数学建模-插值和拟合
文章目录
- 插值和拟合
-
- 一、定义
-
- (1)`插值`:
- (2)`拟合`:
- (3)数据插值和曲线拟合比较
-
- ①相同点
- ②不同点
- 二、插值方法
-
- (1)常用的插值分类
- (2)拉格朗日多项式插值(Lagrange插值)
-
- 2.1.1 插值多项式
- 2.1.2 拉格朗日插值多项式
- 2.1.3 Matlab实现Lagrange 插值
- (3)牛顿插值(Newton)
-
- 3.1 差商(预备知识)
- 3.2 牛顿插值公式
- (4)分段线性插值
-
- ①定义
- ②Lagrange的问题
- ③matlab实现
- (5)埃尔米特(Hermite)插值
-
- ①定义
- ②代码实现
- (6)样条插值(Spline)
- (7)二维插值
-
- ①单调递增
- ②插值节点为散乱节点
- (8)B 样条函数插值方法
- 三、拟合方法
-
- (1)解方程法
- (2)多项式拟合方法
- (3)最小二乘优化
-
- ①lsqlin 函数
- ②lsqcurvefit 函数
- ③lsqnonlin 函数
- ④lsqnonneg 函数
- (4)曲线拟合与函数逼近
- (5)实战
-
- 黄河小浪底调水调沙问题
- 四、全部代码
插值和拟合
2021.8.11《数学建模算法与应用》读书笔记
一、定义
(1)插值:
求过已知有限个数据点的近似函数。
(2)拟合:
已知有限个数据点,求近似函数,不要求过已知数据点,只要求在某种意义
下它在这些点上的总偏差最小。
(3)数据插值和曲线拟合比较
①相同点
1、都属于函数逼近的方法
2、都能进行数据估算
②不同点
1、实现方法不同
数据插值要求逼近函数经过样本点,曲线拟合只要求总体误差最小
2、结果形式不同
数据插值分段进行逼近,没有统一的逼近函数。
曲线拟合有确定的逼近函数表达式。
3、侧重点不同
数据插值一般用于样本区间内的插值计算。
曲线拟合不仅可以估算区间内其他点的函数值,还可以预测持续数字的发展。
4、应用场合不同
样本数据是精确数据,适合采用数据插值方法。
样本数据统计数据,存在误差,适合用曲线拟合的方法。
二、插值方法
(1)常用的插值分类
-
拉格朗日多项式插值
-
牛顿插值
-
分段线性插值
-
Hermite 插值
-
三次样条插值。
(2)拉格朗日多项式插值(Lagrange插值)
2.1.1 插值多项式

2.1.2 拉格朗日插值多项式

2.1.3 Matlab实现Lagrange 插值
lagrange.m
%{
设n 个节点数据以数组 x0, y0输入(注意 Matlat 的数组下标从 1 开始),m 个插值
点以数组 x 输入,输出数组 y 为m 个插值。
参数输入:
x0,y0是原有的数据
x为插值点(范围)
参数输出
y为x的插值输出
%}
function y=lagrange(x0,y0,x);
n=length(x0);m=length(x);
for i=1:m
z=x(i);
s=0.0;
for k=1:n
p=1.0;
for j=1:n
if j~=k
p=p*(z-x0(j))/(x0(k)-x0(j));
end
end
s=p*y0(k)+s;
end
y(i)=s;
end
- 实例测试
% 拉格朗日插值法
% 原始数据
x0 = 0:0.1:1;
y0 = [-0.447,1.978,3.28,6.16,7.08,7.34,7.66,9.56,9.48,9.3,11.2];
hold on;
grid on;
plot(x0,y0,'b*')
% 插值点
x = 0:0.01:1;
% 拉格朗日多项式插值
y = lagrange(x0,y0,x);
plot(x,y,'r--');
legend('原始数据','拉格朗日插值','Location','North');
- 测试结果

(3)牛顿插值(Newton)
3.1 差商(预备知识)

3.2 牛顿插值公式


代码来自https://blog.csdn.net/seamanj/article/details/37562791
newton.m
% newton.m
% 求牛顿插值多项式、差商、插值及其误差估计的MATLAB主程序
% 输入的量:X是n+1个节点(x_i,y_i)(i = 1,2, ... , n+1)横坐标向量,Y是纵坐标向量,
% x是以向量形式输入的m个插值点,M在[a,b]上满足|f~(n+1)(x)|≤M
% 注:f~(n+1)(x)表示f(x)的n+1阶导数
% 输出的量:向量y是向量x处的插值,误差限R,n次牛顿插值多项式L及其系数向量C,
% 差商的矩阵A
function[y,R,A,C,L] = newton(X,Y,x,M)
n = length(X);
m = length(x);
for t = 1 : m
z = x(t);
A = zeros(n,n);
A(:,1) = Y';
s = 0.0; p = 1.0; q1 = 1.0; c1 = 1.0;
for j = 2 : n
for i = j : n
A(i,j) = (A(i,j-1) - A(i-1,j-1))/(X(i)-X(i-j+1));
end
q1 = abs(q1*(z-X(j-1)));
c1 = c1 * j;
end
C = A(n, n); q1 = abs(q1*(z-X(n)));
for k = (n-1):-1:1
C = conv(C, poly(X(k)));
d = length(C);
C(d) = C(d) + A(k,k);%在最后一维,也就是常数项加上新的差商
end
y(t) = polyval(C,z);
R(t) = M * q1 / c1;
end
L = poly2sym(C);
- 实例运行
X = [0 pi/6 pi/4 pi/3 pi/2];
Y = [0 0.5 0.7071 0.8660 1];
x = linspace(0,pi,50);
hold on;
grid on;
M = 1;
[y,R,A,C,L] = newton(X, Y, x, M);
plot(X,Y,'r*');
plot(x,y,'b--');
legend('原始数据','牛顿插值');
- 运行结果
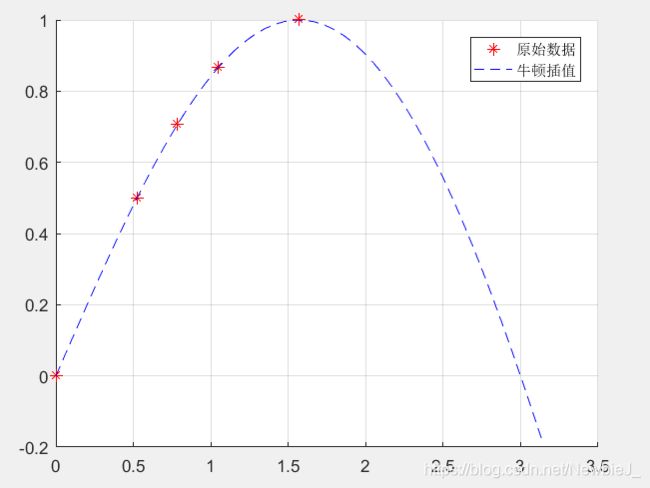
对于其他的一些插值方法就不放原理了。直接掌握使用方式和使用情况。
(4)分段线性插值
①定义
将每两个相邻的节点用直线连起来,如此形成的一条折线就是分段线性插值函数
②Lagrange的问题

③matlab实现

代码看后文样条插值
(5)埃尔米特(Hermite)插值
①定义
如果对插值函数,不仅要求它 在 节 点 处 与 函 数 同 值 \color{blue}{在节点处与函数同值} 在节点处与函数同值,而且要求它 与 函 数 有 相 同 的 一 阶 、 二 阶 甚 至 更 高 阶 的 导 数 值 \color{blue}{与函数有相同的一阶、二阶甚至更高阶的导数值} 与函数有相同的一阶、二阶甚至更高阶的导数值,这就是 Hermite 插值问题。
②代码实现
hermite.m
%{
设n 个节点的数据以
数组 x0 (已知点的横坐标)
y0 (函数值)
y1(导数值)
输入(注意 Matlat 的数组下标从 1 开始)
m 个插值点以数组 x 输入
输出数组 y 为m个插值
%}
function y=hermite(x0,y0,y1,x);
n=length(x0);m=length(x);
for k=1:m
yy=0.0;
for i=1:n
h=1.0;
a=0.0;
for j=1:n
if j~=i
h=h*((x(k)-x0(j))/(x0(i)-x0(j)))^2;
a=1/(x0(i)-x0(j))+a;
end
end
yy=yy+h*((x0(i)-x(k))*(2*a*y0(i)-y1(i))+y0(i));
end
y(k)=yy;
end
(6)样条插值(Spline)
许多工程技术中提出的计算问题对插值函数的光滑性有较高要求,如飞机的机翼外形,内燃机的进、排气门的凸轮曲线,都要求曲线具有较高的光滑程度,不仅要连续,而且要有连续的曲率,这就导致了样条插值的产生。
分段线性插值是一次样条插值。

- 代码示例
% Lagrange插值、分段线性插值、三次样条插值
clc,clear
x0 = [0 3 5 7 9 11 12 13 14 15];
y0 = [0 1.2 1.7 2.0 2.1 2.0 1.8 1.2 1.0 1.6];
x = 0:0.1:15;
% 调用前面编写的Lagrange插值函数
y1 = lagrange(x0,y0,x);
% 分段线性插值
y2 = interp1(x0,y0,x);
% 三次样条插值
y3 = interp1(x0,y0,x,'spline');
% 边界为Largrange的三次样条插值
pp1 = csape(x0,y0); y4=ppval(pp1,x);
% 边界为二阶导数的三次样条插值
pp2 = csape(x0,y0,'second'); y5 = ppval(pp2,x);
fprintf('比较一下不同插值方法和边界条件的结果:\n')
fprintf('x y1 y2 y3 y4 y5\n')
xianshi=[x',y1',y2',y3',y4',y5'];
fprintf('%f\t%f\t%f\t%f\t%f\t%f\n',xianshi')
subplot(2,3,1), plot(x0,y0,'+',x,y1), title('Lagrange')
subplot(2,3,2), plot(x0,y0,'+',x,y2), title('Piecewise linear')
subplot(2,3,3), plot(x0,y0,'+',x,y3), title('Spline1')
subplot(2,3,4), plot(x0,y0,'+',x,y4), title('Spline2')
subplot(2,3,5), plot(x0,y0,'+',x,y5), title('Spline3')
dyx0=ppval(fnder(pp1),x0(1)) %求x=0处的导数
ytemp=y3(131:151);
index=find(ytemp==min(ytemp));
xymin=[x(130+index),ytemp(index)]
- 运行结果
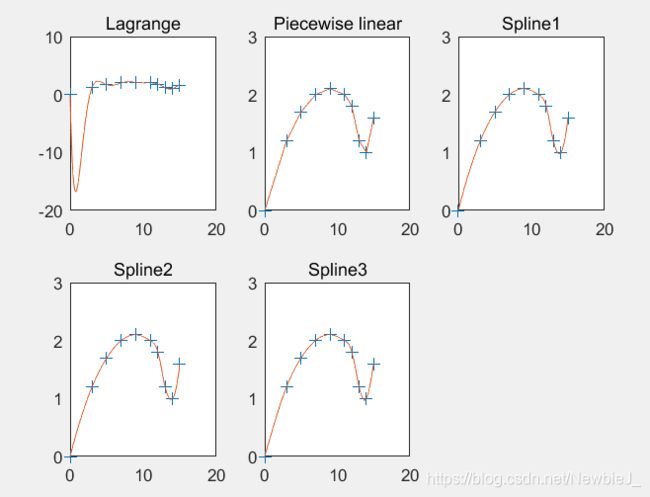
- 结论
- 可以看出,拉格朗日插值的结果根本不能应用,分段线性插值的光滑性较差(特别
是在 x = 14 附近弯曲处),建议选用三次样条插值的结果。
(7)二维插值
①单调递增
前面讲述的都是一维插值,即节点为一维变量,插值函数是一元函数(曲线)。若节点是二维的,插值函数就是二元函数,即曲面。如在某区域测量了若干点(节点)的高程(节点值),为了画出较精确的等高线图,就要先插入更多的点(插值点),计算这些点的高程(插值)。
调用格式:Z1=interp2(X,Y,Z,X1,Y1,method)
其中,X、Y是两个向量,表示两个参数的采样点,Z是采样点对应的函数值。X1、Y1是两个标量或向量,表示要插值的点。
tips
shading函数说明:
是阴影函数控制曲面和图形对象的颜色着色,即用来处理色彩效果的,包括以下三种形式:
shading faceted:默认模式,在曲面或图形对象上叠加黑色的网格线;
shading flat:是在shading faceted的基础上去掉图上的网格线;
shading interp:对曲面或图形对象的颜色着色进行色彩的插值处理,使色彩平滑过渡
- 代码示例
%{
例2 在一丘陵地带测量高程,x 和 y 方向每隔100米测一个点,得高程如2表,试插
值一曲面,确定合适的模型,并由此找出最高点和该点的高程。
%}
% 二维插值
clear,clc
x=100:100:500;
y=100:100:400;
z=[636 697 624 478 450
698 712 630 478 420
680 674 598 412 400
662 626 552 334 310];
% hold on;
xi = 100:10:500;yi=100:10:400
% 三次样条插值注意得到的cz1需要到转一下
pp = csape({x,y},z')
cz1 = fnval(pp,{xi,yi})
% 二维插值
cz2 = interp2(x,y,z,xi,yi','spline')
surfl(x,y,z-400);
hold on;
surfl(xi,yi,cz1');
surfl(xi,yi,cz2+400);
[i,j] = find(cz1==max(max(cz1)))
x = xi(i),y=yi(j),zmax=cz1(i,j)
- 运行结果
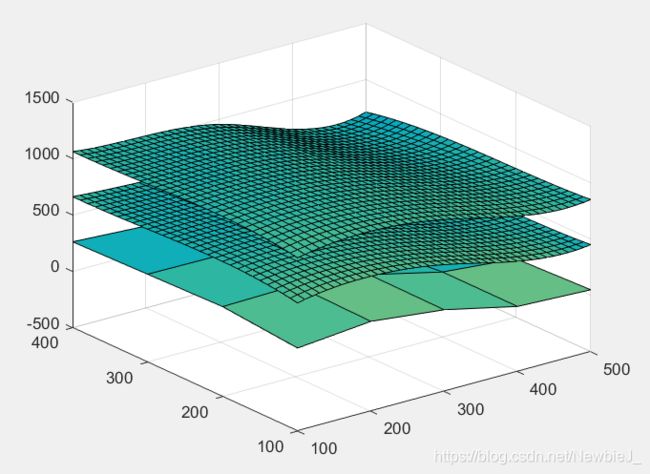
②插值节点为散乱节点
已知n 个节点:(xi , yi ,zi)(i = 1,2,L,n),求点(x, y)处的插值 z 。对上述问题,Matlab 中提供了插值函数 griddata,其格式为:
ZI = GRIDDATA(X,Y,Z,XI,YI,method)
method选项‘linear’:基于三角形的线性插值(缺省算法);‘cubic’: 基于三角形的三次插值;‘nearest’:最邻近插值法;
其中 X、Y、Z 均为 n 维向量,指明所给数据点的横坐标、纵坐标和竖坐标。向量 XI、
YI 是给定的网格点的横坐标和纵坐标,返回值 ZI 为网格(XI,YI)处的函数值。XI
与 YI 应是方向不同的向量,即一个是行向量,另一个是列向量。
- 实例
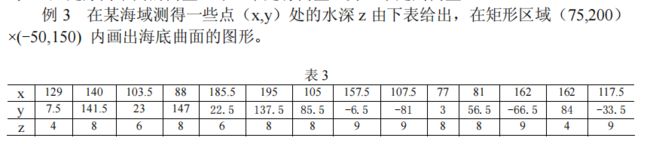
- 代码
% 插值节点为散乱节点
x=[129 140 103.5 88 185.5 195 105 157.5 107.5 77 81 162 162 117.5];
y=[7.5 141.5 23 147 22.5 137.5 85.5 -6.5 -81 3 56.5 -66.5 84 -33.5];
z=-[4 8 6 8 6 8 8 9 9 8 8 9 4 9];
xi=75:1:200;
yi=-50:1:150;
zi=griddata(x,y,z,xi,yi','cubic')
subplot(1,2,1), plot(x,y,'*')
subplot(1,2,2), mesh(xi,yi,zi)
- 运行结果

(8)B 样条函数插值方法
实际中的许多问题,往往是既要求近似函数(曲线或曲面)有足够的光滑性,又要求与实际函数相同的凹凸性,一般插值函数和样条函数都不具有这种性质。如果对于一个特殊函数进行磨光处理生成磨光函数(多项式),则用磨光函数构造出样条函数作为插值函数,既有足够的光滑性,而且也具有较好的保凹凸性,因此磨光函数在一维插值(曲线)和二维插值(曲面)问题中有着广泛的应用。
由积分理论可知,对于可积函数通过积分会提高函数的光滑度,因此,我们可以利用积分方法对函数进行磨光处理。
三、拟合方法
曲线拟合问题的提法是,已知一组(二维)数据,即平面上的n 个点(xi , yi) , i = 1,2,L,n , xi 互不相同,寻求一个函数(曲线)y = f (x) ,使 f (x)在某种准则下与所有数据点最为接近,即曲线拟合得最好。


![]()
对于指数曲线,拟合前需作变量代换,化为对a1,a2 的线性函数。
已知一组数据,用什么样的曲线拟合最好,可以在直观判断的基础上,选几种曲线
分别拟合,然后比较,看哪条曲线的最小二乘指标 J 最加粗样式小。
(1)解方程法

-
例题

-
代码
% 解方程拟合
x=[19 25 31 38 44]';
y=[19.0 32.3 49.0 73.3 97.8]';
r=[ones(5,1),x.^2];
ab=r\y
x0=19:0.1:44;
y0=ab(1)+ab(2)*x0.^2;
plot(x,y,'o',x0,y0,'r')
- 运行结果

(2)多项式拟合方法
polyfit()
函数功能:求得最小二乘拟合多项式系数。
调用格式:
①P=polyfit(X,Y,m)
②[P,S]=polyfit(X,Y,m)
③[P,S,mu]=polyfit(X,Y,m)
其中输入参数 x0,y0 为要拟合的数据,m 为拟合多项式的次数,输出参数 p 为拟合多项
式。根据样本数据X和Y,产生一个m次多项式P及其在采样点误差数据S,m为几次拟合,mu是一个二元向量,mu(1)是mean(X),而mu(2)是std(X).
-
例题
-
代码
% 多项式拟合
% 原始数据
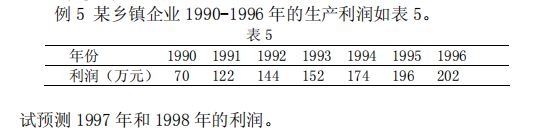
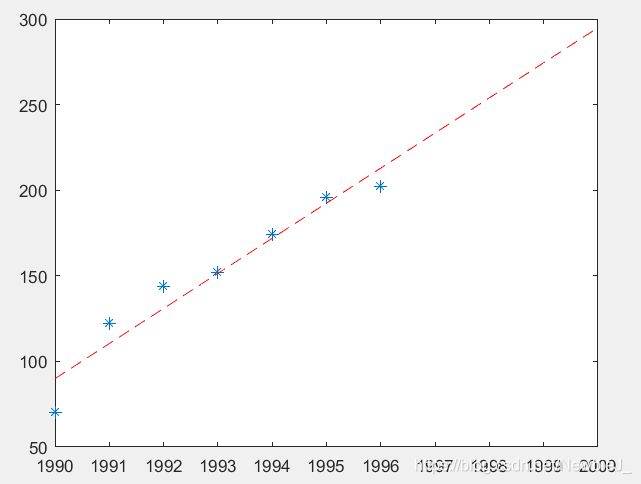
x0=[1990 1991 1992 1993 1994 1995 1996];
y0=[70 122 144 152 174 196 202];
% 画散点图
plot(x0,y0,'*')
hold on;
a=polyfit(x0,y0,1)
x = 1990:0.1:2000;
y = polyval(a,x);
plot(x,y,'r--');
y97=polyval(a,1997)
y98=polyval(a,1998)
a =
1.0e+04 *
0.0021 -4.0705
y97 =
233.4286
y98 =
253.9286
- 运行结果
(3)最小二乘优化
在无约束最优化问题中,有些重要的特殊情形,比如目标函数由若干个函数的平
方和构成。
①lsqlin 函数
x=lsqlin(C,d,A,b,Aeq,beq,lb,ub,x0)
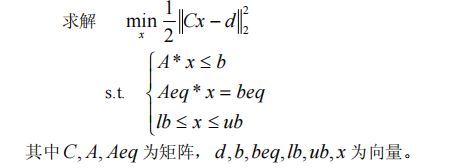
% 用 lsqlin 命令求解例 4。
x=[19 25 31 38 44]';
y=[19.0 32.3 49.0 73.3 97.8]';
r=[ones(5,1),x.^2];
ab=lsqlin(r,y)
x0=19:0.1:44;
y0=ab(1)+ab(2)*x0.^2;
plot(x,y,'o',x0,y0,'r')
②lsqcurvefit 函数
X=LSQCURVEFIT(FUN,X0,XDATA,YDATA,LB,UB,OPTIONS)
其中 FUN 是定义函数F(x, xdata)的 M 文件。
- 例题
- 编写 M 文件
fun1.m定义函数 F(x,tdata):
function f=fun1(x,tdata);
f=x(1)+x(2)*exp(-0.02*x(3)*tdata); %其中 x(1)=a,x(2)=b,x(3)=k
- 调用函数
lsqcurvefit
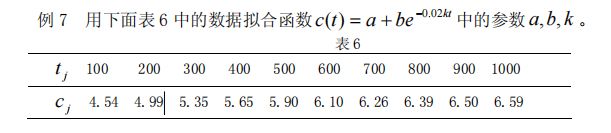
td=100:100:1000;
cd=[4.54 4.99 5.35 5.65 5.90 6.10 6.26 6.39 6.50 6.59];
x0=[0.2 0.05 0.05];
x=lsqcurvefit(@fun1,x0,td,cd)
③lsqnonlin 函数
X=LSQNONLIN(FUN,X0,LB,UB,OPTIONS)
其中 FUN 是定义向量函数F(x)的 M 文件。
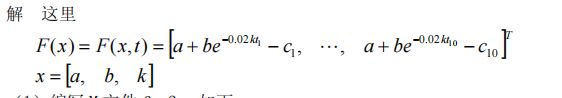
- 编写 M 文件 fun2.m
function f=fun2(x);
td=100:100:1000;
cd=[4.54 4.99 5.35 5.65 5.90 6.10 6.26 6.39 6.50 6.59];
f=x(1)+x(2)*exp(-0.02*x(3)*td)-cd;
- 调用函数
lsqnonlin
x0=[0.2 0.05 0.05]; %初始值是任意取的
x=lsqnonlin(@fun2,x0)
④lsqnonneg 函数
![]()
X = LSQNONNEG(C,d,X0,OPTIONS)

c=[0.0372 0.2869;0.6861 0.7071;0.6233 0.6245;0.6344 0.6170];
d=[0.8587;0.1781;0.0747;0.8405];
x=lsqnonneg(c,d)
(4)曲线拟合与函数逼近


- 例题
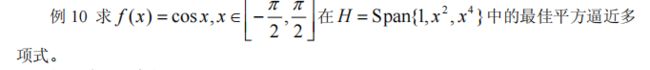
- 代码
syms x
base=[1,x^2,x^4];
y1=base.'*base
y2=cos(x)*base.'
r1=int(y1,-pi/2,pi/2)
r2=int(y2,-pi/2,pi/2)
a=r1\r2
xishu1=double(a)
digits(8),xishu2=vpa(a)

(5)实战
黄河小浪底调水调沙问题
- 问题提出

- 模型的建立与求解

对于问题(1),根据所给问题的试验数据,要计算任意时刻的排沙量,就要确定出排沙量随时间变化的规律,可以通过插值来实现。考虑到实际中的排沙量应该是时间的连续函数,为了提高模型的精度,我们采用三次样条函数进行插值。

- 三次样条程序
clc,clear
load data.txt %data.txt 按照原始数据格式把水流量和排沙量排成 4 行,12 列
liu=data([1,3],:);
liu=liu';
liu=liu(:);
sha=data([2,4],:);
sha=sha';sha=sha(:);
y=sha.*liu;y=y';
i=1:24;
t=(12*i-4)*3600;
t1=t(1);t2=t(end);
pp=csape(t,y);
xsh=pp.coefs %求得插值多项式的系数矩阵,每一行是一个区间上多项式的系数。
TL=quadl(@(tt)ppval(pp,tt),t1,t2)
- 或者是3 次 B 样条函数进行插值
clc,clear
load data.txt %data.txt 按照原始数据格式把水流量和排沙量排成 4 行,12 列
liu=data([1,3],:);
liu=liu';liu=liu(:);
sha=data([2,4],:);
sha=sha';sha=sha(:);
y=sha.*liu;y=y';
i=1:24;
t=(12*i-4)*3600;
t1=t(1);t2=t(end);
pp=spapi(4,t,y) %三次 B 样条
pp2=fn2fm(pp,'pp') %把 B 样条函数转化为 pp 格式
TL=quadl(@(tt)fnval(pp,tt),t1,t2)
对于问题(2),研究排沙量与水量的关系,从试验数据可以看出,开始排沙量是随着水流量的增加而增长,而后是随着水流量的减少而减少。显然,变化规律并非是线性的关系,为此,把问题分为两部分,从开始水流量增加到最大值 2720m3/s(即增长的过程)为第一阶段,从水流量的最大值到结束为第二阶段,分别来研究水流量与排沙量的关系。
- 排沙量与水流量的散点图
% 画散点图
load data.txt
liu=data([1,3],:);
liu=liu';liu=liu(:);
sha=data([2,4],:);
sha=sha';sha=sha(:);
y=sha.*liu;
subplot(1,2,1), plot(liu(1:11),y(1:11),'*')
subplot(1,2,2), plot(liu(12:24),y(12:24),'*')


% 拟合
clc, clear
load data.txt %data.txt 按照原始数据格式把水流量和排沙量排成 4 行,12 列
liu=data([1,3],:); liu=liu'; liu=liu(:);
sha=data([2,4],:); sha=sha'; sha=sha(:);
y=sha.*liu;
%以下是第一阶段的拟合
format long e
nihe1_1=polyfit(liu(1:11),y(1:11),1) %拟合一次多项式,系数排列从高次幂到低次幂
nihe1_2=polyfit(liu(1:11),y(1:11),2)
yhat1_1=polyval(nihe1_1,liu(1:11)); %求预测值
yhat1_2=polyval(nihe1_2,liu(1:11));
%以下求误差平方和与剩余标准差
cha1_1=sum((y(1:11)-yhat1_1).^2); rmse1_1=sqrt(cha1_1/9)
cha1_2=sum((y(1:11)-yhat1_2).^2); rmse1_2=sqrt(cha1_2/8)
%以下是第二阶段的拟合
for j=1:3
str1=char(['nihe2_' int2str(j) '=polyfit(liu(12:24),y(12:24),' int2str(j+1) ')']);
eval(str1)
str2=char(['yhat2_' int2str(j) '=polyval(nihe2_' int2str(j) ',liu(12:24));']);
eval(str2)
str3=char(['cha2_' int2str(j) '=sum((y(12:24)-yhat2_' int2str(j) ').^2);'...
'rmse2_' int2str(j) '=sqrt(cha2_' int2str(j) '/(11-j))']);
eval(str3)
end
format
四、全部代码
% 拉格朗日插值法
% 原始数据
x0 = 0:0.1:1;
y0 = [-0.447,1.978,3.28,6.16,7.08,7.34,7.66,9.56,9.48,9.3,11.2];
hold on;
grid on;
plot(x0,y0,'b*')
% 插值点
x = 0:0.01:1;
% 拉格朗日多项式插值
y = lagrange(x0,y0,x);
plot(x,y,'r--');
legend('原始数据','拉格朗日插值','Location','North');
%
X = [0 pi/6 pi/4 pi/3 pi/2];
Y = [0 0.5 0.7071 0.8660 1];
x = linspace(0,pi,50);
hold on;
grid on;
M = 1;
[y,R,A,C,L] = newton(X, Y, x, M);
plot(X,Y,'r*');
plot(x,y,'b--');
legend('原始数据','牛顿插值');
% Lagrange插值、分段线性插值、三次样条插值
clc,clear
x0 = [0 3 5 7 9 11 12 13 14 15];
y0 = [0 1.2 1.7 2.0 2.1 2.0 1.8 1.2 1.0 1.6];
x = 0:0.1:15;
% 调用前面编写的Lagrange插值函数
y1 = lagrange(x0,y0,x);
% 分段线性插值
y2 = interp1(x0,y0,x);
% 三次样条插值
y3 = interp1(x0,y0,x,'spline');
% 边界为Largrange的三次样条插值
pp1 = csape(x0,y0); y4=ppval(pp1,x);
% 边界为二阶导数的三次样条插值
pp2 = csape(x0,y0,'second'); y5 = ppval(pp2,x);
fprintf('比较一下不同插值方法和边界条件的结果:\n')
fprintf('x y1 y2 y3 y4 y5\n')
xianshi=[x',y1',y2',y3',y4',y5'];
fprintf('%f\t%f\t%f\t%f\t%f\t%f\n',xianshi')
subplot(2,3,1), plot(x0,y0,'+',x,y1), title('Lagrange')
subplot(2,3,2), plot(x0,y0,'+',x,y2), title('Piecewise linear')
subplot(2,3,3), plot(x0,y0,'+',x,y3), title('Spline1')
subplot(2,3,4), plot(x0,y0,'+',x,y4), title('Spline2')
subplot(2,3,5), plot(x0,y0,'+',x,y5), title('Spline3')
dyx0=ppval(fnder(pp1),x0(1)) %求x=0处的导数
ytemp=y3(131:151);
index=find(ytemp==min(ytemp));
xymin=[x(130+index),ytemp(index)]
%{
例2 在一丘陵地带测量高程,x 和 y 方向每隔100米测一个点,得高程如2表,试插
值一曲面,确定合适的模型,并由此找出最高点和该点的高程。
%}
% 二维插值
clear,clc
x=100:100:500;
y=100:100:400;
z=[636 697 624 478 450
698 712 630 478 420
680 674 598 412 400
662 626 552 334 310];
% hold on;
xi = 100:10:500;yi=100:10:400
% 三次样条插值注意得到的cz1需要到转一下
pp = csape({x,y},z')
cz1 = fnval(pp,{xi,yi})
% 二维插值
cz2 = interp2(x,y,z,xi,yi','spline')
surfl(x,y,z-400);
hold on;
surfl(xi,yi,cz1');
surfl(xi,yi,cz2+400);
[i,j] = find(cz1==max(max(cz1)))
x = xi(i),y=yi(j),zmax=cz1(i,j)
% 插值节点为散乱节点
x=[129 140 103.5 88 185.5 195 105 157.5 107.5 77 81 162 162 117.5];
y=[7.5 141.5 23 147 22.5 137.5 85.5 -6.5 -81 3 56.5 -66.5 84 -33.5];
z=-[4 8 6 8 6 8 8 9 9 8 8 9 4 9];
xi=75:1:200;
yi=-50:1:150;
zi=griddata(x,y,z,xi,yi','cubic')
subplot(1,2,1), plot(x,y,'*')
subplot(1,2,2), mesh(xi,yi,zi)
% 解方程拟合
x=[19 25 31 38 44]';
y=[19.0 32.3 49.0 73.3 97.8]';
r=[ones(5,1),x.^2];
ab=r\y
x0=19:0.1:44;
y0=ab(1)+ab(2)*x0.^2;
plot(x,y,'o',x0,y0,'r')
% 多项式拟合
% 原始数据
x0=[1990 1991 1992 1993 1994 1995 1996];
y0=[70 122 144 152 174 196 202];
% 画散点图
plot(x0,y0,'*')
hold on;
a=polyfit(x0,y0,1)
x = 1990:0.1:2000;
y = polyval(a,x);
plot(x,y,'r--');
y97=polyval(a,1997)
y98=polyval(a,1998)
% 用 lsqlin 命令求解例 4。
x=[19 25 31 38 44]';
y=[19.0 32.3 49.0 73.3 97.8]';
r=[ones(5,1),x.^2];
ab=lsqlin(r,y)
x0=19:0.1:44;
y0=ab(1)+ab(2)*x0.^2;
plot(x,y,'o',x0,y0,'r')
% 插值
clc,clear
load data.txt %data.txt 按照原始数据格式把水流量和排沙量排成 4 行,12 列
liu=data([1,3],:);
liu=liu';
liu=liu(:);
sha=data([2,4],:);
sha=sha';sha=sha(:);
y=sha.*liu;y=y';
i=1:24;
t=(12*i-4)*3600;
t1=t(1);t2=t(end);
pp=csape(t,y);
xsh=pp.coefs %求得插值多项式的系数矩阵,每一行是一个区间上多项式的系数。
TL=quadl(@(tt)ppval(pp,tt),t1,t2)
% 画散点图
load data.txt
liu=data([1,3],:);
liu=liu';liu=liu(:);
sha=data([2,4],:);
sha=sha';sha=sha(:);
y=sha.*liu;
subplot(1,2,1), plot(liu(1:11),y(1:11),'*')
subplot(1,2,2), plot(liu(12:24),y(12:24),'*')
% 拟合
clc, clear
load data.txt %data.txt 按照原始数据格式把水流量和排沙量排成 4 行,12 列
liu=data([1,3],:); liu=liu'; liu=liu(:);
sha=data([2,4],:); sha=sha'; sha=sha(:);
y=sha.*liu;
%以下是第一阶段的拟合
format long e
nihe1_1=polyfit(liu(1:11),y(1:11),1) %拟合一次多项式,系数排列从高次幂到低次幂
nihe1_2=polyfit(liu(1:11),y(1:11),2)
yhat1_1=polyval(nihe1_1,liu(1:11)); %求预测值
yhat1_2=polyval(nihe1_2,liu(1:11));
%以下求误差平方和与剩余标准差
cha1_1=sum((y(1:11)-yhat1_1).^2); rmse1_1=sqrt(cha1_1/9)
cha1_2=sum((y(1:11)-yhat1_2).^2); rmse1_2=sqrt(cha1_2/8)
%以下是第二阶段的拟合
for j=1:3
str1=char(['nihe2_' int2str(j) '=polyfit(liu(12:24),y(12:24),' int2str(j+1) ')']);
eval(str1)
str2=char(['yhat2_' int2str(j) '=polyval(nihe2_' int2str(j) ',liu(12:24));']);
eval(str2)
str3=char(['cha2_' int2str(j) '=sum((y(12:24)-yhat2_' int2str(j) ').^2);'...
'rmse2_' int2str(j) '=sqrt(cha2_' int2str(j) '/(11-j))']);
eval(str3)
end
format