【实战】——基于机器学习回归模型对广州二手房价格进行分析及模型评估
目录
- 1、数据导入
- 2、数据清洗
-
- 2.1、变量选取
- 2.2、空值处理
- 2.3、类型转化
- 2.4、数据再处理
- 3、机器学习sklearn的实现
-
- 3.1、训练集和测试集的拆分
- 3.2、数据的标准化
- 3.3、线性回归模型
- 3.4、随机森林模型
- 结语
1、数据导入
首先是数据分析不可或缺的模块导入
import numpy as np
import pandas as pd
然后就是数据的导入了,数据的获取的方法有很多,比如sklearn.datasets模块内置的数据加利福尼亚的房价fetch_california_housing
而我这里选取的数据来源是广州链家二手房网站的数据,一共有4W+个数据
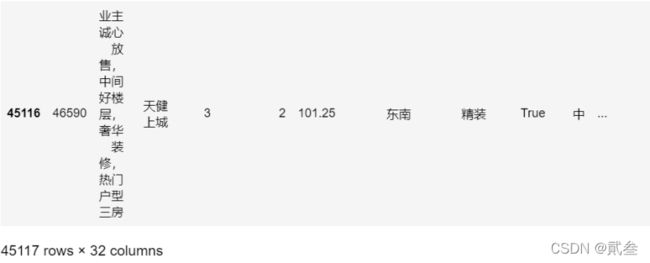
df = pd.read_csv('...\\house.csv', encoding='gbk')
df
2、数据清洗
由于数据是在网站上爬取的,其中有部分数据是我们不需要的,有的数据是需要修改的,因此要对数据进行清洗整理
2.1、变量选取
首先,找出可用的、对二手房价格产生显著影响的变量
gzdf = df[['room','livingroom','area','decoration','elevator','level','total_level','building_year','unit_price']]
gzdf.head()
在这里,我认为需要纳入模型的变量一共有8个,分别是:
| 变量 | 描述 |
|---|---|
| room | 卧室数量 |
| livingroom | 客厅数量 |
| area | 房屋面积 |
| decoration | 装修程度 |
| elevator | 是否有电梯 |
| level | 房子所属楼层高度 |
| total_level | 楼层总高度 |
| building_year | 建成年份 |
最后就是我们的目标变量:
| 目标变量 | 描述 |
|---|---|
| unit_price | 每平方价格 |

2.2、空值处理
大家如果仔细观察所有筛选出来的数据就可以发现,其中有一些数据是空的或者是NaN,所以要对这些空数据进行处理:
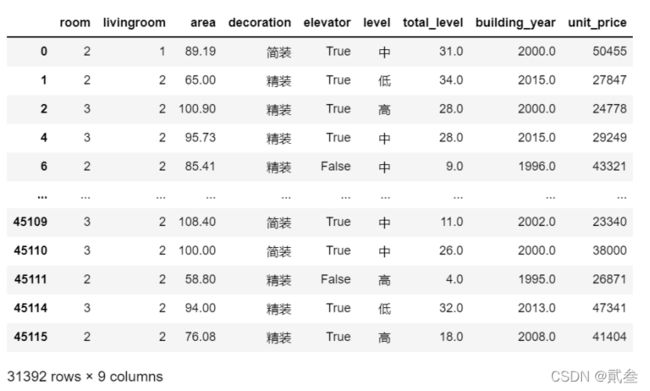
gzdf = gzdf.dropna(axis=0, how='any', thresh=None, subset=['room','livingroom','area','decoration','elevator','level','total_level','building_year','unit_price'], inplace=False)
gzdf
因为这里我觉得数据量充足,就直接将那些包含空值的行进行删除,得出结果还有3w+个数据:
2.3、类型转化
因为其中有些变量是文本类型的,不利于对数据进行分析,所以接下来就是将这些变量的数据转换成数量数据:
装修程度
gzdf['decoration'][gzdf['decoration']=='毛坯'] = 1
gzdf['decoration'][gzdf['decoration']=='简装'] = 2
gzdf['decoration'][gzdf['decoration']=='精装'] = 3
gzdf

是否拥有电梯
gzdf['elevator'][gzdf['elevator']==False] = 0
gzdf['elevator'][gzdf['elevator']==True] = 1
gzdf

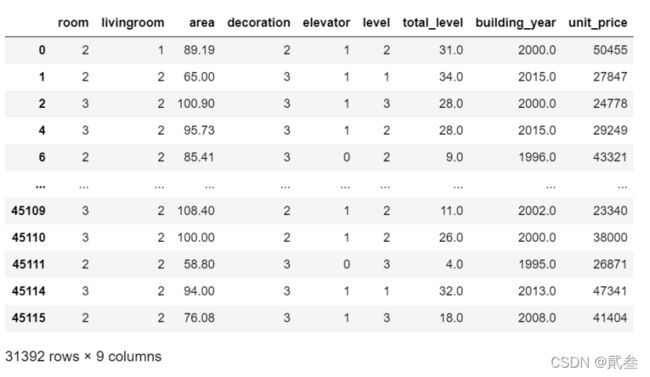
房屋所处楼层高度
gzdf['level'][gzdf['level']=='低'] = 1
gzdf['level'][gzdf['level']=='中'] = 2
gzdf['level'][gzdf['level']=='高'] = 3
gzdf
2.4、数据再处理
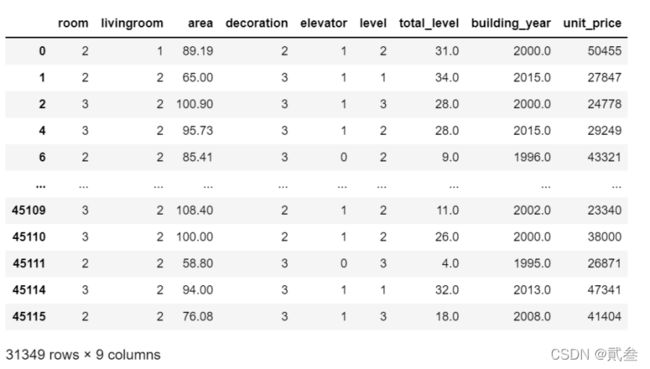
原本以为这样就可以了,可没想到后来进行模型回归时一直报错,一直找不到问题所在,最后只能将这些数据导出查看,发现原来unit_price等变量中有些数据竟然是“精装、简装”,导致数据清洗不干净,所以只能再次处理一下数据了
gzdf = gzdf[gzdf['unit_price']!='精装']
gzdf = gzdf[gzdf['unit_price']!='简装']
gzdf = gzdf[gzdf['decoration']!='其他']
gzdf
还好数据量不算太少,不然就不能直接删除掉这些数据了
3、机器学习sklearn的实现
数据处理就告一段落了,接下来是机器学习部分的内容了
3.1、训练集和测试集的拆分
首先,将所有数据拆分成训练集和测试集
from sklearn.model_selection import train_test_split
x = gzdf.drop(['unit_price'], axis=1)
y = gzdf['unit_price']
train_x, test_x, train_y, test_y = train_test_split(x,y,test_size=0.2, random_state=42)
3.2、数据的标准化
并且将数据标准化,有利于提高模型回归的准确度
from sklearn.preprocessing import StandardScaler
ss = StandardScaler().fit(train_x)
train_x = pd.DataFrame(ss.transform(train_x), columns = train_x.columns)
test_x = pd.DataFrame(ss.transform(test_x), columns = test_x.columns)
train_x
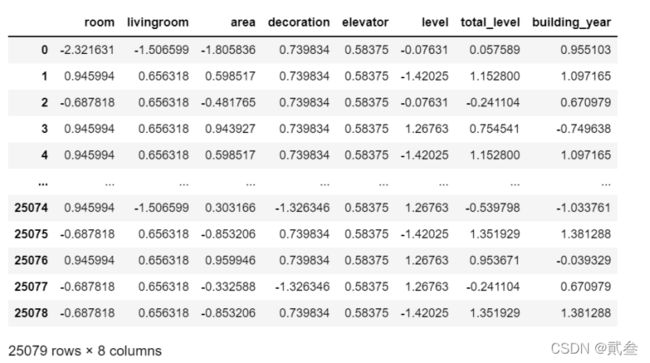
可以看到,训练集一共有2.5w+,所以测试集数据量大概也就是6000+
3.3、线性回归模型
在众多的回归模型中,我们最熟悉的、用得较多的就是线性回归了。线性回归的好处就是简单,但缺点就是其回归结果不太理想。
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(train_x, train_y)
lrscore = lr.score(test_x,test_y)*100
print("sklearn线性回归模型得分:{}%".format(lrscore))
![]()
模型评估的score描述的是回归模型的R方,数值越趋近于1,表示模型回归结果越好。但从这里可以看到线性回归模型的评估得分不太好
接下来让我们将真实数据和预测数据可视化,可以更加直接地观察到回归结果的好坏
import matplotlib.pyplot as plt
from matplotlib import rcParams
lr_pred=lr.predict(test_x)
real_data = test_y[:200]
lr_data = lr_pred[:200]
fig = plt.figure(figsize=(20,16))
plt.plot(range(len(real_data)),real_data,'r',label='real_data',linewidth=3)
plt.plot(range(len(lr_data)),lr_data,'g--',label='lr_data',linewidth=2)
fig.tight_layout()
plt.legend(loc='best')
plt.title("sklearn线性回归模型")
plt.show()
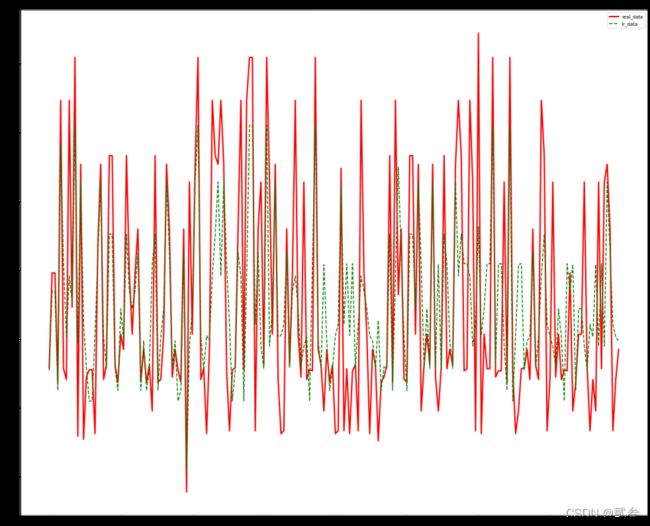
这里选取了测试集的前200个数据,红色实线表示真实数据,绿色虚线表示预测数据,可以看到预测的结果并不理想。
3.4、随机森林模型
随机森林(Random forest)指的是利用多棵树对样本进行训练并预测的一种分类器,可以产生高准确度的模型。
from sklearn import ensemble
model_rf = ensemble.RandomForestRegressor(n_estimators=20)
model_rf.fit(train_x, train_y)
rf_score = model_rf.score(test_x,test_y)*100
print("sklearn随机森林模型得分:{}%".format(rf_score))
rf_pred=model_rf.predict(test_x)
![]()
可以看到随机森林模型R方达到0.888,可以说是相当高的了
import matplotlib.pyplot as plt
from matplotlib import rcParams
real_data = test_y[:200]
rf_data = rf_pred[:200]
fig = plt.figure(figsize=(20,16))
plt.plot(range(len(real_data)),real_data,'r',label='real_data',linewidth=3)
plt.plot(range(len(rf_data)),rf_data,'g--',label='rf_data',linewidth=2)
fig.tight_layout()
plt.legend(loc='best')
plt.title("sklearn随机森林模型")
plt.show()

接下来选取数据的前200个进行可视化,通过上图可以很直接地观察到大部分数据预测的结果很准确,只有少部分误差。我们也可以随机选取200个数据进行可视化:

总体上看还是可以的,只是个别较为特殊的数据拟合的不好,可能存在一些没有纳入模型但却对目标变量产生影响的变量没有考虑到。
结语
关于机器学习回归模型就说到这里了,如果觉得写的不错文章写的不错的小伙伴记得点赞、关注、收藏三连哦~
相关数据及代码在我的资源上,大家可以下载下来自己练一练