数据探索与数据预处理的实验报告
数据探索与数据预处理
提示
参考书:张良均《Python数据分析与挖掘实战》等。
数据文件:课本自带数据。
使用软件:Pycharm。
类别:实验。
温馨提示:该实验是跟张良均这本书配合使用的,代码运行于Pycharm。
一、 实验目的
1、了解数据探索基本方法。
2、了解数据预处理基本方法。
二、 实验环境
1、操作系统:Windows 10。
2、代码运行环境:Jupyter notebook或Pycharm。
三、 实验原理
1、使用数据挖掘的定义及流程。
2、使用数据挖掘基本方法,应用。
3、使用Python数据分析工具。
4、使用数据对象,属性类型,基本统计描述,可视化,相似性与相异性度量。
5、运用数据预处理基本思想,数据离散化,清洗,特征提取与特征选择。
四、 实验步骤与实验结果
4.1 实验步骤:
1、 数据探索(数据:某餐饮企业的餐饮日销售额数据表catering_sale.xls)
(1.1)对给定数据,首先查看数据基本情况,使用describe方法。
(1.2)分析集中趋势,包括均值,中位数,众数指标。
(1.3)分析离散趋势,包括极差,四分位间距等,并给出五数概况。
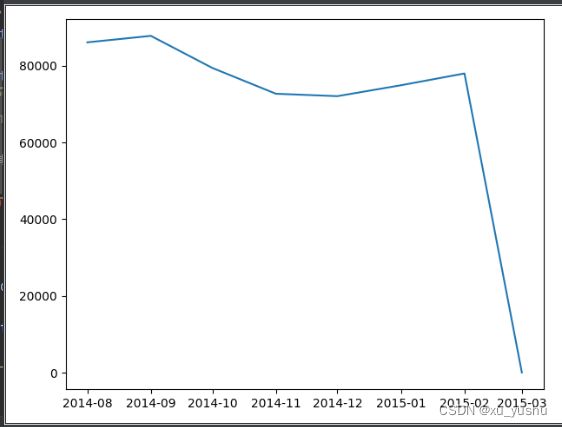
(1.4)以月份为单位,绘制月度销售额直方图(bar),以及按月份时间递增的销售额变化折线图(plot)。
2、 绘制词云,使用数据为《XX大学防控疫情确保开学安全工作方案》。(注意先要将文档转化为可处理的txt)
3、 数据预处理
(3.1)数据清洗-缺失值处理。给定catering_sale.xls,其中2015年2月14日数据缺失。采用合适方法进行数据增补。
(3.2)连续属性离散化。针对医学中的中医证型数据,discretization_data.xls,分别用等宽和等频进行离散化。
(3.3)主成分分析法降维。利用主成分分析法PCA,对数据principal_component.xls进行降维,要求降维后数据保留95%原数据信息即可。
4.2 实验结果:
4.2.1 数据探索
【1】温馨提示:
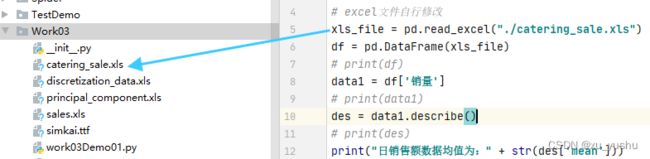
【2】代码:
# coding: utf-8
import pandas as pd
import matplotlib.pyplot as plt
# excel文件自行修改
xls_file = pd.read_excel("./catering_sale.xls")
df = pd.DataFrame(xls_file)
# print(df)
data1 = df['销量']
# print(data1)
des = data1.describe()
# print(des)
print("日销售额数据均值为:" + str(des['mean']))
print("日销售额数据中位数为:" + str(des['50%']))
print("日销售额数据的众位数为:" + str(data1.mode()[0]))
print("日销售额数据的极差为:" + str(des['max'] - des['min']))
print("日销售额数据的四分位间距为:" + str(des['75%']-des['25%']))
print("五数概况为:" + str(des['min'])+", " + str(des['25%']) + ", " + str(des['50%']) + ", " + str(des['75%']) + ", " + str(des['max']))
# data = pd.to_datetime(df['日期']) # 将数据类型换成日期类型
# 设置索引
data = df.set_index('日期', drop=False)
# 按月求和
data_sum = data.resample('MS').sum()
# 画统计图
pl1 = plt.bar(data_sum.index.tolist(), height=data_sum['销量'].tolist(), width=10)
plt.show()
pl2 = plt.plot(data_sum.index.tolist(), data_sum['销量'].tolist())
plt.show()
【3】运行结果:


4.2.2 绘制词云:
【2】代码:
# coding: utf-8
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
import docx
f = ' '
doc = docx.Document('./XX大学防控疫情确保开学安全工作方案.docx')
for p in doc.paragraphs:
# print(type(p)) # 【3】运行结果:
这里结果:根据不同的“XX大学防控疫情确保开学安全工作方案.docx”文件,对应不同的词云图。
4.2.3 题目(3.1)的数据清洗-缺失值处理
【1】温馨提示:

【2】代码:
# -*- coding: utf-8 -*-
# 拉格朗日插值代码
# 导入数据分析库Pandas
import pandas as pd
# 导入拉格朗日插值函数
from scipy.interpolate import lagrange
# 销量数据路径
input_file = 'catering_sale.xls'
# 输出数据路径
output_file = 'sales.xls'
# 读入数据
data = pd.read_excel(input_file)
# data[u'销量'][(data[u'销量'] < 400) | (data[u'销量'] > 5000)] = None #过滤异常值,将其变为空值
# 自定义列向量插值函数
# s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
# 取数
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))]
# 剔除空值
y = y[y.notnull()]
# 插值并返回插值结果
return lagrange(y.index, list(y))(n)
# 逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
# 如果为空即插值
if (data[i].isnull())[j]:
data[i][j] = ployinterp_column(data[i], j)
# 输出结果,写入文件
data.to_excel(output_file)
【3】运行结果:
sale.xls文件
以下为其截图:

4.2.4 题目(3.2)连续属性离散化。
【1】温馨提示:

【2】代码:
# -*- coding: utf-8 -*-
# 数据规范化
import pandas as pd
# 输入数据路径
datafile = 'discretization_data.xls'
# 读取数据
data = pd.read_excel(datafile)
data = data[u'肝气郁结证型系数'].copy()
k = 4
# 等宽离散化,各个类比依次命名为0,1,2,3
d1 = pd.cut(data, k, labels=range(k))
# 等频率离散化
w = [1.0 * i / k for i in range(k + 1)]
# 使用describe函数自动计算分位数
w = data.describe(percentiles=w)[4:4 + k + 1]
w[0] = w[0] * (1 - 1e-10)
d2 = pd.cut(data, w, labels=range(k))
# 引入KMeans
from sklearn.cluster import KMeans
# 建立模型,n_jobs是并行数,一般等于CPU数较好
kmodel = KMeans(n_clusters=k, n_jobs=4)
# 训练模型
kmodel.fit(data.values.reshape((len(data), 1)))
# 输出聚类中心,并且排序(默认是随机序的)
c = pd.DataFrame(kmodel.cluster_centers_).sort_values(0)
# 相邻两项求中点,作为边界点
w = c.rolling(2).mean().iloc[1:]
# 把首末边界点加上
w = [0] + list(w[0]) + [data.max()]
d3 = pd.cut(data, w, labels=range(k))
# 自定义作图函数来显示聚类结果
def cluster_plot(d, k):
import matplotlib.pyplot as plt
# 用来正常显示中文标签
plt.rcParams['font.sans-serif'] = ['SimHei']
# 用来正常显示负号
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(8, 3))
for j in range(0, k):
plt.plot(data[d == j], [j for i in d[d == j]], 'o')
plt.ylim(-0.5, k - 0.5)
return plt
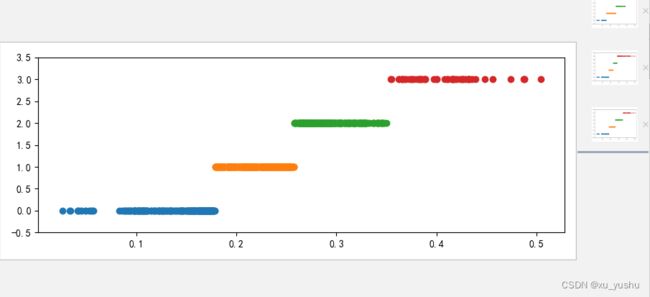
cluster_plot(d1, k).show()
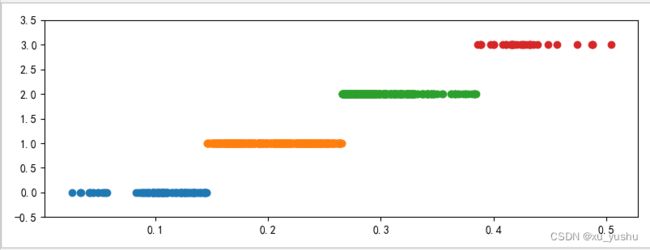
cluster_plot(d2, k).show()
cluster_plot(d3, k).show()
【3】运行结果:

4.2.5 题目(3.3)的主成分分析法降维
【1】提示:
【2】代码:
# coding: utf-8
import pandas as pd
# 3.3 主成分分析法降维
# 利用主成分分析法PCA,对数据进行降维,要求降维后数据保留95%原数据信息即可。
data = pd.read_excel('principal_component.xls', header=None)
from sklearn.decomposition import PCA
# pca = PCA()
# print(pca.fit(data))
# print(pca.explained_variance_ratio_)
# 返回各个成分各自的方差百分比
# 由结果可看出前三个主成分的累积贡献值达到95%
pca = PCA(3)
pca.fit(data)
# 降低维度
low_dimension = pca.transform(data)
# 持久化保存
pd.DataFrame(low_dimension).to_excel('another_principal_component.xls')
【2】运行结果:
生成文件:another_principal_component.xls
以下该文件的截图:

五、 实验总结
通过这次实验,我了解到数据探索、数据预处理是很有趣味的,它涉及的知识面是很广的。数据探索对给定数据,首先查看数据基本情况,分析集中趋势,包括均值,中位数,众数指标。分析离散趋势,包括极差,四分位间距等,并给出五数概况。然后进行可视化,数据预处理,包括数据清洗-缺失值处理,如采用合适方法进行数据增补;连续属性离散化,如用等宽和等频进行离散化;主成分分析法降维等。若是要想好好掌握这数据处理这技能,不仅要花时间学习概率统计学理论知识,还需要知道对应Python的什么模块的什么函数,以及该函数的参数如何使用。