微表情识别的图片预处理(python版)
文章目录
- 前言
- 一、人脸旋转
- 二、人脸裁剪
前言
微表情识别类似于表情识别,在处理时的不同之处在于微表情的关注区域是特定的(AU),所以我们在裁剪人脸的时候也是主要获得该区域,我们实验室之前用的都是matlab代码,刚刚把它转为了python代码。
一、人脸旋转
方法就是采用dlib68模型找到双眼的位置,计算需要旋转的角度,然后做仿射变换,代码如下
import cv2
import dlib
import numpy as np
# 脸部旋转函数
def face_rotate(img, left_eye_x, left_eye_y, right_eye_x, right_eye_y):
center_x, center_y = int((left_eye_x + right_eye_x) / 2), int((left_eye_y + right_eye_y) // 2)
dx, dy = right_eye_x - left_eye_x, right_eye_y - left_eye_y
# 计算角度
angle = np.degrees(np.arctan2(dy, dx))
# 计算仿射矩阵
warp_matrix = cv2.getRotationMatrix2D((center_x, center_y), angle, 1)
# 进行仿射变换,即旋转
rotated_img = cv2.warpAffine(img, warp_matrix, (img.shape[1], img.shape[0]))
return rotated_img
# 脸部剪裁函数
def face_crop(img, left_eye_x, left_eye_y, right_eye_x, right_eye_y, noise_y):
x_min = left_eye_x - (right_eye_x - left_eye_x)
y_min = int((left_eye_y + right_eye_y) / 2 - (noise_y - (left_eye_y + right_eye_y) / 2))
width = 3 * (right_eye_x - left_eye_x)
height = 3 * (noise_y - (left_eye_y + right_eye_y) // 2)
return img[y_min:y_min + height, x_min:x_min + width]
# 加载模型
predictor_model = r'C:\Users\S\Desktop\python\model\dlib\shape_predictor_68_face_landmarks.dat'
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(predictor_model)
# cv2读取图像
test_film_path = r"C:\Users\S\Desktop\img1024-model\0082.png"
img = cv2.imread(test_film_path)
# 取灰度,检测人脸
img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
rects = detector(img_gray, 0)
for i in range(len(rects)):
landmarks = np.matrix([[p.x, p.y] for p in predictor(img, rects[i]).parts()])
left_eye_x, left_eye_y = landmarks[39][0, 0], landmarks[39][0, 1]
right_eye_x, right_eye_y = landmarks[42][0, 0], landmarks[42][0, 1]
noise_x, noise_y = landmarks[33][0, 0], landmarks[33][0, 1]
rotated_img = face_rotate(img, left_eye_x, left_eye_y, right_eye_x, right_eye_y)
# crop_img = face_crop(img, left_eye_x, left_eye_y, right_eye_x, right_eye_y, noise_y)
# cv2.imwrite("rotated_img.jpg", rotate_img)
cv2.imshow("source",img)
cv2.imshow("rotated_img", rotated_img)
# cv2.imwrite("croped_img.jpg", croped_img)
# cv2.imshow("croped_img", croped_img)
cv2.waitKey(0)
效果:
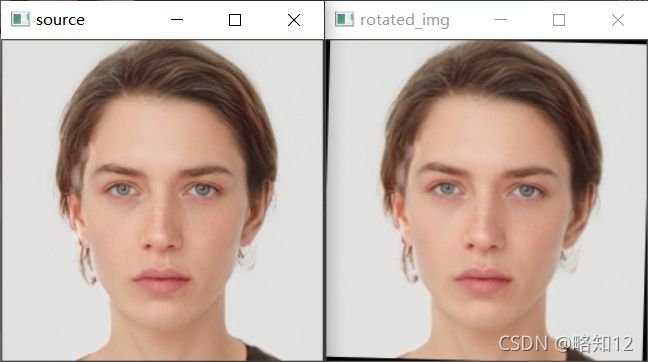
二、人脸裁剪
方法就是根据双眼和鼻子的位置,向左右各扩展双眼的长度,向上下各扩展眼睛到鼻子的垂直距离,代码如下:
import cv2
import dlib
import numpy as np
# 脸部旋转函数
def face_rotate(img, left_eye_x, left_eye_y, right_eye_x, right_eye_y):
center_x, center_y = int((left_eye_x + right_eye_x) / 2), int((left_eye_y + right_eye_y) // 2)
dx, dy = right_eye_x - left_eye_x, right_eye_y - left_eye_y
# 计算角度
angle = np.degrees(np.arctan2(dy, dx))
# 计算仿射矩阵
warp_matrix = cv2.getRotationMatrix2D((center_x, center_y), angle, 1)
# 进行仿射变换,即旋转
rotated_img = cv2.warpAffine(img, warp_matrix, (img.shape[1], img.shape[0]))
return rotated_img
# 脸部剪裁函数
def face_crop(img, left_eye_x, left_eye_y, right_eye_x, right_eye_y, noise_y):
x_min = left_eye_x - (right_eye_x - left_eye_x)
y_min = int((left_eye_y + right_eye_y) / 2 - (noise_y - (left_eye_y + right_eye_y) / 2))
width = 3 * (right_eye_x - left_eye_x)
height = 3 * (noise_y - (left_eye_y + right_eye_y) // 2)
# 下面这个返回的是完全按照规则裁的
# return img[y_min:y_min + height, x_min:x_min + width]
# 下面这个,得到的是一张长宽相同的图
croped_img = img[y_min:y_min + height, left_eye_x + (right_eye_x - left_eye_x)//2-3 * (noise_y - (left_eye_y + right_eye_y) // 2)//2:left_eye_x + (right_eye_x - left_eye_x)//2+3 * (noise_y - (left_eye_y + right_eye_y) // 2)//2]
# 这里resize有两种方法可以得到深度学习所需要的数据,一是将后面长宽不同的图拉伸为224(一般是224);二是将后面长宽相同的图简单resize一下,这里设的是128,有特殊用途,一般是224
resize_img = cv2.resize(croped_img,(128,128),interpolation=cv2.INTER_AREA)
return resize_img
# 加载模型
predictor_model = r'C:\Users\S\Desktop\python\model\dlib\shape_predictor_68_face_landmarks.dat'
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(predictor_model)
# cv2读取图像
test_film_path = r"C:\Users\S\Desktop\train\\0720.jpg"
img = cv2.imread(test_film_path)
# 取灰度,检测人脸
img_gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
rects = detector(img_gray, 0)
for i in range(len(rects)):
landmarks = np.matrix([[p.x, p.y] for p in predictor(img, rects[i]).parts()])
left_eye_x, left_eye_y = landmarks[39][0, 0], landmarks[39][0, 1]
right_eye_x, right_eye_y = landmarks[42][0, 0], landmarks[42][0, 1]
noise_x, noise_y = landmarks[33][0, 0], landmarks[33][0, 1]
# rotated_img = face_rotate(img, left_eye_x, left_eye_y, right_eye_x, right_eye_y)
croped_img = face_crop(img, left_eye_x, left_eye_y, right_eye_x, right_eye_y, noise_y)
# cv2.imwrite("rotated_img.jpg", rotate_img)
cv2.imshow("source",img)
# cv2.imshow("rotated_img", rotated_img)
#cv2.imwrite("croped_img.jpg", croped_img)
cv2.imshow("croped_img", croped_img)
cv2.waitKey(0)
效果:

这样就基本包含了常见的au区域,可以送进网络进行训练了