机器学习之文本挖掘—基于R语言
机器学习之文本挖掘—基于R语言
- 文本挖掘框架与方法
-
- LDA模型
- 实战分析
-
- 1.数据理解与准备
- 2.模型构建与模型评价
-
- 1.词频分析与主题模型
文本挖掘框架与方法
- 将大写字母转化为小写字母
- 删除数字
- 删除标点符号
- 剔除停用词
- 词干提取
- 词语替换
LDA模型
LDA是一个生成式过程,他按照下面的步骤进行迭代,直到达到一个平稳状态
- 1.如果有1~ j个文档,1~k个主题,那么对每个文档(j)使用一个多项式分布(狄利克雷分布)将其随机分配给各个主题(k)。例如,文档A分配给主题1的概率是25%,分配给主题2的概率是25%,分配给主题3的概率是50%。
- 2 .如果有1~j个词,那么每个词都以某个概率属于某个主题(k),例如:词mean以0.25的概率属于主题statistics。
- 3 .对于文档j和主题k中的每一个词i,计算该文档中的词分配给该主题的比例,记为主题(k)在文档(j)的概率P(k|j)。再从包含该词的文档中计算该词(i)在主题(k)中的比例,记为词(i)属于主题(k)的概率P(i|k)
-
- 重新抽样,即基于r属于w的概率为w分配一个新的t,此处的基准概率为P(k|j)×P(i|k)
-
- 重复这个过程,经过多次迭代,算法最终会收敛
实战分析
1.数据理解与准备
我们使用的基础软件包是tm,这是专门的文本挖掘软件包。还需要SnowballC包进行词干提取,使用RColorBrewer包进行上色,当然还有wordcloud包
install.packages("tm")
install.packages("wordcloud")
install.packages("RColorBrewer")
library(tm)
library(wordcloud)
library(RColorBrewer)
数据文件的下载地址
或者使用百度网盘下载:链接:
提取码:99o4
别忘了把文件放在工作路径下
getwd()
name <- file.path("E:/r1/text")
dir(name)
这里的text是一个单独的文件夹
将语法资料库命名为docs,并使用Corpus()函数建立语料库。函数包装了DirSource函数,他是tm包的一部分
docs <- Corpus(DirSource(name))
现在,使用tm包中的tm_map函数进行文本转换
docs <- tm_map(docs,tolower)#小写
docs <- tm_map(docs,removeNumbers)#去掉数字
docs <- tm_map(docs,removePunctuation)#去掉标点符号
docs <- tm_map(docs,removeWords,stopwords("english"))#剔除停用词
docs <- tm_map(docs,stripWhitespace)#删除空白字符
此时,应该删除不必要的词。例如,在演讲过程中,当国会议员对于某个部分鼓掌欢呼的时候,文本中就会出现(Applause),这是必须要删除的:
docs <- tm_map(docs,removeWords,c("applause","can","cant","will",
"that","weve","dont","wont","youll","youre"))
结束文本和冗余词后,请确认文档还是纯文本形式,然后将其放入文档—词矩阵并查看维度:
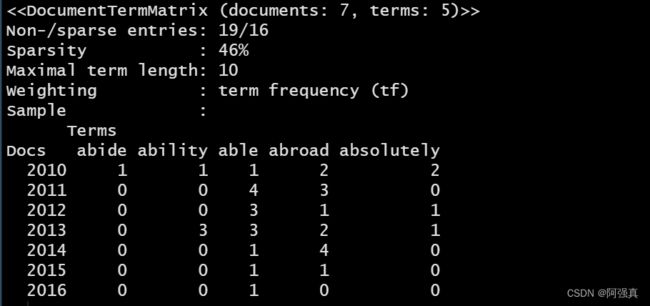
dtm <- DocumentTermMatrix(docs)
dim(dtm)
rownames(dtm) <- c("2010","2011","2012","2013","2014","2015","2016")
inspect(dtm[1:7,1:5])
2.模型构建与模型评价
1.词频分析与主题模型
首先建立一个对象,计算每列综合,然后按照降序重新排列。要计算每列总合,要在代码中使用as.matrix函数。默认的排序方式是升序,所以在freq前面加一个负号就变成了降序
freq <- colSums(as.matrix(dtm))
ord <- order(-freq)
freq[head(ord)]
freq[tail(ord)]

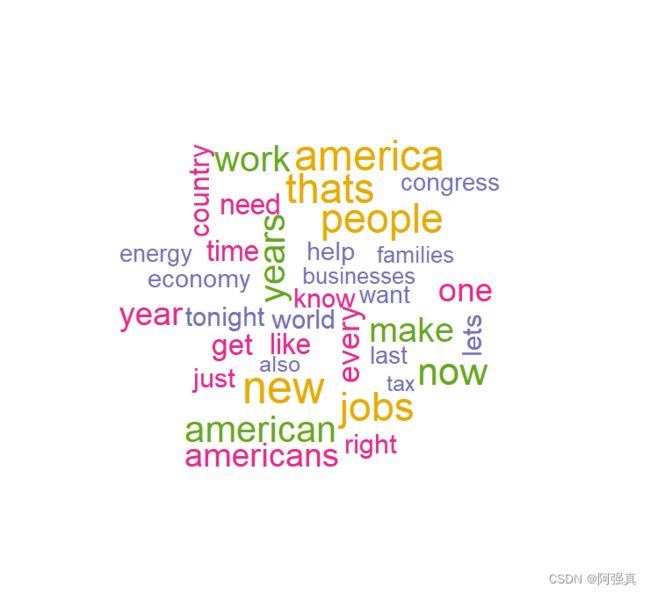
生成词云:
wordcloud(names(freq),freq,min.freq = 70,scale=c(3,0.5),
colors = brewer.pal(6,"Dark2"))
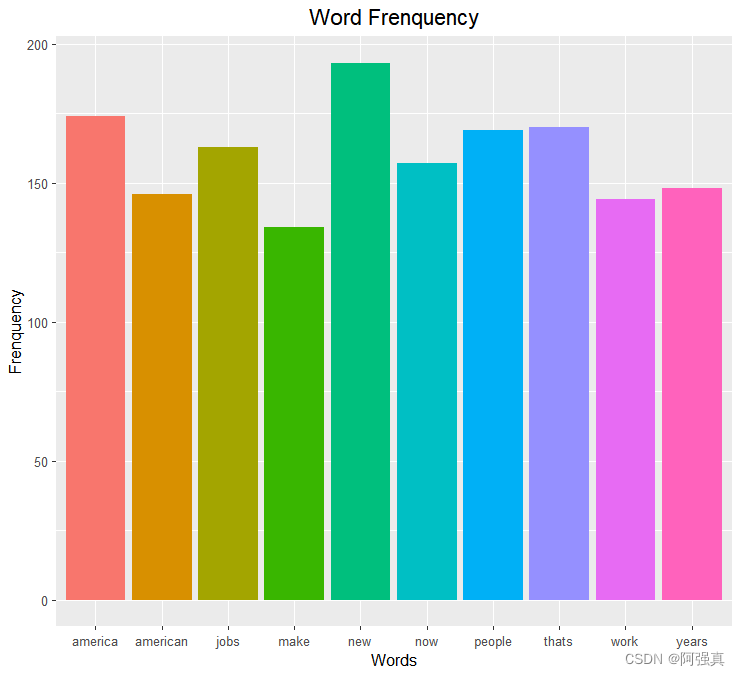
生成条形图:
这里提供了两种方式
gg <- data.frame(freq[head(ord,10)])
colnames(gg) <-" Frequency"
x <- rownames(gg);x
y <- gg[,1]
library(ggplot2)
ggplot(gg)+geom_col(aes(x,y,fill=x))+
labs(x="Words",y="Frenquency",title="Word Frenquency")+
theme(plot.title = element_text(hjust = 0.5,size=15),
legend.position = "none")
ggplot(gg,aes(x,y,fill=x))+geom_bar(stat="identity")
下面使用topicmodels包建立主题模型,这个包提供了LDA函数。问题在于建立多少个主题,看上去3个比较合适,当然也可以尝试其他的:
install.packages("topicmodels")#如果安装失败则按照下面的方法
#先安装pacman包
library(pacman)
p_install("topicmodels")
library(topicmodels)
lda <- LDA(dtm,k=3,method="Gibbs")
topics(lda)
terms(lda,25)
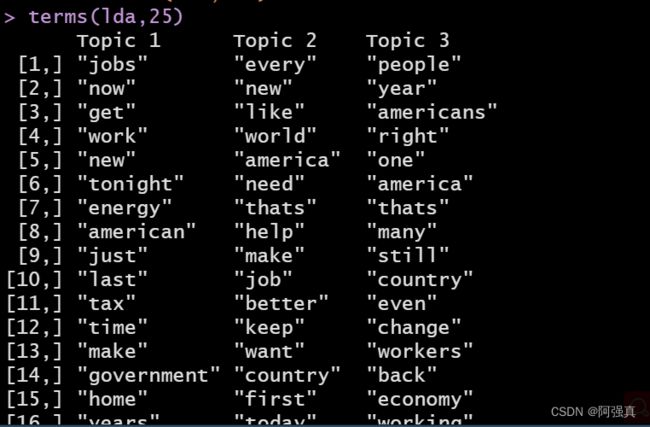
不难发现这些主题都是关于经济和商业的,可以由job,energy,reform和dificit这些词看出