自动驾驶感知新范式——BEV感知经典论文总结和对比(下)
本文承接上篇:
自动驾驶感知新范式——BEV感知经典论文总结和对比(上)_苹果姐的博客-CSDN博客bev感知经典论文总结和对比https://blog.csdn.net/weixin_43148897/article/details/125940492?spm=1001.2014.3001.5501
4 DETR3D引入3D位置编码:PETR[10]和PETRv2[11](旷世科技,2022)
[10] PETR: Position Embedding Transformation for Multi-View 3D Object Detection
[11] PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images
代码:GitHub - megvii-research/PETR: [ECCV2022] PETR: Position Embedding Transformation for Multi-View 3D Object Detection
PETR论文指出,DETR3D虽然可以得到比较好的性能,但是存在三个问题:
1.bev空间与多视图之间的信息交互依赖于3D参考点估计的准确性,如果估计不准,可能无法投影到有效区域内,无法与2D图像进行交互;
2.只进行了object queries与3D参考点投影的2D点的特征之间的信息交互(前文提到),没有学习到全局信息;
3.由于需要采样和投影,DETR3D的pipeline相对复杂,影响推理的效率。
所以,PETR摒弃了采样和投影,直接计算2D多视图对应的3D位置编码,并加到2D图像特征中,再和3D的object queries进行交互,直接对3D object queries进行更新,大大简化了pipeline。DETR/DETR3D/PETR的对比图和PETR结构图如下所示:


PETR
这里3D特征编码借鉴了DSGN[12],即将图像的视锥空间坐标(h, w, d)转到3D空间坐标(x, y, z),再进行embedding,其中d代表均匀分布的深度,从预先设定的深度范围和间隔得到。这里的3D空间指车身的bev空间,所以需要同时使用内参和外参进行转换。因为每个视角对应的视锥空间坐标都相同(只有内外参不同),所以只需要计算一次,省去了DETR对参考点的多次投影过程。
[12] Dsgn: Deep stereo geometry network for 3d object detection.
得到3D特征编码后,与2D特征相加(代码中还加入了2D的正弦编码),然后与object queries做cross-attention。这里没有采样,使用的是全局attention。detection head部分与DETR相似。
PETRv2是在PETR的基础上进一步使用了时序特征、特征引导的3D位置编码和语义分割query,也是孙剑大佬离世前的项目(忧伤)。
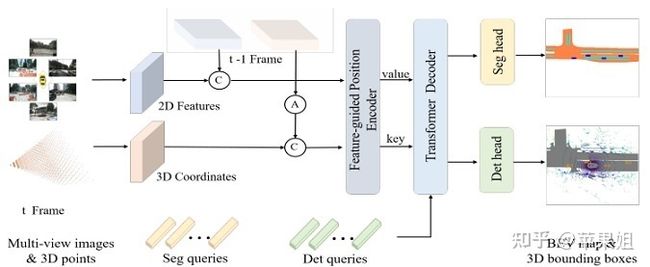
PETRv2
在此之前,BEVformer(下文会提到)提出了使用时序bev进行特征增强和bev视角下语义分割的方案,PETRv2基于PETR的3D特征编码框架对此进行了进一步的探索。首先是增加了时序输入(如上图所示),将t-1帧的特征经过坐标转换后与t帧对齐(如图a左所示),并在batch维度与t帧拼接后输入编码器。其次,3D位置编码使用了特征引导的位置编码(FPE)(如图a右所示),而不是单纯依赖于3D空间坐标,这样可以提供深度信息。最后,增加了语义分割分支,将图像分割为一系列patch,编码得到segmentation queries,再与FPE得到的K,V进行交互,经过分割头得到分割结果(如图b所示)。PETRv2的时空特征融合框架实现了目前最好的目标检测和语义分割性能。
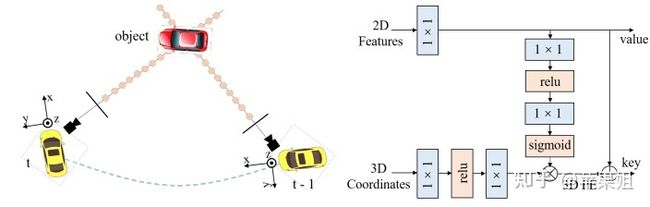
a 左:t-1帧到t帧的坐标转换 右:特征引导的位置编码器(FPE)

b 语义分割分支框架
5 自顶向下稠密的BEV特征建模:BEVFormer[13] (上海AI Lab,2022)和BEVSegformer[14](纽劢科技,2022)
以上介绍的模型主要分两类,一种是自底向上(LSS为代表)的稠密BEV特征建模,一种是自顶向下(DETR3D为代表)的稀疏BEV特征建模,还有一类是自顶向下的稠密BEV特征建模,比较有代表性的是BEVFormer和BEVSegformer。
[13] BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
代码:BEVSegFormer: Bird’s Eye View Semantic Segmentation From Arbitrary Camera Rigs
[14] BEVSegFormer: Bird’s Eye View Semantic Segmentation From Arbitrary Camera Rigs

BEVFormer框架
BEVformer框架也是从DETR3D发展而来,也是从bev空间的3D query出发,得到参考点和采样点,再通过多相机的内外参投影到多视角2D图片上,和相应特征进行交互。但DETR3D的object queries是稀疏的,每个query代表一个可能的目标框,而Bevformer的bev queries是稠密的,大小为H*W*C,H,W为设定的bev特征尺度,每个query代表一个网格(grid)的查询,这样可以得到稠密的bev特征。
看代码会发现,BEVFormer的参考点和采样点的获取方式也和DETR3D有很大的不同,由于BEVFormer是稠密的,不需要额外去预测一些备选参考点,而是直接得到固定的H*W*Z个参考点坐标(Z代表每个bev pillar中设定的不同高度的参考点个数),再将所有参考点投影到N个2D视图中,得到N*H*W*Z个2D参考点,而采样点(与2D参考点的offset)是通过bev queries去预测的,每个bev query预测N*Z*K个采样点,也就是直接从3D的query预测每个2D视图的offset。DETR3D就简单的多,直接从object queries预测N个参考点,再做多视图投影,并与多视图的2D参考点处的特征做交互,没有引入采样点。(看得头疼)
Bevformer另一个创新之处是时序特征融合(temporal self-attention),即用前一帧和当前帧的bev特征进行交互,获取当前帧缺失的时序特征,用来解决当前帧目标遮挡或者不稳定的问题,如下图所示。这里前一帧的特征根据已知的ego-motion转换为与当前帧的特征点位置对齐,但由于存在动态目标,难以建立前后两帧之间动态目标的特征联系,所以本模块采用的deformable attention中采样点的坐标偏移∆p与原生的deformable attention略有不同,是将query和上一帧的bev特征B'拼接后再进行采样点的预测。

BEVFormer效果示意
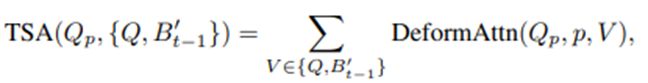
加入时序信息的deformable attention
上文的PETRv2也利用了时序特征,与BEVformer对比可参考PETR与DETR3D的对比,都是使用较固定的3D位置编码(PETRv2采用特征引导的位置编码)代替了内外参投影,在效率上有一定的提升,但PETRv2仍然没做稠密的bev特征建模,而是针对目标检测和语义分割单独设置不同的queries。另外参照BEVDet(自底向上的稠密bev特征建模)的优点,稠密的bev特征可以进一步进行特征提取和数据增强,而且更容易支持多种检测、分割、预测头,但损失一定的开销,所以各有优劣。
另一个相似的模型是BEVSegformer,也是通过bev空间稠密的bev queries与多视角2D图像特征进行信息交互,但主要的不同点在于,BEVformer是通过固定的3D 参考点经过内外参投影到各个相机视角,而BEVSegformer不依赖于3D坐标先验和多相机的内外参,直接从bev query得到多视角的2D参考点和采样点,多视角时间参数不共享,也就是说BEVSegformer整个pipeline都是可学习的,没有内外参投影过程,可以作用于任意相机。整体框架和解码器可以参见下图。

BEVSegformer框架
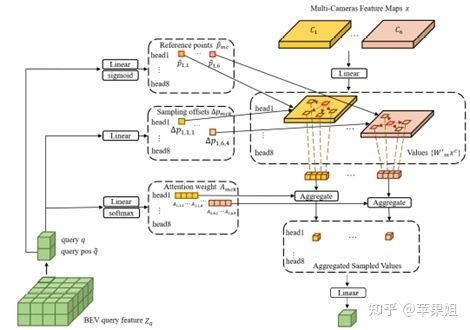
BEVSegformer解码器示意
6 BEV多模态特征融合大杀器:BEVFusion[15](MIT,2022)和FUTR3D[16](复旦、MIT、理想、清华等)
由于任何传感器都具有局限性,所以目前自动驾驶到落地量产阶段必须要做的就是多传感器融合。对于激光雷达和摄像头两种重要的传感器来说,传统的特征融合方法主要有两种:Lidar-to-camera和Camera-to-lidar。然而,前者损失了lidar的几何结构信息,难以用于3D目标检测等任务,后者损失了camera的语义信息,难以用于语义分割等任务,如下如所示。经过本文的介绍大家可以想到,将多种传感器都投影到bev空间是一个有效的特征融合方式,可以同时保留lidar的几何结构信息和camera的语义信息。BEVFusion[15]即是一种有效的多模态特征融合框架。

特征融合方式对比
[15] BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation
代码:GitHub - mit-han-lab/bevfusion: BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation
BEVFusion框架非常直观,照相机和激光点云数据经过各自的encoder进行特征编码后,camera特征采用LSS的自底向上的方法进行bev视角转换,lidar特征直接沿着z轴展平即得到bev特征,再将二者特征拼接后输入BEV encoder进行BEV特征编码,即得到融合后的BEV特征,来支持下游多任务。
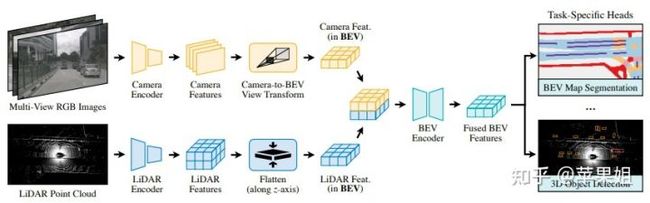
BEVFusion框架
作者还做了效率的提升,提出由于camera产生的稠密伪点云规模较大(经lift处理后规模远远大于lidar特征),原始Bev pooling操作耗时占整个推理耗时的80%,所以采用预计算和GPU并行化提高bev pooling效率,实现bev转换时延从500ms减少到12ms(仅占整个推理过程的10%)。预计算指的是由于只要相机内外参一定,产生的3D伪点云坐标就是一定的,所以可以一次计算好并保存下来,不需要多次计算。GPU并行化简单地说是为每个bev grid开启一个线程进行并行处理。
另一个BEV特征融合框架FUTR3D[16]是从DETR3D发展而来的(同一批作者),采用自顶向下的方式进行特征融合。
[16] FUTR3D: A Unified Sensor Fusion Framework for 3D Detection

FUTR3D
FUTR3D可以支持任意传感器,如2D摄像机、3D激光雷达、3D雷达和4D成像雷达等,只需要对不同的传感器配置不同的特征提取backbone即可。整体框架参照DETR3D,通过object queries得到3D reference points,再与多个传感器特征进行交互,最后同样适用匈牙利匹配的方式计算损失。感慨BEV的各种框架让原本很复杂的多视角图像特征融合、多传感器特征融合变得如此容易!
多种BEV框架的简单总结
由于本文介绍的多个BEV框架细节各不相同,难以区分,所以最后做一个简要的总结。

模型对比
喜欢本文欢迎关注交流讨论~