如何设置TF SDN网关,并与Tungsten Fabric协同工作
Tungsten Fabric并不是“vanilla”(意为完美的)Openstack与OVS。
在Neutron/OVS中,虚拟机通过所谓的供应商网络(Provider Networks)离开数据中心。它们是在数据中心交换结构上移动的VLAN网络,以便连接到网络的其它部分。这意味着要在交换结构上配置和管理所有这些VLAN。
Tungsten Fabric的方法是不同的,它有一个单一的VLAN:TF控制+数据网络。在这个VLAN里面,Tungsten Fabric会建立隧道,允许compute-to-compute的通信,并将虚拟机的流量带到数据中心之外。
当流量要离开数据中心时,必须经过一个作为SDN网关的设备。SDN网关并不是什么新概念,数据中心通常都会有一个数据中心的网关,类似于企业有一个WAN网关来连接分支机构/办公室和互联网。
这里的区别在于SDN网关与SDN控制器集成在一起。在标准的Neutron/OVS环境中,数据中心网关对OpenStack是不可见的;它只是接收属于vlan的流量。而SDN网关则与Tungsten Fabric交互,参与到控制平面流量交换(通过BGP协议),以及数据平面(通过隧道)。
接下来,我们一起试着理解上面提到的这些方面。
我们以这个简单的拓扑结构作为参考。
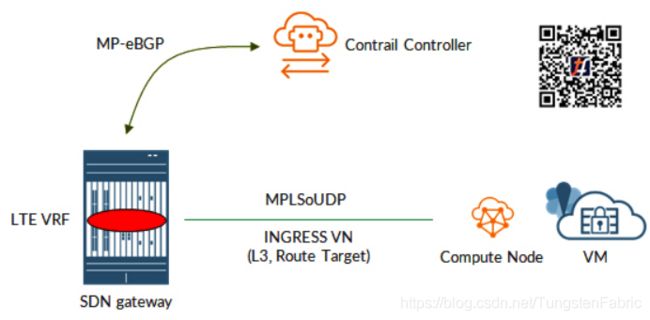
一个MX设备作为SDN网关,然后我们还有Tungsten Fabric云。接下来我们专注于两个元素:控制节点和计算节点(虚拟机就在那里运行)。
虚拟机连接到一个名为INGRESS的虚拟网络,INGRESS也有一个路由目标分配给它。

这是理解Tungsten Fabric如何运作的关键。正如我们将要看到的那样,TF只是重新使用了SDN这个众所周知的概念,但却将它们带入了一个新时代。
我们将要看到的是与众所周知的3层VPN非常相似的东西:
- SDN网关就像一个支持VRF的PE
- 计算节点也是支持VRF的PE(请记住,从TF的角度来看,虚拟网络不过是vRouter上的一个vrf)
- 控制节点就像一个路由反射器
- 虚拟机就像CE一样,使用某个协议(静态或BGP)作为PE-CE协议(与vRouter交换路由)
这些概念在后面都会进一步说明。
让我们从SDN网关——TF Control对话开始。该对话是用于控制平面的,这里使用的是BGP。路由在SDN网关和TF之间进行交换。与3层VPN完全一样,路由目标被用来将路由放入VRF当中。这意味着从SDN GW向特定的虚拟网络(这是一个VRF,并被分配了一个路由目标,正如我们之前看到的那样)发布通告路由,反之亦然。
这个BGP会话可能是内部的,也可能是外部的;在这种情况下,我们创建一个eBGP会话,因为TF和SDN网关属于不同的AS。
此外,BGP端点不属于同一个LAN,所以会话将是多跳的。
首先,要验证我们对SDN网关的可到达性。
在我们的设置中,我们有两个SDN网关,所以有两个对话。我们将只关注其中一个SDN GW,第二个SDN GW的情况是相同的。
Tungsten Fabric控制节点必须在TF控制+数据网络上有一个接口(必须在交换结构上配置)。
[root@cctrl ~]# ifconfig eth1
eth1: flags=4163 mtu 9000
inet 192.168.200.10 netmask 255.255.255.0 broadcast 192.168.200.255
inet6 fe80::200:ff:fe42:11 prefixlen 64 scopeid 0x20
ether 00:00:00:42:00:11 txqueuelen 1000 (Ethernet)
RX packets 18811623 bytes 28524979120 (26.5 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 16157459 bytes 1514455749 (1.4 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
控制节点必须有一条通往SDN GW的路由:
[root@cctrl ~]# ip route
...
192.168.255.101 via 192.168.200.1 dev eth1
192.168.255.102 via 192.168.200.1 dev eth1
并且网络可达:
[root@cctrl ~]# ping -c 3 192.168.255.101
PING 192.168.255.101 (192.168.255.101) 56(84) bytes of data.
64 bytes from 192.168.255.101: icmp_seq=1 ttl=61 time=23.7 ms
64 bytes from 192.168.255.101: icmp_seq=2 ttl=61 time=8.45 ms
64 bytes from 192.168.255.101: icmp_seq=3 ttl=61 time=10.6 ms
--- 192.168.255.101 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 8.457/14.292/23.769/6.761 ms
[root@cctrl ~]# ping -c 3 192.168.255.102
PING 192.168.255.102 (192.168.255.102) 56(84) bytes of data.
64 bytes from 192.168.255.102: icmp_seq=1 ttl=62 time=1.88 ms
64 bytes from 192.168.255.102: icmp_seq=2 ttl=62 time=9.62 ms
64 bytes from 192.168.255.102: icmp_seq=3 ttl=62 time=9.34 ms
--- 192.168.255.102 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 1.884/6.952/9.626/3.587 ms
从TF GUI中我们可以配置BGP路由器。在我们的场景中,有两个BGP路由器:

这是我们配置BGP路由器的方法:

- 供应商设置为Juniper
- IP地址和路由器ID设置为BGP端点地址
- AS设置为SDN GW AS
- 在TF侧选择你要在这个会话上启用的地址族
最后,我们将其关联到控制节点(也可以将其关联到其它设备,但我们暂时忽略这一点):

到这里Tungsten Fabric节点这一边就可以了。
接下来是SDN网关。
我们先配置BGP会话:
tim@mx10003-4-ES-2# show protocols bgp group Contrail-Control
type external;
multihop;
local-address 192.168.255.102;
family inet- {
unicast;
}
family route-target {
external-paths 3;
}
export BGP-Contrail-Control-EXP;
-apply-export;
remove-private;
peer-as 64520;
multipath;
neighbor 192.168.200.10;
- 类型为外部(external)
- 会话为多跳(multihop)
- 本地地址为我们从TF控制节点到达的地址(这个地址是在此节点的环回上配置的)
- 启用的amilies为inet--unicast和route-target。
- 对等AS为TF AS
- 在发布通告路由时,会删除私有AS
- 邻居为TF Control
- 启用多路径(用于负载均衡)
- 导出策略适用于路由
在这里,导出策略是相当重要的:
tim@mx10003-4-ES-2# show policy-options policy-statement BGP-Contrail-Control-EXP
term INET-VPN {
from family inet-;
then {
community add COM-ENCAP-UDP;
}
}
then reject;
该策略只是简单地告诉Junos为任何向Tungsten Fabric通告的路由添加一个community。
我们来看看这个community:
tim@mx10003-4-ES-2# show policy-options community COM-ENCAP-UDP
members 0x030c:64520:13;
这里的community并不是随机的。我们来看64520:这是TF AS,但这不是最重要的。真正重要的是“0x030c”和“13”,它表示“这条路由将使用MPLSoUDP封装”。MPLSoUDP是Tungsten Fabric支持的一种overlay技术。L3的overlay可以使用MPLSoUDP或MPLSoGRE,而L2的overlay使用VXLAN。我们在这里可以使用MPLSoGRE,但更推荐MPLSoUDP,因为它提供了更好的负载均衡(UDP源端口可以设置为内部数据包的哈希)。此外,MPLSoUDP默认用于compute-to-compute的通信。综上所述,该community让Tungsten Fabric明白必须使用MPLSoUDP来到达这些地址。
以上说的都是控制平面。
我们还有数据平面。现在应该很清楚了:我们在控制平面上使用BGP,在数据平面上使用MPLSoUDP。简单来说,SDN网关通过MP-eBGP从Tungsten Fabric控制节点学习一个VM IP。这个BGP路由包含了虚拟机所在的计算节点的信息。该计算节点是MPLSoUDP隧道的端点。数据平面将使用该隧道在SDN网关和VM之间发送数据包。
这些MPLSoUDP是动态的,这意味着只有在需要时才会被创建出来。例如,当SDN网关收到一条到达特定计算节点上托管的虚拟机的路由,就会创建一条隧道。后面我们会更好地理解这一点。
即使是动态的,我们仍然需要告诉SDN网关做好创建这些动态隧道的准备:
tim@mx10003-4-ES-2# show routing-options dynamic-tunnels
ComputeNode {
source-address 192.168.255.102;
udp;
destination-networks {
192.168.200.0/24;
}
}
这会告诉Junos,它可以动态地创建MPLSoUDP隧道,源头是192.168.255.102(我们知道这个地址),指向计算节点所在的控制+数据网络。通过设置整个控制+数据网络,我们也覆盖了控制节点;这可能会很方便,以确保在inet.3中有一条通往控制节点的路由,并让MX能够解析BGP路由(这正是我们与VPN工作的标准RR所拥有的)。
现在一切所需配置都到位了。
让我们检查一下BGP会话状态:
tim@mx10003-4-ES-2> show bgp neighbor 192.168.200.10 | match State
Type: External State: Established Flags:
Last State: OpenConfirm Last Event: RecvKeepAlive
我们找到已配置的选项:
tim@mx10003-4-ES-2> show bgp neighbor 192.168.200.10 | match Options
Options:
Options:
协商的地址族是:
tim@mx10003-4-ES-2> show bgp neighbor 192.168.200.10 | match NLRI
NLRI for restart configured on peer: inet--unicast route-target
NLRI advertised by peer: inet--unicast inet6--unicast route-target e
NLRI for this session: inet--unicast route-target
NLRI that restart is negotiated for: inet--unicast route-target
NLRI of received end-of-rib markers: inet--unicast route-target
NLRI of all end-of-rib markers sent: inet--unicast route-target
Tungsten Fabric通告了更多的族(例如e),但只有inet--unicast和route-target(SDN GW上配置的)会用到。
目前这两个对等点之间交换的路由涉及这些表:
tim@mx10003-4-ES-2> show bgp neighbor 192.168.200.10 | match Table
Table LTE-TRAFFIC.inet.0
Table bgp.l3.0 Bit: 20000
Table bgp.rtarget.0 Bit: 10000
这一点可以通过查看从该对等点接收到的路由来确认。
tim@mx10003-4-ES-2> show route receive-protocol bgp 192.168.200.10
inet.0: 30 destinations, 32 routes (30 active, 0 holddown, 0 hidden)
inet.3: 7 destinations, 7 routes (7 active, 0 holddown, 0 hidden)
LTE-TRAFFIC.inet.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 0.0.0.0/0 192.168.200.11 64520 65101 I
* 172.30.124.10/32 192.168.200.11 100 64520 ?
* 172.30.124.11/32 192.168.200.11 100 64520 ?
* 192.168.20.3/32 192.168.200.11 200 64520 ?
* 192.168.20.4/32 192.168.200.11 200 64520 ?
mpls.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden)
bgp.l3.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
192.168.200.11:5:0.0.0.0/0
* 192.168.200.11 64520 65101 I
192.168.200.11:5:172.30.124.10/32
* 192.168.200.11 100 64520 ?
192.168.200.11:5:172.30.124.11/32
* 192.168.200.11 100 64520 ?
192.168.200.11:5:192.168.20.3/32
* 192.168.200.11 200 64520 ?
192.168.200.11:5:192.168.20.4/32
* 192.168.200.11 200 64520 ?
inet6.0: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
LTE-TRAFFIC.inet6.0: 1 destinations, 1 routes (1 active, 0 holddown, 0 hidden)
bgp.rtarget.0: 50 destinations, 50 routes (37 active, 0 holddown, 13 hidden)
Prefix Nexthop MED Lclpref AS path
64520:64520:101/96
* 192.168.200.10 64520 I
64520:64520:102/96
* 192.168.200.10 64520 I
64520:64520:6100/96
* 192.168.200.10 64520 I
64520:64520:6200/96
* 192.168.200.10 64520 I
...
其中涉及到的一个表,就是众所周知的bgp.l3.0。这再次告诉我们,Tungsten Fabric和SDN网关几乎是自由集成的,不需要额外的学习成本,因为我们使用的是非常熟知的概念!
让我们看看一条具体的路由(VM地址):
tim@mx10003-4-ES-2> show route receive-protocol bgp 192.168.200.10 172.30.124.10/32 extensive table bgp.l3.0
bgp.l3.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden)
* 192.168.200.11:5:172.30.124.10/32 (1 entry, 1 announced)
Import Accepted
Route Distinguisher: 192.168.200.11:5
VPN Label: 34
Nexthop: 192.168.200.11
MED: 100
AS path: 64520 ?
Communities: target:64520:102 target:64520:8000004 encapsulation:unknown(0x2) encapsulation:mpls-in-udp(0xd) mac-mobility:0x0 (sequence 1) unknown type 0x8071:0xfc08:0x7
看下community,有两个特别重要的细节:MPLSoUDP封装和target:64520:102。这就是我们在虚拟网络里配置的Tungsten Fabric的路由目标。
另外,我们看到VPN标签。这就是MPLSoUDP数据包的内部标签。
路由的区分符是192.168.200.11:5,其中192.168.200.11是承载虚拟机的计算节点的控制+数据地址,配置的IP为172.30.124.10。通过查看nexthop字段(192.168.200.11)也可以证实这一点。
这就清楚地表明了我们之前所说的:我们在控制平面上通过BGP在控制节点和SDN网关之间交换路由,在数据平面上通过SDN GW和计算节点之间的MPLSoUDP隧道发送/接收实际数据帧。
之前我们看到,在SDN GW上涉及到一个VRF。我们来具体看一下:
tim@mx10003-4-ES-2# show routing-instances LTE-TRAFFIC | match vrf
instance-type vrf;
vrf-import LTE-IMPORT;
vrf-export LTE-EXPORT;
vrf-table-label;
我们来检查导入策略:
tim@mx10003-4-ES-2# show policy-options policy-statement LTE-IMPORT
term 1 {
from {
protocol bgp;
community 64520:102;
}
then accept;
}
term 2 {
then reject;
}
tim@mx10003-4-ES-2# show policy-options community 64520:102
members target:64520:102;
VRF被配置为INGRESS虚拟网络的导入路由。这就是我们把虚拟网络带到虚拟机之外的方法! 而这也不是什么新鲜事:这是标准的L3VPN!从SDN GW的角度来看,这只是一个PE从RR中获取路由来学习如何到达其它PE。对于那些PE是vRouters的实施,它不知道也不关心。一旦把路由从Tungsten Fabric导入到 vrf 中,剩下的事情就顺理成章了:MPLS建立隧道到远端PE,0/0缺省路由表到GRT等等……
我们来看看VRF里面虚拟机路由的细节:
tim@mx10003-4-ES-2> show route table LTE-TRAFFIC.inet.0 172.30.124.10/32 extensive
LTE-TRAFFIC.inet.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden)
172.30.124.10/32 (1 entry, 1 announced)
TSI:
KRT in-kernel 172.30.124.10/32 -> {indirect(1048577)}
*BGP Preference: 170/-101
Route Distinguisher: 192.168.200.11:5
Source: 192.168.200.10
Next hop type: Tunnel Composite, Next hop index: 639
Import Accepted
VPN Label: 34
Localpref: 100
Router ID: 192.168.200.10
Primary Routing Table bgp.l3.0
Indirect next hops: 1
Protocol next hop: 192.168.200.11
Label operation: Push 34
Indirect path forwarding next hops: 1
Next hop type: Tunnel Composite
Next hop:
192.168.200.11/32 Originating RIB: inet.3
Node path count: 1
Forwarding nexthops: 1
Next hop type: Tunnel Composite
Tunnel type: UDP, nhid: 0, Reference-count: 4, tunnel id: 0
Destination address: 192.168.200.11, Source address: 192.168.255.102
这里有很多有趣的东西!我们很容易找到MPLS标签。下一跳的类型是隧道(MPLSoUDP隧道),我们可以看到这个隧道的端点。源地址是192.168.255.102(我们在动态隧道下配置的),目的地址是192.168.200.11(虚拟机所在的计算节点)。这个路由在inet.3中,所以同样地,正如我们已经知道的,通过查看inet.3来解析bgp路由。
然而,需要注意的是:这条路由源地址是192.168.200.10(TF Controller、RR、控制平面、BGP),而下一跳是192.168.200.11(计算节点、vRouter、数据平面、MPLSoUDP)。
我们还将SDN GW的路由通告到Tungsten Fabric:
tim@mx10003-4-ES-2> show route advertising-protocol bgp 192.168.200.10
LTE-TRAFFIC.inet.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
* 10.10.0.0/24 Self 0 I
* 10.20.0.0/24 Self 0 I
* 170.170.170.1/32 Self 0 I
* 192.168.254.38/31 Self 2 I
bgp.l3.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden)
Prefix Nexthop MED Lclpref AS path
192.168.255.102:100:10.10.0.0/24
* Self 0 I
192.168.255.102:100:10.20.0.0/24
* Self 0 I
192.168.255.102:100:170.170.170.1/32
* Self 0 I
192.168.255.102:100:192.168.254.38/31
* Self 2 I
bgp.rtarget.0: 50 destinations, 50 routes (37 active, 0 holddown, 13 hidden)
Prefix Nexthop MED Lclpref AS path
3269:64520:102/96
* Self I
请记住这些路由。我们会发现它们都在Tungsten Fabric虚拟网络路由表里面:

让我们仔细看看其中一条路由:
tim@mx10003-4-ES-2> show route advertising-protocol bgp 192.168.200.10 10.10.0.0/24 table bgp.l3.0 extensive
bgp.l3.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden)
* 192.168.255.102:100:10.10.0.0/24 (1 entry, 1 announced)
BGP group Contrail-Control type External
Route Distinguisher: 192.168.255.102:100
VPN Label: 16
Nexthop: Self
Flags: Nexthop Change
MED: 0
AS path: [3269] I
Communities: target:64520:102 rte-type:0.0.0.0:5:1 encapsulation:mpls-in-udp(0xd)
我们设置了两个community:Tungsten Fabric虚拟网络上匹配的路由目标和MPLSoUDP封装。当然,我们还通告了MPLS标签。别忘了,MPLS标签在L3VPN上的意义是一样的,没有什么新鲜的!
这个路由是通过OSPF在VRF中学习的:
tim@mx10003-4-ES-2> show route table LTE-TRAFFIC.inet.0 10.10.0.0/24
LTE-TRAFFIC.inet.0: 13 destinations, 13 routes (13 active, 0 holddown, 0 hidden)
+ = Active Route, - = Last Active, * = Both
10.10.0.0/24 *[OSPF/171] 2d 19:22:13, metric 0, tag 0
> to 192.168.254.40 via ae3.2
OSPF是SDN网关与网络中另一设备之间的PE-CE协议(本文不做探讨)。
我们的vrf导出策略可以匹配OSPF路由,并添加所需的路由目标:
tim@mx10003-4-ES-2# show policy-options policy-statement LTE-EXPORT
term 1 {
from protocol ospf;
then {
community add 64520:102;
accept;
}
}
then reject;
Tungsten Fabric虚拟网络默认会导入带有自己路由目标标签的路由。
我们也可以选择配置虚拟网络来导出/导入多个路由目标,就像在Junos设备上通过vrf-import/export策略实现一样。
以上涵盖了基本的Tungsten Fabric - SDN GW通信。
我认为优势是显而易见的。比如,在交换结构上只有一个vlan,即TF控制+数据网络。此外,通过一个单一的BGP会话,承载多个虚拟网络的路由。数据中心之外的设备不再需要与每一个虚拟网络对等,因为全部的所需信息都会通过这个单一的MP-eBGP会话进行传递!
