c语言关键字理解和再认识(上)
文章目录
- 前言
- 关键字深度理解
-
- register关键字
- static关键字
-
- 前言:了解多文件
- 正言
- sizeof关键字
- 编程命名规范
- 数据存储
-
- unsigned和signed关键字
- 原码、反码、补码
-
- 有符号
- 无符号
- 补码如何转化位原码?
- 二进制快速转化口诀
-
- 十进制转化为二进制
- 二进制转化为十进制
- 大小端
-
- 口诀
- 大小端如何影响数据存储的
- 为什么有大小端?
- 整型取值范围
-
- 什么是数据取值范围?
- 例题
- 规则
- if-else语句
-
- 什么是语句?
- 表达式是什么?
- 结论:
- bool类型
-
- c语言中怎么进行的bool和0比较呢?
- float变量和“零值”进行比较
-
- 前言
- 正言
- 浮点数和"零值"进行比较
- 指针和“零值”比较
- else到底和哪个if匹配呢?
别人的知识是别人的,什么都要靠自己才有意思,我们一起加油。
不是特别深层次哈哈哈,但是足以让你去另外一个层次理解c语言关键字。有些点可能不是特别细致,单通俗易懂,相信你们也都是大神。还有下期哦。敬请期待!
前言
首先我们来了解一下,代码和计算机的关系。
我们在编译器vs2022中写的代码叫做文本代码,因为它是放在一个文件夹中的,是一个文件,而这个文本代码具体和我们的计算机是怎么联系起来的。下面我们就好好探究一下这个关系。
首先介绍了文本代码是什么的问题,那么文本代码对应的是什么?其实它就是一个可执行程序(可执行程序就是二进制程序,可执行程序本质上也是个文件)。如图: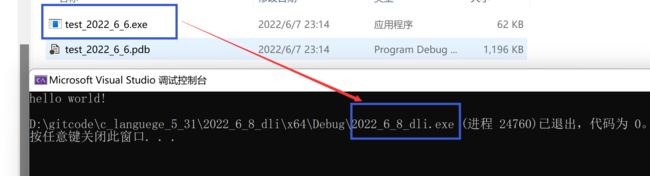
(上面这个.exe后缀的文件在debug文件中)
当我们双击这个后缀为.exe这个文件时,就可以弹出可执行程序,你可以看看这个.exe这个文件的属性,它就是一个应用程序。
在这里双击程序就很容易解释了,那么我们来了解一下双击程序的本质什么?
双击一个软件就是把它打开,本质就是把将执行的数据加载到内存当中,让计算机运行。任何程序在被执行之前都被加载到内存当中。
那么又有两个问题了,
- 没有被加载到内存之前数据是在哪的?
- 为什么要把程序加载到内存中?
第一个问题,没被加载到内存之前数据其实是在硬盘中。第二个问题,因为内存速度更快,运行效率更高,而硬盘速度慢。
这里大家可以了解了解冯诺依曼体系。这里我就不过多赘述了,初步了解就行。
初步了解之后,我们在来看看变量和内存是什么关系。
变量是什么?变量就是在内存中开辟空间。
变量的定义和声明又是什么?
extern a;//声明
int a = 10;//定义
char c = 'c';//定义
double = 3.0;//定义
为什么要定义变量,而不是直接拿内存直接用呢?
我们用图来分析

当数据传给内存时,传的数据很多,但是这是cpu还是对数据一个一个的进行计算,并不是一下次全部计算,因为cpu空间很小,不可能一次子拿来计算,所以,为什么要定义变量这里就可以解决这个问题了,就是要把数据暂时保存起来,等待后续处理(这里的变量就叫做临时变量)。
以上就是初步了解计算机内存和我们的代码的关系。下面我们来步入正题。
关键字深度理解
register关键字
register关键字是用来干什么的呢?
register是用来尽量((这里的尽量的意思是有可能被录入内存中,也有可能被录入寄存器中)向寄存器申请空间,把变量放进寄存器中,这样运行效率更快。
那么,那些变量可以用register修饰呢?
- 局部变量(全局变量会占用寄存器长的时间)。
- 不会被写入的(写入的就需要返回内存,后续需要的检测的话,那么register就毫无意义了)。
- 高频出现的变量(提高效率)。
- 不建议register大量去定义变量,因为寄存器是有限的内存。
那么我们可不可以用去地址符号来访问被register定义的变量呢?
答案是不行的,我们用代码来检验。

我们可以看到,可变参数已经拥有了一个指针(指针反应的就是一个地址),那么我们知道了我们的register修饰的变量不能访问地址,原因就是已经这个变量已经有了地址。
就现在的编译器而言,register这个关键字用的很少了,编译器现在很强大了,我们不需要用register来优化了,现在的编译器可以自动调整。
static关键字
你真的了解static关键字吗?我自认为我了解这个关键字,结果我才知道我了解的是皮毛,我问什么这么说呢,接下来我们一起来再初始static这个关键字。
前言:了解多文件
顾名思义,多文件就是在源文件中创建多个文件。
首先,我们来了解一下多文件是干啥的,在我们写代码的时候,首先会有一个main函数,而这个main函数中有函数,有变量,等等。那么我们可以把函数的定义放在别的源文件中,有的变量也可以放在别的源文件中,这样我们阅读代码就更加轻松,后期维护也方便。不然把所有内容放在有main函数的源文件中,这样内容太多,没有结构感,后期维护很困难。(头文件是以.h后缀的)
那么我们的头文件中具体有哪些内容呢?
1.函数声明
2.变量声明
3.#define以及#typedef等等
这么多内容,一个大项目中有多次声明,我们应该怎么样去解决呢?
方法一:首先在我们的头文件中顶部加上
#pragma once
#pragma once
//变量声明
extern int global;
//库函数声明
#include 注意声明两字。虽然变量不带extern是没有错误的,但是我们在头文件养成习惯,把它加上,这里变量为什么不用声明也可以支持运行呢,原因是变量在这里被定义了,只要是定义在运行的时候,调取项目中所有文件时就不会报错。那么函数用不用带上声明呢,我建议是要带上的,首先,不带上extern声明是不影响的,原因是函数定义是看有不有函数体,有函数体就是定义,没有函数体就是声明,因此在有文件中函数只是给了声明,没有函数体。
总之,头文件就是为了后期更加容易维护,写代码也更加快捷,不需要重复一件事情很多遍。
正言
- 函数可以跨文件访问
- 全局变量可以跨文件访问
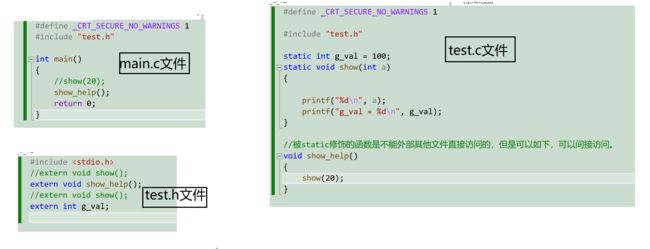
- static修饰全局变量,该变量只在本文件内被访问,不能被其他文件直接访问,可以被函数间接访问。可见的改的是作用域而不是生命周期。
- static修饰函数,只能在本文件中被访问,不能再别的文件被直接访问,只能间接访问。可见改的是作用域而不是生命周期。
- static修饰局部变量,改变了生命周期,作用域并没有改变。
- static修饰是用来增强安全性的,原因是别人修改你的代码的时候,你用static封装一样,你在这个文件中能改,在除了这个文件的其他文件就不能改了。
这里是函数间接访问。
sizeof关键字
#include 通过这段代码我们知道了sizeof是操作符或者关键字,并不是函数,函数的结构是:函数名(); 显然第三种写法是对的就说明sizeof是操作符或者关键字,而不是函数。
#include 总结:sizeof关键字就是求内置类型的大小和自定义类型的大小(指针变量、数组、指针数组)。
当应用于静态维度数组时,sizeof返回整个数组的大小。sizeof操作符不能返回动态分配的数组或外部数组的大小。另外,当数组名取整个数组大小有两种情况,一种是取地址数组,另外一种就是sizeof(数组名)。
编程命名规范
- 命名应该简单易懂。便于记忆和阅读。
- 用最短的长度传递最多的信息。
- 大驼峰命名
- 尽量避免名字中出现数字编号。
- 程序当中不得出现仅靠大小写区分的相似的标识符。
例如:
int c,C;//禁止
int i,I;//禁止
- 一个函数名禁止被用于其他之处。
例如:
#include - 所有的宏定义、枚举常数、只读变量全用大写字母命名,用下划线分割单词。
例如:
#define MAX 100
#define FILE_PATH 20
- 定义变量的同时千万不要忘了初始化。
- 不同类型数据之间的运算要注意精度扩展问题,一般低精度数据将向高精度数据扩展。
命名非常重要,基本个人素养。
数据存储
unsigned和signed关键字
unsigned和signed通常都是修饰整型类型的。
unsigned——无符号,signed——有符号。
unsigned char
signed char
unsigned int
signed int
unsigned short int
signed short int
unsigned long int
signed long int
原码、反码、补码
下面来解决数据在内存当中是如何存储的?
有符号
任何数据在计算机中都被转化成为二进制。为什么呢?原因是计算机只认识二进制,并且计算机中储存的整数必须是补码。
为什么必须是补码?
使用补码可以将符号和数值域统一处理;同时,加法和减法也可以统一处理(CPU中只有加法器ACC)
如果一个数是有符号数,并且是正数,那么原码=反码=补码。
例如:
//三十二位
#include 如果一个数是有符号的,并且是负数,那么补码=原码取反(符号位不变)+1
#include 无符号
没有符号位则原码=反码=补码,直接存储。
unsigned int a = 10; //OK
unsigned int b = -20; //OK
在印象中第二个肯定是错的,但是它是对的。 注意
首先,数据是先转化为二进制补码后再放进b这个空间中,b只是提供一个空间,并不在意它存的数据,所以这个unsigned并没有影响。也就是说存的时候,数据和类型没有关联。
那么这里的变量类型什么时候有区别?
数字带上类型才有意义。
例如:
1111 1111 1111 1111 1111 1111 1111 1110
这个二进制没有说是原码还是反码还是补码,它就是没意义的。
当我们有不同类型定义时,它的结果也是不同的。
那么我们来看看类型不同取的是不是一样的。
#include 总结:
变量的存储过程:字面的数据必须先转化为补码,在放进空间中(先开辟空间再转化)。所以,所谓符号位,完全看数据本身是否携带±号,和变量是否有符号无关!
变量取的过程:取数据一定是先看对应的变量类型,然后才决定要不要看最高符号位。如果不需要,直接二进制转成十进制,如果需要,则需要转成原码,然后才能识别(当然,最高符号位在哪里,又要明确大小端)。
例如:
#include 两个变量先存,再转化为补码,存到内存空间中的是补码形式。然后取。
这里先看变量b,首先取是先看类型,是有符号的,看最高符号位,在判断是原码还是反码还是补码。最高符号位是1,是负数,负数是补码,然后转换成原码输出,得到-10。
再看变量a,首先看类型,是无符号类型,不用看符号,直接把二进制转化十进制,得到4294967286。
再举出一个例子:
signed int a = 10;
首先存进去,补码是0000 0000 0000 0000 0000 0000 0000 1010
然后取,首先看类型,类型是signed有符号,再看最高符号位,为0,是正数,判断是原码,直接转化为10。
补码如何转化位原码?
方法一:原码等于补码减一符号位不变按位取反。
例如:
1111 1111 1111 1111 1111 1111 1110 1100(补码)
1111 1111 1111 1111 1111 1111 1110 1011(反码)
1000 0000 0000 0000 0000 0000 0001 0100(原码)
方法二:原码等与补码符号位不变其余按位取反加一。
例如:
1111 1111 1111 1111 1111 1111 1110 1100(补码)
1000 0000 0000 0000 0000 0000 0001 0011
1000 0000 0000 0000 0000 0000 0001 0100(原码)
计算机这里肯定用的是第二种方法,这样硬件只需要一种硬件电路就可以解决,简化了。
二进制快速转化口诀
十进制转化为二进制
1=2^0
10=2^1
100=2^2
1000=2^3
规律就是1后面有几个零就是二的几次方,假如1后面有n个零则是2^n。
67怎么转为二进制呢?
67=64+2+1=2^6 + 2^1 + 2^0=100 0011
二进制转化为十进制
1001000011=2^9 + 2^6 + 2^1 + 2^0=512+64+2+1=579
大小端
什么是大小端?
表示数据在存储器中的存放顺序。
大端:按照字节为单位,低权值位数据存储在高地址处,就叫做大端。
小端:按照字节为单位,低权值位数据存储在低地址处,就叫做小端。

那么再来看看大小端概念。

口诀
以小端为例
小端低地,否则为大端。
大小端如何影响数据存储的
本质是数据和内存空间的一种映射关系。
例子:
unsigned int a = -10;
这个a变量如何存呢?
-10=1111 1111 1111 1111 1111 1111 1111 0110(补码)=0xFFFFFFF6(十六进制补码)
如何取呢?
- 先看大小端
1111 1111 1111 1111 1111 1111 1111 - 再看自身类型
自身类型是unsigned, 不用看符号位,直接变十进制。
为什么有大小端?
- 数据按字节为单位的情况下,有高权值和低权值之分。
- 内存的地址有高地址和低地址之别的。
整型取值范围
以signed char为例:
char类型是一个字节的大小空间。
那么它的取值范围不就是:11111111 ~ 01111111(-127~127)吗?
这是有问题的。
什么是数据取值范围?
假如两个比特位:
00 ~ 11 这中间还有有01 10
假如是三个比特位:
000 ~ 111 这中间还有001 010 011 100 101 110
那么数据类型能表示多少个数据,是取决于比特位排列组合的个数。
两个比特位就是2^2 个,三个比特位就有2^3 个,三十二个比特位就有2^32个。
回到上面的问题,其实char类型的范围是-128 ~127。那么这个-128怎么来的呢?
首先char类型是占一个字节的内存大小空间,也就是八个比特位,那么八个比特位就有2 ^ 8的排列组合,它的取值范围也就是1111 1111 ~ 0111 1111(-127 ~127),在这个取值范围内,有一个二进制是1000 0000,它的十进制不在-127 ~ 127之间,那么我们规定它是-128或者128,这里符号位是1,那么只能取-128,这就是-128的由来,那么我们怎么去理解-128呢?举一个例子。
char c = -128;
printf("%d\n",c);
打印出的结果是-128,可以打印出正确结果。我们来分析分析,存的过程是先开辟内存空间,然后把-128转化为补码:1 1000 0000存进去;然后取的时候,char类型只能取八个比特位,这时就发生了截断,取的不是1 1000 0000,而是1000 0000,然后先看最高符号位,最高符号位是1,确认是补码,然后转换成原码:0000 0000这时我们发现,它取的时候不是-128而是0;那么就规定1000 0000是-128,直接用。所以char类型的取值范围就是-128 ~ 127。short的取值范围就是-2^15 ~ 2^15 -1。int的取值范围就是:-2^31 ~ 2^31 -1。
例题:
#include 最终输出结果是255。
我们来分析一下,首先strlen函数计算的是这个数组在’\0’结束标志之前的元素个数。那么也就是计算这个数组元素为零之前的元素个数。
a[0] = -1 = 1000 0001(原码) = 1111 1111(补码)
a[i] = -1 + (-1) = 1 1111 1110 (补码) = 1111 1110(截断后取的补码) = 1111 1101(反码) = 1000 0010(原码) = -2
那么i=0,a[0] = -1;i=1,a[1] = -2;i=2,a[2] = -3;…那么i=127,a[127] = -128;
那么-1 + (-127) = ?
a[127] = -1(1111 1111)(补码) + -127(1000 0001)(补码) = 1 1000 0000 = 1000 0000(截断后取的补码) = -128
那么a[128] = ?
a[128] = -1+(-128) = 1111 1111(-1的补码) + 1000 0000(-128的补码) = 1 0111 1111 = 0111 1111(截断后取的补码) = 127
//-1+(-128)本身越界了,超过了范围,出现错误得正数.
那么a[129] = 126,a[130] = 125,依次递减,那么我们的a[255] = 0.0~255有256个元素(包含\0),所有只有255个元素,打印出255.
例题
#include #include 规则
无符号型常量都应该带有字母U后缀。
int a = 10;
unsigned int b = 10u;
调试起来看一下。

if-else语句
什么是语句?
c语言中由一个分号;隔开的就是一条语句。
表达式是什么?
c语言中,用各种操作符把变量连起来,形成有意义的式子,就是一个表达式。
if-else基本语法
#include 结论:
- 注释:ctrl+k+c(注释),ctrl+k+u(取消注释)。
还有一种方法(不推荐)
#include - c语言当中0为假,非0为真。
- if-else语句怎么执行的?
先执行()中的表达式或者函数,得到真假结果——>条件判定——>进行分支功能。
说了怎么执行,那么我们再来看怎么用,深入理解一下。
int fun()
{
printf("如果没有数据\n");
return 1;
}
#include 前面用if-else语句做了铺垫,然后我们一起来看bool类型。
bool类型
c99引入了bool类型。但是c语言大部分都是以c90为标准。所以只需要知道就可以,另外还有微软的BOOL类型,它的空间大小是4个字节,但是不推荐使用,可移植性差(只能适用于微软的编译器)。
#include #include bool类型占一个字节的空间。
c语言中怎么进行的bool和0比较呢?
#include float变量和“零值”进行比较
前言
浮点数在内存中存储,并不是完整存储的,在十进制转化为二进制,有可能有精度损失(数值可能变大,也有可能变小)。
#include 产生了精度的损失。看图:

正言
#include 运行后结果:

浮点数和"零值"进行比较
精度损失导致,那么显然 == 判断操作符绝对不能进行浮点数之间的比较。那么我们规定进行比较是对数和EPSILON进行比较,也就是数是否在一个合法的精度范围内。
#inlcude <float.h>
int main()
{
//使用DBL_EPSILON要引入头文件#include 再来看怎么比较
- 第一种比较(自定义比较)
#include - 第二种方法(DBL_EPSILON比较——c语言中表示最小的精度值)
#include 最后我们来看浮点数和零值比较
#include 写法上不建议比较的时候带上等号。
总结:
- 浮点数存储的时候是有精度损失的。
- 浮点数是不能进行==比较的。
- double用DBL_EPSILON比较,float用FLT_EPSILON比较。
指针和“零值”比较
#include 看看if语句中括号中的写法注意事项。
#include else到底和哪个if匹配呢?
int main()
{
int x = 0;
int y = 1;
if (10 == x)
if (11 == y)
printf("hello girl!\n");
else
printf("hello boy!\n");
return 0;
}
这样的排版结果是什么都没打印,为什么呢?
原因就是,else匹配if是就近原则。建议循环和if分支语句都带上花括号。