Faster RCNN超详细入门 01-准备篇-背景 RCNN,SPPnet,Fast RCNN,RoI Pooling
文章目录
- Faster RCNN学习目标
- 研究背景
-
- 图像处理三大任务
- RCNN
- SPP net (Spatial Pyramid Pooling)
-
- 1.特征
- 2.ResNet+SPPnet代码如下:
- 3.改进RCNN:
-
- a.R-CNN的整个过程:
- b.SPP-Net整个过程:
- Fast RCNN
-
- 1.RCNN的缺陷
- 2.Fast R-CNN优点:
- 3.核心:
- Faster RCNN的历史意义
Faster RCNN学习目标
1.预处理
纵横比
归一化
2.后处理
NMS
3.数据集
Pascal Voc
COCO
4.网络架构
骨干网与特征共享计算
- VGG
- ResNet
候选区域提取网络RPN
Anchor与Proposal
分类网络
双阶段网络
5.网络训练
6.回归机制
7.研究背景
- RCNN
- SPP net
- Fast RCNN
研究背景
图像处理三大任务
- 物体识别
- 目标检测
- 图像分割
RCNN
1.意义:首先将深度学习引入目标检测领域,mAP由DPM的35.1提升至53.7
2.基础算法流程
- 一张图像生成1k~2k个候选区域
- 对于每个候选区域,使用深度网路提取特征
- 特征送入每一类的SVM分类器,判断是否属于该类
- 使用回归器修正候选框位置
3.存在问题
- 尺寸归一化导致物体变形,纵横比特征丢失
- 重复使用网络计算特征,低实时性(单图像GPU处理时间14s)
SPP net (Spatial Pyramid Pooling)

1.特征
- 提出金字塔池化操作,可以适应任何大小的输入图像。
- 计算整幅图像的特征图,根据相应位置进行截取。
- 使用了多级别的空间箱(bin),而滑窗池化则只用了一个窗口尺寸。多级池化对于物体的变形十分鲁棒。
- 由于其对输入的灵活性,SPP可以池化从各种尺度抽取出来的特征。
- 将图像切分成粗糙到精细各种级别,然后整合其中的局部特征。
2.ResNet+SPPnet代码如下:
import torch
from torch import nn
from torchvision import models
import torch.nn.functional as F
import os, math
from torch.nn.modules.pooling import AdaptiveAvgPool2d, AdaptiveMaxPool2d
class ResNet(nn.Module):
def __init__(self, layers=18, num_class=2, pretrained=True):
super(ResNet, self).__init__()
if layers == 18:
self.resnet = models.resnet18(pretrained=pretrained)
elif layers == 34:
self.resnet = models.resnet34(pretrained=pretrained)
elif layers == 50:
self.resnet = models.resnet50(pretrained=pretrained)
elif layers == 101:
self.resnet = models.resnet101(pretrained=pretrained)
elif layers == 152:
self.resnet = models.resnet152(pretrained=pretrained)
else:
raise ValueError('layers should be 18, 34, 50, 101.')
self.num_class = num_class
if layers in [18, 34]:
self.fc = nn.Linear(512, num_class)
if layers in [50, 101, 152]:
self.fc = nn.Linear(512 * 4, num_class)
def conv_base(self, x):
x = self.resnet.conv1(x)
x = self.resnet.bn1(x)
x = self.resnet.relu(x)
x = self.resnet.maxpool(x)
layer1 = self.resnet.layer1(x)
layer2 = self.resnet.layer2(layer1)
layer3 = self.resnet.layer3(layer2)
layer4 = self.resnet.layer4(layer3)
return layer1, layer2, layer3, layer4
def forward(self, x):
layer1, layer2, layer3, layer4 = self.conv_base(x)
x = self.resnet.avgpool(layer4)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
class SPPNet(nn.Module):
def __init__(self, backbone=101, num_class=2, pool_size=(1, 2, 6), pretrained=True):
# Only resnet is supported in this version
super(SPPNet, self).__init__()
if backbone in [18, 34, 50, 101, 152]:
self.resnet = ResNet(backbone, num_class, pretrained)
else:
raise ValueError('Resnet{} is not supported yet.'.format(backbone))
if backbone in [18, 34]:
self.c = 512
if backbone in [50, 101, 152]:
self.c = 2048
self.spp = SpatialPyramidPool2D(out_side=pool_size)
num_features = self.c * (pool_size[0] ** 2 + pool_size[1] ** 2 + pool_size[2] ** 2)
self.classifier = nn.Linear(num_features, num_class)
def forward(self, x):
_, _, _, x = self.resnet.conv_base(x)
x = self.spp(x)
x = self.classifier(x)
return x
class SpatialPyramidPool2D(nn.Module):
"""
Args:
out_side (tuple): Length of side in the pooling results of each pyramid layer.
Inputs:
- `input`: the input Tensor to invert ([batch, channel, width, height])
"""
def __init__(self, out_side):
super(SpatialPyramidPool2D, self).__init__()
self.out_side = out_side
def forward(self, x):
# batch_size, c, h, w = x.size()
out = None
for n in self.out_side:
# w_r, h_r = map(lambda s: math.ceil(s / n), x.size()[2:]) # Receptive Field Size
# s_w, s_h = map(lambda s: math.floor(s / n), x.size()[2:]) # Stride
# max_pool = nn.MaxPool2d(kernel_size=(w_r, h_r), stride=(s_w, s_h))
max_pool = AdaptiveMaxPool2d(output_size=(n, n))
y = max_pool(x)
if out is None:
out = y.view(y.size()[0], -1)
else:
out = torch.cat((out, y.view(y.size()[0], -1)), 1)
return out
多尺度训练:不用尺度size分别跑同一个epoch,能够提升准确度。
主要目的是在保证已经充分利用现在被较好优化的固定尺寸网络实现的同时,模拟不同的输入尺寸。
if __name__ == '__main__':
train_loader_350, test_loader_350 = load(350)
train_loader_400, test_loader_400 = load(400)
train_loader_450, test_loader_450 = load(450)
train_loader_500, test_loader_500 = load(500)
train_loaders = [train_loader_350, train_loader_400, train_loader_450, train_loader_500]
test_loaders = [test_loader_350, test_loader_400, test_loader_450, test_loader_500]
model = SPPNet().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.0001, betas=(0.9, 0.99))
criterion = nn.CrossEntropyLoss()
for epoch in range(1, EPOCH + 1):
for train_loader, test_loader in zip(train_loaders, test_loaders):
train(model, device, train_loader, criterion, optimizer, epoch)
test(model, device, test_loader, criterion, epoch)
torch.save(model, save_path)
3.改进RCNN:
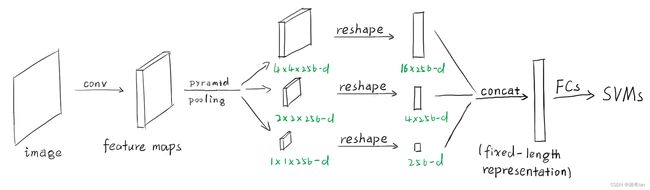
a.R-CNN的整个过程:
1.通过选择性搜索,对待检测的图片进行搜索出~2000个候选窗口。
2.把这2k个候选窗口的图片都缩放到227*227,然后分别输入CNN中,每个proposal提取出一个特征向量,(即:利用CNN对每个proposal进行提取特征向量。)
3.把上面每个候选窗口的对应特征向量,利用SVM算法进行分类识别。 可以看出R-CNN的计算量是非常大的,因为2000个候选窗口都要输入到CNN中,分别进行特征提取。
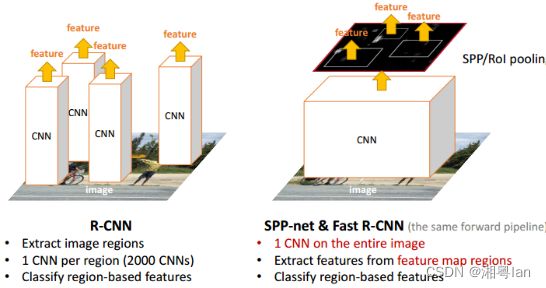
b.SPP-Net整个过程:
1.首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。(这一步和R-CNN一样)。
2.特征提取阶段。区别!! 这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到特征图,然后在特征图中找到各个候选框的区域,再对各个候选框采用空间金字塔池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度会大大提升。
3.最后一步,采用SVM算法进行特征向量分类识别。
Fast RCNN
1.RCNN的缺陷
训练在时间和空间上是的开销很大。对于SVM和检测框回归训练,从每个图像中的每个目标候选框提取特征,并写入磁盘。
针对传统的CNN来说,输入的map需要时固定尺寸的,而归一化过程中对图片产生的形变会导致图片大小改变,这对CNN的特征提取有致命的坏处;
每个region proposal都需要进入CNN网络计算。进而会导致过多次的重复的相同的特征提取,这一举动会导致大大的计算浪费。
2.Fast R-CNN优点:
比R-CNN和SPPnet具有更高的目标检测精度(mAP)。
训练是使用多任务损失的单阶段训练。
训练可以更新所有网络层参数。
需要磁盘空间缓存特征。
3.核心:
RoI (Region of Interest) Pooling layer:
思路:在最后一个卷积层后加了一个roi pooling layer层。在每一个图像上只运行一次 CNN,并找到一种在 ~2000 个推荐里共享计算的方式。RoIPool 会对图像的所有子区域共享 CNN 的forward pass。
作用:将图像中的ROI区域定位到卷积特征中的对应位置;将这个对应后的卷积特征区域通过池化操作固定到特定长度的特征,然后将特征送入全连接层。
把不同模型整合为一个网络:损失函数使用多任务损失函数 multi-task loss,将边框回归bounding box regression 直接加入CNN网络中训练。
Faster RCNN的历史意义
首个端到端学习的深度检测网络,实时性与准确率均达当时最优。
推动了深度学习在检测任务中的应用,加速目标检测的研究。