{% for search_word in topn_search %} {{ search_word }} {% endfor %}
搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上采集信息,在对信息进行组织和处理后,为用户提供检索服务,将检索的相关信息展示给用户的系统。
网络中用于各种功能的搜索引擎非常多,在求职,找工作方面,智联招聘、拉勾网等也比较优秀,但数据都过于集中,却缺少重点。对于即将毕业的大学生,要花费大量的时间在多个网站投递简历,无疑增加了学生们的工作量。这次实训,我们想要实现的就是整合多个网站以及本校的校招信息,搭建起一个更为方便、便利的搜索引擎,在同学们找工作的过程中给与更好的帮助。
这个项目的功能是利用爬虫获取信息,获取的数据缓存到elastic搜索引擎。该搜索引擎可以根据浏览者输入的字符串,对搜索信息进行推荐,然后展示搜索信息。
本课程设计由4人组成一组,×负责前台网页界面的设计与美工以及搜索出来的文字界面设计,×××主要负责网站后台的功能模块的实现,以及数据库的录入设计和数据的获取,×负责网页之间各模块之间的调用,×负责搜索功能的实现。(其实都是我写的,他们在准备考研……)
2.1、获取数据
通过http将web服务器上协议站点的网页代码提取出来,根据一定的正则表达式和xpath提取器取出所需的数据。
2.2、搭建搜索引擎
搭建elasticsearch搜索引擎,与Django结合,获取搜索引擎返回的数据,展示在前台页面。
2.3、模块功能介绍
(1)爬虫模块:主要是对数据的收集,分为职位爬虫和宣讲会爬虫,可以得到所需的信息。
(2)数据添加模块:把收集的信息保存到elasticsearch搜索引擎中。
(3)删除模块:使用elasticsearch-head插件进行数据的删除和修改。
(4)内容模块:显示用户查询的信息,以及信息的详情页面。
(5)搜索建议模块:根据用户输入的字符,实时返回推荐的信息。
(6)热度搜索模块:返回用户搜索次数最多的职位名称。
(7)搜索模块:对用户所搜索的关键字符串所显示的职位与信息的概要内容。
3.1、系统的功能模块
系统的功能结构如下图:
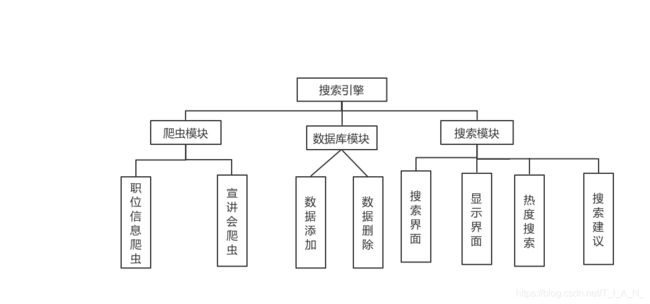
根据本网络爬虫的概要设计本网络爬虫是一个自动提取网页的程序,实现搜索引擎从自己想要访问的网上下载网页,再根据已下载的网页上继续访问其它的网页,并将其下载直到满足用户的需求。根据现实中不同用户的实际上的各种需求,本项目简单实现网络中的搜索引擎,本网络爬虫的基本流程如下:

1.设计基于多线程的网络爬虫,该爬虫程序通过socket 套接字实现客户端对服务器的访问,客户端向服务器发送自己设定好请求。
2.通过http将Web服务器上协议站点的网页代码提取出来。
3.根据一定的正则表达式提取出客户端所需要的信息。
4.宽度优先搜索可从网页中某个链接出发,访问该链接网页上的所有链接,访问完成后,再通过递归算法实现下一层的访问。
总的来说,爬虫程序从配置文件中读出URL任务列表,即初始URL种子,把初始种子保存在临界区中,然后利用多线程技术,每一一个线程发送一一个请求,多个爬虫线程在互联网上同时爬行,按照广度搜索运算法搜索抓取网页并提取URL返回到临届区中,通过正则表达式过滤所得的URL保存在临届区再将所得URL传回URL列表作为新的种子应用递归算法开始新的一轮多线程的搜索抓取网页和提取URL,从而使整个爬虫程序循环运行下去。
#部分代码如下:
class Lagou1Spider(CrawlSpider):
name = 'lagou1'
allowed_domains = ['lagou.com']
start_urls = ['https://www.lagou.com/zhaopin']
rules = (
Rule(LinkExtractor(allow=r'https://www.lagou.com/zhaopin/.*'), follow=True),
Rule(LinkExtractor(allow=r'https://www.lagou.com/jobs/.*'), follow=True, callback='parse_detail'),
)
def parse_item(self, response):
item = {}
return item
def parse_detail(self, response):
# 数据解析
item_loader = ItemLoader(item=ZhisousouItem(), response=response)
item_loader.add_xpath('title', '//h1[@class="name"]/text()')
item_loader.add_xpath('salary', '//span[@class="salary"]/text()')
item_loader.add_xpath('work_years', '//dd[@class="job_request"]//span[3]/text()')
item_loader.add_xpath('job_city', '//dd[@class="job_request"]//span[2]/text()')
item_loader.add_xpath('degree_need', '//dd[@class="job_request"]//span[4]/text()')
item_loader.add_xpath('job_type', '//dd[@class="job_request"]//span[5]/text()')
item_loader.add_xpath('job_advantage','//dd[@class="job-advantage"]//p/text()')
all_job_desc = response.xpath('//dd[@class="job_bt"]//text()').getall()
all_job_desc = ''.join(all_job_desc).replace('\n', '')
item_loader.add_value('job_need', all_job_desc.split('任职要求:')[-1].strip())
item_loader.add_value('job_responsibility', all_job_desc.split('岗位职责:')[1].split('任职要求:')[0].strip())
item_loader.add_value('job_url', '来自拉勾网')
publish_time = response.xpath('//p[@class="publish_time"]/text()').get().split('\xa0')[0]
item_loader.add_value('publish_time', publish_time)
company_name = response.xpath('//h4[@class="company"]/text()').get()[0:-2]
item_loader.add_value('company_name', company_name)
company_url = response.xpath('//h4[@class="c_feature_name"]/text()').getall()[3]
item_loader.add_value('company_url', company_url)
job_item = item_loader.load_item()
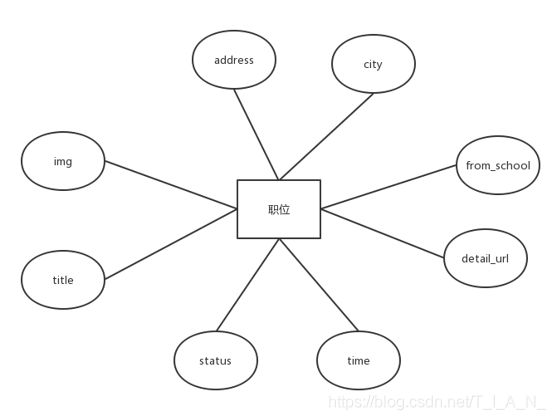
return job_item4.2、数据库模块设计
数据库用来保存爬虫获取的数据,E-R图如下:
职位E-R图:

宣讲会E-R图:
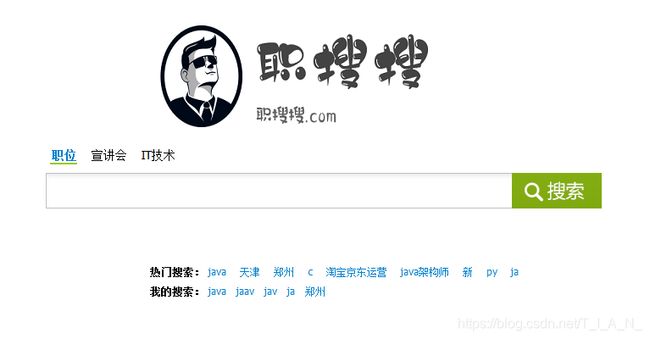
4.3.1、搜索界面
搜索分为职位、宣讲会、it技术搜索。每个按钮对应不同的url,当点击不同的搜索目标后,会选中当前的搜索目标。
搜索界面如下:
部分代码如下:
4.3.2、显示界面
实现界面如下:
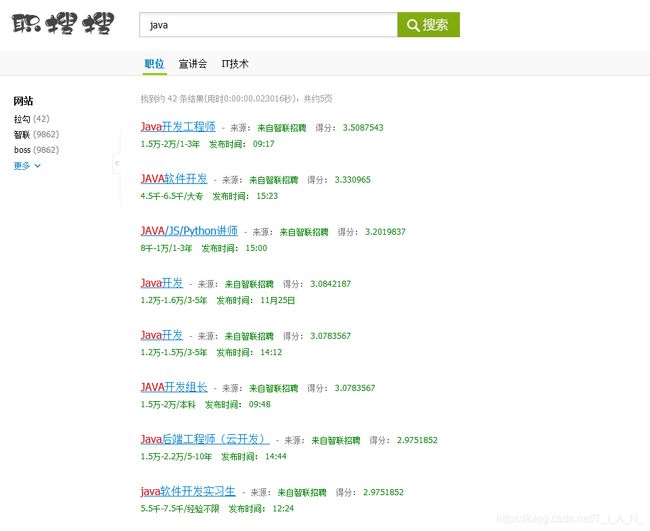
实现流程:
1、当用户输入想要搜索的信息后,使用JavaScript技术获取用户输入的信息。
2、发送ajax请求。
3、后台接收到请求,判断用户搜索的类型是职位、宣讲会或者it技术。
4、根据不同的搜索类型,构建查询语句,连接elasticsearch搜索引擎。
如response = client.search( #编写kibana查询语句
index="lagou",
body={
"query": {
"bool": {
"should": [
{"multi_match": {
"query": key_words,
"fields": ["job_city", "title", "company_name"]
}}
]
}
},
"from": (page - 1) * 10,
"size": 10,
# 高亮处理
"highlight": {
"pre_tags": [""], # 可以指定关键词使用的html标签
"post_tags": [""],
"fields": {
"title": {},
"job_city": {},
}
}
}
)5、获取搜索引擎返回的数据,渲染前端页面。
部分代码如下:
if type == 'teach-in':
redis_cli.zincrby("search_keywords_set", 1, key_words)
topn_search = redis_cli.zrevrange("search_keywords_set", 0, -1, withscores=True)
top = []
for obj in topn_search:
keyword, score = obj
top.append(keyword.decode('utf-8'))
top = top[:9]
page = request.GET.get("p", "1") # 获取分页数据
try:
page = int(page) # 进行转换
except:
page = 1
start_time = datetime.now() # 获取查询开始时time
response = client.search( #编写kibana查询语句
index="xuan",
body={
"query": {"bool": {"should": [{"multi_match": {"query": key_words, "fields": ["city", "title"]}}] } },
"from": (page - 1) * 10,
"size": 10,
# 高亮处理
"highlight": { "pre_tags": [""], # 可以指定关键词使用的html标签"post_tags": [""],"fields": {
"title": {}, "city": {}, }}})
end_time = datetime.now()
last_seconds = (end_time - start_time) # 获取查询时间
total_nums = response["hits"]["total"] # 获取查询到的值
if (page % 10) > 0: # 计算页码
page_nums = int(total_nums / 10) + 1
else:
page_nums = int(total_nums / 10)
hit_list = []
for hit in response["hits"]["hits"]: # 对查询的数据进行处理
hit_dict = {}
if "title" in hit["highlight"]:
hit_dict["title"] = "".join(hit["highlight"]["title"])
else:
hit_dict["title"] = hit["_source"]["title"]
if "city" in hit["highlight"]:
hit_dict["city"] = "".join(hit["highlight"]["city"])
else:
hit_dict["city"] = hit["_source"]["city"]
hit_dict["img"] = hit["_source"]["img"]
hit_dict["address"] = hit["_source"]["address"]
hit_list.append(hit_dict)
return render(request, "result_xuan.html", {"page": page,
"all_hits": hit_list, "key_words": key_words, "total_nums": total_nums,
"page_nums": page_nums, "last_seconds": last_seconds,
"topn_search": top, "type": 'teach-in'})4.3.3、热度搜索
根据用户搜索的关键字进行热度排序
运行界面:

实现流程:
1、本功能实现使用了redis数据库,当用户在首页输入查询信息,并点击搜索按钮。
2、后台获取用户查询的关键字。
3、连接redis数据库,对该关键字的分数加1。zincrby("search_keywords", 1, key_words)
4、再按分数获取排名前十的查询信息。zrevrange("search_keywords_set", 0, -1, withscores=True)
4.3.4、搜索建议
运行界面:

实现流程:
1、用户在首页输入查询信息,每当用户输入一个字符,就发送一次ajax请求。
2、后台获取请求,解析出类型,根据不同的类型构建不同的搜索语句,在elasticsearch搜索引擎中搜索。
3、后台返回搜索引擎执行后的数据,前端渲染数据。
部分代码:
if key_words and type == 'teach-in':
s = XuanType.search()
# 执行elasticsearch搜索语句,推荐搜索
s = s.suggest('my_suggest', key_words, completion={
"field": "suggest", "fuzzy": {
"fuzziness": 2},"size": 10 })
suggestions = s.execute_suggest() # 执行方法
for match in suggestions.my_suggest[0].options:
source = match._source
re_datas.append(source["title"]) # 获取查询结果title值
return HttpResponse(json.dumps(re_datas), content_type="application/json")三、实训体会
……