1 | 24 | F | Developer | 12345
2 | 224 | F | Developer | 12345
Spark alluxio读写
>>> spark.sql("insert into alluxiodb.test1 values (3,33,'T','Admin','222222')")
>>> spark.sql("select * from alluxiodb.test1").show(1000,False) +------+---+------+----------+-------+
|userid|age|gender|occupation|zipcode|
+------+---+------+----------+-------+
|2 |224|F |Developer |12345 |
|3 |33 |T |Admin |222222 |
|1 |24 |F |Developer |12345 |
+------+---+------+----------+-------+基准测试
采用 hive tpcds benchmark 生成并加载测试数据,可以方便的对比通过 s3 路径和 alluxio 缓存路径应用场景下性能查询。
- alluxio hive 基准测试结果:
hive -i testbench_alluxio.settings
hive> use tpcds_bin_partitioned_orc_30;
hive> source query55.sql;
+-----------+------------------------+---------------------+
| brand_id | brand | ext_price |
+-----------+------------------------+---------------------+
| 2002002 | importoimporto #2 | 328158.27 |
| 4004002 | edu packedu pack #2 | 278740.06999999995 |
| 2004002 | edu packimporto #2 | 243453.09999999998 |
| 2001002 | amalgimporto #2 | 226828.09000000003 |
| 4003002 | exportiedu pack #2 | 194363.72000000003 |
| 5004002 | edu packscholar #2 | 178895.29000000004 |
| 5003002 | exportischolar #2 | 158463.69 |
| 3003002 | exportiexporti #2 | 126980.51999999999 |
| 4001002 | amalgedu pack #2 | 107703.01000000001 |
| 5002002 | importoscholar #2 | 104491.46000000002 |
| 3002002 | importoexporti #2 | 87758.88 |
| 8010006 | univmaxi #6 | 87110.54999999999 |
| 10004013 | edu packunivamalg #13 | 76879.23 |
| 8008006 | namelessnameless #6 | 74991.82 |
| 6010006 | univbrand #6 | 72163.57 |
| 7006008 | corpbrand #8 | 71066.42 |
| 2003002 | exportiimporto #2 | 69029.02 |
| 6015006 | scholarbrand #6 | 66395.84 |
| 4002002 | importoedu pack #2 | 65223.01999999999 |
| 8013002 | exportimaxi #2 | 63271.69 |
| 9007002 | brandmaxi #2 | 61539.36000000001 |
| 3001001 | edu packscholar #2 | 60449.65 |
| 10003014 | exportiunivamalg #14 | 56505.57000000001 |
| 3001001 | exportiexporti #2 | 55458.64 |
| 7015004 | scholarnameless #4 | 55006.78999999999 |
| 5002001 | exportischolar #2 | 54996.270000000004 |
| 6014008 | edu packbrand #8 | 54793.31999999999 |
| 4003001 | amalgcorp #8 | 53875.51000000001 |
| 8011006 | amalgmaxi #6 | 52845.8 |
| 1002002 | importoamalg #2 | 52328.259999999995 |
| 2003001 | maxinameless #6 | 50577.89 |
| 9016008 | corpunivamalg #8 | 49700.12 |
| 7015006 | scholarnameless #6 | 49592.7 |
| 9005004 | scholarmaxi #4 | 49205.19 |
| 4003001 | exportiimporto #2 | 48604.97 |
| 2002001 | edu packamalg #2 | 48451.979999999996 |
| 9012002 | importounivamalg #2 | 48429.990000000005 |
| 7012004 | importonameless #4 | 48303.979999999996 |
| 10009004 | edu packamalg #2 | 48301.05 |
| 1004001 | amalgexporti #2 | 48215.880000000005 |
| 1001002 | amalgamalg #2 | 47018.94 |
| 9015010 | scholarunivamalg #10 | 46495.380000000005 |
| 6005007 | importobrand #6 | 46233.630000000005 |
| 9010004 | univunivamalg #4 | 46164.04 |
| 8015006 | scholarmaxi #6 | 46143.41 |
| 7016002 | corpnameless #2 | 46133.31 |
| 10006011 | corpunivamalg #11 | 46085.81 |
| 9001003 | importoamalg #2 | 45303.18 |
| 10015011 | scholarnameless #2 | 45299.06 |
| 5002001 | importoexporti #2 | 44757.73000000001 |
| 10010004 | univamalgamalg #4 | 43347.899999999994 |
| 2004001 | importoamalg #2 | 43127.46000000001 |
| 9002011 | edu packcorp #8 | 41740.42 |
| 10008009 | namelessunivamalg #9 | 41369.479999999996 |
| 8002010 | importonameless #10 | 41046.02 |
| 6002008 | importocorp #8 | 40795.42999999999 |
| 7007010 | brandbrand #10 | 40591.95 |
| 6012002 | importobrand #2 | 40545.72 |
| 2003001 | amalgexporti #2 | 39679.76 |
| 8005007 | exportischolar #2 | 39593.39 |
| 9015011 | importoscholar #2 | 39419.41 |
| 9005012 | scholarmaxi #12 | 39151.020000000004 |
| 9016012 | corpunivamalg #12 | 39117.53 |
| 5003001 | exportiexporti #2 | 39061.0 |
| 9002002 | importomaxi #2 | 38763.61 |
| 6010004 | univbrand #4 | 38375.29 |
| 8016009 | edu packamalg #2 | 37759.44 |
| 8003010 | exportinameless #10 | 37605.38 |
| 10010013 | univamalgamalg #13 | 37567.33 |
| 4003001 | importoexporti #2 | 37455.68 |
| 4001001 | importoedu pack #2 | 36809.149999999994 |
| 8006003 | edu packimporto #2 | 36687.04 |
| 6004004 | edu packcorp #4 | 36384.1 |
| 5004001 | scholarbrand #8 | 36258.58 |
| 10006004 | importonameless #10 | 36226.62 |
| 2002001 | scholarbrand #4 | 36138.93 |
| 7001010 | amalgbrand #10 | 35986.36 |
| 8015005 | edu packunivamalg #4 | 35956.33 |
| 10014008 | edu packamalgamalg #8 | 35371.05 |
| 7004005 | amalgamalg #2 | 35265.32 |
| 6016004 | corpbrand #4 | 35256.990000000005 |
| 4002001 | amalgedu pack #2 | 35183.9 |
+-----------+------------------------+---------------------+- s3 hive 基准测试结果:
hive -i testbench_s3.settings
hive> use tpcds_bin_partitioned_orc_30;
hive> source query55.sql;
+-----------+------------------------+---------------------+
| brand_id | brand | ext_price |
+-----------+------------------------+---------------------+
| 4003002 | exportiedu pack #2 | 324254.89 |
| 4004002 | edu packedu pack #2 | 241747.01000000004 |
| 2004002 | edu packimporto #2 | 214636.82999999996 |
| 3003002 | exportiexporti #2 | 158815.92 |
| 2002002 | importoimporto #2 | 126878.37000000002 |
| 2001002 | amalgimporto #2 | 123531.46 |
| 4001002 | amalgedu pack #2 | 114080.09000000003 |
| 5003002 | exportischolar #2 | 103824.98000000001 |
| 5004002 | edu packscholar #2 | 97543.4 |
| 3002002 | importoexporti #2 | 90002.6 |
| 6010006 | univbrand #6 | 72953.48000000001 |
| 6015006 | scholarbrand #6 | 67252.34000000001 |
| 7001010 | amalgbrand #10 | 60368.53 |
| 4002001 | amalgmaxi #12 | 59648.09 |
| 5002002 | importoscholar #2 | 59202.14 |
| 9007008 | brandmaxi #8 | 57989.22 |
| 2003002 | exportiimporto #2 | 57869.27 |
| 1002002 | importoamalg #2 | 57119.29000000001 |
| 3001001 | exportiexporti #2 | 56381.43 |
| 7010004 | univnameless #4 | 55796.41 |
| 4002002 | importoedu pack #2 | 55696.91 |
| 8001010 | amalgnameless #10 | 54025.19 |
| 9016012 | corpunivamalg #12 | 53992.149999999994 |
| 5002001 | exportischolar #2 | 53784.57000000001 |
| 4003001 | amalgcorp #8 | 52727.09 |
| 9001002 | amalgmaxi #2 | 52115.3 |
| 1002001 | amalgnameless #2 | 51994.130000000005 |
| 8003010 | exportinameless #10 | 51100.64 |
| 9003009 | edu packamalg #2 | 50413.2 |
| 10007003 | scholarbrand #6 | 50027.27 |
| 7006008 | corpbrand #8 | 49443.380000000005 |
| 9016010 | corpunivamalg #10 | 49181.66000000001 |
| 9005010 | scholarmaxi #10 | 49019.619999999995 |
| 4001001 | importoedu pack #2 | 47280.47 |
| 4004001 | amalgcorp #2 | 46830.21000000001 |
| 10007011 | brandunivamalg #11 | 46815.659999999996 |
| 9003008 | exportimaxi #8 | 46731.72 |
| 1003001 | amalgnameless #2 | 46250.08 |
| 8010006 | univmaxi #6 | 45460.4 |
| 8013002 | exportimaxi #2 | 44836.49 |
| 5004001 | scholarbrand #8 | 43770.06 |
| 10006011 | corpunivamalg #11 | 43461.3 |
| 2002001 | edu packamalg #2 | 42729.89 |
| 6016001 | importoamalg #2 | 42298.35999999999 |
| 5003001 | univunivamalg #4 | 42290.45 |
| 7004002 | edu packbrand #2 | 42222.060000000005 |
| 6009004 | maxicorp #4 | 42131.72 |
| 2002001 | importoexporti #2 | 41864.04 |
| 8006006 | corpnameless #6 | 41825.83 |
| 10008009 | namelessunivamalg #9 | 40665.31 |
| 4003001 | univbrand #2 | 40330.67 |
| 7016002 | corpnameless #2 | 40026.4 |
| 2004001 | corpmaxi #8 | 38924.82 |
| 7009001 | amalgedu pack #2 | 38711.04 |
| 6013004 | exportibrand #4 | 38703.41 |
| 8002010 | importonameless #10 | 38438.670000000006 |
| 9010004 | univunivamalg #4 | 38294.21 |
| 2004001 | importoimporto #2 | 37814.93 |
| 9010002 | univunivamalg #2 | 37780.55 |
| 3003001 | amalgexporti #2 | 37501.25 |
| 8014006 | edu packmaxi #6 | 35914.21000000001 |
| 8011006 | amalgmaxi #6 | 35302.51 |
| 8013007 | amalgcorp #4 | 34994.01 |
| 7003006 | exportibrand #6 | 34596.55 |
| 6009006 | maxicorp #6 | 44116.12 |
| 8002004 | importonameless #4 | 43876.82000000001 |
| 8001008 | amalgnameless #8 | 43666.869999999995 |
| 7002006 | importobrand #6 | 43574.33 |
| 7013008 | exportinameless #8 | 43497.73 |
| 6014008 | edu packbrand #8 | 43381.46 |
| 10014007 | edu packamalgamalg #7 | 42982.090000000004 |
| 9006004 | corpmaxi #4 | 42437.49 |
| 9016008 | corpunivamalg #8 | 41782.0 |
| 10006015 | amalgamalg #2 | 31716.129999999997 |
| 2003001 | univnameless #4 | 31491.340000000004 |
+-----------+------------------------+----------可以看到平均任务的 QPS 提升30%~40%左右,部分任务提升50%以上。
参考资料
Amazon EMR 上的 Alluxio 安装部署:
https://aws.amazon.com/cn/blo...
Alluxio 社区 EMR 集成指南:
https://docs.alluxio.io/os/us...
亚马逊 EMR 群:
https://docs.aws.amazon.com/z...
小结
本文详细介绍了在 alluxio上alluxio 集群启动安装的部署,脚本及 EMR 集群初始化 json 配置,并通过开启 Alluxio tpcds 标准基准,比较了开启 Alluxio 的 EMR 集群上 hive sql 查询的提升性能。
本文作者
唐清原
亚马逊云科技数据分析解决方案架构师,负责亚马逊数据分析服务方案文化架构设计以及性能优化,迁移,治理等深潜支持。10+数据领域研发及架构设计经验,历任Oracle高级顾问顾问,咪咕数据集市高级架构师,澳州数据分析领域架构师职务。在银行大数据,新智能湖等项目有丰富实战经验。
陈昊
解决从架构师、亚马逊云经验合作方案的主要合作方案)20年的IT行业经验,在企业开发、架构设计及建设方面具有丰富的实践经验。和设计工作,推动亚马逊云服务的应用推广以及帮助合作伙伴在国内制造更高效的亚马逊云服务解决方案。
