2020CVPR-面向人脸反欺骗的单边域泛化
2020CVPR,Single-Side Domain Generalization for Face Anti-Spoofing,中科院,有源代码
文章链接:Single-Side Domain Generalization for Face Anti-Spoofing (thecvf.com) https://openaccess.thecvf.com/content_CVPR_2020/papers/Jia_Single-Side_Domain_Generalization_for_Face_Anti-Spoofing_CVPR_2020_paper.pdf
https://openaccess.thecvf.com/content_CVPR_2020/papers/Jia_Single-Side_Domain_Generalization_for_Face_Anti-Spoofing_CVPR_2020_paper.pdf
源代码链接:GitHub - taylover-pei/SSDG-CVPR2020: Single-Side Domain Generalization for Face Anti-Spoofing, CVPR2020Single-Side Domain Generalization for Face Anti-Spoofing, CVPR2020 - GitHub - taylover-pei/SSDG-CVPR2020: Single-Side Domain Generalization for Face Anti-Spoofing, CVPR2020 https://github.com/taylover-pei/SSDG-CVPR2020 Single-Side Domain Generalization for Face Anti... - 知乎 (zhihu.com)
https://github.com/taylover-pei/SSDG-CVPR2020 Single-Side Domain Generalization for Face Anti... - 知乎 (zhihu.com)
摘要
现有的人脸反欺骗领域泛化方法都致力于提取共同的区分特征来提高泛化能力。然而,由于伪人脸在不同领域的分布差异很大,很难为其寻找一个紧凑的、广义的特征空间。为了提高人脸反欺骗的泛化能力,本文提出了一种端到端的单边领域泛化框架(SSDG)。其主要思想是学习一个广义特征空间,其中真实人脸的特征分布是紧凑的,而假人脸的特征分布是分散在各个域之间的,但在每个域内是紧凑的。具体地说,特征生成器被训练成只使来自不同领域的真实人脸变得不可区分,而不使假人脸变得不可区分,从而形成单边对抗性学习。此外,设计了一种非对称的三元组损失来约束不同域的伪人脸在真实人脸聚集时被分离出来。以上两点以端到端的训练方式集成到一个统一的框架中,产生了更通用的类边界,特别适合于来自新领域的样本。将特征和权重归一化相结合,进一步提高了泛化能力。大量实验表明,我们提出的方法是有效的,并且在四个公共数据库上的性能优于最先进的方法。
1引言
近年来,人脸识别技术在我们的日常生活中得到了广泛的应用,特别是在智能手机登录、访问控制等领域。然而,也出现了许多表示攻击(如打印攻击、视频攻击、3D面具攻击),这给人脸识别系统带来了巨大的安全风险,成为人脸识别领域日益关注的问题。为了解决这一问题,人们提出了各种人脸反欺骗方法,这些方法大致可以分为基于文本的方法和基于时间的方法。基于纹理的方法利用手工描述符或数据驱动的深度学习来提取区分真假人脸的纹理线索,例如颜色[5]、失真线索[11,39]等。相比之下,基于时间的方法利用连续人脸帧中的各种时间线索,例如rPPG[20,21]和opticalflow[2,4]。
虽然现有的最新方法在数据库内测试场景下已经取得了令人振奋的结果,但它们在跨数据库测试的情况下不能很好地推广,其中训练(源域source domain)和测试(目标域target domain)数据来自不同的域。其原因是传统的方法没有考虑到不同领域之间的内在分布关系,从而提取偏向于数据库的区别性特征[35],导致对不可见领域的泛化能力较差。为了解决这个问题,最近的人脸反欺骗方法[19,38]采用了域自适应技术,通过利用未标记的目标数据来最小化源域和目标域之间的分布差异。然而,在许多现实场景中,收集大量未标记的目标数据进行训练是困难和昂贵的,甚至没有关于目标领域的信息。
因此,一些研究人员开始从领域泛化(DG)的角度来解决人脸反欺骗问题,即在看不到任何目标数据的情况下,利用现有的多个源域来训练模型。传统的DG方法[18,33]旨在通过对齐多个源域之间的分布来学习广义特征空间。并且假设所提取的未见人脸的特征可以映射到共享特征空间附近,这样模型就可以很好地推广到新的领域。由于源域和目标域的真实人脸都是通过成像的真人采集的,所以它们的分布差异很小,这使得学习紧凑的特征空间变得相对容易。相比之下,由于攻击类型和收集方式的多样性,很难将不同领域的假人脸特征聚合在一起。因此,为假人脸寻找广义特征空间是很难优化的,而且还可能影响对目标域的分类精度[1,40]。因此,如图1的左侧所示,尽管实现了真实和虚假示例的紧凑特征空间,但它仍然无法学习新目标领域的区分类边界。有鉴于此,除了限制真假人脸尽可能可区分之外,我们还提出了拉取所有真实人脸的聚合,同时将不同域的假人脸进行分离的方法。如图1右侧所示,我们的方法旨在迫使伪人脸的特征在特征空间中更加分散,而真实人脸的特征更加紧凑,从而产生类边界,从而更好地推广到目标域。
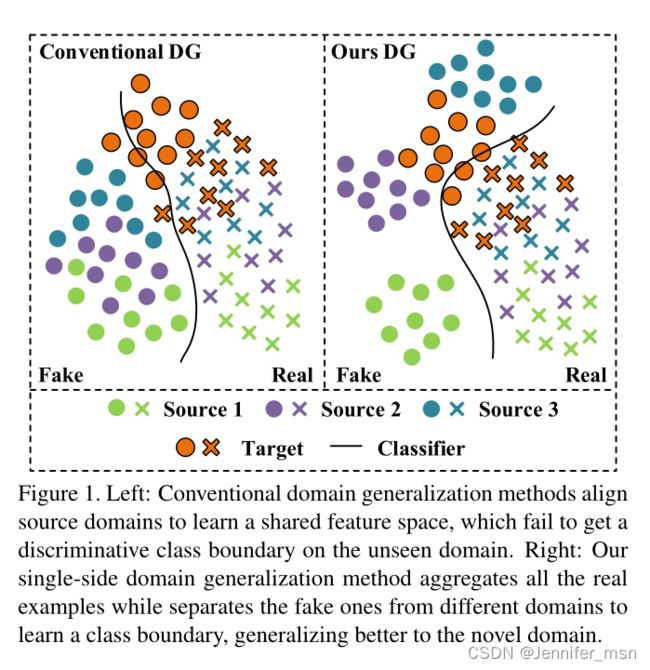
图1图示:左图:传统的域泛化方法对齐源域以学习共享特征空间,无法在不可见域上得到可区分的类边界。右图:我们的单边领域泛化方法聚合了所有的真实实例,同时从不同的领域中分离出假的实例来学习类边界,更好地泛化到新的领域。
考虑到上述思想,我们提出了一种端到端的单边领域泛化框架(SSDG),如图2所示。具体地说,特征生成器与领域鉴别器竞争训练,使来自不同领域的真实人脸的特征无法区分,形成单边对抗性学习。由于假人脸与真人脸的差异较大,我们将不同域的假人脸作为不同的类别,而将所有域的真人脸作为另一个类别进行非对称三元组挖掘(triplet mining),从而保证了三个特性:1)不同类别的假人脸被分离;2)不同域的所有真人脸被聚合;3)所有的真人脸和假人脸都是可区分的。结果,可以得到两种不同特征的特征分布,从而为目标领域带来更好的广义类边界。同时,将特征和权重归一化相结合,进一步提高了训练过程中的泛化能力。
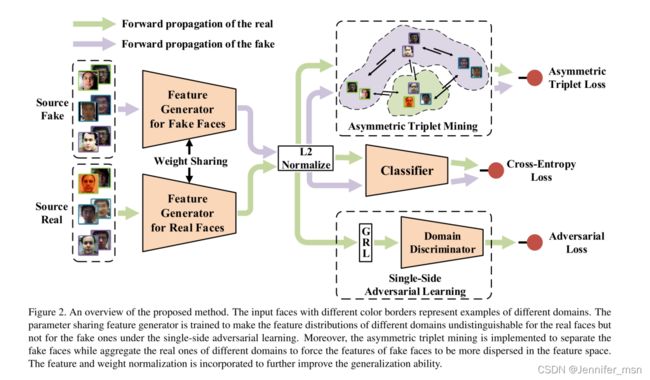
图2图示:所提方法的框架。具有不同颜色边框的输入面表示不同域的示例。训练参数共享特征生成器,使得在单边对抗性学习下,不同领域的特征分布对于真实人脸是不可区分的,而对于虚假人脸则是可区分的。此外,采用非对称三元组挖掘方法分离假人脸,聚合不同领域的真实人脸,使假人脸的特征在特征空间中更加分散。将特征和权重归一化相结合,进一步提高了泛化能力。
本文的主要工作总结如下:1)在分析伪人脸与真实人脸差异较大的基础上,提出了一种新的端到端单边领域泛化框架。2)设计了单边对抗性学习算法和非对称三元组丢失法,实现了真假人脸的不同优化目标,并对特征和权重进行归一化处理,进一步提高了算法的性能。3)综合比较,在四个公共数据库上实现了最先进的性能。
2相关工作
相关工作的介绍分为2部分,分别介绍人脸反欺骗方法和领域泛化方法
2.1人脸反欺骗方法
分为基于纹理的方法和基于时间的方法:基于纹理的方法通过各种纹理线索来区分真假人脸,包括手工特征,如LBP、HOG、SURF、SIFT等,以及基于CNN提取深层次特征,或者深层次特征和手工特征相结合的算法。
基于时间的方法利用连续人脸帧中的时间线索进行人脸反欺骗检测,最早是鼠标运动检测和眨眼检测,近年来已有更通用的方法依赖于更有效的时间线索,而不是特定的活跃度信息。出现了CNN与LSTM相结合的方法,提出CNN-LSTM和CNN-RNN网络检测攻击,
虽然上述方法在数据库内测试场景下取得了显著的效果,但它们不能挖掘不同领域之间的分布关系,并且可能会受到提取偏向于数据库的特征的影响,导致对不可见领域的泛化能力较差。
2.2领域泛化
领域自适应方法和零镜头人脸反欺骗方法,都旨在提高泛化能力。相比之下,域泛化(DG)方法在不访问任何目标数据的情况下显式地挖掘多个源域之间的关系,从而更好地泛化到看不见的域。以往的DG方法大多着眼于最小化多个源域之间的分布差异来提取域不变性特征。Motiian et al.。[27]提出了一种新的损失来引导同一类特征在潜在特征空间中接近。在[13,18]中利用自动编码器来对齐通用特征的源域的分布。与我们最相关的工作在[33]中提出,其中多个特征提取器被训练成通过对抗性学习来学习广义特征空间。然而,作为首次尝试从DG的角度解决人脸反欺骗问题,其训练过程并不是端到端的。此外,由于攻击类型和收集方式的多样性,很难为假人脸寻找一个广义特征空间,这往往导致人脸反欺骗的解是次优的。
3所提方法
3.1概述
假人脸的分布差异比真实人脸大得多,因此对来自不同领域的假人脸进行特征对齐是非常重要的,为真假人脸寻找一个紧凑而广义的特征空间是很难优化的,而且可能会对不可见区域的分类精度带来负面影响。
本文针对的是属于不同领域的真假人脸的非对称优化目标,学习对不可见领域具有较强泛化能力的特征空间,即解决的是未知攻击检测。提出用于人脸反欺骗检测的单边域泛化框架(SSDG)。
具体是通过特征生成器与领域判别器竞争训练,是真实人脸的特征变得不可区分,形成代表对抗性学习过程。还提出了非对称三元组损失来显式分离不同域的伪脸,同时聚合真实的伪脸。此外,在训练过程中进一步加入了特征和权重归一化,以提高泛化能力。因此,本文提出的SSDG方法迫使伪人脸在特征空间中更加分散,而真实人脸更加紧凑,从而导致对不可见区域的类边界更加一般化。
3.2单边对抗学习(Single-Side Adversarial Learning)
论文假设不同域都包含真实和虚假两类人脸图像,真实人脸图像都是通过真实采集得到的,因此论文提出一个假设:来自不同域的真实人脸之间的分布差异比虚假人脸的分布差异要小得多。
从而提出单边对抗学习为真实人脸寻找广义特征空间,这种学习只在提取的真实人脸特征上进行,对虚假人脸则不进行对抗学习。
特征生成器(feature generator):将输入的人脸转换成潜在的特征空间。特征生成器被训练欺骗域辨别器,使得域标签不能被识别
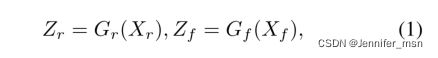

域辨别器(domain discrimination):
在学习过程中,特征生成器的参数以最大化域鉴别器的损失为目标进行优化,而域鉴别器的参数则以相反的目标进行优化。由于有多个源域可供分类,在单边对抗性学习下,我们利用标准交叉熵损对网络进行优化:


特征生成器以最大化域判别器的loss为优化目标,域判别器则相反。为了同步优化生成器和辨别器,在特征生成器后插入一个梯度反向层(gradient reverse layer, GRL),在反向传播的过程中把对抗loss乘以−λ,目的是抑制早期训练阶段噪声信号的影响。
3.3非对称三重挖掘(asymmetric triplet mining)
由于攻击类型和数据库收集方式的多样性,伪人脸之间的分布差异比真实人脸的分布差异要大得多。因此,与寻找紧凑的特征空间相比,为假货寻找一个分散的特征空间相对容易。考虑到这一点,我们对不同区域的伪脸进行了显式分离,迫使它们在特征空间中更加分散。相比之下,我们将所有真实的元素聚合在一起,以迫使它们更加紧凑。为了实现真假人脸的非对称优化目标,我们提出了非对称三元组损失的概念,对非对称三元组进行分类挖掘,促进了对不可见领域更好的类边界学习。