单眼测试
Autonomous driving requires an accurate representation of the environment around the ego vehicle. The environment includes static elements such as road layout and lane structures, and also dynamic elements such as other cars, pedestrians, and other types of road users. The static elements can be captured by an HD map containing lane level information.
无人驾驶需要精确表示自我车辆周围的环境。 环境包括静态元素(例如道路布局和车道结构)以及动态元素(例如其他汽车,行人和其他类型的道路使用者)。 静态元素可以通过包含车道级别信息的高清地图来捕获。
There are two types of mapping methods, offline and online. For offline mapping and the application of deep learning in offline mapping, please refer to my previous post. In places where there is no map support or the autonomous vehicle has never been to, online mapping would be useful. For online mapping, one conventional method is SLAM (simultaneous localization and mapping) which relies on the detection and matching of geometric features on a sequence of images, or with a twist of the added notion of object.
有两种类型的映射方法,脱机和联机。 有关离线地图以及深度学习在离线地图中的应用,请参阅我的上一篇文章。 在没有地图支持或自动驾驶汽车从未去过的地方,在线地图会很有用。 对于在线制图,一种常规方法是SLAM(同时定位和制图),它依赖于图像序列上的几何特征的检测和匹配,或者依赖于所添加的对象概念的扭曲。
This post will focus on another way to do online mapping — bird’s-eye-view (BEV) semantic segmentation. Compared with SLAM which requires a sequence of images from the same moving camera over time, BEV semantic segmentation is based on images captured by multiple cameras looking at different directions of the vehicle at the same time. It is, therefore, able to generate more useful information from the one-shot collection of data than SLAM. In addition, when the ego car is stationary or slowly moving, BEV semantic segmentation would still work, while SLAM will perform poorly or fail.
这篇文章将重点介绍另一种进行在线映射的方法-鸟瞰(BEV)语义分割。 与需要随时间推移从同一台运动摄像机获取一系列图像的SLAM相比,BEV语义分割基于多个摄像机同时看向车辆不同方向的图像。 因此,与SLAM相比,它能够从一次数据收集中生成更多有用的信息。 此外,当自驾车静止不动或缓慢行驶时,BEV语义细分仍将起作用,而SLAM的表现会很差或失败。
为什么选择BEV语义图? (Why BEV semantic maps?)
In a typical autonomous driving stack, Behavior Prediction and Planning are generally done in this a top-down view (or bird’s-eye-view, BEV), as hight information is less important and most of the information an autonomous vehicle would need can be conveniently represented with BEV. This BEV space can be loosely referred to as the 3D space. (For example, object detection in BEV space is typically referred to as 3D localization, to differ from full-blown 3D object detection.)
在典型的自动驾驶系统中,行为预测和计划通常是在自顶向下的视图(或鸟瞰图,BEV)中进行的,因为较高的信息不太重要,自动驾驶汽车可能需要的大多数信息都可以用BEV方便地表示。 这个BEV空间可以广义地称为3D空间。 (例如,BEV空间中的对象检测通常称为3D定位,与成熟的3D对象检测不同。)
It is therefore standard practice to rasterize HD maps into a BEV image and combine with dynamic object detection in behavior prediction planning. Recent research exploring this strategy includes IntentNet (Uber ATG, 2018), ChauffeurNet (Waymo, 2019), Rules of the Road (Zoox, 2019), Lyft Prediction Dataset (Lyft, 2020), among many others.
因此,标准做法是将高清地图栅格化为BEV图像,并在行为预测计划中与动态对象检测相结合。 探索该策略的最新研究包括IntentNet (Uber ATG,2018), ChauffeurNet (Waymo,2019),道路规则(Zoox,2019), Lyft Prediction Dataset (Lyft,2020)等。

Traditional computer vision tasks such as object detection and semantic segmentation involve making estimations in the same coordinate frame as the input image. As a consequence, the Perception stack of autonomous driving typically happens in the same space as the onboard camera image — the perspective view space.
传统的计算机视觉任务(例如对象检测和语义分割)涉及在与输入图像相同的坐标系中进行估计。 因此,自动驾驶的Percept堆栈通常发生在与车载摄像机图像相同的空间—透视图空间中。

The gap between the representation used in perception and downstream tasks such as prediction and planning are typically bridged in the Sensor Fusion stack, which lifts the 2D observation in perspective space to 3D or BEV, usually with the help of active sensors such as radar or lidar. That said, it is beneficial for perception across modalities to use BEV representation. First of all, it is interpretable and facilitates debugging about inherent failure modes for each sensing modality. It is also easily extensible to other new modalities and simplifies the task of late fusion. In addition, as mentioned above, the perception results in this representation can be readily consumed by prediction and planning stack.
通常在传感器融合堆栈中弥合用于感知和下游任务(如预测和计划)的表示之间的差距,这通常在有源传感器(例如雷达或激光雷达)的帮助下将透视空间中的2D观察提升为3D或BEV。 。 就是说,使用BEV表示法对于跨模态感知是有益的。 首先,它是可解释的,并且有助于调试每种感应方式的固有故障模式。 它也可以很容易地扩展为其他新形式,并简化了后期融合的任务。 另外,如上所述,该表示中的感知结果可以容易地被预测和计划栈消耗。
将Perspective RGB图像提升到BEV (Lifting Perspective RGB images to BEV)
The data from active sensors such as radar or lidar lend themselves to the BEV representation as the measurement are inherently metric in 3D. However, due to the ubiquitous presence and low cost of the surround-view camera sensors, the generation of BEV images with semantic meaning has attracted a lot of attention recently.
来自主动传感器(如雷达或激光雷达)的数据适合BEV表示,因为测量本质上是3D度量。 然而,由于环视相机传感器的普遍存在和低成本,具有语义意义的BEV图像的产生近来引起了很多关注。
In the title of this post, “monocular” refers to the fact that the input of the pipeline are images obtained from monocular RGB cameras, without explicit depth information. Monocular RGB images captured onboard autonomous vehicles are perspective projections of the 3D space, and the inverse problem of lifting 2D perspective observations into 3D is an inherently ill-posed problem.
在这篇文章的标题中,“单眼”指的是管道的输入是从单眼RGB相机获得的图像,没有明确的深度信息。 在自动驾驶汽车上捕获的单眼RGB图像是3D空间的透视投影,而将2D透视观察提升为3D的反问题是一个固有的不适定问题。
IPM及其它面临的挑战 (Challenges, IPM and Beyond)
One obvious challenge for BEV semantic segmentation is the view transformation. In order to properly restore the BEV representation of the 3D space, the algorithm has to leverage both hard (but potentially noisy) geometric priors such as the camera intrinsics and extrinsics, and also soft priors such as the knowledge corpus of road layout, and common sense (cars do not overlap in BEV, etc). Conventionally, inverse perspective mapping (IPM) has been the go-to method for this task, assuming a flat ground assumption and a fixed camera extrinsics. But this task does not work well for non-flat surface or on a bumpy road when camera extrinsics vary.
BEV语义分割的一个明显挑战是视图转换。 为了正确还原3D空间的BEV表示,该算法必须利用硬的(但可能有噪声)几何先验条件,例如相机固有和外部性,以及软的先验条件,例如道路布局的知识语料库和通用模型。感觉(汽车在BEV中不会重叠等)。 按照惯例,假定地面平坦且摄影机外部固定,逆透视映射(IPM)已成为该任务的首选方法。 但是,当相机的外部特性变化时,此任务不适用于非平坦表面或在崎road不平的道路上。

The other challenge lies in the collection of data and annotation for such a task. One way to do this is to have a drone following the autonomous vehicle at all times (similar to MobileEye’s CES 2020 talk), and then ask human annotation of semantic segmentation. This method is obviously not practical and scalable. Many studies have relied on synthetic data or unpaired map data for training the lifting algorithm.
另一个挑战在于针对此类任务的数据收集和注释。 一种方法是让无人机始终跟踪自动驾驶汽车(类似于MobileEye的CES 2020演讲),然后要求人工标注语义分割。 这种方法显然是不切实际和可扩展的。 许多研究依靠合成数据或未配对的地图数据来训练提升算法。
In the following sessions, I will review recent advances in the field and highlight the commonalities. These studies can be largely grouped into two types depending on the supervision signal used. The first type of study resorts to simulation for indirect supervision and the second type directly leverages the recently released multi-modal datasets for direct supervision.
在接下来的会议中,我将回顾该领域的最新进展并强调其共同点。 这些研究可以根据所使用的监督信号大致分为两种类型。 第一种研究采用模拟进行间接监管,第二种研究直接利用最近发布的多模式数据集进行直接监管。
仿真和语义分割 (Simulation and Semantic Segmentation)
The seminal studies in this field use simulation to generate the necessary data and annotation to lift perspective images into BEV. To bridge the simulation-to-reality (sim2real) domain gap, many of them use semantic segmentation as an intermediate representation.
在该领域的开创性研究使用模拟来生成必要的数据和注释,以将透视图图像导入BEV。 为了弥合仿真与现实(sim2real)领域的鸿沟,他们中的许多人都使用语义分段作为中间表示。
VPN(查看解析器网络,RAL 2020) (VPN (View Parser Network, RAL 2020))
VPN (Cross-view Semantic Segmentation for Sensing Surroundings) is among the first works to explore BEV semantic segmentation and refers to it as “cross-view semantic segmentation”. The View Parsing Network (VPN) uses a view transformer module to model the transformation from perspective to BEV. This module is implemented as a multilayer perceptron (MLP) that stretches the 2D physical extent into a 1D vector and then perform a fully connected operation on it. In other words, it ignores strong geometric priors but purely adopts a data-driven approach to learn the perspective-to-BEV warping. This warping is camera-specific and one network has to be learned per camera.
VPN(用于感知环境的跨视图语义分割)是探索BEV语义分割的首批作品之一,并将其称为“跨视图语义分割”。 视图解析网络(VPN)使用视图转换器模块对从透视图到BEV的转换进行建模。 此模块以多层感知器(MLP)的形式实现,该感知器将2D物理范围扩展为1D向量,然后对其执行完全连接的操作。 换句话说,它忽略了强大的几何先验,而纯粹采用了数据驱动的方法来学习从透视到BEV的变形。 这种扭曲是特定于摄像机的,每个摄像机必须学习一个网络。
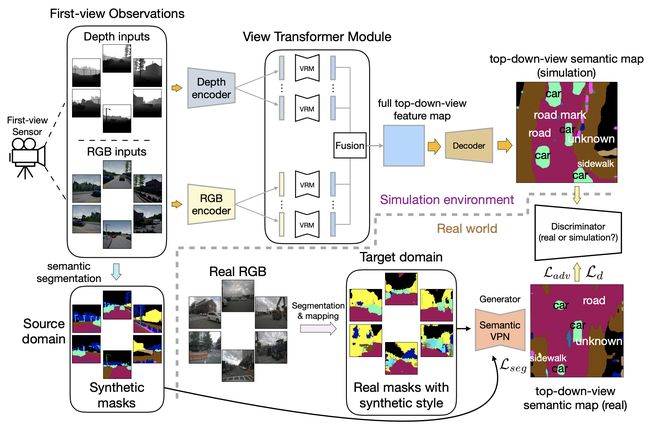
VPN uses synthetic data (generated with CARLA) and adversarial loss for domain adaptation during training. In addition, it uses a semantic mask as an intermediate representation without the photorealistic texture gap.
VPN在训练过程中使用合成数据(使用CARLA生成)和对抗性损失进行域适应。 此外,它使用语义蒙版作为中间表示,而没有真实感的纹理间隙。
The input and output of the view transformer module are of the same size. The paper mentioned that this makes it easily plugged-in to other architectures. It is actually quite not necessary as I see it, as the perspective view and BEV are inherently different spaces and therefore no need to enforce the same pixel format nor even the aspect ratio between the input and output. Code is available on github.
视图转换器模块的输入和输出大小相同。 该论文提到,这使得它很容易插入其他架构。 正如我所见,实际上并没有必要,因为透视图和BEV本质上是不同的空间,因此不需要强制使用相同的像素格式,甚至不需要输入和输出之间的宽高比。 代码在github上可用。
捕鱼网(CVPR 2020) (Fishing Net (CVPR 2020))
Fishing Net convert lidar, radar, and camera fusion in a single unified representation in BEV space. This representation makes it much easier to perform late fusion across different modalities. The view transformation module (the purple block in the vision path) is similar to the MLP-based VPN. The input to the view transformation network is a sequence of images, but they are just concatenated across the channel dimension and fed into the network, instead of leveraging an RNN structure.
钓鱼网在BEV空间中以单个统一表示形式转换激光雷达,雷达和摄像机融合。 这种表示使跨不同模式进行后期融合变得容易得多。 视图转换模块(视觉路径中的紫色块)类似于基于MLP的VPN。 视图转换网络的输入是图像序列,但是它们只是跨通道维级联并馈入网络,而不是利用RNN结构。

The groundtruth generation is with 3D annotation in lidar, and it mainly focuses on dynamic objects such as vehicles and VRU (vulnerable road users, such as pedestrians and cyclists). All the rest are represented by a background class.
Groundtruth生成器在激光雷达中带有3D注释,它主要关注动态对象,例如车辆和VRU(易受伤害的道路用户,例如行人和骑自行车的人)。 其余所有由背景类表示。
The BEV semantic grid has a resolution of 10 cm and 20 cm/pixel. This is much coarser than the typical value of 4 or 5 cm/pixel used in the offline mapping. Following the convention of VPN, the dimensions of the images match the output resolution of 192 x 320. Talk at CVPR 2020 can be found on Youtube.
BEV语义网格的分辨率为10厘米和20厘米/像素。 这比离线映射中使用的4或5 cm /像素的典型值要粗糙得多。 遵循VPN的惯例,图像的尺寸与192 x 320的输出分辨率匹配。CVPR2020上的对话可在Youtube上找到。
VED(ICRA 2019) (VED (ICRA 2019))
VED (Monocular Semantic Occupancy Grid Mapping with Convolutional Variational Encoder-Decoder Networks) exploits a variational encoder-decoder (VED) architecture for semantic occupancy grid map prediction. It encodes the front-view visual information for the driving scene and subsequently decodes it into a BEV semantic occupancy grid.
VED(具有卷积变分编码器-解码器网络的单眼语义占用网格映射)利用变体编码器-解码器(VED)架构进行语义占用网格图预测。 它对驾驶场景的前视视觉信息进行编码,然后将其解码为BEV语义占用网格。

This groundtruth is generated using a disparity map from stereo matching in the CityScape dataset. This process may be noisy, and this actually prompted the use of VED and the sampling from the latent space to make the model robust to imperfect GT. However, by virtue of being a VAE, it often does not produces sharp edges, perhaps due to the Gaussian prior and mean-squared error.
使用真实视差图根据CityScape数据集中的立体匹配生成此地面真相。 这个过程可能很嘈杂,这实际上促使人们使用VED和从潜在空间进行采样,从而使模型变得稳健,可以使GT变得不完美。 但是,由于是VAE,它通常不会产生尖锐的边缘,这可能是由于高斯先验误差和均方误差引起的。
The input image and output are 256×512 and 64×64. VED leveraged the architecture of a vanilla SegNet (a relatively strong baseline for conventional semantic segmentation) and introduced one 1x2pooling layer in order to accommodate the different aspect ratio of input and output.
输入图像和输出为256×512和64×64。 VED利用了香草SegNet的体系结构(传统语义分段的相对强大的基线)并引入了一个1x2池层,以适应输入和输出的不同长宽比。
学习环顾对象(ECCV 2018) (Learning to Look around Objects (ECCV 2018))
Learning to Look around Objects for Top-View Representations of Outdoor Scenes hallucinates occluded areas in BEV, and leverages simulation and map data to help.
学习环顾四周的物体以获取室外场景的俯视图,使BEV中的遮挡区域产生幻觉,并利用模拟和地图数据提供帮助。
Personally, I think this is quite a seminal paper in the field of BEV semantic segmentation, but it does not seem to have received much attention. Maybe it needs a catchy name?
就我个人而言,我认为这是BEV语义分段领域的开创性论文,但似乎并没有引起太多关注。 也许需要一个醒目的名称?

The view transformation is done via pixel-wise depth prediction and project to BEV. This partially overcomes the issue of lack of training data in BEV space. This is also done in later work as in Lift, Splat, Shoot (ECCV 2020) reviewed below.
视图转换是通过逐像素深度预测完成的,并投影到BEV。 这部分克服了BEV空间中缺乏训练数据的问题。 这也将在以后的工作中完成,如下文所述的“升力,摔跤,射击”(ECCV 2020) 。
The trick used by the paper to learn to hallucinate (predict occluded portions) is quite amazing. For dynamic objects whose GT depth is hard to find, we filter out loss. Randomly masking out blocks of images and ask the model to hallucinate. Use the loss as a supervision signal.
该论文用来学习幻觉(预测被遮挡的部分)的技巧非常了不起。 对于GT深度很难找到的动态对象,我们会滤除损失。 随机掩盖图像块,并让模型产生幻觉。 将损失用作监督信号。

As it is hard to obtain explicitly paired supervision in BEV space, the paper used the adversarial loss to guide the learning with simulation and OpenStreetMap data to ensure that the generated road layout looks like realistic road layouts. This trick is also used in later work as in MonoLayout (WACV 2020).
由于很难在BEV空间中获得明确的配对监管,因此本文使用对抗性损失来通过模拟和OpenStreetMap数据指导学习,以确保生成的道路布局看起来像真实的道路布局。 此技巧还用于以后的工作,如MonoLayout(WACV 2020) 。
It employs one CNN in image space for depth and semantics prediction, lifts the predictions to 3D space and renders in BEV, and finally uses another CNN in BEV space for refinement. This refinement module in BEV is also used in many other works such as Cam2BEV (ITSC 2020) and Lift, Splat, Shoot (ECCV 2020).
它在图像空间中使用一个CNN进行深度和语义预测,将预测提升到3D空间并在BEV中进行渲染,最后在BEV空间中使用另一个CNN进行细化。 BEV中的优化模块还用于许多其他作品,例如Cam2BEV(ITSC 2020)和Lift,Splat,Shoot(ECCV 2020) 。
Cam2BEV(ITSC 2020) (Cam2BEV (ITSC 2020))

Cam2BEV (A Sim2Real Deep Learning Approach for the Transformation of Images from Multiple Vehicle-Mounted Cameras to a Semantically Segmented Image in Bird’s Eye View) uses a spatial transformer module with IPM to transform perspective features to BEV space. The neural network architecture takes in four images captured by different cameras, and for each of them apply IPM transformation before concatenating them together.
Cam2BEV (一种Sim2Real深度学习方法,用于将图像从多个车载摄像机转换为鸟瞰视图中的语义分割图像)使用具有IPM的空间转换器模块将透视特征转换为BEV空间。 神经网络体系结构接收由不同摄像机捕获的四张图像,并且对于每张图像,在将它们连接在一起之前都应用IPM转换。
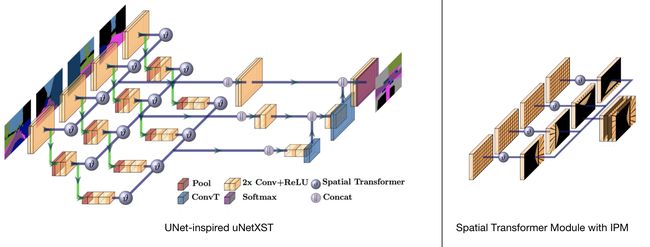
Cam2BEV uses synthetic data generated from VTD (virtual test drive) simulation environment. It takes in four semantic segmentation image and focus on the lifting process and avoided dealing with the sim2real domain gap.
Cam2BEV使用从VTD (虚拟测试驱动器)仿真环境生成的合成数据。 它采用了四个语义分割图像,并专注于提升过程,避免了处理sim2real域差距。
Cam2BEV has a rather focused scope and many design choices which makes it highly practical. First of all, it only works in semantic space, and thus avoided the question of sim2real domain gap. It has a preprocessing stage to deliberately mask out occluded regions to avoid reasoning about occlusion and arguably make the problem more tractable. To ease the lifting process, it also takes as input a “homography image”, generated by IPM of semantic segmentation results and concatenated into a 360 deg BEV image. Thus the main goal of Cam2BEV is to reason the physical extent of the 3D objects in the BEV, which may be elongated in the homography image.
Cam2BEV具有相当集中的范围和许多设计选择,这使其非常实用。 首先,它仅在语义空间中起作用,从而避免了sim2real域间隙的问题。 它有一个预处理阶段,可以故意遮盖遮挡的区域,以避免推理出遮挡,并且可以说使问题更容易解决。 为了简化提升过程,它还将IPM产生的语义分割结果并连接成360度BEV图像的“单应性图像”作为输入。 因此,Cam2BEV的主要目标是推断BEV中3D对象的物理范围,该物理范围在单应性图像中可能会变长。

As Cam2BEV uses fixed IPM, it cannot handle non-flat road surface or pitch changes during the drive. Both the input and output of Cam2BEV is 256x512 pixels. Code is available in github.
由于Cam2BEV使用固定的IPM,因此在行驶过程中无法处理非平坦的路面或变距。 Cam2BEV的输入和输出均为256x512像素。 代码可以在github中找到。
您需要的只是(多峰)数据集 (All you need is (multimodal) datasets)
The recent release of many multi-modality datasets (Lyft, Nuscenes, Argoverse, etc) makes direct supervision of the monocular BEV semantic segmentation task possible. These datasets provide not only 3D object detection information but also an HD map along with localization information to pinpoint ego vehicle at each timestamp on the HD map.
最近发布的许多多模式数据集( Lyft , Nuscenes , Argoverse等)使得直接监视单眼BEV语义分割任务成为可能。 这些数据集不仅提供3D对象检测信息,而且还提供HD地图以及定位信息,以便在HD地图的每个时间戳上精确定位自我车辆。
The BEV segmentation task has two parts, the (dynamic) object segmentation task, and the (static) road layout segmentation task. For object segmentation, 3D bounding boxes are rasterized into the BEV image to generate annotation. For static road layouts, maps are transformed into the ego vehicle frame based on provided localization results and rasterized into BEV annotation.
BEV细分任务包含两个部分,(动态)对象细分任务和(静态)道路布局细分任务。 对于对象分割,将3D边界框栅格化到BEV图像中以生成注释。 对于静态道路布局,基于提供的定位结果将地图转换为自我车架,并栅格化为BEV注释。
MonoLayout(WACV 2020) (MonoLayout (WACV 2020))
MonoLayout: Amodal scene layout from a single image focuses on the lifting of a single camera into a semantic BEV space. The focus of the paper is on amodal completion which reasons for the occluded area. It seems to be heavily influenced by Learning to Look around Objects (ECCV 2018).
MonoLayout :来自单个图像的模态场景布局着重于将单个摄像机提升到语义BEV空间中。 本文的重点是无模态完成,这是造成闭塞区域的原因。 似乎受学习环顾对象的影响很大(ECCV 2018) 。

The view transformation is performed via an encoder-decoder structure and the latent feature is called “shared context”. Two decoders are used to decode the static and dynamic class separately. The authors also reported negative results of using a combined decoder to handle both static and dynamic objects in the ablation study.
视图转换通过编码器-解码器结构执行,并且潜在特征称为“共享上下文”。 使用两个解码器分别解码静态和动态类。 作者还报告了在消融研究中使用组合解码器处理静态和动态物体的负面结果。

Though HD Map groundtruth is available in Argoverse dataset, MonoLayout chooses to use it only for evaluation but not for training (hindsight or deliberate design choice?). For training, MonoLayout uses a temporal sensor fusion process to generated weak groundtruth by aggregating 2D semantic segmentation results throughout a video with localization information. It uses monodepth2 to lift RGB pixels to point cloud. It also discards anything 5 m away from the ego car as they could be noisy. To encourage the network to output conceivable scene layout, MonoLayout used adversarial feature learning (similar to that used in Learning to Look around Objects). The prior data distribution is obtained from OpenStreetMap.
尽管Argoverse数据集中提供了HD Map groundtruth ,但MonoLayout选择仅将其用于评估,而不能用于培训(事后考虑还是故意设计?)。 为了进行训练,MonoLayout使用时间传感器融合过程通过将整个视频中的2D语义分割结果与本地化信息进行聚合来生成弱基础。 它使用monodepth2提升RGB像素以指向点云。 它还会丢弃距离自我汽车5 m以外的任何物体,因为它们可能会很吵。 为了鼓励网络输出可能的场景布局,MonoLayout使用了对抗性特征学习(类似于“学习环顾四周的对象”中使用的那种)。 先前的数据分布是从OpenStreetMap获得的。
MonoLayout has a spatial resolution of 30 cm/pixel, and thus the 128 x 128 output corresponds to 40 m x 40 m in BEV space. Code is available in github.
MonoLayout的空间分辨率为30 cm /像素,因此128 x 128输出对应于BEV空间中的40 mx 40 m。 代码在github中可用。
演示地址
PyrOccNet(CVPR 2020)(PyrOccNet (CVPR 2020))
PyrOccNet: Predicting Semantic Map Representations from Images using Pyramid Occupancy Networks predicts BEV semantic map from monocular images and fuses them into a coherent view with Bayesian Filtering.
PyrOccNet :使用金字塔占用网络从图像中预测语义图表示形式从单眼图像中预测BEV语义图,并通过贝叶斯过滤将其融合为一致的视图。

The core component of view transformation in PyrOccNet is performed via a Dense Transformer module. It seems to be heavily inspired by OFT (BMVC 2019) from the same authors. OFT uniformly smears the feature at a pixel location along the ray projected back into 3D space, which closely resembles the backprojection algorithm used in Computational Tomography. The Dense Transformer module in PyrOccNet takes it one step further by using an FC layer to expand along the depth axis. In practice, there are multiple dense transformers operating at different scales, focusing on different distance ranges in BEV space.
PyrOccNet中视图转换的核心组件是通过Dense Transformer模块执行的。 似乎受到了同一作者的OFT(BMVC 2019)的极大启发。 OFT在沿着投影回3D空间的光线的像素位置均匀涂抹特征,这与计算层析成像中使用的反投影算法非常相似。 通过使用FC层沿深度轴扩展,PyrOccNet中的Dense Transformer模块将其进一步向前发展。 实际上,有多个密度互感器以不同的比例运行,专注于BEV空间中不同的距离范围。
The dense transformer layer is inspired by the observation that while the network needs a lot of vertical context to map features to the birds-eye-view (due to occlusion, lack of depth information, and the unknown ground topology), in the horizontal direction the relationship between BEV locations and image locations can be established using simple camera geometry. — from PyrOccNet paper
密集的变压器层受到以下观察的启发:虽然网络需要大量垂直上下文才能在水平方向上将要素映射到鸟瞰图(由于遮挡,缺少深度信息以及未知的地面拓扑) BEV位置和图像位置之间的关系可以使用简单的相机几何来建立。 —来自PyrOccNet论文

The training data comes from the multimodal dataset of the Argoverse dataset and nuScenes dataset, which has both map data and 3D object detection ground truth
训练数据来自Argoverse数据集和nuScenes数据集的多峰数据集,它们同时具有地图数据和3D对象检测地面真相
PyrOccNet uses Bayesian Filtering to fuse the information across multiple cameras and across time in a coherent manner. It drawing inspiration from the old idea of the binary Bayesian occupancy grid and boosts the interpretability of the network output. The temporal fusion results closely resemble a mapping process and is quite similar to the “temporal sensor fusion” process used to generate weak GT in MonoLayout.
PyrOccNet使用贝叶斯过滤,以连贯的方式将信息融合到多个摄像机和整个时间中。 它从二进制贝叶斯占用网格的旧思想中汲取了灵感,并提高了网络输出的可解释性。 时间融合结果非常类似于映射过程,并且与用于在MonoLayout中生成弱GT的“时间传感器融合”过程非常相似。

PyrOccNet has a spatial resolution of 25 cm/pixel, and thus the 200 x 200 output corresponds to 50 m x 50 m in BEV space. Code will be available in github.
PyrOccNet的空间分辨率为25 cm /像素,因此200 x 200的输出对应于BEV空间中的50 mx 50 m。 代码将在github中提供。
演示地址
举起,摔跤,射击(ECCV 2020)(Lift, Splat, Shoot (ECCV 2020))

Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D performs dense pixel-wise depth estimation for the view transformation. It first uses per-camera CNNs to perform probabilistic pixel-wise depth prediction to lift each perspective image into a 3D point cloud and then uses camera extrinsics to splat on BEV. Finally, a BEV CNN is used to refine the predictions. The “shoot” part means path planning and will be skipped as it is outside the scope of this post.
抬升,平移,射击:通过隐式地将图像投影到3D来编码来自任意摄像机装备的图像,从而对视图变换执行逐像素的深度估计。 它首先使用按摄像机的CNN来执行概率的像素深度预测,以将每个透视图图像提升到3D点云中,然后使用摄像机的外部特性来生成BEV。 最后,BEV CNN用于完善预测。 “拍摄”部分表示路径规划,由于它不在本文讨论范围之内,因此将被跳过。

It proposed probabilistic 3D lifting through prediction of depth distribution for a pixel in the RGB image. In a way, it unifies the one-hot lifting of pseudo-lidar (CVPR 2019) and the uniform lifting of OFT (BMVC 2019). Actually this “soft” prediction is a trick commonly used in differentiable rendering. The concurrent work of Pseudo-Lidar v3 (CVPR 2020) also uses this soft rasterization trick to make depth lifting and projection differentiable.
通过预测RGB图像中像素的深度分布,提出了概率3D提升。 从某种意义上讲,它统一了伪激光的一次热销(CVPR 2019)和OFT的统一热销(BMVC 2019)。 实际上,这种“软”预测是可微分渲染中常用的一种技巧。 Pseudo-Lidar v3 (CVPR 2020)的并行工作也使用此软光栅化技巧使深度提升和投影可区分。
The training data comes from the multimodal dataset of the Lyft dataset and nuScenes dataset, which has both map data and 3D object detection ground truth.
训练数据来自Lyft数据集和nuScenes数据集的多峰数据集,后者同时具有地图数据和3D对象检测地面真相。
演示地址
Lift-Splat-Shoot has a input resolution of 128x352, and the BEV grid is 200x200 with a resolution of 0.5 m/pixel = 100m x 100m. Code will be available in github.
Lift-Splat-Shoot的输入分辨率为128x352,BEV网格为200x200,分辨率为0.5 m /像素= 100m x 100m。 代码将在github中提供。
局限性和未来方向 (Limitations and Future Directions)
Although much progress has been made in BEV semantic segmentation, there exist several key gaps as I see it before its wide deployment in production systems.
尽管BEV语义分段已经取得了很大进展,但在将其广泛应用于生产系统之前,我仍然看到一些关键的差距。
First of all, for the dynamic participants, there is no concept of instance yet. This makes it hard to leverage prior knowledge of dynamic objects in the behavior prediction. For example, cars follow a certain motion model (such as a bicycle model) and have limited patterns of future trajectory, while pedestrians tend to have more random motion. Many of the existing approaches tend to connect multiple cars into one contiguous region in the semantic segmentation results.
首先,对于动态参与者,还没有实例的概念。 这使得很难在行为预测中利用动态对象的先验知识。 例如,汽车遵循某种运动模型(例如自行车模型),并且未来轨迹的模式有限,而行人则倾向于随机运动。 在语义分割结果中,许多现有方法都倾向于将多辆汽车连接到一个连续区域中。
The dynamic semantic classes cannot be reused and are largely “disposable” information, while static semantic classes (such as the road layout and markings on the road) in the BEV image can be seen as an “online map” and should be harvested and recycled. How to aggregate BEV semantic segmentation over multiple timestamps to estimate a better map is another critical question to answer. The temporal sensor fusion approach in MonoLayout and PyrOccNet may be useful, but they need to be benchmarked against traditional approaches such as SLAM.
动态语义类不能重复使用,并且在很大程度上是“一次性”信息,而BEV图像中的静态语义类(例如道路布局和道路标记)可以看作是“在线地图”,应该被收集和回收。 。 如何在多个时间戳上聚合BEV语义分段以估计更好的地图是另一个要回答的关键问题。 MonoLayout和PyrOccNet中的时间传感器融合方法可能有用,但是需要将它们与SLAM等传统方法进行基准比较。
How to convert the online pixel-wise semantic map into a lightweight and structured map for future reuse. In order not to throw away precious mapping cycles onboard, the online map has to be converted to some format which the ego car or other cars can effectively leverage in the future.
如何将在线像素语义映射转换为轻量级和结构化的映射以供将来重用。 为了不浪费宝贵的地图绘制周期,必须将在线地图转换为自我汽车或其他汽车将来可以有效利用的某种格式。
带走 (Takeaway)
View Transformation: many of the existing work ignores the strong geometric prior info of camera extrinsics. This should be avoided. PyrOccNet and Lift-Splat-Shoot seem to be in the correct direction.
视图转换:许多现有工作都忽略了相机外部几何学的强大几何先验信息。 应该避免这种情况。 PyrOccNet和Lift-Splat-Shoot似乎是正确的方向。
Data and Supervision: Most of the research prior to 2020 are based on simulation data and use semantic segmentation as the intermediate representation to bridge the sim2real domain gap. More recent works leverage multi-modal datasets to perform direct supervision on the task, achieving very promising results.
数据和监督: 2020年之前的大多数研究都基于模拟数据,并使用语义分段作为中间表示来弥合sim2real域差距。 最近的工作利用多模式数据集对任务进行直接监督,从而获得了非常可观的结果。
I do feel that perception in BEV space is the future of perception, especially with the help of differentiable rendering, the view transformation can be implemented as a differentiable module and plug into an end-to-end model to directly lift perspective images into BEV space.
我确实认为BEV空间中的感知是感知的未来,尤其是在差异化渲染的帮助下,视图转换可以实现为差异化模块,并插入端到端模型以将透视图图像直接提升到BEV空间中。
翻译自: https://towardsdatascience.com/monocular-birds-eye-view-semantic-segmentation-for-autonomous-driving-ee2f771afb59
单眼测试