网站、数据库的衍变之路(三)
话接前文《网站、数据库的衍变之路(二)》。上文讲了几种静态化方案的利弊,有朋友要讲详细一点,呵呵,这不属于本文的范畴。也有朋友说有些网站不适合搞静态化,是有这种情况。但是在这个时期,网站还处于刚发展的起始阶段。初期的网站用户量往往很小,都是以提供咨询为主,典型的web1.0系统,静态化方案是和这个背景紧密相关的。而随着网站的逐步发展又会遇到些什么样的问题呢?这个要看网站发展的实际情况。大体上分为两类:一、就是做资讯的,用户一般是从搜索引擎过来的,没有多少的交互任务;二、以做SNS或者论坛这类互动性高的产品的(用论坛提供下载或者文字阅读的不在此例)。
一、提供内容为主的系统
对于第一种提供内容的网站而言,会出现两种情况。一种是数据容量过大,由于早期设计失误,造成数据库访问速度很慢;第二种是访问人数过多,造成IIS响应不过来,反映在访问速度慢或者干脆报Service Unavailable错误。或者两种情况都发生了。
对于数据访问慢的情况,需要对数据库进行优化。包括优化查询语句,优化数据库结构,索引优化。而对于单表数据好几千万条的优化则需要进行分表。在SQL2005以前版本中并没有,没有使用内置的表分区功能,需要自己实现。策略一般是按照时间,把数据放到不同的表中。然后再使用视图功能把表查询聚合到一起。这种方式和SQL2005带的表分区相比有很大不同,效率远比SQL2005带的要低。为什么呢?比如SQL2000,建立两张相同结构的表,储存数据。表一和表二都是500万数据。查询时,先从表1筛选到数据,再从表二筛选到数据,然后合并,再按条件排序,还是单线程的,这能不慢吗?而SQL2005是可以把索引放到不同的分区,多线程地去操作,由于是在进程内完成数据的筛选排序,速度还是很快。当然,前提是服务器有很多个核。(SQL2005表分区只在服务器版中可以使用。)
对于IIS响应慢或者Service Unavailable的情况,有可能是带宽太小,也可能是连接数太多了。我记得有人做过测试,IIS的TCP连接数最大大概是8000的样子,Unix下的Apache(还是httpd忘记了。)最大连接数一万多。好像说是操作系统TCP/IP堆栈的限制,我对这方面不太懂。如果超过这个量或者是其它类似的原因造成了web服务不稳定,那么就该加服务器了。
二、互动性高的系统
互动性高的系统容易遇到的问题是数据库高并发。数据库的很多操作是有锁的,锁保存在系统表里,如果系统的吞吐量也满足不了需要,那么锁就会出现问题了。你可以认为,数据库一次至多只能有100个连接(在SQL2005服务器版本上测试)。如果超出了,那么,第101个就会超时。假如有一条语句操作时间很长,也操作频繁,那么应该很容易就引起数据库超时的错误。
这种系统,如果数据库本身已经满足不了了,可以用拦截器来解决。用拦截器也需要考虑怎么设计方案。假设现在每秒钟有100条数据库操作命令,而这100条命令各不相同,并且数据库1秒钟刚好能处理这100条命令。那现在每秒钟有101条命令,并且命令还是各不相同,每秒中与每秒钟产生的命令也是不相同的,那么做拦截器也是毫无用处的。最多只能有一个缓解作用。因为每秒钟都会增加一条无法处理的命令。

图2.1
幸运的是,在处理的语句中有很多是重复的。比如,现在拦截器如图2.1一样工作,在1秒钟内,拦截了101条命令,归并出有20条语句都是查询的同样的内容(一般是列表页),最后整理出实际需要操作40条命令,然后执行命令,拿到数据库后分发给这101个请求。也就是说101个工作被压缩成了40个工作。
还可以对某些不常变动的数据进行缓存。比如文章的分类,用户的名字(这个要看注册用户增长的情况)。图2.1的模型改成图2.2的情况。
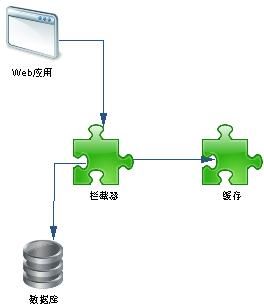
图2.2
当然缓存块也可以加在Web应用的部分。主要用来保存一段时间内不更新的数据,当然,这个缓存是有过期策略的。
对于SQL查询的优化,缓存也能帮到一定的忙。比如,有个联合查询,查询的是文章分类表和文章表。完全可以只查文章表,而文章表中只有分类ID,显示的时候怎么办?在内存中,缓存了一个分类字典,键就是分类ID,值就是分类名称。显示的时候,直接用文章内分类ID在字典中找。这样就提高了SQL语句的效率。
而出现大表的情况,还是参考本文的第一部分解决。
现在,本文还有一个问题没解决呢,那是第一部分遗留的。要增加服务器,那怎么部署呢?