【论文翻译】论文中英对照翻译--(Learning Generalized Deep Feature Representation for Face Anti-Spoofing)(其一)
【开始时间】2018.10.23
【完成时间】2018.10.25
【论文翻译】论文中英对照翻译--(Learning Generalized Deep Feature Representation for Face Anti-Spoofing)(其一)
【中文译名】人脸反欺骗的广义深层特征表示
【论文链接】论文链接
【说明】此论文较长,本人将它分为了两部分,这是前半部分
【补充】
1)论文的发表时间是:2018年5月14日,是在IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY上发表的论文
2)2017年12月20日收到手稿;2018年3月13日修订;2018年3月20日接受;2018年4月11日出版;本版日期:2018年5月14日。这项研究是在新加坡南洋科技大学的快速富物搜索(ROSE)实验室进行的。
【声明】本文是本人根据原论文进行翻译,有些地方加上了自己的理解,有些专有名词用了最常用的译法,时间匆忙,如有遗漏及错误,望各位包涵

题目:人脸反欺骗的广义深层特征表示
Abstract(摘要)
In this paper, we propose a novel framework leveraging the advantages of the representational ability of deep learning and domain generalization for face spoofing detection. In particular, the generalized deep feature representation is achieved by taking both spatial and temporal information into consideration, and a 3D convolutional neural network architecture tailored for the spatial-temporal input is proposed. The network is first initialized by training with augmented facial samples based on cross-entropy loss and further enhanced with a specifically designed generalization loss, which coherently serves as the regularization term. The training samples from different domains can seamlessly work together for learning the generalized feature representation by manipulating their feature distribution distances. We evaluate the proposed framework with different experimental setups using various databases. Experimental results indicate that our method can learn more discriminative and generalized information compared with the state-of-the-art methods.
本文提出了一种新的人脸欺骗检测框架,该框架充分利用了深度学习的表征能力和领域泛化的特点,实现了人脸欺骗检测。特别是考虑了时空信息,实现了广义深度特征表示,并提出了一种适合时空输入的三维卷积神经网络结构。该网络首先通过基于交叉熵损失的增强样本训练来初始化,然后通过特定设计的泛化损失 作为正则化项,对网络进行进一步增强。不同领域的训练样本通过调整特征分布距离,可以无缝地学习广义特征表示。我们使用不同的数据库并采用不同的实验设置,对我们提出的的框架进行了评价。实验结果表明,与现有的方法相比,我们的方法能够学习到更多的判别信息和广义信息。
Index Terms—Face spoofing, deep learning, 3D CNN, domain generalization.
术语索引--------面部欺骗,深度学习,三维CNN,领域泛化。
I. INTRODUCTION(引言)
BIOMETRICS offers a powerful and practical solution to authentication-required applications. Due to the breakthrough of biometrics authentication via deep learning and its better security capability compared with traditional authentication methods (e.g., password, secret question, token code), more and more attention has been attracted from both academia and industry nowadays. Typical biometric modalities include fingerprint, iris, face and voice print, among which “face” is the most popular one as it does not require any additional hardware infrastructure and almost all mobile phones are equipped with a front-facing camera. Despite the success of face recognition, it is still vulnerable to the presentation attacks due to the popularity of social media from which facial images are easy to acquire [1]. For instance, a presentation attack can record the face information of a person by printing (printing attack), replaying on screen (replay attack) or even counterfeiting the face via 3D masking [2] and VR [3], which brings extremely challenging security issues.
生物识别技术为有认证需求的应用程序提供了一个强大而实用的解决方案。由于生物特征认证的深度学习突破及其与传统认证方法(密码、秘密问题、令牌码等)相比具有更好的安全性,近年来从学术界到工业节都受到越来越多的关注。典型的生物识别方式包括指纹、虹膜、人脸和语音打印,其中“脸”是最受欢迎的,因为它不需要任何附加的硬件基础设施,几乎所有的手机都配备了正面摄像头( front-facing camera)。尽管人脸识别取得了成功,但由于社交媒体的普及,面部图像很容易从社交媒体中获取,因此仍然容易受到演示攻击( the presentation attacks) [1]。例如,演示攻击可以通过打印(打印攻击)、在屏幕上重放(重放攻击),甚至通过3D面具[2]和VR[3]伪造人脸来记录人的面部信息,这就带来了极具挑战性的安全问题。
Security concerns of face recognition systems have motivated a number of studies for face spoofing detection. From the perspective of evaluating the disturbance information injected into the spoofing media, a series of approaches aim at extracting the distortion information, which may appear on spoofed face samples. Typical spoofing artifacts include texture artifacts [4], motion artifacts [5] and image quality relevant artifacts [6]. Other approaches focus on the system level in which specific sensors (e.g., gravity sensor) can be utilized for auxiliary assistance [7] or additional hardware can be incorporated into the verification system (e.g., infrared sensor [8]). Moreover, human-computer interaction may also be required for spoofing detection (head moving, eye blinking, etc.) [9], [10].
人脸识别系统的安全性问题引发了大量人脸欺骗检测的研究,从对注入到欺骗介质中的干扰信息进行评估的角度出发,提出了一系列针对伪人脸样本中可能出现的失真信息的提取方法。典型的欺骗工件包括纹理伪影[4]、运动伪影[5]和与图像质量相关的伪影(relevant artifacts)[6]。其他方法侧重于系统一级,其中可利用特定传感器(例如重力传感器)辅助协助[7],或将额外硬件纳入核查系统(例如,红外传感器[8])。此外,欺骗检测(头部移动、眨眼等)也可能需要人机交互[9]、[10]。
With numerous approaches proposed to deal with the artifacts within a single image, there are still two important issues in face anti-spoofing. On one hand, how to generalize well to the “unseen data” becomes pivotal, as obtaining enough data with sufficient variability in the training process is not always practical. On the other hand, much less work has been dedicated to extracting information along the temporal direction, which can also provide valuable cues (liveness information, unexpected motion [9], [10], temporal aliasing, etc.). More importantly, learning spatial plus temporal features would become more difficult, as more training data would be necessary and the lack of generalization could be even more pronounced. All these issues cast challenges on the generalization capability of robust feature representation. In view of this, we focus on deep feature representation in a generalized way by exploiting the information from both spatial and temporal dimensions. In particular, 3D convolutional neural networks (3D CNN), which have been proved to be efficient for action recognition task [11], are employed to learn spoofing-specific information based on typical printed and replay video attacks.The solution incorporates 2D and 3D features related to the presentation attack problem, and learns not only spatial variations associated with attacks but also artifacts that takeplace over time. More specifically, we employ the 3D CNN architecture with a data augmentation strategy for the spoofing detection task. To obtain a more robust and generalized 3D CNN model, the lack of generalization is dealt with by introducing a regularization mechanism, which focuses on improving classification accuracy during training as well as
generalizing to unknown conditions by minimizing the feature distribution dissimilarity across domains. These capabilities allow us to make a further step regarding the detection of attacks under unknown or different conditions.
虽然众多处理单一图像中的真伪的方法已经被提出, 但是面对反欺骗仍然存在两个重要的问题。一方面,如何很好地泛化到“看不见的数据”成为关键,因为在训练过程中获得足够的、具有足够可变性的数据并不总是切实可行的。另一方面,更少的工作是沿着时间方向提取信息,这也可以提供有价值的线索(活性信息、意外运动[9]、[10]、时间混叠等)。另一方面,很少的工作是从时间的角度提取信息,而这也可以提供有价值的线索(活性信息、意外运动[9]、[10]、时间混叠等)。更重要的是,学习空间加上时间特征将变得更加困难,因为需要更多的训练数据,而缺乏泛化的情况可能更加明显。所有这些问题都对鲁棒特征表示的泛化能力提出了挑战,为此,我们从空间和时间两个维度出发,对深度特征表示进行了广义的研究。特别是,已被证明对行动识别任务[11]有效的三维卷积神经网络(3D CNN),被用于学习基于典型打印和重放视频攻击的特定欺骗信息。该解决方案结合了与表示攻击问题相关的2d和3d特征,不仅学习了与攻击相关的空间变化,而且还学习了随时间而发生的伪影信息(artifacts)。更具体地说,我们采用了带有数据增强策略的3D CNN结构来完成欺骗检测任务,为了获得一个更鲁棒、更泛化的3D CNN模型,通过引入正则化机制来解决其泛化不足的问题,该机制的重点是在训练过程中提高分类精度,并通过最小化域间的特征分布差异来泛化到未知条件。这些能力使我们能够进一步探测未知或不同条件下的攻击。
The main contributions of our work are as follows.
-
we apply a 3D CNN network which take both spatial and temporal information into consideration with a specifically designed data augmentation method for face spoofing detection.
-
To further improve the generalization performance, we employ a generalization regularization by minimizing the Maximum Mean Discrepancy distance among different domains.
-
We conduct extensive experimental analysis on four different datasets as well as our proposed cross-camera based protocol. The results show that our proposed framework can achieve significantly better performance compared with other state-of-the-art methods.
我们工作的主要贡献如下。
-
我们采用一种三维cnn网络,该网络考虑了时间和空间信息,采用了一种专门设计的数据增强方法进行人脸欺骗检测。
-
为了进一步提高泛化性能,我们采用了一种泛化正则化方法,使不同区域间的最大平均差异距离最小。
-
我们对四种不同的数据集和基于交叉摄像机的协议进行了广泛的实验分析,结果表明,与其他先进的方法相比,我们提出的框架可以获得更好的性能。
II. RELATED WORK(相关工作)
A. Face Anti-Spoofing(人脸反欺骗)
In terms of various application scenarios, we roughly categorize existing face spoofing detection methods into three categories, including motion analysis based [5] (which may require user cooperation), texture analysis based [4], [12], and sensor-assisted detection [7]. The first two categories can be generally applied to face verification/registration task with personal computers and mobile phones, while the last one requires extra hardwares. To further enhance the robustness
of biometric spoofing detection, some other biometrics information can be incorporated into the face antispoofing system (e.g. [13]–[16]).
在不同的应用场景中,我们将现有的人脸欺骗检测方法大致分为三类,包括基于的运动分析[5](可能需要用户合作)、基于的纹理分析[4]、[12]和传感器辅助检测[7]。前两类通常可以应用于个人计算机和移动电话的人脸验证/注册任务,而最后一类则需要额外的硬件。为了进一步增强生物识别欺骗的鲁棒性,检测时,还可以将其他一些生物特征信息纳入人脸反欺骗系统(例如[13]-[16])。
Motion analysis relies on extracting liveness information (e.g., eye blinking, lips movement, head rotation) for distinguishing between genuine and spoofed ones. For instance, such liveness information can be obtained via optical flow. In [5], Kollreider et al. reported that even subtle movement can be regarded as motion cues. For these kind of methods, the user assistance is usually required. Though motion analysis based methods are effective to counter printed photo attacks, they may suffer performance drops when the spoofing attack is conducted by video replay.
运动分析依赖于提取活跃度信息(如眨眼、嘴唇移动、头部旋转),以区分真假脸。例如,这种活性信息可以通过光流获得。在[5]中,kolereider等人报告说,即使是细微的运动也可以看作是运动线索。对于这类方法,通常需要用户的帮助。虽然基于运动分析的方法能够有效地抵抗印刷照片的攻击,但当通过视频重放进行欺骗攻击时,它们的性能可能会下降。
The idea of facial texture and distortion analysis originates from the assumption that the spoofed medium is likely to lack high-frequency information, due to the face media reproduction process. By analyzing the texture artifacts left behind during an attack, we can extract useful information such that the genuine and spoofed faces can be properly distinguished.In [17], a texture analysis method based on two dimensional Fourier spectrum is conducted. In [18], Tan et al. proposed a total-variation based decomposition method and extracted the different-of-Gaussian (DoG) information on the high-frequency part. The final model is learned in a bilinear sparse low-rank regression manner. Texture features designed for object detection/recognition tasks have also been proved to be effective for face spoofing detection. In [4], multi-scale Local Binary Pattern (LBP) with Support Vector Machine (SVM) classifier was proposed, achieving superior performance on NUAA [18] and Idiap REPLAY-ATTACK databases [19]. The multi-scale LBP feature was further extended to facial component based method followed by fisher vector [20], such that more discriminative information can be extracted. Other texture features, such as Scale Invariant Feature Transform (SIFT) and Speed Up Robust feature (SURF) [21], can also be applied to the face anti-spoofing task. As the high-frequency information can also be discarded in the temporal domain, the texture features based on 2-D plane can be extended to 3-D plane [22]. By jointly exploring color and texture information, the face anti-spoofing performance can be largely improved [12], [23]. Recently, a dynamic texture face spoofing was proposed [24] by considering volume local binary count patterns. Moreover, by incorporating flash light, the texture pattern can be detected more readily [25]. Another stream of feature design is based on image quality methods. In [6], 25 quality assessment based metrics were employed as the discriminative features for face spoofing detection. In [26], the authors extended the method in a regression manner to tackle the problem whereby samples were taken from multiple camera models. In [27], a feature concatenation based method was proposed by considering specular, blurriness and color distortion. However, both texture-based and distortion-based features are likely to be overfitted to one particular setup, which may limit their application for practical scenarios when confronting diverse image/video capturing conditions.
人脸纹理和失真分析的思想来源于这样一种假设,即由于人脸媒体的再现过程,欺骗介质很可能缺乏高频信息。通过分析攻击过程中留下的纹理伪影,我们可以提取有用的信息,从而正确区分真假人脸。在[17]中,提出了一种基于二维傅立叶谱的纹理分析方法。在[18]中,tan等人提出了一种基于全变差的分解方法,并提取了高频部分不同的高斯(DOG)信息。最后的模型采用双线性稀疏低秩回归方法学习,为目标检测/识别任务设计的纹理特征也被证明对于人脸欺骗检测有效。在[4]中,提出了使用支持向量机分类器的多尺度局部二值模式(LBP),在NUAA[18]和Idiap重播攻击数据库[19]上取得了较好的性能。将多尺度LBP特征进一步扩展到基于人脸分量的方法中,然后采用Fisher向量[20],从而提取出更多的判别信息。其他纹理特征,如尺度不变特征变换(cale Invariant Feature Transform---Sift)和加速鲁棒特征( Speed Up Robust feature---SURF)[21],也可应用于人脸防欺骗任务。由于高频信息在时域上也可以被丢弃,基于二维平面的纹理特征可以扩展到三维平面[22]。通过对颜色和纹理信息的联合研究,可以大大提高人脸的抗欺骗性能[12],[23]。最近,人们提出了一种考虑体积局部二进制计数模式的动态纹理人脸欺骗。此外,通过结合闪光灯,可以更容易地检测纹理模式[25]。另一种特征设计流基于图像质量方法。在文献[6]中,采用了25个基于质量评估的度量作为人脸欺骗检测的判别特征,在[26]中,作者将该方法进行了回归扩展,以解决从多个摄像机模型中抽取样本的问题。
在[27]中,提出了一种考虑镜面、模糊和颜色失真的基于特征级联的方法。然而,基于纹理的特征和基于失真的特征都可能被过拟合于特定的设置,这可能限制了它们在实际场景中的应用,当他们在面对不同的图像/视频捕获条件时。
In addition to motion analysis and texture analysis methods, additional sensors can also be leveraged for face spoofing detection. Compared with face images directly captured by the popular camera models, 3D depth information [28], [29], multi-spectrum and infrared images [8], and even vein flow information [30] can be obtained if additional sensors are deployed. Such methods can be enhanced by audio information [31], which can further improve the robustness of face spoofing detection. However, as additional equipments are required in such methods, they are usually more expensive
除了运动分析和纹理分析方法之外,还可以利用额外的传感器来进行人脸欺骗检测。与传统摄像机模型直接获取的人脸图像相比,增加传感器可以获得三维深度信息[28]、[29]、多光谱和红外图像[8],甚至静脉流信息[30]。这些方法可以通过音频信息[31]得到增强,从而进一步提高鲁棒性。然而,由于这些方法需要额外的设备,所以通常成本更高。
Deep learning based methods have also been proved to be effective for biometric spoofing detection tasks. Yang et al. [32] first proposed to use Convolutional Neural Network (CNN) for face spoofing detection. Some other works [33]–[36] have been proposed to modify the network architecture directly, which can further improve the detection accuracy. In [37], a CNN has been proved to be effective for face, fingerprint, and iris spoofing detection. Nogueira et al. [38] further showed that a pre-trained CNN model based on ImageNet [39] can be transferred to fingerprint spoofing detection without any fine-tuning process. In [2],
a deep dictionary learning based method was proposed for mask attacking detection. Additional information (e.g., eye blinking) can also be considered as auxiliary information by associating it with deep learning [40], which further improves the face spoofing detection performance. More recently, Atoum et al. [41] proposed a depth-based CNN for face spoofing detection to extract depth information based on RGB face images. Gan et al. [42] proposed a 3D CNN based framework to jointly capture the spatial and temporal information. As [42] also deals with 3D CNN for the PAD problem, it is important to highlight the differences between their method and the one we propose herein. In summary, our technique prioritizes 3×3×3 convolutions for better efficiency, and a streamlined strategy for temporal feature learning is adopted with different pre-preprocessing and augmentation mechanisms. In general, deep learning methods can achieve desirable performance when the training and testing samples are acquired in very similar conditions (e.g., captured with the same type of phone). However, such environment cannot be always ensured due to the diverse capturing devices, illumination conditions and shooting angles [43].
基于深度学习的方法对于生物识别欺骗检测任务也被证明是有效的。[32]首次提出将卷积神经网络(CNN)用于人脸欺骗检测,文[33]-[36]提出了直接修改网络结构的方法,进一步提高了检测精度。在[37]中,CNN被证明是一种有效的人脸、指纹和虹膜欺骗检测方法。Nogueira等人[38]进一步表明,基于ImageNet[39]的预先训练的cnn模型可以在没有任何微调过程的情况下转移到指纹欺骗检测中。文[2]中提出了一种基于深度字典学习的面具攻击检测方法。额外的信息(如眨眼)也可以被认为是辅助信息,通过将其与深度学习联系起来[40],这进一步提高了人脸欺骗检测性能。最近,阿图姆等人[41]提出了一种基于深度的cnn人脸欺骗检测方法,用于提取基于RGB人脸图像的深度信息。42]提出了一种基于3D CNN的联合捕获时空信息的框架。由于文[42]也针对PAD问题提出了3D CNN,因此必须强调它们与本文提出的方法之间的区别。总之,为了提高效率,我们对3×3×3卷积进行了排序,并针对不同的预处理和增强机制,采用了一种简化(流线型)的时态特征学习策略。一般来说,当训练和测试样本是在非常相似的条件下获得的时候(例如,用同一类型的手机捕捉到的),深度学习方法可以获得理想的性能。然而,由于捕获设备、光照条件和拍摄角度的不同,这种环境并不总是被保证。
B. Multimedia Recapturing Detection(多媒体重捕检测)
Multimedia recapturing aims at reproducing the content illegally from the perspective of security. During the multimedia content reproduction process, the camera, display screen as well as the lighting condition are carefully tuned to obtain the reproduced content with the best quality. To the best of our knowledge, the first work addressing the problem of image recapturing detection on LCD screens was proposed in [44], whereby three distortion types, including the texture
pattern caused by aliasing, the loss-of-detail pattern caused by the low resolution of LCD screens and the color distortion caused by the device gamut were analyzed. To address this problem, LBP, multi-scale wavelet statistics as well as color channel statistics were combined as a single feature vector for classification. As claimed in [45], although the texture pattern can be eliminated by setting the recapturing condition properly, the loss-of-detail artifact cannot be avoided during recapturing, which can be further employed as discriminative features for image reproduction detection. Recently, Li et al. [46] proposed a CNN+RNN framework to exploit the deep representation of recapturing artifacts, which was proved to be effective when using 32×32 image block as the input of the network. For video reproduction, Wang and Farid [47] proposed to explore geometry principles based on the motivation that the recaptured scene is constrained to a planar surface, while the original video was taken by projecting objects from the real world to the camera. In [47], both mathematical analysis and experimental results showed that the reproduction process can cause “non-zero” skew in the projection matrix by assumin that the skew value of camera for the original capturing was zero. Along this vein, the algorithm proposed in [48]detected the radial lens distortion based on the geometry principle. A mathematical model was built for lens distortion and distorted line based on the edge of video frame, which was regarded as discriminative cue for reproduction identification. In [48], the characteristic ghosting artifact, which is generated
从安全的角度来看,多媒体重捕的目的是非法复制内容。在多媒体内容再现过程中,对摄像机、显示屏以及光照条件进行了精心的调整,可以获得最优质的再现内容。据我们所知,文章 [44]首次提出了解决LCD屏幕上图像重建检测问题的工作,其中分析了三种失真类型,包括混叠引起的纹理模式、液晶显示屏低分辨率引起的细节丢失和器件色域引起的颜色失真。针对这一问题,将LBP、多尺度小波统计和彩色信道统计相结合,作为单一的特征向量进行分类。正如在[45]中所声称的那样,虽然通过适当设置恢复条件可以消除纹理模式,但在恢复过程中无法避免细节伪像的丢失,这可以进一步用作图像再现检测中的鉴别特征。.最近,Li等人。[46]提出了一种CNN+RNN的框架,当该框架以32×32图像块作为网络的输入,可以有效地利用了再现伪影的深度表示。对于视频再现,Wang和Farid[47]提出了一种探索几何原理的方法,他们将再现的场景限制在平面上,而原始的视频则是通过将物体从现实世界投射到摄像机上来实现的。在[47]中,无论是数学分析还是实验结果都表明,在投影矩阵中,通过假设摄像机的偏斜值为零,再现过程会导致投影矩阵中的“非零”偏斜。沿着这一思路,[48]中提出的基于几何原理的径向透镜畸变检测算法。基于视频帧的边缘,建立了镜头畸变和畸变线的数学模型,作为识别再现的依据。在[48]中,由于摄像机和投影屏幕之间缺乏同步而产生的特征重影伪影,可以作为鉴别信息被由两个Dirac脉冲组成的滤波器检测出来。
III. METHODOLOGY(方法)
Generally speaking, both spatial and temporal artifacts (e.g., unexpected texture patterns, color distortions and blurring [44], [49]) may occur during the face spoofing process.Regarding the texture pattern, such pattern appearing in spatial dimension is caused by the mismatch of the replay device resolution and the capturing device resolution [17] and texture distortion appeared on replay medium due to blurring artifact [27] and surface/glasses reflection [50], while
in temporal domain it is derived from the divergence between flash frequency of display device (e.g., 120 Hz) and the sampling frequency of video signal (e.g., 25 Hz). The color distortion is due to the mismatch of color gamut between the display medium and the recapturing model [51], [52]. Besides the texture pattern and color distortion, the unexpected motion such as display device shaking along the temporal dimension can also be beneficial for spoofing detection. Instead
of using the hand-crafted features in inferring the distinctive information, applying Convolutional Neural Network (CNN) to spoofing detection has shown promising results for different spoofing setups. However, as most of the current adopted CNN models for spoofing detection are based on 2D images
trained in a label-guided manner [37], [38], [41], there are two outstanding limitations:
-
Due to the limitation of the 2D CNN structure, the tem-poral statistics encoded in contiguous frames are ignored.
-
Directly applying the classification loss with label information can lead to overfitting problem to a certain database collection. In this scenario, the trained model cannot generalize well to the unseen data.
一般来说,在人脸欺骗过程中,可能会出现时空伪影(例如,意料之外的纹理模式、颜色畸变和模糊环[44]、[49])。关于纹理模式,这种模式出现在空间维中是由于重放设备分辨率和捕获设备分辨率[17]的不匹配造成的,而纹理失真则是由于模糊伪影[27]和表面/眼镜反射[50]而出现在重放介质上的。。而在时域,它是由显示设备的闪光灯频率(例如120赫兹)和视频信号的采样频率(例如25赫兹)之间的差异导致的。颜色失真是由于显示介质与再现模型[51]、[52]之间色域不匹配造成的,除了纹理模式和颜色失真外,显示装置沿时间方向抖动等意想不到的运动也有利于欺 骗检测。将卷积神经网络(Cnn)应用于欺骗检测,而不是利用手工构造的特征来推断不同的信息,在不同的欺骗机制中显示出了很好的效果。然而,由于目前采用的cnn欺骗检测模型大多是基于以标签引导方式训练的2d图像[37]、[38]、[41],因此存在两个突出的局限性:
-
由于二维CNN结构的局限性,忽略了连续帧编码的统计量。
-
直接将分类损失与标签信息相结合会导致对某一数据库集合的过度拟合问题,在这种情况下,经过训练的模型不能很好地泛化到未见数据。
In view of these limitations, we develop a 3D CNN architecture such that discriminative information can be learned from both spatial and temporal dimensions. In particular, when training and testing samples are captured under similar environments, our model can achieve lower error rate compared with 2D CNN models as well as other handcrafted features used in prior art. More importantly, when training a CNN by considering face samples collected from different cameras under diverse illumination conditions, the extracted featuresacross domains are expected to lie in a similar manifold such that a classifier trained with such features will have better generalization ability. In view of this, we also take advantage of domain generalization in network training by introducing a regularization term, which forces the learned features to share similar distributions. The pipeline of our proposed scheme is shown in Fig. 1.
鉴于这些局限性,我们开发了一种三维cnn结构,可以从空间和时间两方面学习鉴别信息。特别是,当训练和测试样本在类似的环境下被捕获时,我们的模型可以获得比2d cnn模型以及现有技术中使用的其他手工制作的特征的方法更低的误差率。更重要的是,当训练cnn时,考虑在不同的光照条件下从不同的摄像机采集的人脸样本,所提取的区域特征将位于一个相似的流形中,因此使用这些特征训练的分类器具有更好的泛化能力。鉴于此,我们还在网络训练中引入了一个正则化项,使学习到的特征共享相似的分布,从而利用了网络训练中的领域泛化,并在图1中给出了该方案的流水线图。
A. 3D Convolutional Neural Network(3D卷积神经网络)
In the 2D convolutional neural network, the convolution process is only applied on the 2D feature maps to compute the response in the spatial dimension, which has largely ignored the temporal information. In contrast with 2D CNN, the 3D CNN is conducted by convolving an input cube,which is stacked by multiple contiguous frames with a 3D kernel. We refer to the 3D convolution kernel size in the l−th layer by W l × H l × T l , where T l denotes the temporal depth and W l × H l represents the spatial size of the kernel. As such, the temporal information can also be preserved in the feature map. By jointly considering the temporal information, we can achieve better feature learning capability for face spoofing detection. In particular, each convolution operation is performed followed by a non-linear activation function such as ReLU. Mathematically, such process can be formulated as :
在二维卷积神经网络中,卷积过程只应用在二维特征映射上来计算空间维上的响应,而忽略了时间信息。与二维CNN相比,三维CNN是通过一个输入立方体来进行的,输入立方体由多个连续帧叠加而成,该立方体由一个三维核组成,我们将1层−第四层中的三维卷积核尺寸称为 W l × H l × T l ,其中Tl表示时间深度,Wl×Hl表示核的空间大小。因此,时间信息也可以保存在特征映射中。通过同时考虑时间信息,我们可以获得更好的人脸欺骗检测的特征学习能力。特别是当每次卷积运算之后都会有一个非线性激活函数时,如relu。从数学上讲,这样的过程可以表述为:
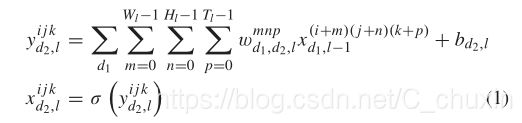
where ![]() is the value of a unit at position (i, j,k) in the d1−th feature map from the (l−1)-th layer,
is the value of a unit at position (i, j,k) in the d1−th feature map from the (l−1)-th layer, ![]() is the value of the element at position (m,n, p) of the 3D convolution kernel connected to the d 2 -th feature map in the l−th layer,
is the value of the element at position (m,n, p) of the 3D convolution kernel connected to the d 2 -th feature map in the l−th layer,![]() is the bias term, and σ(·) denotes a non-linear activation layer. Subsequently, a 3D pooling layer is applied to reduce the resolution of feature maps and enhance the invariance of the input signals to distortions. According to the research in [53], smaller receptive fields of 3D convolution kernels with deeper architectures can yield better performance for video classification. Although our problem is different from [53], we found out that adopting a smaller receptive field leads to better results for face spoofing detection as well. Therefore, in the 3D CNN architecture, we only consider the spatial-temporal receptive field as 3 × 3 × 3. The proposed 3D CNN model is detailed in Table I. This architecture has five
is the bias term, and σ(·) denotes a non-linear activation layer. Subsequently, a 3D pooling layer is applied to reduce the resolution of feature maps and enhance the invariance of the input signals to distortions. According to the research in [53], smaller receptive fields of 3D convolution kernels with deeper architectures can yield better performance for video classification. Although our problem is different from [53], we found out that adopting a smaller receptive field leads to better results for face spoofing detection as well. Therefore, in the 3D CNN architecture, we only consider the spatial-temporal receptive field as 3 × 3 × 3. The proposed 3D CNN model is detailed in Table I. This architecture has five
convolutional layers followed by the fully connected layer. The study regarding the appropriate number of convolutional layers is presented in Section IV-D.
其中,![]() 是在第(l−1)层的第d1个特征途图中位置为(i,j,k)的一个单元的值,
是在第(l−1)层的第d1个特征途图中位置为(i,j,k)的一个单元的值,![]() 是连接到第l层中第d2个特征图的3d卷积核位于(m,n,p)的元素的值。
是连接到第l层中第d2个特征图的3d卷积核位于(m,n,p)的元素的值。![]() 为偏置项,σ(·)表示非线性激活层。然后,采用3D池层来降低特征映射的分辨率,提高输入信号对失真的不变性。根据文献[53]的研究,结构较深的三维卷积核的接受域较小,可以获得更好的视频分类性能。虽然我们的问题与[53]不同,但我们发现,采用较小的接收场也可以获得更好的人脸欺骗检测结果,因此,在三维CNN结构中,我们只考虑3×3×3的时空接受场。所提出的三维CNN模型详见表一。该体系结构有五个卷积层,然后是完全连接层。在第IV-D节中对适当的卷积层数进行了研究。
为偏置项,σ(·)表示非线性激活层。然后,采用3D池层来降低特征映射的分辨率,提高输入信号对失真的不变性。根据文献[53]的研究,结构较深的三维卷积核的接受域较小,可以获得更好的视频分类性能。虽然我们的问题与[53]不同,但我们发现,采用较小的接收场也可以获得更好的人脸欺骗检测结果,因此,在三维CNN结构中,我们只考虑3×3×3的时空接受场。所提出的三维CNN模型详见表一。该体系结构有五个卷积层,然后是完全连接层。在第IV-D节中对适当的卷积层数进行了研究。
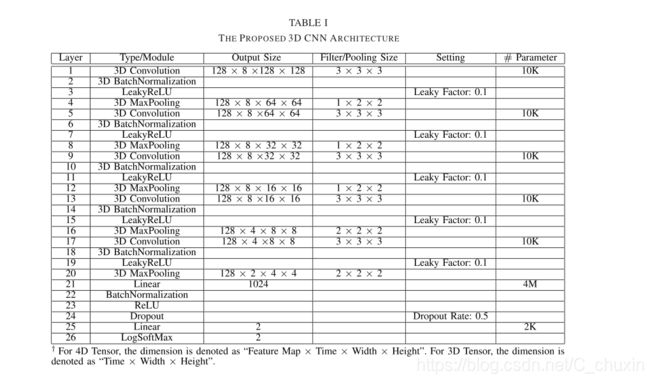
表1、提出的3D卷积神经网络的结构
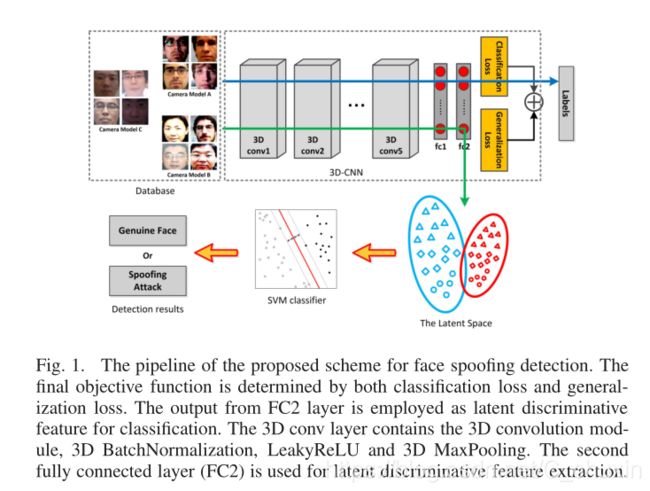
图1、本文提出的人脸欺骗检测方案的流水线,最终目标函数由分类损失和广义损失共同决定,fc2层的输出作为潜在的判别特征进行分类。三维卷积层包括三维卷积模式、三维批量归一化、LeakyReLU层和三维最大池化层,第二完全连通层(Fc2)用于潜在判别特征提取。
B. Data Augmentation(数据增强)
As it can be observed from Table I, our proposed 3D CNN model has more than 4M parameters to be optimized. However, existing samples in public databases are not enough to train such model. Therefore, the underfitting problem can not be avoided due to the large number of parameters in the model and the sparsity of training samples. To address this issue, we propose a data augmentation method based on video cubes to increase the number of training data. It should be noted that traditional augmentation methods such as injecting additional noise may not be feasible for the spoofing detection problem, given that the distortion information plays a key role in face spoofing detection. Therefore, the strategy of augmenting the video cubes is developed concerning this task.
从表一可以看出,我们提出的三维cnn模型有超过4M个参数需要优化,但是现有的公共数据库样本不足以训练这类模型,因此,由于模型中大量参数和训练样本的稀疏性,无法避免模型的欠拟合问题。针对这一问题,我们提出了一种基于视频立方体的数据增强方法,以增加训练数据的数量。需要注意的是,传统的增强方法,如注入附加噪声等,对于欺骗检测问题并不可行,因为失真信息在人脸欺骗检测中起着关键的作用。因此,针对这一任务,提出了一种增强视频立方体的策略。
1) Spatial Augmentation: To mitigate the variation of background for face spoofing detection, face detection is usually conducted as a pre-processing step [19]. However, variations of background near face regions can even be beneficial to face spoofing detection when considering deep learning approaches, as spoofing artifacts can be from the background region or the bezel of spoofing medium. Therefore, we propose to shift the boundingbox in four different directions (up, down, right and left) by α · l, where l is equal to the width/height of bounding box. The parameter α is a predefined scaling factor, which is empirically set to 0.2 in our work. We stop the spatial augmentation if the bounding box moves out of the image boundary. We show an example of spatial augmentation in Fig. 2.
1)空间增强:为了减少人脸欺骗检测背景的变化,人脸检测通常是作为预处理步骤进行的[19],但是,在考虑深入学习的方法时,人脸区域附近背景的变化甚至有利于人脸欺骗检测,因为欺骗伪影可以来自背景区域或欺骗介质的边框。因此,我们提出用α·l将边框在四个不同方向(上、下、右、左)移动,其中l等于边框的宽度/高度,参数α是一个预定义的缩放因子,在我们的工作中经验地设置为0.2,如果边框移出图像边界,我们停止空间增强,我们在图2中给出了一个空间增强的例子。
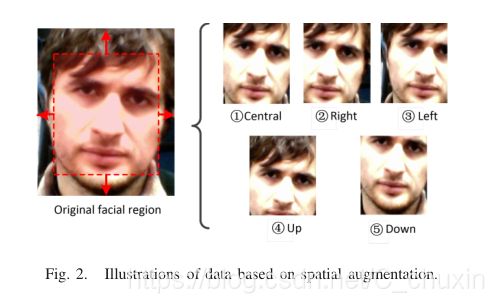
图2、基于空间增强的数据说明。
2) Gamma Correction Based Augmentation: To take the display medium diversity due to different types of capturing devices into consideration, we conduct a gamma correction based augmentation on each individual frame of a given video cube. Considering the face captured by a certain camera model with gamma value γ 1 , the gamma correction process to γ 2 can be represented as
2)基于伽马校正的增强:为了考虑由于不同类型的捕获设备而产生的显示介质的多样性,我们对给定的视频立方体的每个帧进行伽马校正增强。考虑到用γ值为γ1的摄像机模型捕捉到的人脸,对γ2的伽马校正过程可以表示为:
![]()
where I and I aug are the original pixel and augmented pixel, respectively, in RGB space. ‘|·|’ denotes the round and truncation operations, where the output value is truncated into the range [0,255]. Since the camera performs linear correction (γ = 1.0) and exponential gamma correction (e.g. γ = 2.2) before display, 1 we choose the ratio γ 2 /γ 1 to be 1.0/2.2 and 2.2/1.0 for augmentation in our work. We show an example 。
0of gamma correction based augmentation in Fig. 3.
其中I和I aug分别是RGB空间中的原始像素和增广像素。“|·|”表示圆形和截断操作(机下取整),其中输出值被截断到范围[0,255]。因为摄像机执行线性校正(γ=1.0)并在显示前进行了指数伽玛校正(如γ=2.2),所以我们选择γ2/γ1为1.0/2.2和2.2/1 0作为增强,图3给出了基于γ校正的增强图。

图3、基于伽玛校正基础上的数据增强的图解。(A)原始脸;(B)伽马校正比1.0/2.2的脸;(C)伽马校正比2.2/1.0的脸。
C. Model Generalization(模型泛化)
Although deep learning is powerful in learning representative information when training data are diverse, it may still suffer from performance degradation when test data are “unseen”, such as the test samples obtained from a different environment from the training data. Generally speaking, it is impossible to involve face samples captured by all types of cameras from every potential scenario. In view of this,we leverage the advantage of domain generalization [54] to solve this problem. More specifically, given face samples from a few different capturing conditions, by partitioning the face samples into different domains based on the capturing conditions, we aim at learning a robust representation across different domains for face spoofing detection by introducing the generalization loss as the regularization term. As such, the generalization capability of the network can be better enhanced.
尽管在训练数据多样化的情况下,深度学习在学习表示信息方面有很强的作用,但是当测试数据“看不见”时,它仍然会受到性能下降的影响,例如,从与训练数据中不同的环境中获取的测试样本。一般来说,不可能获得从每一种可能的场景中并涉及到所有类型的摄像机捕捉到的面部样本。鉴于此,我们利用领域泛化[54]的优势来解决这个问题。更具体地说,给出几个不同捕获条件下的人脸样本,根据捕获条件将人脸样本划分成不同的区域,通过引入泛化损失作为正则化项,学习不同域间的鲁棒表示来进行人脸欺骗检测。
因此,可以更好地提高网络的泛化能力。

假设有来自L个训练域的样本,用 X = [X 1 ,X 2 ,...,X L ]表示,Xi代表区域I中的样本,x中的样本总数为 N 1 + N 2 + ... + N L,其中N 1 , N 2 ,..., NL 是来自每个区域的样本数。另外,假定网络的第f层的特征输入为![]() ,
,![]() 其中
其中![]() 是指从域i(的数据)得到的第f个全连通层的特征。我们进一步表示
是指从域i(的数据)得到的第f个全连通层的特征。我们进一步表示![]() ,作为
,作为![]() 中第k个样本的输入特征。为了使来自不同领域的特征分布对齐,我们采用了最大平均偏差(Maximum Mean Discrepancy---MMD)[55],这是衡量两种分布之间相似性的一种流行的度量方法,以最小化区域间的特征分布差异。因此,给定两个分布,如果它们之间的MMD距离等于零,它们是相同的。为了学习广义特征表示,我们的目标是优化网络,将输入样本X嵌入Yf,使不同区域之间的MMD距离最小化[55]。
中第k个样本的输入特征。为了使来自不同领域的特征分布对齐,我们采用了最大平均偏差(Maximum Mean Discrepancy---MMD)[55],这是衡量两种分布之间相似性的一种流行的度量方法,以最小化区域间的特征分布差异。因此,给定两个分布,如果它们之间的MMD距离等于零,它们是相同的。为了学习广义特征表示,我们的目标是优化网络,将输入样本X嵌入Yf,使不同区域之间的MMD距离最小化[55]。



这里给出了多个区域间的MMD距离的定义:
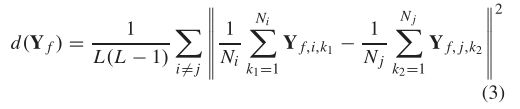
它可以进一步重写为:
![]()
其中Kf是基于Yf的 Gram矩阵,Kf=![]() ,而Q定义为:
,而Q定义为:

Q是基于域对样本定义的系数矩阵。特别地,给出了域i和j的矩阵块Qi,j的定义:
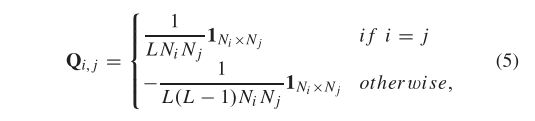
其中,![]() 表示维数为
表示维数为![]() 的全1矩阵.泛化损失相对于网络参数Θ的梯度可以计算为:
的全1矩阵.泛化损失相对于网络参数Θ的梯度可以计算为:

其中,![]() 可通过反向传播方法获得[56]。
可通过反向传播方法获得[56]。
为了学习我们提出的三维CNN网络的广义特征表示,我们从零开始对从多个区域采集的具有交叉熵损失(L)[57]的人脸样本进行训练。此外,需要同时最小化各区域之间的MMD距离。因此,网络参数可以通过下式进行学习:
![]()
其中,θ是网络参数,而R的定义如下:
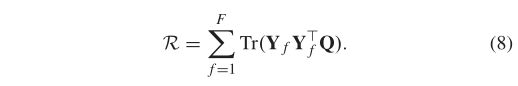
这里f是网络中完全连接层的数目,在我们的工作中设置为2,因为我们建议的网络中有两个完全连接的层。
---------------------------------------------------------未完待续---------------------------------------------------------------------