软件工程应用与实践(四):Paddle OCR文字识别器策略二
2021SC@SDUSC
目录
一、前情回顾:文字识别器模型的策略介绍
1.策略回顾
总体
本人负责
2.本文所介绍的文字识别器模块策略(接上次)
策略
介绍
二、序列化介绍
1.文字识别器的架构
2.基于架构的RNN网络与SRN网络介绍
传统RNN网络存在的问题
SRN的特色
SRN构成
SRN-PVAM并行视觉注意力模块
SRN-GSRM全局语义推理模块
SRN-VSFD视觉-语义融合解码器
三、主要策略与代码解释
文件rec_srn_head.py
总结
一、前情回顾:文字识别器模型的策略介绍
1.策略回顾
总体
策略的选用主要是用来增强模型能力和减少模型大小。下面是PP-OCR文字识别器所采用的九种策略:
- 轻主干,选用采用 MobileNetV3 large x0.5 来权衡精度和效率;
- 数据增强,BDA (Base Dataaugmented)和TIA (Luo et al. 2020);
- 余弦学习率衰减,有效提高模型的文本识别能力;
- 特征图辨析,适应多语言识别,进行向下采样 feature map的步幅修改;
- 正则化参数,权值衰减避免过拟合;
- 学习率预热,同样有效;
- 轻头部,采用全连接层将序列特征编码为预测字符,减小模型大小;
- 预训练模型,是在 ImageNet 这样的大数据集上训练的,可以达到更快的收敛和更好的精度;
- PACT量化,略过 LSTM 层;
本人负责
- 轻主干,选用采用 MobileNetV3 large x0.5 来权衡精度和效率;
- 数据增强,BDA (Base Dataaugmented)和TIA (Luo et al. 2020);
- 余弦学习率衰减,有效提高模型的文本识别能力;
- 特征图辨析,适应多语言识别,进行向下采样 feature map的步幅修改
- 轻头部,采用全连接层将序列特征编码为预测字符,减小模型大小;
2.本文所介绍的文字识别器模块策略(接上次)
策略
- 轻头部,采用全连接层将序列特征编码为预测字符,减小模型大小;
介绍
在一般情况下采用全连接层将序列特征编码为预测字符。序列特征的维数对文本识别器的模型大小有影响,特别是对于汉字超过 6000 个字符的识别。同时,并不是维数越高,序列特征表示能力越强。在 PP-OCR 中,经验上将序列特征的维数设为 48,从而达到减小模型,减轻头部的目的。
二、序列化介绍
1.文字识别器的架构
为了介绍轻头部策略算法。这里再次对Paddle OCR文字识别器的相关结构进行介绍。也是对上一篇文章的一些补充。因为上一篇文章直接根据代码和组网组成来进行介绍。这里对Paddle OCR文字识别器模型架构简单进行了解。
文字识别算法有两个方向构成,分别时基于attention和基于CTC。其主要区别是将网络学习到的序列特征转化为最终识别结果的处理方式不同。下图是两种方向算法步骤的图示:

由上图,故在进行组网架构时,整个文字识别体系中,骨干backbone、颈部neck、头部head都要根据两种算法来构建。上一篇文章介绍了Paddle OCR的组网的包构成,这里不再仔细介绍。本文重点介绍轻头部策略所涉及的头部组网构建。
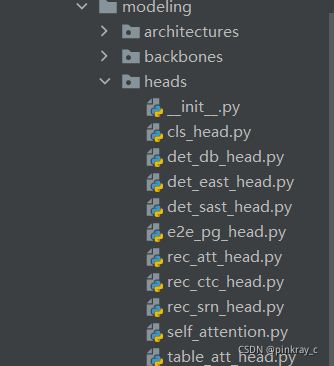
在头部组网构建,包含文字识别模型的CTC头部、文字识别模型的attention头部以及文字识别的SRN头部。下图是PP-OCR的头部包构成:
2.基于架构的RNN网络与SRN网络介绍
在文字识别器的架构部分涉及到了SRN头部。SRN,是百度Paddle OCR自研的文字识别算法,它一种新颖的端到端可训练框架,该框架称为语义推理网络,用于准确的场景文本识别。主要是为了解决传统文字识别所适用的RNN所存在的相关问题。
传统RNN网络存在的问题
1.传统RNN类的方法未充分利用图像中的语义信息;
2.传统RNN类的方法基于时序解码和翻译,影响效果和速度;
SRN的特色
1.提出SRN网络,有效结合视觉特征和语义信息;
2.并行视觉注意模块PVAM:并行带注意力的视觉特征对齐;
3.全局语义推理模块GSRM:并行语义推理,利用全局语义信息快速推理;
4.视觉语义融合解码器VSFD:视觉信息和语义信息有效解码;
SRN构成
SRN是一个端到端的可训练框架,由四个部分组成:主干网络、并行视觉注意模块(PVAM)、全局语义推理模块(GSRM)和视觉语义融合解码器(VSFD)。 给定输入图像,首先使用主干网络提取2D特征V。 然后,PVAM用于生成N个对齐的一维特征G,其中每个特征对应于文本中的一个字符并捕获对齐的视觉信息。 然后将这N个一维特征G送入我们的GSRM中,以捕获语义信息S。最后,VSFD将对齐的视觉特征G和语义信息S融合在一起,以预测N个字符。 对于小于N的文本字符串,将填充“ EOS”。 SRN的详细结构如下图所示:

SRN-PVAM并行视觉注意力模块
注意力机制可以描述如下:给定键值集(ki,vi)和查询q,计算查询q与所有键ki之间的相似度。然后,根据相似性将值vi汇总。概括图如下:

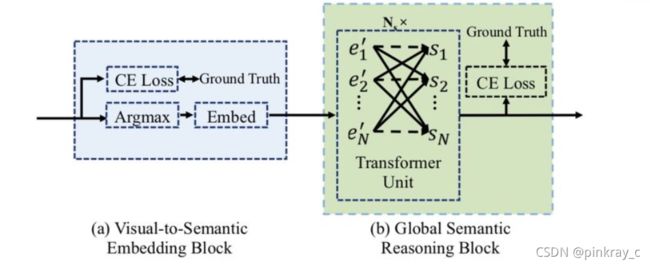
SRN-GSRM全局语义推理模块
GSRM的结构由两个关键部分组成:视觉到语义的嵌入块和语义推理块。

SRN-VSFD视觉-语义融合解码器
考虑视觉对齐特征G和语义信息S对于场景文本识别非常重要。但是,G和S属于不同的域,并且在不同情况下用于最终序列识别的权重也应不同,引入了一些可训练的权重,以平衡VSFD中来自不同域的要素的贡献
三、主要策略与代码解释
文件rec_srn_head.py
#PVAM模块部分
class PVAM(nn.Layer):
def __init__(self, in_channels, char_num, max_text_length, num_heads,
num_encoder_tus, hidden_dims):
#……
def forward(self, inputs, encoder_word_pos, gsrm_word_pos):
#……
#GSRM模块部分
class GSRM(nn.Layer):
def __init__(self, in_channels, char_num, max_text_length, num_heads,
num_encoder_tus, num_decoder_tus, hidden_dims):
#……
def forward(self, inputs, gsrm_word_pos, gsrm_slf_attn_bias1,
gsrm_slf_attn_bias2):
#……
class VSFD(nn.Layer):
def __init__(self, in_channels=512, pvam_ch=512, char_num=38):
#……
def forward(self, pvam_feature, gsrm_feature):
#……
#头部
class SRNHead(nn.Layer):
def __init__(self, in_channels, out_channels, max_text_length, num_heads,
num_encoder_TUs, num_decoder_TUs, hidden_dims, **kwargs):
#……
#pvam
self.pvam = PVAM(
in_channels=in_channels,
char_num=self.char_num,
max_text_length=self.max_length,
num_heads=self.num_heads,
num_encoder_tus=self.num_encoder_TUs,
hidden_dims=self.hidden_dims)
#gsrm
self.gsrm = GSRM(
in_channels=in_channels,
char_num=self.char_num,
max_text_length=self.max_length,
num_heads=self.num_heads,
num_encoder_tus=self.num_encoder_TUs,
num_decoder_tus=self.num_decoder_TUs,
hidden_dims=self.hidden_dims)
#vsfd
self.vsfd = VSFD(in_channels=in_channels, char_num=self.char_num)
#……
def forward(self, inputs, targets=None):
#……
#返回预测
return predicts
总结
以上是今天PP-OCR文字识别模型的轻头部策略相关代码及知识研读。之后将会介绍PP-OCR文字识别模型的其他策略。