cvpr2022|自注意力和卷积集成,ACmix性能速度全面提升

导言:
清华大学等提出将卷积与自注意力融合的新范式,用于图像领域,性能和速度全面提升,官方代码已开源。
前言
卷积和自注意力是表示学习的两种强大技术,通常被认为是两种不同机制的方法。在该文中,作者证明了这两种范式的大部分计算实际上是通过相同的操作完成的,展示了它们之间很强的内在关系。作者将卷积和自注意力均拆分成两个阶段,卷积操作中,将kernel大小为k×k的传统卷积可以分解为k x k个单独的 1×1 卷积,然后进行移位和求和操作。self attention 模块中,我们将查询、键和值的投影解释为多个 1×1 卷积,然后通过计算注意力权重和聚合值。因此,两个模块的第一阶段都包含类似的操作。更重要的是,与第二阶段相比,第一阶段贡献了主要的计算复杂度(通道大小的平方)。这样就可以将这两种看似不同的范式结合在一起,提出ACmix,它享有自注意力和卷积的好处,同时与纯卷积或self-attention相比具有最小的计算开销。作者并将大量实验证明了,模型在图像识别和下游任务的竞争基线上取得了持续改进的结果。
主要内容
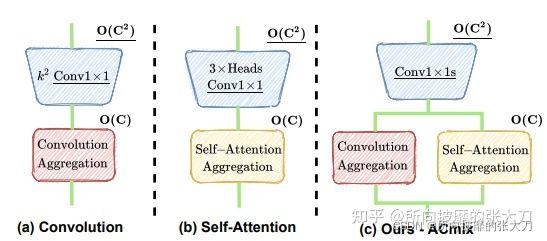
从结构上,如上图所示,将卷积和自注意力中隐式包含的1x1卷积实现共享,从而减少这一部分的计算。
具体如何实现呢,虽然作者给了大概的表示,但是还不够清晰,为了更加清晰的理解这个过程,我们根据作者的公式以及参数量和计算量等分析下具体操作过程。
卷积
对于卷积,想了解卷积算子的实现可以点击这里,传统卷积会通过k * k 卷积核特征转换后,先聚合后再偏移进入下个位置再卷积,这里的卷积是通过1 * 1卷积核计算feature map所有的特征转换后,先偏移,再聚合,将其拆分成变换和偏移聚合两个阶段:


第一步: 是卷积操作将k * k的卷积核拆分成kk个11的卷积核,计算出每个kernel中的每个元素与feature map 相乘的值,不做加和处理,所以有k * k * cin * cout的计算量,参数量因为卷积核均参与计算,所以参数量k * k * cin * cout,计算量k * k * cin * cout,为如上图。
第二步: 第一个公式,是通过11的卷积核卷积后,需要对应到kk的标准卷积上,那就需要将各个位置对应上在相加,第一个公式则是移位操作,第二个公式是对移位后的值在对应位置上加和操作,计算量为k * k* cout,第二步将第一步的输出进行加和,没有新的参数出来,所以参数量为0,计算量上,移位操作没有计算量的产生,总计算量为k* k* cout。
self-attention
自注意力机制,目前也被广泛用于cv领域,如transformer系列,与传统的卷积相比,它让模型在更大的内容空间中聚焦于重要区域,其计算公式如下(考虑N个heads):

其中:

同理,多头注意力机制也可以用两阶段来看:
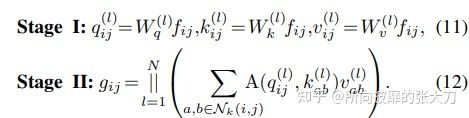

第一步,通过1x1的卷积变换后,计算出quey,key,value,这里为啥可以用1x1的卷积替代的原因是可以将输入到输出看出全连接,全连接可以用1x1卷积替代可以查看这里,这里单纯3个1x1的卷积矩阵,参数量为3xcxc,第二步,对quey,key,value进行注意力权重的计算和拼接不同头的操作,因为此时只考虑窗口kxk范围内的元素,即收集局部特征,所以计算量中序列长度也是固定的为kxk。所以在quey和key的计算中,计算量为kxcxk,在quey x key和value的计算中,计算量为kxkxc。所以整体为2倍kxkxc。而且此时没有额外的需要学习的参数,所以参数量为0。
ACmix
ACmix操作集成了卷积和自注意力操作,主要是对他们的第一步做了共享的特征转换操作,如下图所示。

第一阶段中,通过3个1x1的卷积,生成3个feature map(主要是针对self attention的q,k和v),并将3个feature map分别在深度方向上分为N组(针对self attention的N 个 heads)。这里的计算量和参数量也就是3个独立的1x1卷积操作对应的量,感觉作者在第一阶段主要考虑self-attention机制,可能觉得卷积的主要作用是特征提取,怎样卷积不影响,第一阶段的参数量和计算量均为3xCxC。第二阶段中考虑两部分内容。
卷积部分,先通过通道层的全连接对通道扩张,这里的(HxWxC/N)可以看出一个分组卷积(N间不共享,C/N内共享),做为卷积的一个基础单元,在通道层上的深度为3N,通过全连接的3N→k x k x N层,这里的k x k为了对应卷积核的size为k x k ,这样转换过后,则和上面卷积层操作的第一步对应上了,后面的处理和卷积第二步的处理相同,先对其偏移后,再去聚合成对应的维度。

这里面有几个点:1、直接空间偏移会破坏数据的局限性,很难实现向量化处理,所以作者使用类似于卷积的等效变换做为shift,如上图,偏移的使用可以参考【6】,第一个是手动平移,第二个通过矩阵转换操作,第三个是通过分组卷积操作。作者使用的通过第三种操作实现的,使用了类似于卷积的可学习的分组卷积结构来实现,引用了kc X kc大小的卷积操作。2、在空间偏移中,根据计算量,kc^4 X C,可以推导到,在N组分组卷积中,对于每一组的卷积没有做加和操作,而是使用deepwise深度可分离卷积。3、 根据计算量和参数量推理出,ACmix在第二步卷积计算时,kkC在聚合时计算量是(k X kX C),使用的是并行处理。
self-attention部分,按照正常的attention操作执行,因为分了N个heads,计算量为:N X ka X C/N X ka +N X ka X ka X C/N =2ka X ka X C,参数量上,后面没有新的参数进来,参数量为0.
最后,将计算的卷积部分和self-attention部分,以不同权重做融合:
![]()
其中α和β是可学习参数。
实验结果
作者在图像识别以及下游任务均做了试验。
图像识别
在ResNet、SAN、PVT、Swin-Transformer四种基础模型上使用ACmix,在ImageNet数据集上测试结果如下:

在计算量和参数量差别不大的情况下,top1准确率有1个点左右的提升。
分割任务
分割任务使用的Senmantic FPN 和UperNet两个网络上,在数据集ADE20K测试结果如下:

目标检测任务
目标检测任务使用resnet做为backbone网络和transformer为backbone网络的试验,使用coco数据集,测试结果如下:


推理速度
在image size (3, 576, 576)图片大小下,在昇腾910硬件平台下,在MindSpore框架环境下推理,推理速度如下:

消融试验
1.不同权重融合的消融试验:

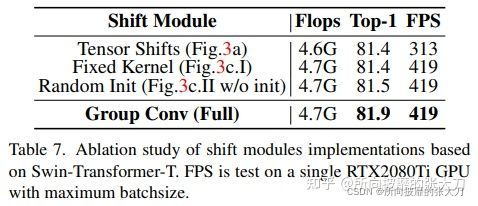
2. 卷积shift三种准换的对比试验:
不同路径的权重
作者将可学习的α和β在SAN-ACmix网络中不同层的结果显示如下:在网络早期时,卷积所占权重更高,起到特征提取的作用;后期时self-attention慢慢提上来,所占权重更高。

结语
综上,作者将卷积和self-attention机制分解后,在投影特征图时共享特征提取层,共享计算开销,集成卷积和self-attention操作,在图像分类以及下游任务中证明了有效性。其实随着transformer在cv上的大放异彩后,卷积和self-attention 已经被各种形式的结合,作者将其以权重融合的方式,这样卷积和self-attention均包含进去,因为与卷积共享特征提取,那这里面self-attention任然是基于固定窗口的,非全局的。
论文地址: https://arxiv.org/pdf/2111.14556.pdf
开源代码地址:https://github.com/LeapLabTHU/ACmix
参考:
[1] https://arxiv.org/pdf/2111.14556.pdf
[2] https://www.yuque.com/lart/papers/nlu51g
[3] https://zhuanlan.zhihu.com/p/440649716
[4] https://blog.csdn.net/qq_37151108/article/details/121938837
[5] https://zhuanlan.zhihu.com/p/439676274
[6] https://blog.csdn.net/P_LarT/article/details/122521114
更多内容深度学习关注公众号”所向披靡的张大刀“