MySQL中SQL语句——DML(数据操作语言)和DDL(数据定义语言)
前言: 上一篇博客,博主主要对于SQL语句中DQL语言做了一些了解,大家肯定对于mysql有了一定的认识。这篇博客则主要讲解一下DML语言和DDL语言,希望可以有所帮助。
如果还没看过DQL语言的大佬们,可以先去看看博主上一篇:
上一篇博客:MySQL中SQL语句——DQL(数据查询语句)
1.DML语言(数据操作语言)
说明: 数据操纵语言(Data Manipulation Language, DML)是用于数据库操作,对数据库其中的对象和数据运行访问工作的编程语句。就是对于数据进行增删改查。
数据操作语言相关的关键字:
- 插入: insert
- 修改: update
- 删除: delete
一、插入语句()
(经典且推荐)方式一:
语法:
insert into 表名(列名,...) vlaues(值1,...)
特点:
1.插入的值的类型要与列的类型一致或兼容
2.不可以为null的列必须插入值,可以为null的列可以不插入:
方式一:在values()中用null代替值
方式二:在列名处不添加该列名
3.列的顺序可以调换
4.列数和值的个数必须一致(⭐)
5.可以省略列名,默认所有列,而且列的顺序和表中列的顺序一致
6.支持子查询
案例:一次性插入多条数据
第一种通过子查询:
INSERT into 表(列名...)
select 值,值,... union
值,值,... union
值,值,... ;
第二种经典查询:
INSERT into 表
values(值1,...),(值2,...),(值3,...);
方式二:
语法:
insert into 表名
set 列名=值,列名=值…;
二、修改语句
1.修改单表的记录
语法:
update 表名
set 列=新值,列=新值....
where 筛选条件
2.修改多表的记录(支持92和99标准)
语法:
sql92语法:
update 表1 别名,表2 别名
set 列=新值....
where 连接条件
and 筛选条件;
sql99语法:
update 表1 别名
inner|left|right join 表2 别名
on 连接条件
set 列=值,....
where 筛选条件;
三、删除语句
方式一:delete
语法:
(重点掌握)1.单表的删除
delete from 表名 [where 筛选条件 limit 条目数]
2.多表的删除
sql92语法:
delete 需要删除的表的别名(表与表之间逗号隔开)
from 表1 别名,表2 别名
where 连接条件
and 筛选条件;
sql99语法(推荐):
delete 需要删除的表的别名(表与表之间逗号隔开)
from 表1 别名
inner|left|right join 表2 别名
on 连接条件
where 筛选条件;
方式二: truncate(不能加where,通常用于清空表的数据)
语法:
truncate table 表名;
truncate 和 delete 使用区别(面试题⭐):
1.delete 可以加wwhere,truncate不能加
2.truncate删除效率高一点
3.当要删除的表中有自增长列,使用delete删除后,再插入数据,自增长列的值会从断点的值开始;
使用truncate 删除后,则会自增长则会从基础值开始;
4.truncate没有返回值,delete删除有返回值;
5.truncate 删除不能回滚,delete删除可以回滚(在事务的知识点);
2.DDL(数据定义语言)
说明: 数据库模式定义语言DDL(Data Definition Language),是用于描述数据库中要存储的现实世界实体的语言。
常见的DDL语句:
创建数据库CREATE DATABASE、创建数据库表格CREATE TABLE、修改数据库表格ALTER TABLE、删除数据库表格DROP TABLE、创建查询命令CREATE VIEW、修改查询命令ALTER VIEW、删除查询命令DROP VIEW。
相关关键字:
- 创建:create
- 修改:alter
- 删除:drop
一、库的管理(操作后需刷新)
1.库的创建:
语法:create database [if not exists(用于判断是否存在该库名)] 库名
2.库的修改(不建议修改库,容易导致数据混乱丢失):
若修改,建议找到该库的文件名,进行修改文件名(注意修改时,需关闭服务端)
补充:
修改库的字符集
alter database 库名 character set 字符集;
3.库的删除:
语法: drop database [if exists] 库名;
二、表的管理
1.表的创建:
语法:
create table [if not exists] 表名(
列名 列的类型[(显示长度) 约束],
列名 列的类型[(显示长度) 约束],
.......
列名 列的类型[(显示长度) 约束],
列名 列的类型[(显示长度) 约束]
)
案例:创建一个book表
create table if not exists book(
id int,#图书编号
Bname varchar(10),#图书名称
author varchar(10) #作者
)
2.表的修改:
①修改列名
语法: alter table 表 change (column) 现列名 修改列名 列的类型
②修改列的类型或约束
语法: alter table 表 modify column 列名 类型|约束;
③添加新列
语法: alter table 表 add column 新列名 类型 [first|after 列名(可以控制放的位置)];
④删除列
语法: alter table 表 drop column 列名;
⑤修改表名
语法:alter table 现表名 rename to 修改表名;
3.表的删除:
语法:
drop table [if exists] 表;
4.表的复制:
①复制表的结构
语法:create table 复制的表 like 被复制的表
②复制表的结构和数据
语法:create table 复制的表
select 列,列... from 表
[where 筛选条件]
③仅仅复制某些字段
语法:create table 复制的表
select 列,列... from 表
where 0;
补充知识点
1.常见数据类型
一、整型
分类:
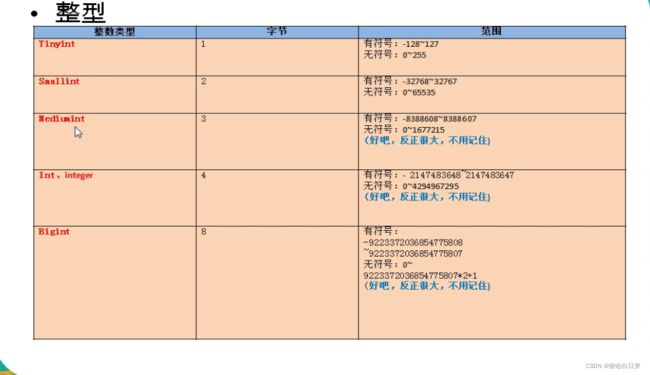
特点:
①如果不设置无符号号还是有符号,默认为有符号,如果想设置无符号,需要添加unsigned关键字;
②如果插入的数值超过整型的范围,会报出out of rang异常,并返回的是临界值;
③如果不设置长度,会有默认长度
长度代表的是显示的最大宽度,如果不够会用0在左边填充,必须搭配zerofill使用!!
案例:设置无符号和符号
create table 表(
id int(长度) , zerofill(使用zerofill的话只能是有符号)
id1 int(长度) unsigned(无符号)
)
二、小数
分类:
浮点数:float (M,D), double(M,D)
(精确度较高)定点数:DEC(M,D)/DECIMAL(M,D)
特点:
①M代表的是整数部位位数+小数部位位数,D代表的是小数部位位数
如果超出范围,则返回临界值;
②M,D都可以省略
如果是定点型,则默认为(10,0);
③定点型精确度较高,在插入要求精确度较高时则考虑定点型,如货币等;
三、浮点型
分类:
(较短的文本)字符串类型:
M的意思 特点 空间耗费 效率
char(M) 最长的字符长度,可以省略,默认为1 char是不可变的 比较耗费 较高
varchar(M) 最长的字符长度,不可以省略 varchar是可变的 比较节省 较低
其他类型:
bit(M)位类型
binary和varbinary包含较短的二进制字符串,类似于char和varchar;
enum用于保存枚举类型,不区分大小写,且保存一次只一个;
set用于保存集合,不区分大小写,且保存是可以保存多个;
较长的文本:
text
blob(保存较长的二进制数据)
四、日期类型
分类:
data只保存日期;
time只保存时间;
year只保存年;
datetime 保存日期+时间;
timestamp 保存日期+时间;
两者区别:
字节 范围 时区,语法模式、版本的影响
datetime 保存日期+时间 8 1000-9999 不受
timestamp 保存日期+时间 4 1970-2038 受,更能反映当前时区的时间
2.常见约束
含义:一种限制,用于限制表中的数据,为了保证表中的数据的准确性和可靠性;
分类:
NOT NULL: 非空(用于保证该字段的值不能为空);
DEFAULT: 默认(用于保证该字段有默认值);
PRIMARY KEY: 主键(用于保证该字段的值唯一性且非空);
UNIOUE: 唯一(用于保证该字段的值唯一,可以为空);
CHECK: 检查约束(mysql中不支持,没有效果);
FOREIGN KEY: 外键(用于限制两个表的关系,保证该字段的值必须来自于主表的关联列的值),在从表添加外键约束,用于引用主表的某列的值;
添加约束的时机:
1.创建表时
2.修改表时
要求:都需要在添加数据前
添加约束的分类:
列级约束:
约束都支持,但外键约束没有效果
表级约束
除了非空、默认,其他都支持
主键与唯一的区别:
共同点:1.都保证了唯一性 2.都允许组合(两个列组合为主键或者唯一),但都不推荐。
不同点:1.主键不能为空,唯一可以 2.主键一个表只能至多有一个,唯一可以有多个。
外键的特点:
1.要求在从表中设置外键关系;
2.从表外键列的类型和主表的关联列的类型要求一直或兼容;
3.要求主表的关联列必须是一个key(一般是主键(主要)或唯一);
4.插入数据时,先插入主表数据,再是从表
删除数据时,先删除从表,再是主表;
1.添加表级约束
语法:在各个字段的最下面
constraint 约束名 约束类型(字段名);
2.添加列级约束
语法:
直接在字段名和类型后面追加 约束类型即可
只支持:默认、非空、主键、唯一、检查(mysql不支持);
语法:
create teble 表名(
字段名 字段类型 列级约束,
字段名 字段类型 列级约束,
....
表级约束
);
一、创建表时添加约束
案例:创建一个stuinfo表
通用写法:
drop table stuinfo; #在创建表前可以先删除表操作
create table if not exists stuinfo(
id int primary key,#主键
stuName varchar(20) not null,#非空
gender char(1) check(gender='男' or gender='女'),#检查
seat int unique,#唯一
age int default 18,#默认约束,列是什么类型,约束就是什么类型
majorId int ,
constraint fk_stuinfo_major foreign key(majorId) references major(id)#外键
);
create table major(
id int primary key,
majorName varchar(10)
);
DESC stuinfo;#用于查询表的结构
show index from stuinfo;#用于查看表中所有的索引,包括主键、外键、唯一
二、修改表时添加约束
1.添加列级约束
alter table 表名 modify column 字段名 字段类型 新约束;
2.添加表级约束
alter table 表名 add [constraint 约束名] 约束类型(字段名) [外键的引用];
三、修改表时删除约束
#1.删除非空约束
alter table 表 modify column 字段名 字段类型 null;
#2.删除默认约束
alter table 表 modify column 字段名 字段类型;
#3.删除主键
alter table 表 drop primary key;
#4.删除唯一
alter table 表 drop index 约束名;
#5.删除外键
alter table 表 drop foreign key 约束名;
标识列(又称为自增长列)
含义: 可以不用手动的插入值,系统提供默认的序列值。
关键字: auto_increment
特点:
1.标识列必须跟一个key(键)搭配;
2.一个表中可以有至多一个;
3.标识列的类型只能是数值型;
4.标识列可以通过set auto_increment_increment=数值类型(设置步长)
则初始值可以手动插入值来设置初始值;
一、创建表时添加标识列
create teble 表名(
字段名 字段类型 列级约束 auto_increment,
字段名 字段类型 列级约束,
....
表级约束
)
二、修改表时设置标识列
alter table 表 modify column 字段名 字段类型 约束类型 auto_increment;
三、修改表时删除标识列
alter table 表 modify column 字段名 字段类型 ;
选择类型原则:
原则:所选择类型越简单越好,能保存的数值的类型越小越好。