人工智能大作业
人工智能作业
- 人工智能大作业——讨论手写数字识别的几种实现方法
-
- 一、实验目的
- 二、实验环境
- 三、实验原理
-
- 3.1 线性判别(fisher判别)[^1]
- 3.2 集成学习[^2]
-
- 3.2.1 Bagging
-
- random forest
- 3.2.2 Boosting
-
- adaboost
- 四、实验步骤
-
- 4.1 线性判别
- 4.2 adaboost
- 五、实验结果
- 参考文献
项目github地址链接
人工智能大作业——讨论手写数字识别的几种实现方法
一、实验目的
用多种机器学习方法实现手写数字识别,并比较不同。
二、实验环境
2.1 Python 3.7.6
2.2 Anaconda Spyder IDE
三、实验原理
3.1 线性判别(fisher判别)1
给定训练样本集,设法将样例投影到一条直线上,是的同类样例的投影点尽可能接近、异类样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的这条直线上,再根据投影点的位置来确定新样本的类别。
给定数据集 D = { ( x i , y i ) } i = 1 m , y i ∈ { 0 , 1 } D=\{(\boldsymbol x_i,y_i)\}_{i=1}^m,y_i \in \{0,1\} D={(xi,yi)}i=1m,yi∈{0,1},令 X i X_i Xi、 μ i \boldsymbol \mu_i μi、 Σ i \boldsymbol \Sigma_i Σi分别表示第 i ∈ { 0 , 1 } i \in \{0,1\} i∈{0,1}类示例的集合、均值向量、协方差矩阵。若将数据投影到直线 w \boldsymbol w w上,则两类样本的中心在直线上的投影分别为 w T μ 0 \boldsymbol w^T\mu_0 wTμ0和 w T μ 1 \boldsymbol w^T\mu_1 wTμ1;若将所有样本点都投影到直线上,则两类样本的协方差分布为 w T Σ 0 w \boldsymbol w^T\boldsymbol\Sigma_0\boldsymbol w wTΣ0w和 w T Σ 1 w \boldsymbol w^T\boldsymbol\Sigma_1\boldsymbol w wTΣ1w。
欲使同类样例的投影尽可能接近,可以让同类样例投影点的协方差尽可能小,即 w T Σ 0 w + w T Σ 1 w \boldsymbol w^T\boldsymbol\Sigma_0\boldsymbol w+\boldsymbol w^T\boldsymbol\Sigma_1\boldsymbol w wTΣ0w+wTΣ1w尽可能小;而欲使异类样例的投影点尽可能远离,可以让类中心之间的距离尽可能大,即 ∥ w T μ 0 − w T μ 1 ∥ 2 2 \| \boldsymbol w^T\boldsymbol\mu_0-\boldsymbol w^T\boldsymbol\mu_1\|_2^2 ∥wTμ0−wTμ1∥22尽可能大。同时考虑二者,则可得到最大化目标
J = ∥ w T μ 0 − w T μ 1 ∥ 2 2 w T Σ 0 w + w T Σ 1 w = w T ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T w w T ( Σ 0 + Σ 1 ) w . (1) \begin{aligned} \\ J &=\frac{\| \boldsymbol w^T\boldsymbol\mu_0-\boldsymbol w^T\boldsymbol\mu_1\|_2^2}{\boldsymbol w^T\boldsymbol\Sigma_0\boldsymbol w+\boldsymbol w^T\boldsymbol\Sigma_1\boldsymbol w}\\ &=\frac{\boldsymbol w^T(\boldsymbol\mu_0-\boldsymbol\mu_1)(\boldsymbol\mu_0-\boldsymbol\mu_1)^T\boldsymbol w}{\boldsymbol w^T(\boldsymbol\Sigma_0+\boldsymbol\Sigma_1)\boldsymbol w} \ . \tag{1} \end{aligned} J=wTΣ0w+wTΣ1w∥wTμ0−wTμ1∥22=wT(Σ0+Σ1)wwT(μ0−μ1)(μ0−μ1)Tw .(1)
定义“类内散度矩阵”
S w = Σ 0 + Σ 1 = ∑ x ∈ X 0 ( x − μ 0 ) ( x − μ 0 ) T + ∑ x ∈ X 1 ( x − μ 1 ) ( x − μ 1 ) T , (2) \begin{aligned} S_{\boldsymbol w} &=\boldsymbol \Sigma_0+\boldsymbol \Sigma_1 \\ &=\sum_{\boldsymbol x \in X_0}(\boldsymbol x-\boldsymbol \mu_0)(\boldsymbol x-\boldsymbol \mu_0)^T+\sum_{\boldsymbol x \in X_1}(\boldsymbol x-\boldsymbol \mu_1)(\boldsymbol x-\boldsymbol \mu_1)^T \ , \tag{2} \end{aligned} Sw=Σ0+Σ1=x∈X0∑(x−μ0)(x−μ0)T+x∈X1∑(x−μ1)(x−μ1)T ,(2)
以及“类间散度矩阵”
S b = ( μ 0 − μ 1 ) ( μ 0 − μ 1 ) T , (3) \begin{aligned} S_b &=(\boldsymbol\mu_0-\boldsymbol\mu_1)(\boldsymbol\mu_0-\boldsymbol\mu_1)^T \ , \tag{3} \end{aligned} Sb=(μ0−μ1)(μ0−μ1)T ,(3)
则(1)式可重写为
J = w T S b w w T S w w . (4) \begin{aligned} \\ J &=\frac{\boldsymbol w^T S_b \boldsymbol w}{\boldsymbol w^T S_{\boldsymbol w} \boldsymbol w} \ . \tag{4} \end{aligned} J=wTSwwwTSbw .(4)
令 w T S w w = 1 \boldsymbol w^T S_{\boldsymbol w} \boldsymbol w=1 wTSww=1,则(4)式等价于
min w − w T S b w s . t . w T S w w = 1 . (5) \min_{\boldsymbol w} \ -\boldsymbol w^T S_b \boldsymbol w \\ s.t. \ \boldsymbol w^T S_{\boldsymbol w} \boldsymbol w=1 \ . \tag{5} wmin −wTSbws.t. wTSww=1 .(5)
由拉格朗日乘子法,上式等价于
S b w = λ S w w , (6) S_b \boldsymbol w=\lambda S_{\boldsymbol w} \boldsymbol w \ , \tag{6} Sbw=λSww ,(6)
其中 λ \lambda λ是拉格朗日乘子。又 S b w S_b \boldsymbol w Sbw的方向恒为 μ 0 − μ 1 \boldsymbol \mu_0-\boldsymbol \mu_1 μ0−μ1,令
S b w = λ ( μ 0 − μ 1 ) , (7) S_b \boldsymbol w=\lambda(\boldsymbol \mu_0-\boldsymbol \mu_1) \ , \tag{7} Sbw=λ(μ0−μ1) ,(7)
代入式(6)即得
w = S w − 1 ( μ 0 − μ 1 ) . (8) \boldsymbol w=S_{\boldsymbol w}^{-1}(\boldsymbol \mu_0-\boldsymbol \mu_1) \ . \tag{8} w=Sw−1(μ0−μ1) .(8)
通常对 S w S_{\boldsymbol w} Sw进行奇异值分解,即 S w = U Σ V T S_{\boldsymbol w}=\boldsymbol U \boldsymbol \Sigma \boldsymbol V^T Sw=UΣVT,然后由 S w − 1 = U Σ − 1 V T S_{\boldsymbol w}^{-1}=\boldsymbol U \boldsymbol \Sigma ^{-1}\boldsymbol V^T Sw−1=UΣ−1VT得到 S w − 1 S_{\boldsymbol w}^{-1} Sw−1。
3.2 集成学习2
给定二分类训练数据集
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)}
其中,每个样本点由实例与标记组成。实例 x i ∈ X ⊆ R n x_i \in \mathcal{X}\subseteq \mathcal{R}^n xi∈X⊆Rn,标记 y i ∈ Y = { − 1 , + 1 } y_i\in\mathcal{Y}=\{-1,+1\} yi∈Y={−1,+1}, X \mathcal{X} X是实例空间, Y \mathcal{Y} Y是标记集合。
3.2.1 Bagging
random forest
输入:训练集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } T=\{(\boldsymbol x_1,y_1),(\boldsymbol x_2,y_2),...,(\boldsymbol x_N,y_N)\} T={(x1,y1),(x2,y2),...,(xN,yN)};基学习算法 L \mathfrak{L} L;训练轮数 M M M
过程:
1: f o r m = 1 , 2 , . . . , M d o for\ m=1,2,...,M\ do for m=1,2,...,M do
2: 随机选择几个属性用于决策树的生成
3: h m = L ( T , T b s ) , T b s h_m=\mathfrak{L}(T,\mathcal{T}_{bs}),\ \mathcal{T}_{bs} hm=L(T,Tbs), Tbs是自助采样产生的样本分布
4: e n d f o r end\ for end for
输出: H ( x ) = arg max y ∈ Y ∑ m = 1 M I ( h m ( x ) = y ) H(x)=\underset{y\in\mathcal{Y}}{\arg\max}\sum\limits_{m=1}^M\Bbb I(h_m(\boldsymbol x)=y) H(x)=y∈Yargmaxm=1∑MI(hm(x)=y)
3.2.2 Boosting
adaboost
1.初始化训练数据的权值分布
D 1 = ( w 11 , . . . , w 1 i , . . . , w 1 N ) , w 1 i = 1 N , i = 1 , 2 , . . . , N (9) D_1=\left(w_{11},...,w_{1i},...,w_{1N}\right),\ w_{1i}=\frac{1}{N},\ i=1,2,...,N \tag{9} D1=(w11,...,w1i,...,w1N), w1i=N1, i=1,2,...,N(9)
2.对 m = 1 , 2 , . . . , M m=1,2,...,M m=1,2,...,M
a.使用具有权值分布 D m D_m Dm的训练数据集学习,得到基本分类器
G m ( x ) : X → { − 1 , + 1 } G_m(x):\mathcal{X} \to\{-1,+1\} Gm(x):X→{−1,+1}
b.计算 G m ( x ) G_m(x) Gm(x)在训练数据集上的分类错误率
e m = ∑ i = 1 N P ( G m ( x i ) ≠ y i ) = ∑ i = 1 N w m i I ( P ( G m ( x i ) ≠ y i ) (10) e_m=\sum\limits_{i=1}^NP(G_m(x_i)\neq y_i)=\sum\limits_{i=1}^Nw_{mi}\Bbb I(P(G_m(x_i)\neq y_i) \tag{10} em=i=1∑NP(Gm(xi)=yi)=i=1∑NwmiI(P(Gm(xi)=yi)(10)
c.计算 G m ( x ) G_m(x) Gm(x)的系数
α m = 1 2 ln 1 − e m e m (11) \alpha_m=\frac{1}{2}\ln\frac{1-e_m}{e_m} \tag{11} αm=21lnem1−em(11)
d.更新训练数据集的权值分布
D m + 1 = ( w m + 1 , 1 , . . . , w m + 1 , i , . . . , w m + 1 , N ) (12) D_{m+1}=(w_{m+1,1},...,w_{m+1,i},...,w_{m+1,N}) \tag{12} Dm+1=(wm+1,1,...,wm+1,i,...,wm+1,N)(12)
w m + 1 , i = w m i Z m exp ( − α m y i G m ( x i ) ) , i = 1 , 2 , . . . , N (13) w_{m+1,i}=\frac{w_{mi}}{Z_m}\exp(-\alpha_my_iG_m(x_i)),\ i=1,2,...,N \tag{13} wm+1,i=Zmwmiexp(−αmyiGm(xi)), i=1,2,...,N(13)
其中, Z m Z_m Zm是规范化因子
Z m = ∑ i = 1 N w m i exp ( − α m y i G m ( x i ) ) (14) Z_m=\sum\limits_{i=1}^Nw_{mi}\exp(-\alpha_my_iG_m(x_i)) \tag{14} Zm=i=1∑Nwmiexp(−αmyiGm(xi))(14)
3.构建基本分类器的线性组合
f ( x ) = ∑ m = 1 M α m G m ( x ) (15) f(x)=\sum\limits_{m=1}^M\alpha_mG_m(x) \tag{15} f(x)=m=1∑MαmGm(x)(15)
得到最终分类器
G ( x ) = s i g n ( f ( x ) ) = s i g n ( ∑ m = 1 M α m G m ( x ) ) (16) \begin{aligned} G(x) &=sign(f(x))\\ &=sign\Big(\sum\limits_{m=1}^M\alpha_mG_m(x)\Big) \tag{16} \end{aligned} G(x)=sign(f(x))=sign(m=1∑MαmGm(x))(16)
四、实验步骤
4.1 线性判别
输入:数据集
D = { ( x i , y i ) } i = 1 m , y i ∈ { 0 , 1 } ; G j : X j = { ( x i j , y i j ) } j = 1 n j , i = 1 , 2 , . . . , m , j ∈ { 0 , 1 } D=\{(\boldsymbol x_i,y_i)\}_{i=1}^m\ ,\ y_i \in \{0,1\}\ ;\ G_j:X_j=\{(\boldsymbol x_i^j,y_i^j)\}_{j=1}^{n_j}\ ,\ i=1,2,...,m\ ,\ j \in \{0,1\} D={(xi,yi)}i=1m , yi∈{0,1} ; Gj:Xj={(xij,yij)}j=1nj , i=1,2,...,m , j∈{0,1},其中,下标 i i i表示第 i i i个样例,上标 j j j表示第 j j j类。
-
计算类内散度矩阵 S w S_{\boldsymbol w} Sw
-
计算两类样例均值差 μ 0 − μ 1 \boldsymbol \mu_0-\boldsymbol \mu_1 μ0−μ1
-
对 S w S_{\boldsymbol w} Sw进行奇异值分解得到 S w − 1 S_{\boldsymbol w}^{-1} Sw−1
-
计算投影向量 w , w = S w − 1 ( μ 0 − μ 1 ) \boldsymbol w \ , \ \boldsymbol w=S_{\boldsymbol w}^{-1}(\boldsymbol \mu_0-\boldsymbol \mu_1) w , w=Sw−1(μ0−μ1)
-
计算两类样例投影中心的中点 c , c = 1 2 ( w T μ 0 + w T μ 1 ) c\ , \ c=\frac{1}{2}(\boldsymbol w^T\boldsymbol \mu_0+\boldsymbol w^T\boldsymbol \mu_1) c , c=21(wTμ0+wTμ1)
-
根据Fisher判别函数,对每一个输入的 x \boldsymbol x x进行判别
F ( x ) = w T x − c = { ≥ 0 , x ∈ G 0 < 0 , x ∈ G 1 (17) F(\boldsymbol x)=\boldsymbol w^T \boldsymbol x -c= \begin{cases} \ge0, \ \boldsymbol x \in G_0\\ <0, \ \boldsymbol x \in G_1 \tag{17} \end{cases} F(x)=wTx−c={≥0, x∈G0<0, x∈G1(17)
输出:
x ∈ G j , j ∈ { 0 , 1 } \boldsymbol x \in G_j\ ,\ j\in\{0,1\} x∈Gj , j∈{0,1}。
4.2 adaboost
输入:训练集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y N ) } D=\{(\boldsymbol x_1,y_1),(\boldsymbol x_2,y_2),...,(\boldsymbol x_N,y_N)\} D={(x1,y1),(x2,y2),...,(xN,yN)};基学习算法 L \mathfrak{L} L;训练轮数 M M M
过程:
1: D 1 ( x ) = 1 / m \mathcal{D}_1(\boldsymbol x)=1/m D1(x)=1/m
2: f o r m = 1 , 2 , . . . , M d o for\ m=1,2,...,M\ do for m=1,2,...,M do
3: h m = L ( D , D m ) h_m=\mathfrak{L}(D,\mathcal{D}_{m}) hm=L(D,Dm)
4: ϵ m = P x ∼ D m ( h m ( x ) ≠ f ( x ) ) \epsilon_m=P_{\boldsymbol x\sim\mathcal{D}_m}(h_m(\boldsymbol x)\neq f(\boldsymbol x)) ϵm=Px∼Dm(hm(x)=f(x))
5: i f ϵ m > 0.5 t h e n b r e a k if\ \epsilon_m >0.5\ then\ break if ϵm>0.5 then break
6: α m = 1 2 ln 1 − ϵ m ϵ m \alpha_m=\frac{1}{2}\ln\frac{1-\epsilon_m}{\epsilon_m} αm=21lnϵm1−ϵm
7: D m + 1 ( x ) = D m ( x ) exp ( − α m f ( x ) h m ( x ) ) Z m , Z m = ∑ m = 1 M D m ( x ) exp ( − α m f ( x ) h m ( x ) ) \mathcal{D}_{m+1}(\boldsymbol x)=\frac{\mathcal{D}_m(\boldsymbol x)\exp(-\alpha_mf(\boldsymbol x)h_m(\boldsymbol x))}{Z_m},\ Z_m=\sum\limits_{m=1}^M\mathcal{D}_m(\boldsymbol x)\exp(-\alpha_mf(\boldsymbol x)h_m(\boldsymbol x)) Dm+1(x)=ZmDm(x)exp(−αmf(x)hm(x)), Zm=m=1∑MDm(x)exp(−αmf(x)hm(x))
8: e n d f o r end\ for end for
输出: H ( x ) = s i g n ( ∑ m = 1 M α m h m ( x ) ) H(x)=sign\Big(\sum\limits_{m=1}^M\alpha_mh_m(\boldsymbol x)\Big) H(x)=sign(m=1∑Mαmhm(x))
五、实验结果
分别使用线性判别法和集成学习中的随机森林和adaboost算法对手写数字进行识别。
1.线性判别法识别结果

2.决策树识别结果

3.bagging识别结果

4.随机森林算法识别结果
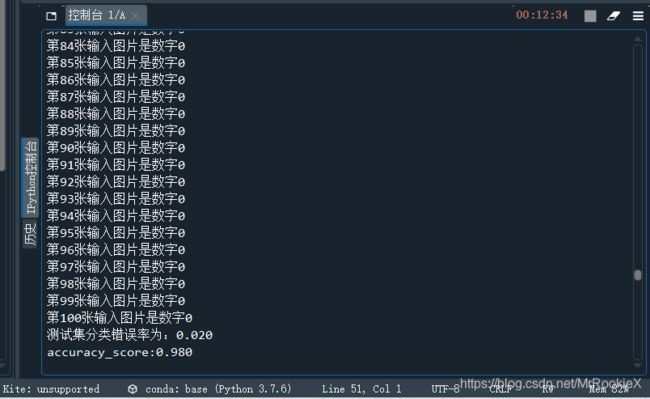
5.adaboost识别结果
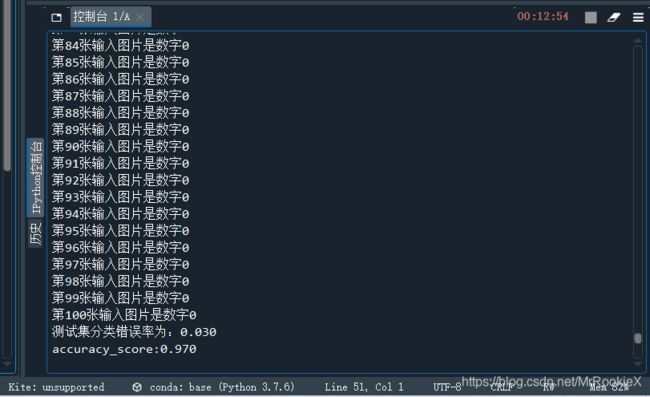
可以看出,识别效果最好的算法是随机森林,最次的是线性判别。算法按识别效果从好到次排序:random forest, adaboost, bagging, decision tree, LDA。
参考文献
清华周志华.机器学习[M]. 北京:清华大学出版社, 2016. 171-190. ↩︎
李航.统计学习方法[M]. 北京:清华大学出版社, 2019. 155-157. ↩︎