对给定数据集分别实现k-means聚类、dbscan聚类以及agnes聚类
目录
- 1. k-means
- 2. dbscan
- 3. agnes
数据集
提取码:hgsr
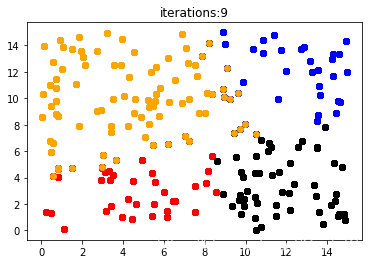
1. k-means
这个前面已经做过了,具体见:机器学习之k-means(附简单手写代码)
代码:
import numpy as np
import matplotlib.pyplot as plt
# np.random.seed(300)
x = np.random.rand(200) * 15 # 产生要聚类的数据点,(0,15)之间
y = np.random.rand(200) * 15
center_x = [] # 存放聚类中心坐标
center_y = []
result_x = [] # 存放每次迭代后每一小类的坐标
result_y = []
number_cluster = 4 # 簇数
time = 50 # 迭代次数
color = ['red', 'blue', 'black', 'orange']
for i in range(number_cluster): # 随机生成中心
result_x.append([]) # 顺便初始化存放聚类结果的列表
result_y.append([])
x1 = np.random.choice(x) # 为了避免出现聚类后有的簇一个点也没有,
y1 = np.random.choice(y) # 干脆就以某一个数据点为中心
if x1 not in center_x and y1 not in center_y:
center_x.append(x1)
center_y.append(y1)
plt.scatter(x, y) # 画出数据图
plt.title('init plot')
plt.show()
def K_means():
for t in range(time):
for i in range(len(x)):
distance = [] # 存放每个点到各中心的距离
for j in range(len(center_x)):
k = (center_x[j] - x[i]) ** 2 + (center_y[j] - y[i]) ** 2 # 距离
distance.append([k])
result_x[distance.index(min(distance))].append(x[i]) # 聚类
result_y[distance.index(min(distance))].append(y[i])
plt.title('iterations:' + str(t + 1))
for i in range(number_cluster):
plt.scatter(result_x[i], result_y[i], c=color[i])
plt.show()
# 更新位置
center_x.clear()
center_y.clear()
for i in range(number_cluster):
ave_x = np.mean(result_x[i])
ave_y = np.mean(result_y[i])
center_x.append(ave_x)
center_y.append(ave_y)
if __name__ == '__main__':
K_means()
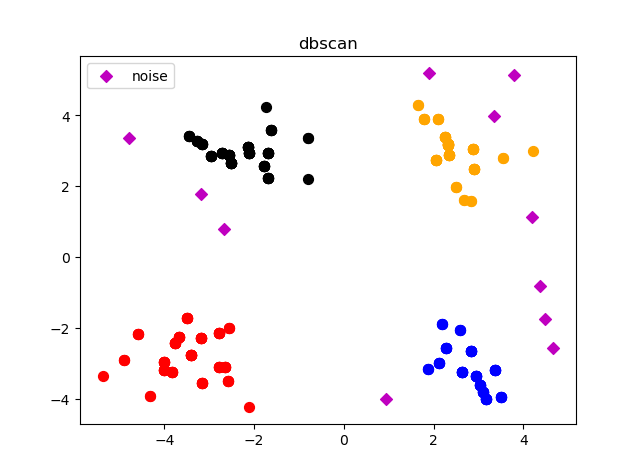
2. dbscan
初始设定两个值:minPts以及半径r
一些基本概念:
- 核心对象:若一个点的r邻域内点的个数大于等于minPts,我们就称该点为一个核心对象。
- ε \varepsilon ε-邻域的距离阈值:r。
- 直接密度可达:若某点p在核心点q的邻域内,则称p-q直接可达。
- 密度可达:若有一个点序列:q0,q1,q2,…,qk,对序列里任意两个相邻的点都是直接可达的,则称从q0到qk密度可达。
基本流程:
- 任意选择一个未被访问的点p,并将该点标记为已访问。
- 如果p的邻域内点的个数大于mminPts(核心对象),则初始化一个簇C,将p以及p领域内的点加入到C中。
- 遍历C中每个点,如果有未被访问的,将其标记为已访问。如果该点也是核心对象,则同样将该点邻域内的点加入到C中。
- 重复步骤3直到C中不再存在没被访问的核心对象,将簇C加入到一个集合final中。
- 重复步骤1234直到没有核心点未被标记,剩余的点标记为噪声点。
- 输出final与噪声点。
代码:
import matplotlib.pyplot as plt
minPts = 5 #最小个数
epsilon = 1.0 #半径
color = ['red', 'black', 'blue', 'orange']
visited = []
C = [] #保存最终的聚类结果
noise = [] #噪声点
x = []
y = []
data = open('聚类数据集/dataset.txt')
for line in data.readlines():
x.append(float(line.strip().split('\t')[0]))
y.append(float(line.strip().split('\t')[1]))
for i in range(len(x)): #初始化标记数组
visited.append(False)
def judge(): #判断是否还存在核心点未被标记
for i in range(len(x)):
if visited[i]:
continue
cnt, lis = countObject(x, y, i)
if cnt >= minPts:
return True
return False
def select(): #选择一个没被标记的点
for i in range(len(visited)):
if not visited[i]:
return i
return -1
def countObject(x, y, p): #计算点p邻域的内点的个数
cnt = 0
lis = []
for i in range(len(x)):
if i == p:
continue
if (x[i] - x[p]) ** 2 +(y[i] - y[p]) ** 2 <= epsilon ** 2:
cnt += 1
lis.append(i)
return cnt, lis
def check(c):
for i in c:
if visited[i]:
continue
cnt, lis = countObject(x,y , i)
if cnt >= minPts:
return True
return False
def dbscan():
while judge(): #判断是否还存在核心点未被标记
p = select() #选择一个没被访问的点
visited[p] = True
cnt, lis = countObject(x, y, p)
if cnt >= minPts:
c = []
c.append(p)
for i in lis:
c.append(i)
while(check(c)): #至少有一个点没被访问且该点领域内至少minPts个点
for i in c:
if not visited[i]:
visited[i] = True
cnt1, lis1 = countObject(x, y, i)
if cnt >= minPts:
for j in lis1:
c.append(j)
C.append(c)
for i in range(len(visited)):
if not visited[i]:
noise.append(i)
return C
if __name__ == '__main__':
cluster = dbscan()
X = []
Y = []
for i in noise:
X.append(x[i])
Y.append(y[i])
plt.scatter(X, Y, c='m', marker='D') # 噪声点
plt.legend(['noise'])
for i in range(len(cluster)):
X = []
Y = []
for j in cluster[i]:
X.append(x[j])
Y.append(y[j])
plt.scatter(X, Y, c=color[i], alpha=1, s=50)
plt.title('dbscan')
plt.show()
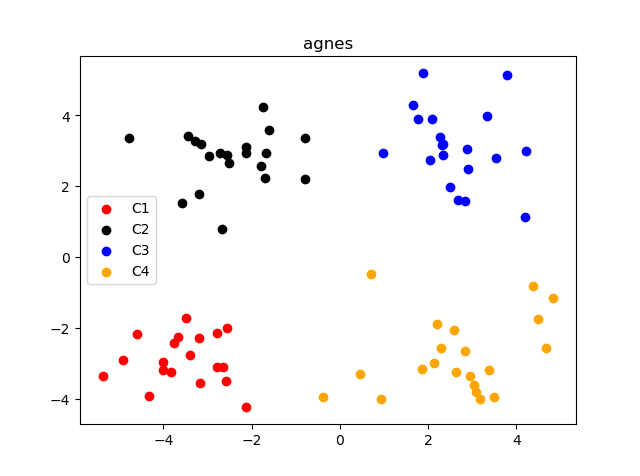
3. agnes
agnes是一种采用自底向上聚合策略的层次聚类算法。思路也很简单:
- 最开始每一个点都是一个单独的簇
- 算出所有簇之间的两两距离,选择距离最短的两个簇进行合并
- 重复步骤2直到簇的个数减小到我们指定的数目
一个问题:怎么计算两个簇之间的距离?其实就是计算两个簇之间所有点的两两距离,最后取平均值。
代码:
import matplotlib.pyplot as plt
import numpy as np
cluster_Num = 4
color = ['red', 'black', 'blue', 'orange']
C = []
x = []
y = []
data = open('聚类数据集/dataset.txt')
for line in data.readlines():
x.append(float(line.strip().split('\t')[0]))
y.append(float(line.strip().split('\t')[1]))
for i in range(len(x)):
C.append([i])
def distance(Ci, Cj): #计算两个簇之间的距离
dis = []
for i in Ci:
for j in Cj:
dis.append(np.sqrt((x[i] - x[j]) ** 2 + (y[i] - y[j]) ** 2))
dis = list(set(dis))
return np.mean(dis) #平均距离
def find_Two_cluster():
temp = []
for i in range(len(C)):
for j in range(i+1, len(C)):
dis = distance(C[i], C[j])
temp.append([i, j, dis])
temp = sorted(temp, key=lambda x:x[2])
return temp[0][0], temp[0][1]
def agnes():
global C
while len(C) > cluster_Num:
i, j =find_Two_cluster()
merge = C[i] + C[j]
C = [C[t] for t in range(len(C)) if t != i and t != j]
C.append(merge)
for i in range(len(C)):
X = []
Y = []
for j in range(len(C[i])):
X.append(x[C[i][j]])
Y.append(y[C[i][j]])
plt.scatter(X, Y, c=color[i])
plt.legend(['C1', 'C2', 'C3', 'C4'])
plt.title('agnes')
plt.show()
if __name__ == '__main__':
agnes()