第二次学习计划 之(LeNET、AlexNet、VGGNet、GoogLeNet,ResNet)算法
非自己原创,借鉴于网上各位大佬,自己做了一个学习总结。
1.LeNET
Lenet 是一系列网络的合称,包括 Lenet1 - Lenet5,由 Yann LeCun 等人在 1990 年《Handwritten Digit Recognition with a Back-Propagation Network》中提出,是卷积神经网络的 HelloWorld。
LeNET是一个 7 层的神经网络,包含 3 个卷积层,2 个池化层,1 个全连接层。其中所有卷积层的所有卷积核都为 5x5,步长 strid=1,池化方法都为全局 pooling,激活函数为 Sigmoid,LeNET-5网络 结构如下:
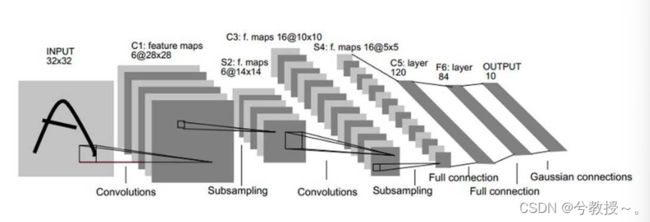
下面逐层介绍LeNet-5的结构,并且卷积层将用Ci表示,子采样层则被标记为Si,完全连接层被标记为Fi,其中i是层索引。
层C1是具有6个 5 ∗ 5 5*5 5∗5的卷积核的卷积层(convolution),特征映射的大小为 28 ∗ 28 28*28 28∗28,这样可以防止输入图像的信息掉出卷积核边界。C1包含156个可训练参数和122304个连接。
层S2是输出6个大小为 14 ∗ 14 14*14 14∗14的特征图的子采样层(subsampling/pooling)。每个特征地图中的每个单元连接到C1中的对应特征地图中的 2 ∗ 2 2*2 2∗2个邻域。S2中单位的四个输入相加,然后乘以可训练系数(权重),然后加到可训练偏差(bias)。结果通过S形函数传递。由于 2 ∗ 2 2*2 2∗2个感受域不重叠,因此S2中的特征图只有C1中的特征图的一半行数和列数。S2层有12个可训练参数和5880个连接。
层C3是具有16个 5 ∗ 5 5*5 5∗5的卷积核的卷积层。前六个C3特征图的输入是S2中的三个特征图的每个连续子集,接下来的六个特征图的输入则来自四个连续子集的输入,接下来的三个特征图的输入来自不连续的四个子集。最后,最后一个特征图的输入来自S2所有特征图。C3层有1516个可训练参数和156 000个连接。
2.AlexNet
Alexnet模型由5个卷积层和3个池化Pooling 层 ,其中还有3个全连接层构成。AlexNet 跟 LeNet 结构类似,但使用了更多的卷积层和更大的参数空间来拟合大规模数据集 ImageNet。它是浅层神经网络和深度神经网络的分界线。
下图为AlexNet网络结构:
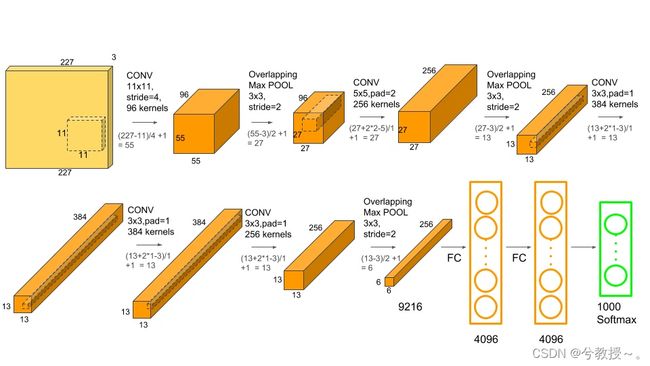
特点:
1、首次利用GPU进行网络加速训练。
2、在每个卷机后面添加了Relu激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数,解决了Sigmoid的梯度消失问题,使收敛更快。
3、使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元,避免模型的过拟合(也使用数据增强防止过拟合)
4、添加了归一化LRN(Local Response Normalization,局部响应归一化)层,使准确率更高。
5、重叠最大池化(overlapping max pooling),即池化范围 z 与步长 s 存在关系 z>s 避免平均池化(average pooling)的平均效应。
3.VGGNet
VGG 的结构与 AlexNet 类似,区别是深度更深,但形式上更加简单。VGG由5层卷积层、3层全连接层、1层softmax输出层构成,层与层之间使用maxpool(最大化池)分开,所有隐藏层的激活单元都采用ReLU函数。
VGGNet的网络结构如下图所示
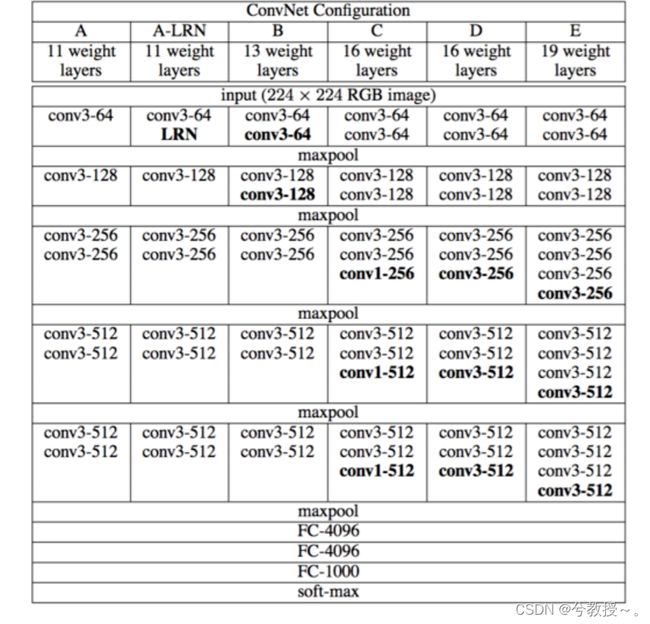
作者在原论文中,根据卷积层不同的子层数量,设计了A、A-LRN、B、C、D、E这6种网络结构。

这6种网络结构相似,都是由5层卷积层、3层全连接层组成,区别在于每个卷积层的子层数量不同,从A至E依次增加,总的网络深度从11层到19层。表格中的卷积层参数表示为“conv(感受野大小)-通道数”,例如con3-64,表示使用3x3的卷积核,通道数为64;最大池化表示为maxpool,层与层之间使用maxpool分开;全连接层表示为“FC-神经元个数”,例如FC-4096表示包含4096个神经元的全连接层;最后是softmax层。
其中,D表示著名的VGG16,E表示著名的VGG19。
VGG网络特点:
(1)结构简洁
虽然VGG层数较多,总的网络深度从11层到19层,但是它的整体结构还是相对简单。概括来说,VGG由5层卷积层(每个卷积层的子层数量不同)、3层全连接层、softmax输出层构成,层与层之间使用maxpooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数。
(2) 小卷积核
小卷积核是VGG的一个重要特点,VGG没有采用AlexNet中比较大的卷积核尺寸(如7x7),而是通过降低卷积核的大小(3x3),增加卷积子层数来达到同样的性能(VGG:从1到4卷积子层,AlexNet:1子层)。
VGG使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,VGG作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。示意图如下所示:
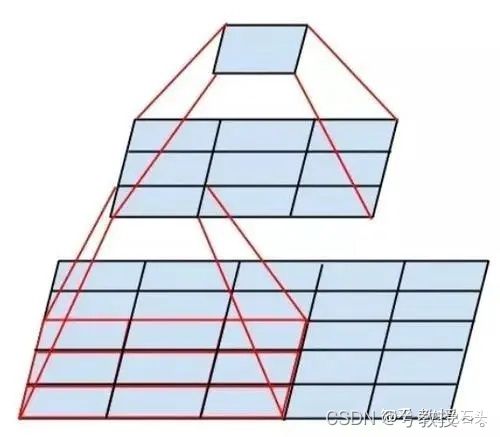
使用3x3小卷积核的好处有两个方面:
一是大幅度减少模型参数数量。例如使用2个3x3的卷积核代替1个5x5的卷积核,通道数为C,1个5x5的卷积核参数量为 5 ∗ 5 ∗ C 5*5*C 5∗5∗C,2个3x3的卷积核参数量为 2 ∗ 3 ∗ 3 ∗ C 2*3*3*C 2∗3∗3∗C,参数两减小了28%。另外,小卷积核选取小的 stride可以防止较大的stride导致细节信息的丢失。
二是多层卷积层(每个卷积层后都有非线性激活函数),增加非线性,提升模型性能。
此外,我们注意到在VGG网络结构D中,还使用了1x1卷积核,1x1卷积核可以在不改变感受野的情况下,增加模型的非线性(后面的非线性激活函数)。同时,还可以用它来整合各通道的信息,并输出指定通道数。通道数减小即降维,通道数增加即升维。
(3)小池化核
相比AlexNet的3x3的池化核,VGG全部采用2x2的池化核。
(4)通道数更多,特征度更宽
每个通道代表着一个FeatureMap,更多的通道数表示更丰富的图像特征。VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,通道数的增加,使得更多的信息可以被提取出来。
(5)层数更深
使用连续的3x3小卷积核代替大的卷积核,网络的深度更深,并且对边缘进行填充,卷积的过程并不会减小图像尺寸。仅使用小的2x2池化单元,减小图像的尺寸。
4.GoogLeNet
GoogLeNet在2014年由Google团队提出(与VGG网络同年,注意GoogLeNet中的L大写是为了致敬LeNet),斩获当年ImageNet竞赛中Classification Task (分类任务) 第一名。
Google Inception Net是一个大家族,包括:Inception V1-V4。
2014年9月的《Going deeper with convolutions》提出的Inception V1.
2015年2月的《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》提出的Inception V2
2015年12月的《Rethinking the Inception Architecture for Computer Vision》提出的Inception V3
2016年2月的《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》提出的Inception V4
InceptionV4的提出,是在ResNet之后。是Google对ResNet的挑战。
Inception-ResNetV1,Inception-ResNetV2这两个结构用来和InceptionV3和InceptionV4进行性能对比。
Inception V1
GoogLeNet的核心思想是:将全连接,甚至卷积中的局部连接,全部替换为稀疏连接。
又由于计算机计算稀疏矩阵的低效,因此提出将:稀疏矩阵聚类为密集的子矩阵

Inception V2
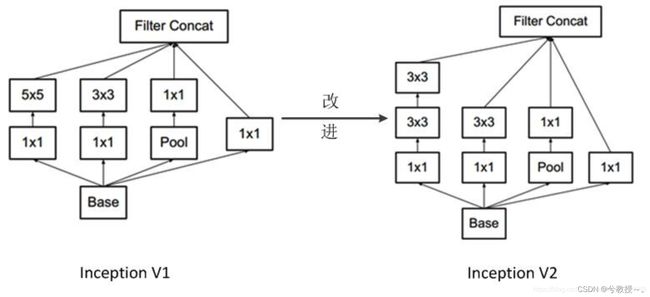
Inception v2加入了BN(Batch Normalization)层,并且使用2个 3 ∗ 3 3*3 3∗3替代1个 5 ∗ 5 5*5 5∗5卷积。
(1) 加入了BN层,减少了InternalCovariate Shift(内部neuron的数据分布发生变化),使每一层的输出都规范化到一个N(0, 1)的高斯,从而增加了模型的鲁棒性,可以以更大的学习速率训练,收敛更快,初始化操作更加随意,同时作为一种正则化技术,可以减少dropout层的使用。
(2) 用2个连续的 3 ∗ 3 3*3 3∗3 conv替代inception模块中的 5 ∗ 5 5*5 5∗5,从而实现网络深度的增加,网络整体深度增加了9层,缺点就是增加了25%的weights和30%的计算消耗。
Inception V3
Inception v3主要在v2的基础上,提出了卷积分解(Factorization)
(1) 将 7 ∗ 7 7*7 7∗7分解成两个一维的卷积( 1 ∗ 7 1*7 1∗7, 7 ∗ 1 7*1 7∗1), 3 ∗ 3 3*3 3∗3也是一样( 1 ∗ 3 1*3 1∗3, 3 ∗ 1 3*1 3∗1),这样的好处,既可以加速计算(多余的计算能力可以用来加深网络),又可以将1个conv拆成2个conv,使得网络深度进一步增加,增加了网络的非线性,更加精细设计了 35 ∗ 35 35*35 35∗35/ 17 ∗ 17 17*17 17∗17/ 8 ∗ 8 8*8 8∗8的模块。
(2) 增加网络宽度,网络输入从 224 ∗ 224 224*224 224∗224变为了 299 ∗ 299 299*299 299∗299。
Inception V4
Inception v4主要利用残差连接(Residual Connection)来改进v3结构,将Inception模块和ResidualConnection结合,使得训练加速收敛更快,精度更高。代表:Inception-ResNet-v1,Inception-ResNet-v2。
resnet中的残差结构如下,使用原始层和经过2个卷基层的feature map做Eltwise。

5.ResNet(里程碑式创新)
ResNet是一种残差网络,咱们可以把它理解为一个子网络,这个子网络经过堆叠可以构成一个很深的网络。咱们可以先简单看一下ResNet的结构
为什么要引入ResNet?
我们知道,网络越深,咱们能获取的信息越多,而且特征也越丰富。但是根据实验表明,随着网络的加深,优化效果反而越差,测试数据和训练数据的准确率反而降低了。这是由于网络的加深会造成梯度爆炸和梯度消失的问题。

目前针对这种现象已经有了解决的方法:对输入数据和中间层的数据进行归一化操作,这种方法可以保证网络在反向传播中采用随机梯度下降(SGD),从而让网络达到收敛。但是,这个方法仅对几十层的网络有用,当网络再往深处走的时候,这种方法就无用武之地了。
为了让更深的网络也能训练出好的效果,何凯明大神提出了一个新的网络结构——ResNet。这个网络结构的想法主要源于VLAD(残差的想法来源)和Highway Network(跳跃连接的想法来源)。
ResNet详解
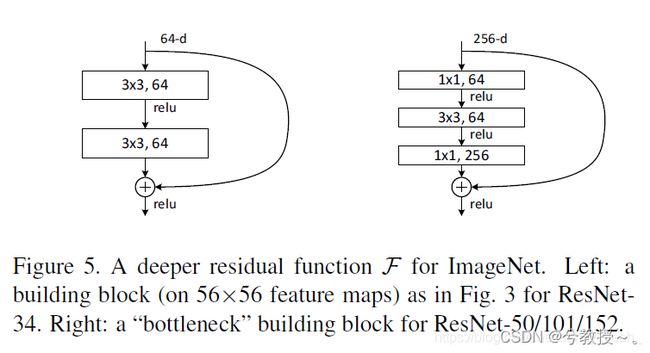
ResNet block有两种,一种两层结构,一种三层结构。
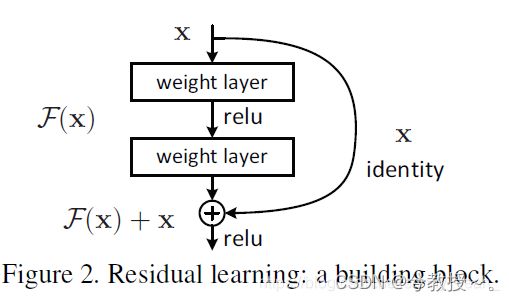
咱们要求解的映射为:H(x)
现在咱们将这个问题转换为求解网络的残差映射函数,也就是F(x),其中F(x) = H(x)-x。
残差:观测值与估计值之间的差。
这里H(x)就是观测值,x就是估计值(也就是上一层ResNet输出的特征映射)。
我们一般称x为identity Function,它是一个跳跃连接;称F(x)为ResNet Function。
那么咱们要求解的问题变成了H(x) = F(x)+x。(本人不是很懂,以下是其他作者回答)
有小伙伴可能会疑惑,咱们干嘛非要经过F(x)之后在求解H(x)啊!整这么麻烦干嘛!
如果是采用一般的卷积神经网络的化,原先咱们要求解的是H(x) = F(x)这个值对不?
那么,我们现在假设,在我的网络达到某一个深度的时候,咱们的网络已经达到最优状态了,也就是说,此时的错误率是最低的时候,再往下加深网络的化就会出现退化问题(错误率上升的问题)。咱们现在要更新下一层网络的权值就会变得很麻烦,权值得是一个让下一层网络同样也是最优状态才行。对吧?
但是采用残差网络就能很好的解决这个问题。还是假设当前网络的深度能够使得错误率最低,如果继续增加咱们的ResNet,为了保证下一层的网络状态仍然是最优状态,咱们只需要把令F(x)=0就好啦!因为x是当前输出的最优解,为了让它成为下一层的最优解也就是希望咱们的输出H(x)=x的话,是不是只要让F(x)=0就行了?
当然上面提到的只是理想情况,咱们在真实测试的时候x肯定是很难达到最优的,但是总会有那么一个时刻它能够无限接近最优解。采用ResNet的话,也只用小小的更新F(x)部分的权重值就行啦!不用像一般的卷积层一样大动干戈!
注意:如果残差映射(F(x))的结果的维度与跳跃连接(x)的维度不同,那咱们是没有办法对它们两个进行相加操作的,必须对x进行升维操作,让他俩的维度相同时才能计算。
升维的方法有两种:
全0填充;
采用1*1卷积。
最后的实验结果表明,ResNet在上百层都有很好的表现,但是当达到上千层了之后仍然会出现退化现象。不过在2016年的Paper中对ResNet的网络结构进行了调整,使得当网络达到上千层的时候仍然具有很好的表现。