hadoop中OutputFormat 接口的设计与实现
OutputFormat 主要用于描述输出数据的格式,它能够将用户提供的 key/value 对写入特定格式的文件中。 本文将介绍 Hadoop 如何设计 OutputFormat 接口 , 以及一些常用的OutputFormat 实现。
1.旧版 API 的 OutputFormat 解析
如图所示, 在旧版 API 中,OutputFormat 是一个接口,它包含两个方法:
RecordWriter<K, V> getRecordWriter(FileSystem ignored, JobConf job, String name, Progressable progress) throws IOException; void checkOutputSpecs(FileSystem ignored, JobConf job) throws IOException;
checkOutputSpecs 方法一般在用户作业被提交到 JobTracker 之前, 由 JobClient 自动调用,以检查输出目录是否合法。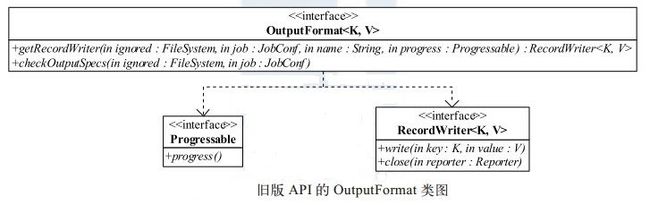
getRecordWriter 方法返回一个 RecordWriter 类对象。 该类中的方法 write 接收一个key/value 对, 并将之写入文件。在 Task 执行过程中, MapReduce 框架会将 map() 或者reduce() 函数产生的结果传入 write 方法, 主要代码(经过简化)如下。假设用户编写的 map() 函数如下:
public void map(Text key, Text value, OutputCollector<Text, Text> output, Reporter reporter) throws IOException { // 根据当前 key/value 产生新的输出 <newKey, newValue>, 并输出 …… output.collect(newKey, newValue); }
则函数 output.collect(newKey, newValue) 内部执行代码如下:
RecordWriter<K, V> out = job.getOutputFormat().getRecordWriter(...);
out.write(newKey, newValue);
Hadoop 自带了很多OutputFormat 实现, 它们与 InputFormat 实现相对应,具体如图所示。所有基于文件的 OutputFormat 实现的基类为 FileOutputFormat, 并由此派生出一些基于文本文件格式、 二进制文件格式的或者多输出的实现。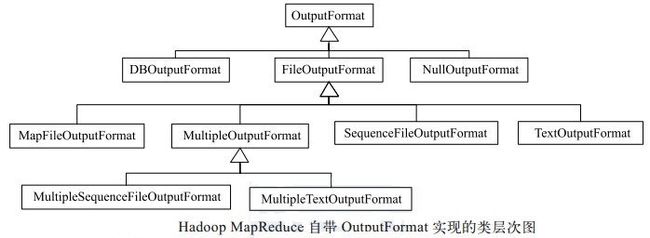
为了深入分析OutputFormat的实现方法,选取比较有代表性的FileOutputFormat类进行分析。同介绍 InputFormat 实现的思路一样,我们先介绍基类FileOutputFormat,再介绍其派生类 TextOutputFormat。基类 FileOutputFormat 需要提供所有基于文件的 OutputFormat 实现的公共功能,总结起来,主要有以下两个:
(1) 实现 checkOutputSpecs 接口
该接口 在作业运行之前被调用, 默认功能是检查用户配置的输出目 录是否存在,如果存在则抛出异常,以防止之前的数据被覆盖。
(2) 处理 side-effect file
任务的 side-effect file 并不是任务的最终输出文件,而是具有特殊用途的任务专属文件。 它的典型应用是执行推测式任务。 在 Hadoop 中,因为硬件老化、网络故障等原因,同一个作业的某些任务执行速度可能明显慢于其他任务,这种任务会拖慢整个作业的执行速度。为了对这种“ 慢任务” 进行优化, Hadoop 会为之在另外一个节点上启动一个相同的任务,该任务便被称为推测式任务,最先完成任务的计算结果便是这块数据对应的处理结果。为防止这两个任务同 时往一个输出 文件中 写入数据时发生写冲突, FileOutputFormat会为每个 Task 的数据创建一个 side-effect file,并将产生的数据临时写入该文件,待 Task完成后,再移动到最终输出目 录中。 这些文件的相关操作, 比如创建、删除、移动等,均由 OutputCommitter 完成。它是一个接口,Hadoop 提供了默认实现 FileOutputCommitter,用户也可以根据自己的需求编写 OutputCommitter 实现, 并通过参数 {mapred.output.committer.class} 指定。OutputCommitter 接口定义以及 FileOutputCommitter 对应的实现如表所示。
表-- OutputCommitter 接口定义以及 FileOutputCommitter 对应的实现
| 方法 | 何时被调用 | FileOutputCommitter 实现 |
| setupJob | 作业初始化 | 创建临时目录 ${mapred.out.dir} /_temporary |
| commitJob | 作业成功运行完成 | 删除临时目录,并在${mapred.out.dir} 目录下创建空文件_SUCCESS |
| abortJob | 作业运行失败 | 删除临时目录 |
| setupTask | 任务初始化 | 不进行任何操作。原本是需要在临时目录下创建 side-effect file 的,但它是用时创建的(create on demand) |
| needsTaskCommit | 判断是否需要提交结果 | 只要存在side-effect file,就返回 true |
| commitTask | 任务成功运行完成 | 提交结果, 即将 side-effect file 移动到 ${mapred.out.dir} 目录下 |
| abortTask | 任务运行失败 | 删除任务的 side-effect file注意默认情况下,当作业成功运行完成后,会在最终结果目录 ${mapred.out.dir} 下生成 |
注意:默认情况下,当作业成功运行完成后,会在最终结果目录 ${mapred.out.dir} 下生成空文件 _SUCCESS。该文件主要为高层应用提供作业运行完成的标识,比如,Oozie 需要通过检测结果目 录下是否存在该文件判 断作业是否运行完成。
2. 新版 API 的 OutputFormat 解析
如图所示,除了接口变为抽象类外,新 API 中的 OutputFormat 增加了一个新的方法:getOutputCommitter,以允许用户自 己定制合适的 OutputCommitter 实现。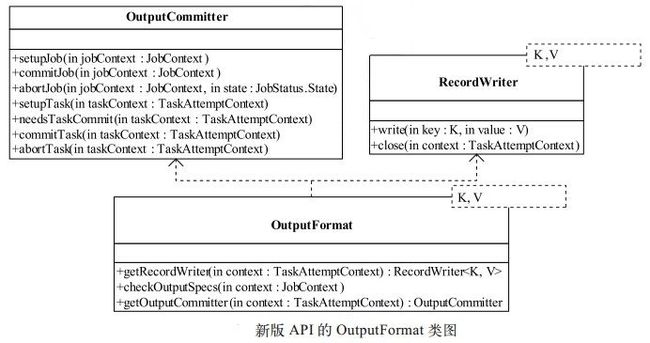
参考资料
《Hadoop技术内幕 深入理解MapReduce架构设计与实现原理》