机器学习之Python常用函数及模块整理
机器学习之Python常用函数及模块整理
- 1. map函数
- 2. apply函数
- 3. applymap函数
- 4. groupby函数
- 5. agg函数
- 6. lambda函数
- 7. rank函数
- 8. pandas set_option函数: 数据框展示设置
- 9. eval和ast.literal_val:字符串解析
- 10. python中日期函数
-
- 10.1 strftime函数: datetime类---> string
- 10.2 strptime函数: string---> datetime类
- 10.3 日历函数
- 11. transform函数
- 12. 缺失值处理
-
- 12.1 缺失值定位
- 12.2 缺失值删除
- 12.3 缺失值填充
- 13. logging:日志处理
- 14. 数据框合并:merge、concat、join、append函数
-
- 14.1 merge函数
- 14.2 concat函数
- 14.3 join函数
- 14.4 append函数
- 14.5 实战案例
- 15. squeeze函数-压缩
- 16.break和continue语句
-
- 16.1 break
- 16.2 continue
- 17.定义函数之可变参数(*args和**kwargs)
-
- 17.1 可变参数
- 17.2 可变关键字参数
- 18.jupyter notebook中生成.py文件
- 19. 查看当前工作目录及删除文件:os模块
- 20. 异常
-
- 20.1 捕捉异常-try except finally
- 21.类
-
- 21.1类的定义
- 21.2 类的继承
- 22. 文件及文件夹遍历(os.walk函数)
- 23. 文件目录处理模块-os和shutil
-
- 23.1 os模块
-
- 23.1.1 os操作
- 23.1.2 os.path操作
- 23.2 shutil模块
- 24. glob.glob()函数:查找符合条件的文件
1. map函数
# 全美婴儿姓名数据,包含了1880-2018年全美每年对应每个姓名的新生儿数据
import pandas as pd
#读入数据
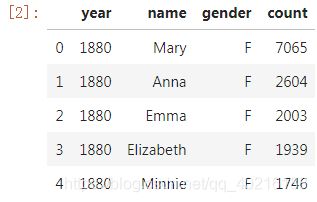
data=pd.read_csv('data.csv')
data.head()
#打印数据类型及数据框尺寸
print(data.dtypes)
print(data.shape)

1) 字典映射
#定义F->女性,M->男性的映射字典
gender2xb = {'F': '女性', 'M': '男性'}
#利用map()方法得到对应gender列的映射列
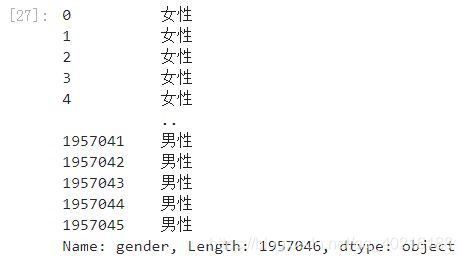
data.gender.map(gender2xb)

2)常规函数
def gender_to_xb(x):
return '女性' if x is 'F' else '男性'
data.gender.map(gender_to_xb)

3) 特殊对象
data.gender.map("This kid's gender is {}".format)

map()还有一个参数na_action,取值为None或ingore,用于控制遇到缺失值的处理方式,设置为ingore时串行运算过程中将忽略Nan值原样返回。
2. apply函数
apply()堪称pandas中最好用的方法,其使用方式跟map()很像,主要传入的主要参数都是接受输入返回输出。
但相较于map()针对单列Series进行处理,一条apply()语句可以对单列或多列进行运算,覆盖非常多的使用场景。
1) 单列数据
data.gender.apply(lambda x:'女性' if x is 'F' else '男性')
此时功能和map函数一样。
2)输入多列数据
譬如这里我们编写一个使用到多列数据的函数用于拼成对于每一行描述性的话,并在apply()用lambda函数传递多个值进编写好的函数中(当调用DataFrame.apply()时,apply()在串行过程中实际处理的是每一行数据,而不是Series.apply()那样每次处理单个值)。
注意在处理多个值时要给apply()添加参数axis=1
def generate_descriptive_statement(year, name, gender, count):
year, count = str(year), str(count)
gender = '女性' if gender is 'F' else '男性'
return '在{}年,叫做{}性别为{}的新生儿有{}个。'.format(year, name, gender, count)
data.apply(lambda row:generate_descriptive_statement(row['year'],
row['name'],
row['gender'],
row['count']),
axis = 1)

3)输出多列数据
有些时候我们利用apply()会遇到希望同时输出多列数据的情况,在apply()中同时输出多列时实际上返回的是一个Series,这个Series中每个元素是与apply()中传入函数的返回值顺序对应的元组。
比如下面我们利用apply()来提取name列中的首字母和剩余部分字母:
data.apply(lambda row: (row['name'][0], row['name'][1:]), axis=1)

可以看到,这里返回的是单列结果,每个元素是返回值组成的元组,这时若想直接得到各列分开的结果,需要用到zip(*zipped)来解开元组序列,从而得到分离的多列返回值:
a, b = zip(*data.apply(lambda row: (row['name'][0], row['name'][1:]), axis=1))
print(a[:10])
print(b[:10])

4)结合tqdm给apply()过程添加进度条
我们知道apply()在运算时实际上仍然是一行一行遍历的方式,因此在计算量很大时如果有一个进度条来监视运行进度就很舒服。
tqdm:用于添加代码进度条的第三方库tqdm对pandas也是有着很好的支持。
我们可以使用progress_apply()代替apply(),并在运行progress_apply()之前添加tqdm.tqdm.pandas(desc=‘’)来启动对apply过程的监视。
其中desc参数传入对进度进行说明的字符串:
from tqdm import tqdm
def generate_descriptive_statement(year, name, gender, count):
year, count = str(year), str(count)
gender = '女性' if gender is 'F' else '男性'
return '在{}年,叫做{}性别为{}的新生儿有{}个。'.format(year, name, gender, count)
#启动对紧跟着的apply过程的监视
tqdm.pandas(desc='apply')
data.progress_apply(lambda row:generate_descriptive_statement(row['year'],
row['name'],
row['gender'],
row['count']),
axis = 1)

5)结合tqdm_notebook()给apply()过程添加美观进度条
熟悉tqdm的朋友都知道其针对jupyter notebook开发了ui更加美观的tqdm_notebook()。
而要想在jupyter notebook/jupyter lab平台上为pandas的apply过程添加美观进度条,可以参照如下示例:
from tqdm._tqdm_notebook import tqdm_notebook
tqdm_notebook.pandas(desc='apply')
data.progress_apply(lambda row:generate_descriptive_statement(row['year'],
row['name'],
row['gender'],
row['count']),
axis = 1)

3. applymap函数
applymap()是与map()方法相对应的专属于DataFrame对象的方法,类似map()方法传入函数、字典等,传入对应的输出结果。
不同的是applymap()将传入的函数等作用于整个数据框中每一个位置的元素,因此其返回结果的形状与原数据框一致。
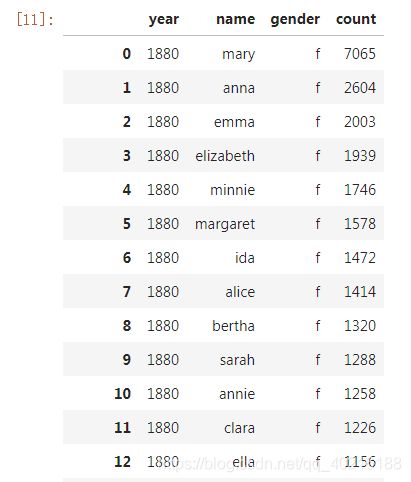
譬如下面的简单示例,我们把婴儿姓名数据中所有的字符型数据消息小写化处理,对其他类型则原样返回:
def lower_all_string(x):
if isinstance(x, str):
return x.lower()
else:
return x
data.applymap(lower_all_string)
其形状没有变化
data.applymap(lower_all_string).shape==data.shape

4. groupby函数
其主要使用到的参数为by,这个参数用于传入分组依据的变量名称,当变量为1个时传入名称字符串即可。
当为多个时传入这些变量名称列表,DataFrame对象通过groupby()之后返回一个生成器,需要将其列表化才能得到需要的分组后的子集,如下面的示例
#按照年份和性别对婴儿姓名数据进行分组
groups = data.groupby(by=['year','gender'])
#查看groups类型
type(groups)
![]()
可以看到它此时是生成器,下面我们用列表解析的方式提取出所有分组后的结果:
#利用列表解析提取分组结果
groups = [group for group in groups]
查看其中的一个元素

可以看到每一个结果都是一个二元组,元组的第一个元素是对应这个分组结果的分组组合方式,第二个元素是分组出的子集数据框。
1)直接调用聚合函数
我们提取count列后直接调用max()方法
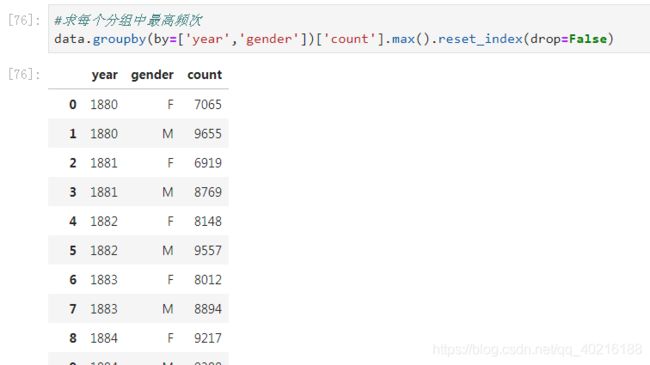
#求每个分组中最高频次
data.groupby(by=['year','gender'])['count'].max()
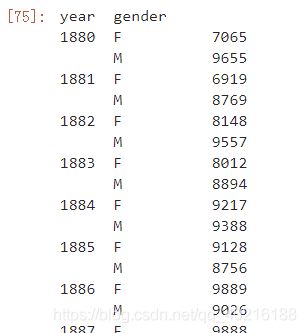
注意这里的year、gender列是以索引的形式存在的,想要把它们还原回数据框,使用reset_index(drop=False)即可
#求每个分组中最高频次
data.groupby(by=['year','gender'])['count'].max().reset_index(drop=False)
#求每个分组中最高频次
data.groupby(by=['year','gender'])['count'].max()
2) 结合apply()
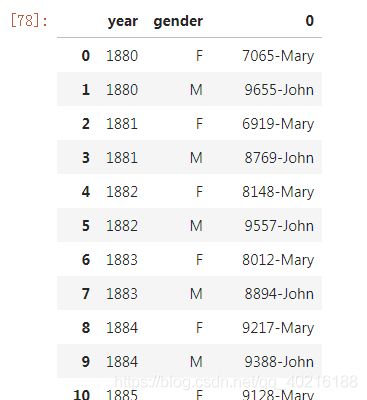
分组后的结果也可以直接调用apply(),这样可以编写更加自由的函数来完成需求,譬如下面我们通过自编函数来求得每年每种性别出现频次最高的名字及对应频次。
要注意的是,这里的apply传入的对象是每个分组之后的子数据框,所以下面的自编函数中直接接收的df参数即为每个分组的子数据框:
import numpy as np
def find_most_name(df):
return str(np.max(df['count']))+'-'+df['name'][np.argmax(df['count'])] #np.argmax返回最大值对应的索引
data.groupby(['year','gender']).apply(find_most_name).reset_index(drop=False)
5. agg函数
利用agg()进行更灵活的聚合agg即aggregate,聚合,在pandas中可以利用agg()对Series、DataFrame以及groupby()后的结果进行聚合。
其传入的参数为字典,键为变量名,值为对应的聚合函数字符串,譬如{‘v1’:[‘sum’,‘mean’], ‘v2’:[‘median’,‘max’,'min]}就代表对数据框中的v1列进行求和、均值操作,对v2列进行中位数、最大值、最小值操作。
a) 聚合series
在对Series进行聚合时,因为只有1列,所以可以不使用字典的形式传递参数,直接传入函数名列表即可:
#求count列的最小值、最大值以及中位数
data['count'].agg(['min','max','median'])
b) 聚合数据框
对数据框进行聚合时因为有多列,所以要使用字典的方式传入聚合方案:
data.agg({'year': ['max','min'], 'count': ['mean','std']})
值得注意的是,因为上例中对于不同变量的聚合方案不统一,所以会出现NaN的情况。
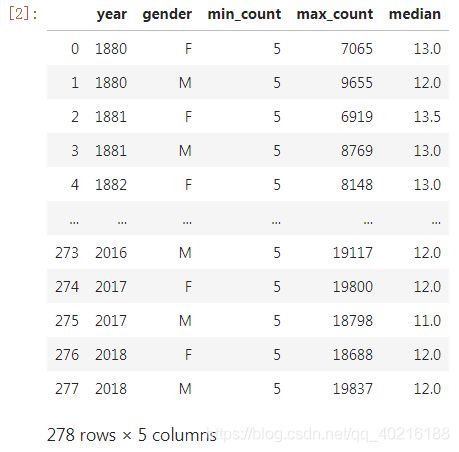
c) 聚合groupby()结果
data.groupby(['year','gender']).agg({'count':['min','max','median']}).reset_index(drop=False)

可以注意到虽然我们使用reset_index()将索引列还原回变量,但聚合结果的列名变成红色框中奇怪的样子,而在pandas 0.25.0以及之后的版本中,可以使用pd.NamedAgg()来为聚合后的每一列赋予新的名字:
data.groupby(['year','gender']).agg(
min_count=pd.NamedAgg(column='count', aggfunc='min'),
max_count=pd.NamedAgg(column='count', aggfunc='max'),
median=pd.NamedAgg(column='count', aggfunc='median')).reset_index(drop=False)
6. lambda函数
在Python中,lambda函数是使用lambda表达式定义的单行匿名函数。它常用于将函数作为参数传递等场景。
lambda函数具有lambda <参数> : <表达式>的格式。它没有函数名,函数体只有一条语句,这条语句的结果就是该函数的返回值。
#数据gender列性别中只有F和M所以编写如下lambda函数
data.gender.map(lambda x:'女性' if x is 'F' else '男性')

7. rank函数
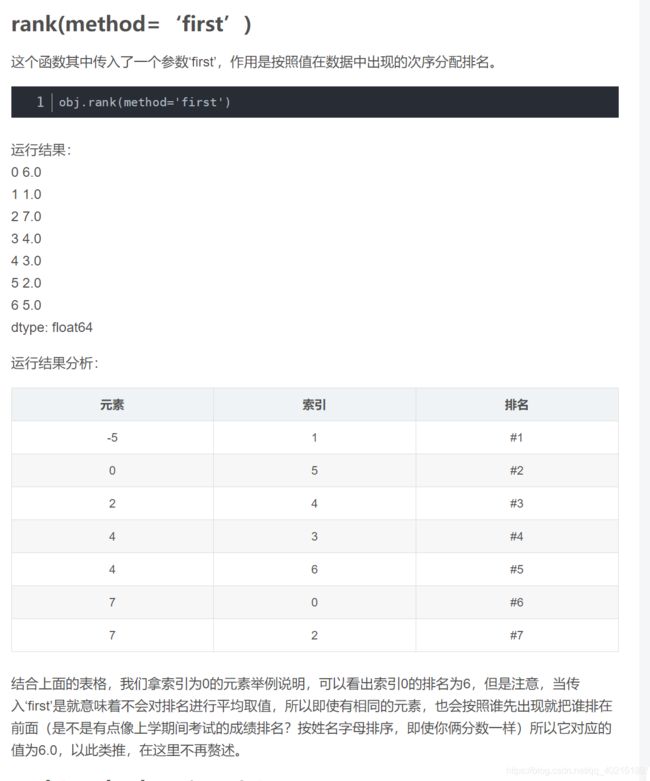
rank()函数
”排名“,是指对数组从1到有效数据点总数分配名次的操作。
默认情况下,rank通过将平均排名分配到每个组来打破平级关系:
import pandas as pd
obj = pd.Series([7,-5,7,4,2,0,4])
obj

obj.rank() #选择默认参数

根据上面的表格可以看出,索引0对应的元素排名为6,但是使用rank()会对排名求平均值,也就是说有N个相同的元素,排名会相加并除以N,所以说索引0对应的元素最终排名为6.5;索引1对应的元素排名为1,所以它对应的排名值为1.0,以此类推得出上述运行结果。
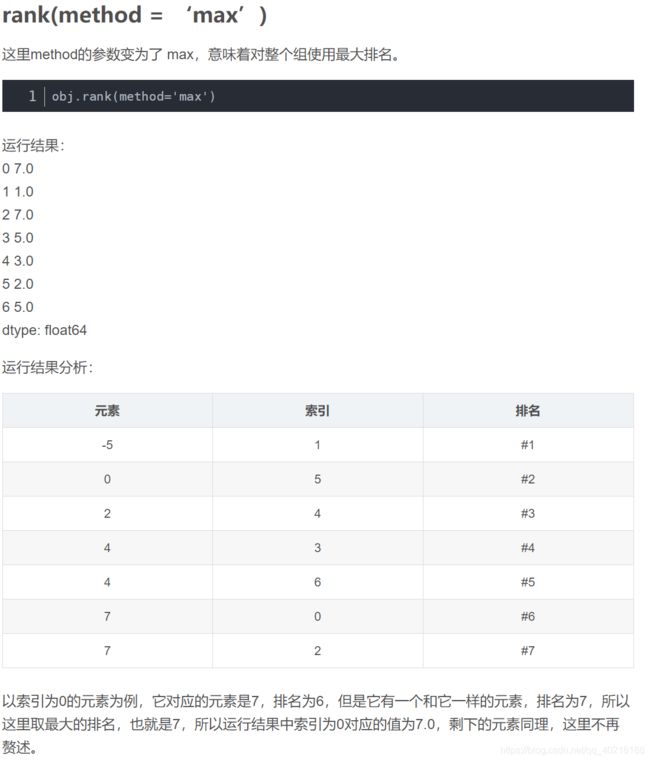
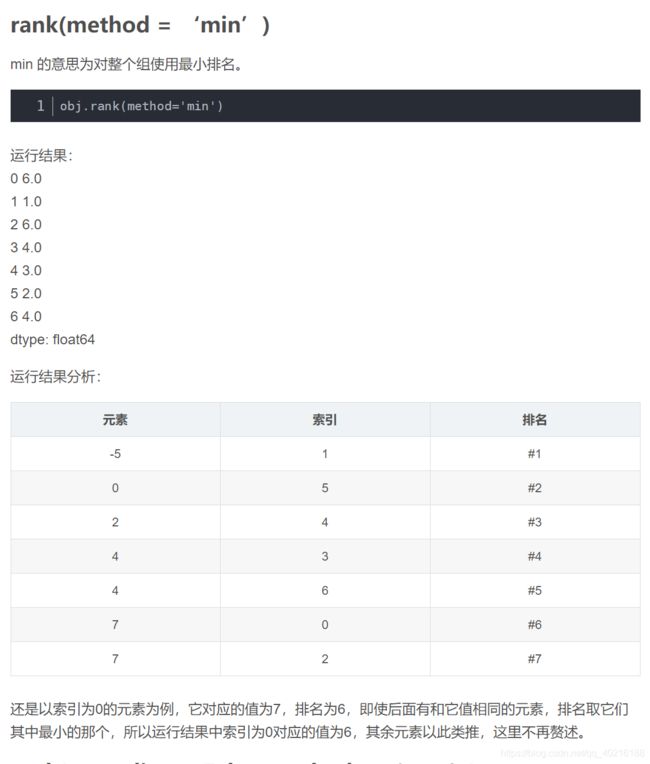
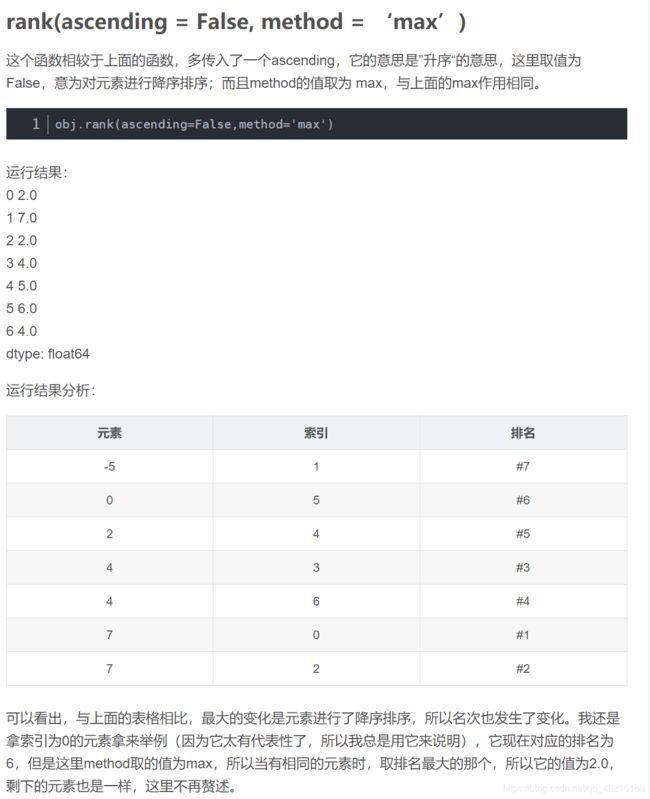



8. pandas set_option函数: 数据框展示设置
import pandas as pd
1)pd.set_option(‘expand_frame_repr’, False)
True就是可以换行显示。设置成False的时候不允许换行
2)pd.set_option(‘display.max_rows’, 10)
pd.set_option(‘display.max_columns’, 10)
显示的最大行数和列数。
3)pd.set_option(‘precision’, 5)
显示小数点后的位数
4)pd.set_option(‘large_repr’, A)
truncate表示截断,info表示查看信息,一般选truncate
5)pd.set_option(‘max_colwidth’, 100)
设置每一列的最大显示长度,默认为50个字符
6)pd.set_option(‘chop_threshold’, 0.5)
绝对值小于0.5的显示0.0
7)pd.set_option(‘colheader_justify’, ‘left’)
设置数据框中每列显示为居中还是居左
8)pd.set_option(‘display.width’, 200)
横向最多显示多少个字符,平时多用200,有时数据列数太多时,显示时会自动换行,可以将此值设置大一些,不进行换行展示
9. eval和ast.literal_val:字符串解析
如果要将字符串型的list,tuple,dict转变成原有的类型(作用就是把数据还原成它本身或者是能够转化成的数据类型),那么eval()和ast.literal_val()的区别是什么呢?
#string <==> list
str_list='[1,2,3,4]'
chg_list=eval(str_list) #输出[1,2,3,4]
#string <==> tuple
str_tuple='(1,2,3,4)'
chg_tuple=eval(str_tuple) #输出(1,2,3,4)
#string <==> dict
str_dict='{'name':'bob'}'
chg_dict=eval(str_dict) #输出{'name':'bob'}
从上面来看,eval功能可谓非常强大,即可以做string与list,tuple,dict之间的类型转换!更有甚者,可以对她能解析的字符串都做处理,而不顾忌可能带来的后果!所以说eval强大的背后,是巨大的安全隐患!!!
ast模块下的literal_eval()函数:则会判断需要计算的内容计算后是不是合法的python类型,如果是则进行运算,否则就不进行运算。

10. python中日期函数
strftime和strptime函数均来自包datetime
from datetime import *
10.1 strftime函数: datetime类—> string
语法:strftime(format)
将datetime包中的datetime类,按照输入参数的格式生成字符串变量
from datetime import *
currenttime=datetime.now() #生成当前时间的datetime类实例
print('type of currenttime', type(currenttime))
print(currenttime)
cur=currenttime.strftime('%Y_%m_%d-%H-%M-%S')
print('type of cur', type(cur))
print(cur)
输出:
type of currenttime
2019-08-29 14:01:39.973547
type of cur
2019_08_29-14-01-39
10.2 strptime函数: string—> datetime类
语法:strptime(date_string, format)
将字符串根据其格式,提取所含时间,并生成datetime类实例
from datetime import *
strdate='2019:08:29:09-00-00'
strdatetime=datetime.strptime(strdate,'%Y:%m:%d:%H-%M-%S')
print('type of strdatetime:',type(strdatetime),':',strdatetime)
输出:
type of strdatetime:
注意: strptime中的第二个参数是输入字符串的格式,而不是出参格式,datetime实例的格式是固定的
python中时间日期格式化符号:
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
10.3 日历函数
import calendar
print(calendar.month(2022,3))
#结果
"""
March 2022
Mo Tu We Th Fr Sa Su
1 2 3 4 5 6
7 8 9 10 11 12 13
14 15 16 17 18 19 20
21 22 23 24 25 26 27
28 29 30 31"""
print(help(calendar.month)) #打印函数的帮助
"""Help on method formatmonth in module calendar:
formatmonth(theyear, themonth, w=0, l=0) method of calendar.TextCalendar instance
Return a month's calendar string (multi-line).
None"""
11. transform函数
加载数据并查看数据
import pandas as pd
df = pd.read_excel("sales_transactions.xlsx")
df

数据包含了不同的订单(order),以及订单里的不同商品的数量(quantity)、单价(unit price)和总价(ext price)
现在我们的任务是为数据表添加一列,表示不同商品在所在订单的价钱占比。
首先我们要获得每个订单的总花费。groupby可以实现。
df.groupby('order')["ext price"].sum()
输出:
order
10001 576.12
10005 8185.49
10006 3724.49
Name: ext price, dtype: float64
过程如下图所示:
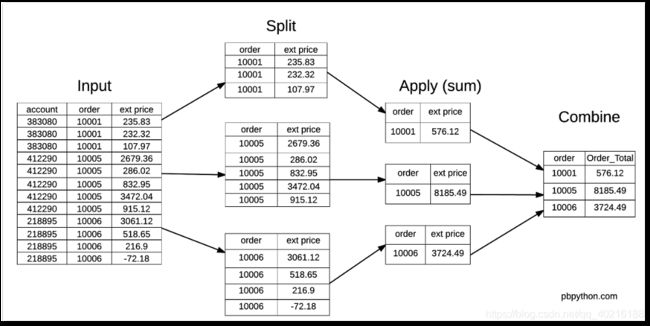
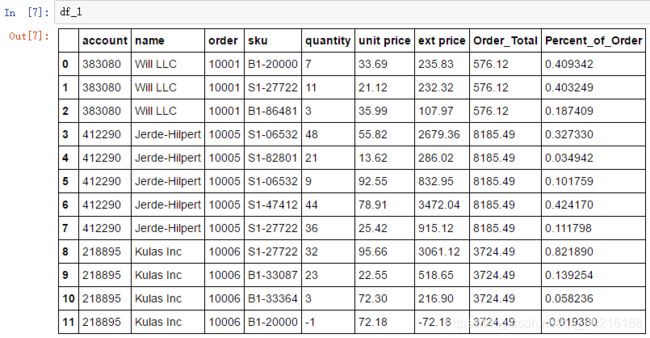
得到的新数据与df进行结合
order_total = df.groupby('order')["ext price"].sum().rename("Order_Total").reset_index()
df_1 = df.merge(order_total)
df_1["Percent_of_Order"] = df_1["ext price"] / df_1["Order_Total"]
目标实现了,但是步骤太多了,有没有简单的方式可以实现,transform上场
df.groupby('order')["ext price"].transform('sum')
输出:
0 576.12
1 576.12
2 576.12
3 8185.49
4 8185.49
5 8185.49
6 8185.49
7 8185.49
8 3724.49
9 3724.49
10 3724.49
11 3724.49
dtype: float64
不再是只显示3个订单的对应项,而是保持了与原始数据集相同数量的项目,这样就很好继续了。这就是transform的独特之处
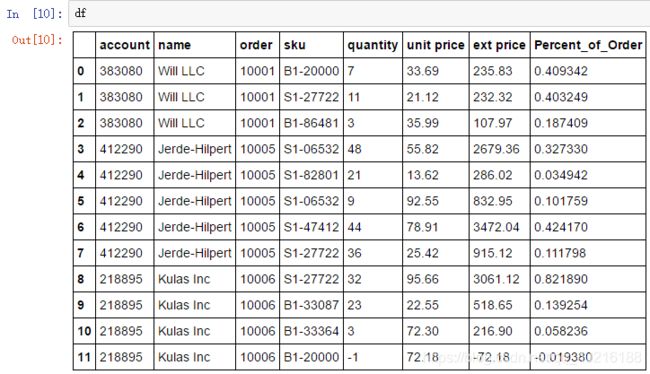
df["Order_Total"] = df.groupby('order')["ext price"].transform('sum')
df["Percent_of_Order"] = df["ext price"] / df["Order_Total"]
#可以一步实现
df["Percent_of_Order"] = df["ext price"] / df.groupby('order')["ext price"].transform('sum')
接下来介绍transform函数的主要 功能:
1)转换数值
语法:pd.transform(func, axis=0)
参数含义如下:
func是指定用于处理数据的函数,它可以是普通函数、字符串函数名称、函数列表或轴标签映射函数的字典。
axis是指要应用到哪个轴,0代表列,1代表行。
a)普通函数
df = pd.DataFrame({'A': [1,2,3], 'B': [10,20,30] })
def plus_10(x):
return x+10
df.transform(plus_10)
#df.transform(lambda x: x+10) #或者直接采用lambda函数即可

b)字符串函数
也可以传递任何有效的pandas内置的字符串函数,例如sqrt:
df.transform('sqrt')

c)函数列表
func还可以是一个函数的列表。例如numpy的sqrt和exp函数的列表组合:
df.transform([np.sqrt, np.exp])
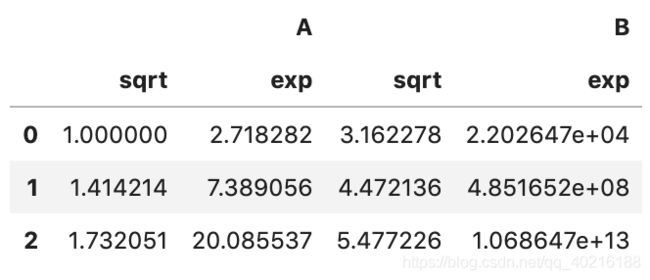
通过上面结果看到,两个函数分别作用于A和B每个列
d)轴标签映射函数的字典
如果我们只想将指定函数作用于某一列,该如何操作?
func还可以是轴标签映射指定函数的字典。例如:
df.transform({
'A': np.sqrt,
'B': np.exp,
})
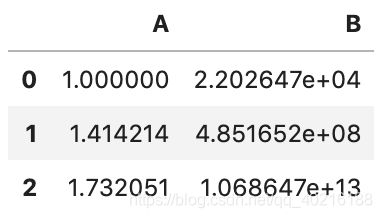
这样,就可以对A和BL两列分别使用相应函数了,互补干扰。
2)合并分组结果
df = pd.DataFrame({
'restaurant_id': [101,102,103,104,105,106,107],
'address': ['A','B','C','D', 'E', 'F', 'G'],
'city': ['London','London','London','Oxford','Oxford', 'Durham', 'Durham'],
'sales': [10,500,48,12,21,22,14]
})
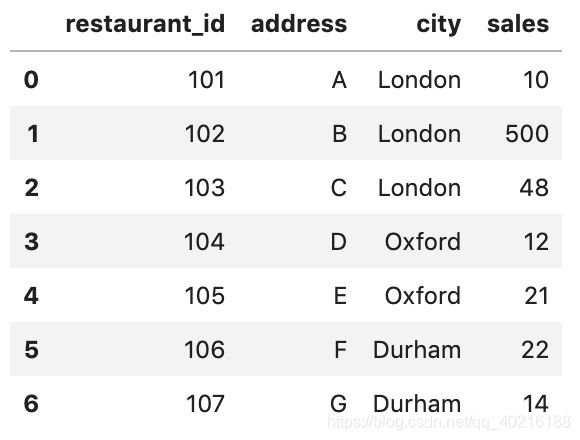
我们可以看到,每个城市都有多家销售餐厅。我们现在想知道每家餐厅在城市中所占的销售百分比是多少。 预期输出为:
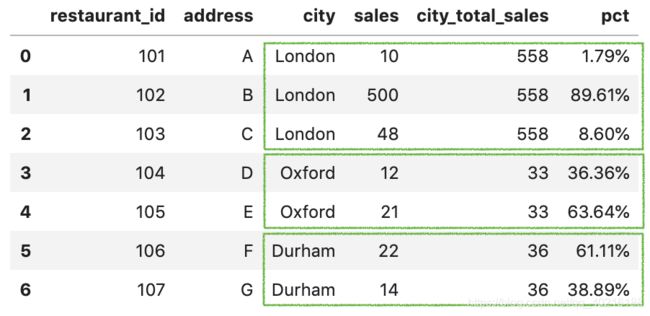
df['city_total_sales'] = df.groupby('city')['sales'].transform('sum')
transform直接在原表上增加一列数据
df['pct'] = df['sales'] / df['city_total_sales']
df['pct'] = df['pct'].apply(lambda x: format(x, '.2%'))
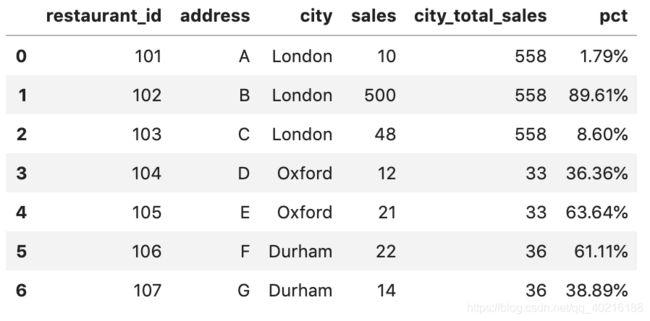
3)过滤数据
transform也可以用来过滤数据。仍用上个例子,我们希望获得城市总销售额超过40的记录,那么就可以这样使用。
df[df.groupby('city')['sales'].transform('sum') > 40]

上面结果来看,并没有生成新的列,而是通过汇总计算求和直接对原表进行了筛选,非常优雅。
4)结合分组处理缺失值
df = pd.DataFrame({
'name': ['A', 'A', 'B', 'B', 'B', 'C', 'C', 'C'],
'value': [1, np.nan, np.nan, 2, 8, 2, np.nan, 3]
})
在上面的示例中,数据可以按name分为三组A、B、C,每组都有缺失值。我们知道替换缺失值的常见的方法是用mean替换NaN。下面是每个组中的平均值。
df.groupby('name')['value'].mean()
#输出为:
name
A 1.0
B 5.0
C 2.5
Name: value, dtype: float64
我们可以通过transform()使用每组平均值来替换缺失值。用法如下:
df['value'] = df.groupby('name') .transform(lambda x: x.fillna(x.mean()))

12. 缺失值处理
12.1 缺失值定位
#查看数据中列的缺失值
np.isnan(data).any()
#结果
MONTH False
DAY False
DAY_OF_WEEK False
AIRLINE False
FLIGHT_NUMBER False
DESTINATION_AIRPORT False
ORIGIN_AIRPORT False
AIR_TIME True
DEPARTURE_TIME True
DISTANCE False
dtype: bool
12.2 缺失值删除
data.dropna(inplace=True)
12.3 缺失值填充
- 固定值填充
#都填90
df['taixin'] = df['taixin'].fillna('90')
- 均值填充
#一定要保证数据是int或float类型
df['taixin'] = df['taixin'].fillna(df['taixin'].mean())
- 众数填充
#一定要保证数据是int或float类型
df['taixin'] = df['taixin'].fillna(df['taixin'].mode())
- 上下数据填充
#用前一个非缺失值填充
df['taixin'] = df['taixin'].fillna(method='pad')
#用后一个非缺失值填充
df['taixin'] = df['taixin'].fillna(method='bfill')
- 插值法填充
#前后非缺失值的均值填充
df['taixin'] = df['taixin'].interpolate()
- KNN进行填充
from sklearn.impute import KNNImputer
imputer = KNNImputer(n_neighbors=3)
imputed = imputer.fit_transform(df)
df_imputed = pd.DataFrame(imputed, columns=df.columns)
优化K值进行聚类填充缺失值
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
rmse = lambda y, yhat: np.sqrt(mean_squared_error(y, yhat))
迭代K的可能范围-1到20之间的所有奇数都可以:
- 使用当前的K值执行插补
- 将数据集分为训练和测试子集
- 拟合随机森林模型
- 预测测试集
- 使用RMSE进行评估
def optimize_k(data, target):
errors = []
for k in range(1, 20, 2):
imputer = KNNImputer(n_neighbors=k)
imputed = imputer.fit_transform(data)
df_imputed = pd.DataFrame(imputed, columns=df.columns)
X = df_imputed.drop(target, axis=1)
y = df_imputed[target] #y为预测值
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestRegressor()
model.fit(X_train, y_train)
preds = model.predict(X_test)
error = rmse(y_test, preds)
errors.append({'K': k, 'RMSE': error})
return errors
k_errors = optimize_k(data=df, target='MEDV')
k_errors

看起来K = 15是给定范围内的最佳值,因为它导致最小的误差。
13. logging:日志处理
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%a, %d %b %Y %H:%M:%S',
filename='myapp.log',
filemode='w')
logging.debug('This is debug message')
logging.info('This is info message')
logging.warning('This is warning message')
#参数
logging.basicConfig函数各参数:定义日志输出格式
filename: 指定日志文件名
filemode: 和file函数意义相同,指定日志文件的打开模式,'w'或'a'
format: 指定输出的格式和内容,format可以输出很多有用信息,如上例所示:
%(levelno)s: 打印日志级别的数值
%(levelname)s: 打印日志级别名称
%(pathname)s: 打印当前执行程序的路径,其实就是sys.argv[0]
%(filename)s: 打印当前执行程序名
%(funcName)s: 打印日志的当前函数
%(lineno)d: 打印日志的当前行号
%(asctime)s: 打印日志的时间
%(thread)d: 打印线程ID
%(threadName)s: 打印线程名称
%(process)d: 打印进程ID
%(message)s: 打印日志信息
datefmt: 指定时间格式,同time.strftime()
level: 设置日志级别,默认为logging.WARNING
stream: 指定将日志的输出流,可以指定输出到sys.stderr,sys.stdout或者文件,默认输出到sys.stderr,当stream和filename同时指定时,stream被忽略
import jieba
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
# asctime:时间、levelname:日志级别名称、message:日志信息、logging.INFO:日志级别
sentences = [
'2018年10月份,麻省理工学院的Zakaria el Hjouji, D. Scott Hunter等学者发表了《The Impact of Bots on Opinions in Social Networks》,',
'该研究通过分析 Twitter 上的机器人在舆论事件中的表现,证实了社交网络机器人可以对社交网络舆论产生很大的影响,不到消费者总数1%的活跃机器人,就可能左右整个舆论风向。',
'通过社会化媒体挖掘,我们可以得到对目标受众具有(潜在)影响力的商业情报。淘沙得金,排沙简金,最终得到的分析结果用以预判受众的思考和行为,为我们的生产实践服务。'
]
data_cut = [jieba.lcut(i) for i in sentences] #对语句进行分词
data_cut = [' '.join(jieba.lcut(i)) for i in sentences] #用空格隔开词汇,形成字符串,便于后续的处理
stoplist = [i.strip() for i in open('datasets/stopwords.txt',encoding='utf-8').readlines()] #载入停用词列表
sentences = [[word for word in document.strip().split() if word not in stoplist] for document in data_cut] #过滤语句中的停用词
输出的日志如下所示:

参考:https://www.cnblogs.com/yyds/p/6901864.html
https://blog.csdn.net/fengleieee/article/details/54862877
14. 数据框合并:merge、concat、join、append函数
14.1 merge函数
pd.merge(left, # 待合并的2个数据框
right,
how='inner', # ‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’
on=None, # 连接的键,默认是相同的键
left_on=None, # 指定不同的连接字段:键不同,但是键的取值有相同的内容
right_on=None,
left_index=False, # 根据索引来连接
right_index=False,
sort=False, # 是否排序
suffixes=('_x', '_y'), # 改变后缀
copy=True,
indicator=False, # 显示字段来源
validate=None)
- 参数解释:
1)left、right:待合并的数据帧
2)how:合并的方式,有5种:{‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, 默认是 ‘inner’
1、 left:左连接,保留left的全部数据;right类似;类比于SQL的left join 或者right join
2、outer:全连接功能,类似SQL的full outer join
3、inner:交叉连接,类比于SQL的inner join
4、cross:创建两个数据帧DataFrame的笛卡尔积,默认保留左边的顺序
3)on:连接的列属性;默认是两个DataFrame的相同字段
4)left_on/right_on:指定两个不同的键进行联结
5)left_index、right_index:通过索引进行合并
6)suffixes:指定我们自己想要的后缀
7)indictor:显示字段的来源
import pandas as pd
df1=pd.DataFrame({"userid":list("abcd"),
"age":[20,27,23,18]})
df2=pd.DataFrame({"userid":list("aca"),
"score":[600,634,621]})
df3=pd.DataFrame({"userid":list("ae"),
"score":[600,621]})
df4=pd.DataFrame({"userid1":list("ac"),
"score":[630,616]})
- 参数how
pd.merge(df1,df2) #默认按照两个数据框相同的字段连接
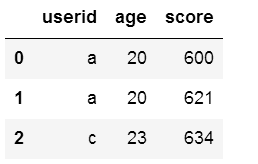
df1.merge(df2) #效果同上
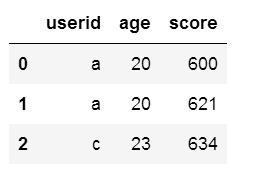
- 参数left、right
pd.merge(df1,df2,how='inner') #默认
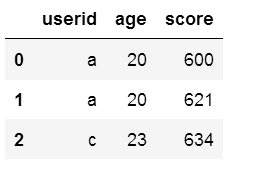
pd.merge(df1,df3,how='outer') #外连接,如果某个键在某个数据框中不存在数据,则为NaN

pd.merge(df1,df3,how='left') #左连接,以左边数据框中的键为基准;如果左边存在但是右边不存在,则右边用NaN表示

pd.merge(df1,df3,how='right') #右连接,以右边数据框中的键的取值为基准;如果右边存在但是左边不存在,则左边用NaN表示

- 参数on
pd.merge(df1,df2) #默认
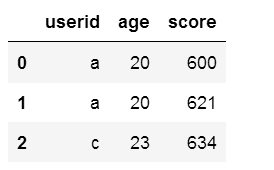
pd.merge(df1,df2, on='userid') #相同的字段作为键,on的值
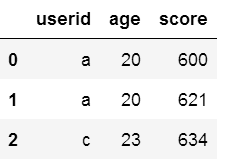
df5=pd.DataFrame({"key1":["K0", "K0", "K1", "K2"],
"key2":["K0", "K1", "K0", "K1"],
"A":["A0", "A1", "A2", "A3"],
"B":["B0", "B1", "B2", "B3"]})
df6=pd.DataFrame({"key1":["K0", "K1", "K1", "K2"],
"key2":["K0", "K0", "K0", "K0"],
"C":["C0", "C1", "C2", "C3"],
"D":["D0", "D1", "D2", "D3"]})
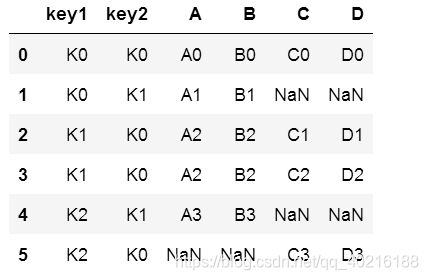
pd.merge(df5,df6,on=['key1', 'key2'])
#通过on参数指定两个连接的字段key1、key2
#只有当两个数据框中的key1和key2的取值完全相同的时候(交集),才会保留下来;

pd.merge(df5,df6,how='outer', on=['key1', 'key2'])
#指定连接的两个键key1、key2
#使用how="outer",会保留两个数据框中的全部数据。某个数据框中不存在键的值,则取NaN
- 参数left_on、right_on
pd.merge(df1,df4,left_on='userid',right_on='userid1')

- 参数suffixes
df7=pd.DataFrame({"userid":list("abcd"),
"age":[20,27,23,18]})
df8=pd.DataFrame({"userid":list("ac"),
"age":[20,27],
"score":[600,621]})
#如果连接之后结果有相同的字段出现,默认后缀是_x_、_y。这个参数就是改变我们默认的后缀
pd.merge(df7,df8, on='userid', suffixes=['_left','_right'])

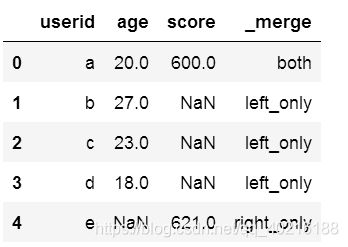
- indicator
#这个参数的作用是表明生成的一条记录是来自哪个DataFrame:both、left_only、right_only
#如果带上次参数会显示一个新字段_merge
#不带上参数的话,默认是不会显示来源的
pd.merge(df1,df3,how='outer',indicator=True)
14.2 concat函数
pandas.concat(objs, # 合并对象
axis=0, # 合并方向,默认是0纵轴方向
join='outer', # 合并取的是交集inner还是并集outer
ignore_index=False, # 合并之后索引是否重新
keys=None, # 在行索引的方向上带上原来数据的名字;主要是用于层次化索引,可以是任意的列表或者数组、元组数据或者列表数组
levels=None, # 指定用作层次化索引各级别上的索引,如果是设置了keys
names=None, # 行索引的名字,列表形式
verify_integrity=False, # 检查行索引是否重复;有则报错
sort=False, # 对非连接的轴进行排序
copy=True # 是否进行深拷贝
)
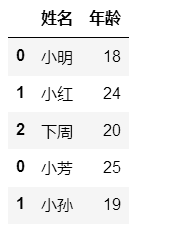
- 默认
import pandas as pd
df1=pd.DataFrame({"姓名":["小明","小红","下周"],"年龄":[18,24,20]})
df2=pd.DataFrame({"姓名":["小芳","小孙"],"年龄":[25,19]})
df3=pd.DataFrame({"地址":["深圳","广州","珠海"],"成绩":[600,630,598]})
df4=pd.DataFrame({"地址":["深圳","广州","东莞"],"爱好":["乒乓球","羽毛球","高尔夫"]})
df5=pd.DataFrame({"地址":["深圳","广州","东莞","上海","北京"],
"爱好":["乒乓球","羽毛球","高尔夫","跑步","健身"]})
pd.concat([df1,df2]) #默认使用原索引
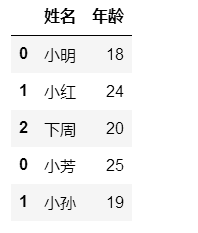
- 参数axis
pd.concat([df1,df2], axis=0) #默认,axis=0
pd.concat([df1,df2], axis=1) #列上合并,某个数据库中不存在的数据,用NaN代替

pd.concat([df1,df3], axis=1) #列上合并

- 参数ignore_index
#是否保留原表索引,默认保留,为 True 会自动增加自然索引。
pd.concat([df1,df2]) #默认
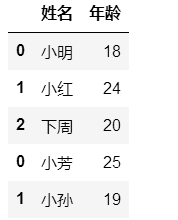
pd.concat([df1,df2],ignore_index=True)

- 参数join
#指定取得交集inner还是并集outer,默认是并集outer
pd.concat([df3,df4], join='outer')
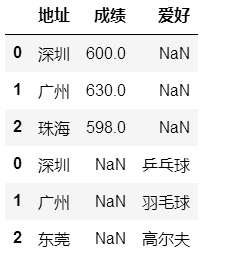
#df3和df4只有地址这个字段是相同的,所以保留了它,其他的舍弃
pd.concat([df3,df4], join='inner')

- 参数keys
pd.concat([df1,df2],keys=['df1','df2'])

pd.concat([df1,df2]) #默认

#当我们设置了索引重排(ignore_index=True),keys参数就无效啦
pd.concat([df1,df2],keys=['df1','df2'],ignore_index=True)

- 参数name
df6=pd.concat([df1,df2],keys=['df1','df2'],names=['D1','D2'])
df6
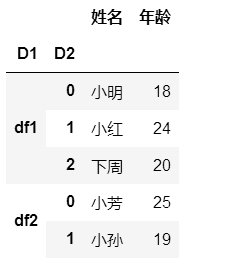
#我们可以检查下df6的索引,发现是层级索引:
df6.index

- 合并多个DataFrame
pd.concat([pd.concat([df1,df2],axis=0,ignore_index=True),df5],axis=1)

14.3 join函数
dataframe.join(other, # 待合并的另一个数据框
on=None, # 连接的键
how='left', # 连接方式:‘left’, ‘right’, ‘outer’, ‘inner’ 默认是left
lsuffix='', # 左边(第一个)数据框相同键的后缀
rsuffix='', # 第二个数据框的键的后缀
sort=False) # 是否根据连接的键进行排序;默认False
- 参数lsuffix、rsuffix–不指定,会报错
#添加指定的后缀
df10.join(df11,lsuffix='_left',rsuffix='_right')


- 参数how:how参数默认是left,保留左边的全部字段。右边不存在的数据用NaN
#how参数默认是left,保留左边的全部字段。右边不存在的数据用NaN
df10.join(df11,lsuffix='_left',rsuffix='_right')

#改成right之后,保留右边的全部数据:
df10.join(df11,how='right', lsuffix='_left',rsuffix='_right')
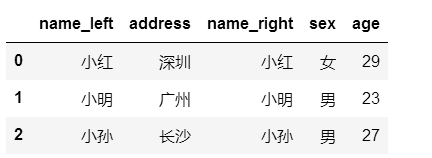
#在上述合并中,相同字段name被分成name_left和name_right,如何进行字段的合并呢?
'''
先把键当做行索引
通过join合并
通过reset_index()重新设置索引
'''
#1、先把键当做行索引
df10.set_index("name")
df11.set_index("name")
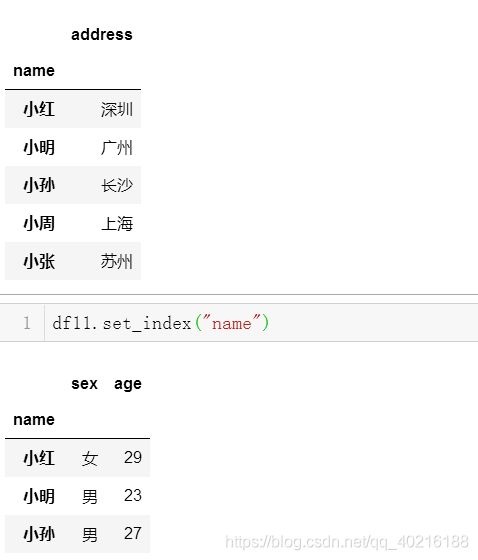
#2、通过join合并
df10.set_index("name").join(df11.set_index("name"))
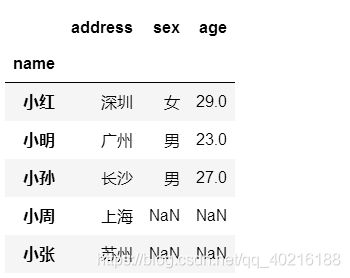
#3、通过reset_index()重新设置索引
df10.set_index("name").join(df11.set_index("name")).reset_index()
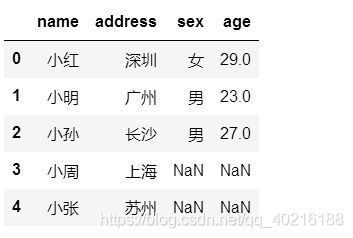
#更为简单的方法
df10.join(df11.set_index("name"),on='name')
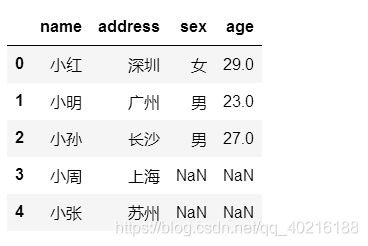
- 合并多个dataframe
df10.set_index("name").join([df11.set_index("name"),
df12.set_index("name")]).reset_index()
#如果我们想要用merge函数来实现呢?
#使用how="outer",保留全部字段的数据信息
pd.merge(pd.merge(df10,df11,how='outer'),df12,how='outer')

14.4 append函数
- 字面意思是“追加”。向dataframe对象中添加新的行,如果添加的列名不在dataframe对象中,将会被当作新的列进行添加。
DataFrame.append(other,
ignore_index=False,
verify_integrity=False,
sort=False)
- 参数解释
1)other:待合并的数据。可以是pandas中的DataFrame、series,或者是Python中的字典、列表这样的数据结构
2)ignore_index:是否忽略原来的索引,生成新的自然数索引
3)verify_integrity:默认是False,如果值为True,创建相同的index则会抛出异常的错误
4)sort:boolean,默认是None。如果self和other的列没有对齐,则对列进行排序,并且属性只在版本0.23.0中出现。
df12=pd.DataFrame([[601,592],[23,24]],columns=['小明','小红'])
df13=pd.DataFrame([['男','女'],['深圳','广州']],columns=['小明','小红'])
- 添加不同类型数据
#python字典
dic={'小明':'乒乓球','小红':'排球'}
df12.append(dic,ignore_index=True)

#Series类型
s=pd.Series(dic)
df12.append(s,ignore_index=True)
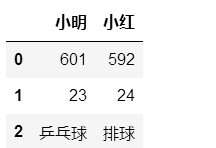
#DataFrame类型
d=pd.DataFrame(dic,index=[0])
df12.append(d,ignore_index=True)

- 默认合并
df12.append(df13)

- 参数ignore_index
df12.append(df13,ignore_index=True)

- 参数verify_integrity
#默认是False,如果值为True,创建相同的index则会抛出异常的错误
df12.append(df13,verify_integrity=False,ignore_index=True)
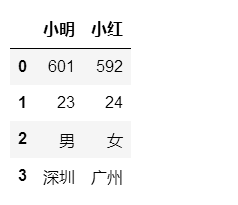
- 如果添加的列名不在dataframe对象中,将会被当作新的列进行添加。
df14=pd.DataFrame([[601,592],[23,24]],columns=['小明','小红'])
df15=pd.DataFrame([['男','女','男'],['深圳','广州','珠海']],columns=['小明','小红','小李'])
df14.append(df15)

14.5 实战案例
假设现在一个excel表中有3个sheet:订单表、订单商品表、商品信息表。
1、订单表
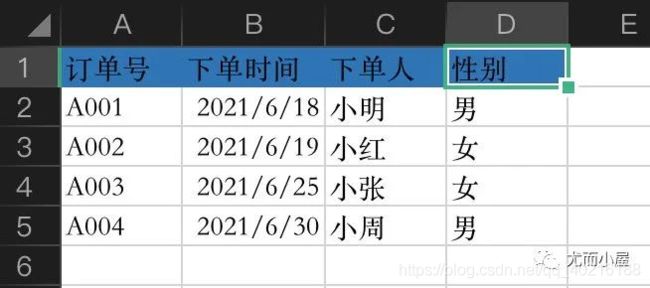
2、订单商品表
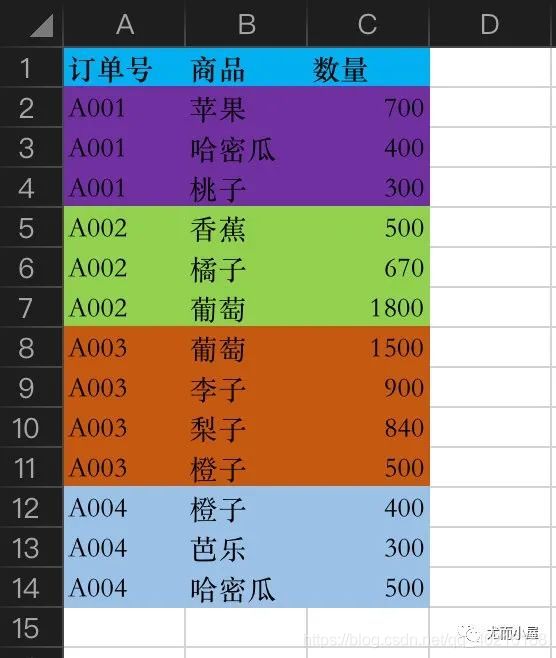
3、商品信息表
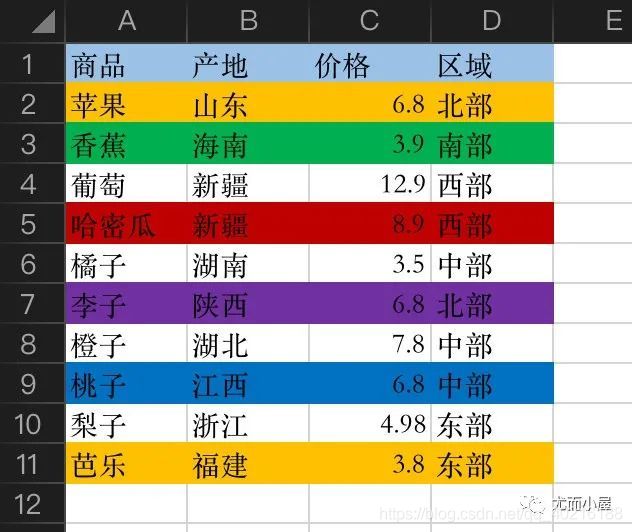
import pandas as pd
import numpy as np
# 读取订单表中的内容
df1 = pd.read_excel("水果订单商品信息3个表.xlsx",sheet_name=0) # 第一个sheet的内容,索引从0开始
# 读取订单商品表
df2 = pd.read_excel("水果订单商品信息3个表.xlsx",sheet_name=1)
# 商品信息表
df3 = pd.read_excel("水果订单商品信息3个表.xlsx",sheet_name="商品信息")
#订单表和订单商品表的合并
df4=pd.merge(df1,df2,how='outer')
df4

#将上面的结果和商品信息表合并
df5=pd.merge(df4,df3,how='outer')
df5
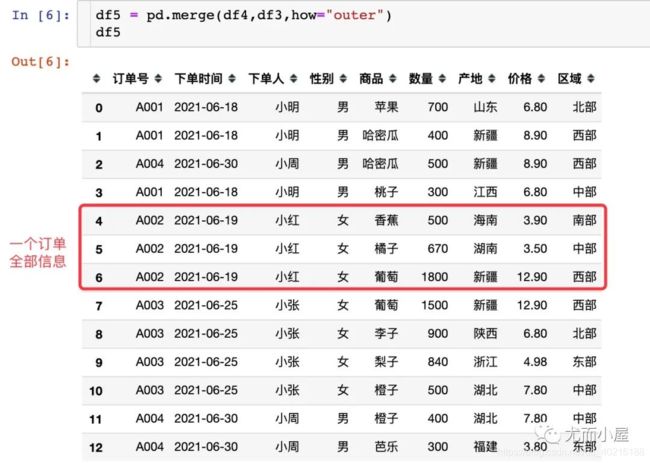
#不同水果的销量和订单数:根据水果进行分组统计数量和订单数
df5.groupby('商品').agg({'数量':'sum', '订单号':'nunique'}).reset_index()

#不同区域的水果销售额和客户数
df5.groupby('区域').agg({'销售额':'sum', '下单人':'nunique'}).reset_index()

15. squeeze函数-压缩
pandas.DataFrame.squeeze(axis=None)
- 具有单个元素的Series或DataFrame被压缩为标量。
- 具有单列或单行的DataFrame被压缩为Series。
- 否则,对象不变。
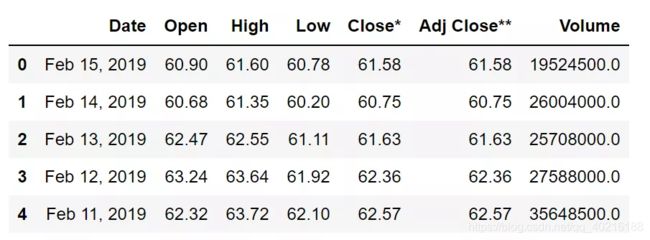
volume_highest=df[df['Volume']>100000000]['Volume']
type(volume_highest)
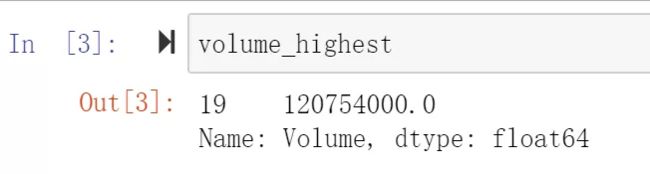

此时,volume_highest虽然只有一个值,但数据类型是Series,我们想要取出其中的一个值
volume_highest_scalar = volume_highest.squeeze()

16.break和continue语句
16.1 break
- break函数是当满足break的执行条件时,直接跳出循环结构;
#打印小于11的自然数
n = 1
while n <= 100:
if n > 10: # 当n = 11时,条件满足,执行break语句
break # break语句会结束循环,直接跳出循环结构
print(n)
n = n + 1
print('END')
#结果
1
2
3
4
5
6
7
8
9
10
END
16.2 continue
- continue语句当执行条件符合时,直接跳出本次循环,执行下一次循环;
#打印1-10之间的奇数
n = 0
while n < 10:
n = n + 1
if n % 2 == 0: # 如果n是偶数(对2取余数为0),执行continue语句
continue # continue语句会直接继续下一轮循环,后续的print()语句不会执行
print(n)
#结果
1
3
5
7
9
17.定义函数之可变参数(*args和**kwargs)
17.1 可变参数
- 给定一组数字 a , b , c , . . . a,b,c,... a,b,c,...计算 a 2 + b 2 + c 2 + . . . . . . a^2+b^2+c^2+...... a2+b2+c2+......,由于数字的个数不确定,采用可变参数函数来实现;
def cal(*nums):
res=0
for i in nums:
res+= i**2
return res
cal()
#结果
0
cal(1,2,3)
#结果
14
- 仅仅在参数前面加了一个*号。在函数内部,参数nums接收到的是一个tuple。
- 调用该函数时,可以传入任意个参数,包括0个参数。
- 如果已经有一个list或者tuple,调用函数时在list或者tuple前加*。
num=[1,2,3,4]
cal(*num)
#结果
30
num=(1,2,3,4)
cal(*num)
#结果
30
def add_num(a,*args):
for i in args:
a+=i
retunrn a
add_num(1,2,3)
#结果
6
17.2 可变关键字参数
- 可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
person('Michael', 30)
#结果
name: Michael age: 30 other: {}
person('Bob', 35, city='Beijing')
#结果
name: Bob age: 35 other: {'city': 'Beijing'}
person('Adam', 45, gender='M', job='Engineer')
name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}
def add_nums(a,**kwargs):
for arg,value in kwargs.items():
print(arg,value)
add_nums(1,x=2,y=3)
#结果
6
18.jupyter notebook中生成.py文件
- 生成.py文件:
%%writefile xxx.py
%%writefile test.py ##test.py为文件名
val=10
def func(lst):
res=0
for i in range(len(lst)):
res+=lst[i]
return res
lst=[1,2,3,4,5]
print(func(lst))
#执行结束,会显示Overwriting test.py,并在当前目录可以查看到test.py文件已经存在。
- 调用:
%run xxx.py
%run test.py
#结果
15
#导入保存好的test.py文件
import test
#查看test的路径
test
#结果:#导入模块并命名为别名
import test as ts
ts.val
#结果
100
ts.func(list1)
#结果
33
#精准导入模块中的参数和函数
from test import val,func
val
#结果
100
func(list1)
#结果
33
#批量导入模块中的参数和函数
from test import *
val
#结果
100
#func(list)
#结果
33
19. 查看当前工作目录及删除文件:os模块
import os
os.path.abspath('.')
#结果
'C:\\Users\\PG_01\\Desktop\\Liuxin_pytorch'
#删除文件
os.remove('test.py')
20. 异常
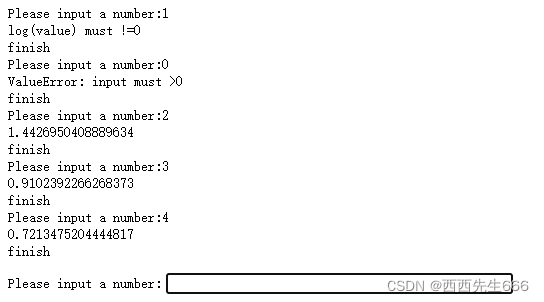
20.1 捕捉异常-try except finally
- try和except选择一个执行,但finally一定会执行;
import math
for i in range(10):
try:
input_number=input('Please input a number:')
if input_number=='q':
break #跳出循环
result=1/math.log(float(input_number))
print(result)
except ValueError:
print('ValueError: input must >0')
except ZeroDivisionError:
print('log(value) must !=0')
except Exception: #对于其他错误的提示信息
print('unkown error')
finally:
print('finish')
21.类
21.1类的定义
class People:
'帮助信息:XXXXXX'
#公有参数
number=100
#初始化函数,当创建一个类时,首先会被调用
def __init__(self, name, age):
self.name=name
self.age=age
def display(self):
print('number=',self.number)
def display_name(self):
print(self.name)
#查询类的帮助文档
People.__doc__
#类的初始化
p1=People('Ella',30)
p1.display()
#结果
number= 100
#查询类的属性和函数
p1.name
#结果
'Ella'
#调用类的函数
p1.display_name()
#结果
Ella
#类中属性重新赋值
p1.name='python'
p1.name
#结果
'python'
#删除类的属性
del p1.name
p1.name #删除后会报错
#结果
"""
AttributeError Traceback (most recent call last)
in
----> 1 p1.name
AttributeError: 'People' object has no attribute 'name'
"""
#检查类是否包含某个属性
hasattr(p1,'age')
#结果
True
hasattr(p1,'sex')
#结果
False
#获取类的属性值
getattr(p1,'name')
#结果
'python'
#设置类的属性值
setattr(p1,'name','bob')
getattr(p1,'name')
#结果
'bob'
#删除类的属性值
delattr(p1,'name')
getattr(p1,'name')
#结果
"""
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
in
1 delattr(p1,'name')
----> 2 getattr(p1,'name')
AttributeError: 'People' object has no attribute 'name'
"""
print(People.__doc__) #打印类的帮助文档
print(People.__name__)#打印类的名称
print(People.__module__)#打印类的模块名
print(People.__bases__)#打印类的父类
print(People.__dict__)#打印类的结构
"""
帮助信息:XXXXXX
People
__main__
(,)
{'__module__': '__main__', '__doc__': '帮助信息:XXXXXX', 'number': 100, '__init__': , 'display': , 'display_name': , '__dict__': , '__weakref__': }"""
21.2 类的继承
class Parent:#定义父类
number=100
def __init__(self):
print('调用父类的初始化函数')
def paerntMethod(self):
print('调用父类函数')
def setAttr(self,attr):
self.parentAttr=attr
def getAttr(self):
print('父类属性:',self.parentAttr)
def newMethod(self):
print('父类要被重写的函数')
class Child(Parent): #定义子类,继承父类
def __init__(self):
print('调用子类的初始化函数')
def childMethod(self):
print('调用子类函数')
def newMethod(self): #重写父类中的函数,函数名一致,可重新定义执行内容
print('子类给改掉了')
c=Child()
c.childMethod()
c.paerntMethod()
c.setAttr(1000)
c.getAttr()
c.newMethod()
#结果
"""调用子类的初始化函数
调用子类函数
调用父类函数
父类属性: 1000
子类给改掉了"""
22. 文件及文件夹遍历(os.walk函数)
- os.walk(path)返回三组数据,root目录路径、dirs文件夹、files文件
- 要读取路径中以’credit’开头和以’reference.png’结尾的图像,并保存到字典中。

def cv_show(name,img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
import os
args = dict() #图像和模板参数的字典
args['image'] = dict()
for root, dirs, files in os.walk(r'./images'): #返回3个参数,一次是根目录root、当前目录下的目录dirs、当前目录下的文件files
for i, name in enumerate(files):
if name.startswith('credit'): #文件名以'credit'开头
img_path=os.path.join(root, name)
args['image'][i] = cv2.imread(img_path)
args['image'][i]
cv_show('name', args['image'][i])
elif name.endswith('reference.png'):#模板名以'reference.png'开头
tmp_path = os.path.join(root, name)
args['tmp'] = cv2.imread(tmp_path) #模板
cv_show('name', args['tmp'])






23. 文件目录处理模块-os和shutil
23.1 os模块
23.1.1 os操作
import os
#打开记事本功能
os.system('notepad.exe')
#打开计算器
os.system('calc.exe')
#直接调用可执行文件
os.startfile('F:\\CloudMusic\\cloudmusic.exe')
#返回当前的目录路径
print(os.getcwd())
#返回指定路径下的所有目录和文件
print(os.listdir('../pythonProject'))
#创建目录
os.mkdir('newdir2')
#创建多级目录
os.makedirs('A/B/C')
#删除目录
os.rmdir('newdir2')
#删除多级目录
os.removedirs('A/B/C')
#删除文件,输入参数必须为文件名
os.remove('a.txt')
#改变当前的工作路径为F://pythonProject
os.chdir('F://pythonProject')
23.1.2 os.path操作
import os.path
#获取文件的绝对路径
print(os.path.abspath('first.py'))
#判断文件或目录是否存在,存在返回True,否则返回False
print(os.path.exists('Linux'),os.path.exists('four.py'))
#将目录与目录或目录和文件名连接起来
print(os.path.join('F:\\pythonProject','three.py'))
#将目录和文件名分割开来
print(os.path.split('F:\\pythonProject\\first.py'))
#从一个目录中提取文件名
print(os.path.basename('F:\\pythonProject\\first.py'))
#获取路径下的目录
print(os.path.dirname('F:\\pythonProject\\first.py'))
#判断是否为目录
print(os.path.isdir('F:\\pythonProject'))
#判断是否为文件
print(os.path.isdir('F:\\pythonProject\\first.py'))
23.2 shutil模块
- shutil是 篇python中的高级文件操作模块,与os模块形成互补的关系,os主要提供了文件或文件夹的新建、删除、查看等方法,还提供了对文件以及目录的路径操作。shutil模块提供了移动、复制、 压缩、解压等操作,恰好与os互补。
- copy()函数:复制文件
"""
语法:shutil.copy(fsrc,path),返回值:返回复制之后的路径
fsrc:源文件
path:目标地址
"""
import shutil
shutil.copy('test.csv','C:/Users/Desktop/')
#结果
'C:/Users/Desktop/test.csv'
- copyfileobj()函数:将一个文件内容拷贝到另一个文件中,如果目标文件本身就有内容,来源文件的内容会把目标文件的内容覆盖掉。如果目标文件不存在它会自动创建一个
"""
语法:shutil.copyfileobj(fsrc, fdst[, length=16*1024])
fsrc:源文件
fdst:复制到fdst文件
length:缓冲区大小,即fsrc每次读取的长度
"""
f1 = open('file.txt','r')
f2 = open('file_copy.txt','w+')
shutil.copyfileobj(f1,f2,length=16*1024)
- copyfile()函数:将一个文件的内容拷贝到另一个文件中,目标文件无需存在
"""
语法:shutil.copyfile(src, dst,follow_symlinks)
src:源文件路径
dst:复制至dst文件,若dst文件不存在,将会生成一个dst文件;若存在将会被覆盖
follow_symlinks:设置为True时,若src为软连接,则当成文件复制;如果设置为False,复制软连接。默认为True。
"""
- copytree()函数:复制整个目录文件,不需要的文件类型可以不复制
"""
语法:shutil.copytree(oripath, despath, ignore= shutil.ignore_patterns("*.xls", "*.doc"))
oripath : "来源路径"
despath : "目标路径"
ignore : shutil.ignore_patterns() 是对内容进行忽略筛选,将对应的内容进行忽略。
"""
- copymode()函数:拷贝权限,前提是目标文件存在,不然会报错。将src文件权限复制至dst文件。文件内容,所有者和组不受影响
"""
语法:shutil.copymode(src,dst)
src:源文件路径
dst:将权限复制至dst文件,dst路径必须是真实的路径,并且文件必须存在,否则将会报文件找不到错误
follow_symlinks:设置为False时,src, dst皆为软连接,可以复制软连接权限,如果设置为True,则当成普通文件复制权限。默认为True。Python3新增参数
"""
- move()函数:移动文件或文件夹
语法:shutil.move(src, dst)
- disk_usage():查看磁盘使用信息,计算磁盘总存储,已用存储,剩余存储信息。
"""
语法:shutil.disk_usage('盘符')
返回值:元组
"""
shutil.disk_usage('D:')
#结果
usage(total=151199412224, used=41293144064, free=109906268160)
total总存储:151199412224/1024/1024/1024=140GB
used已使用:41293144064/1024/1024/1024=38GB
free剩余容量:109906268160/1024/1024/1024=102GB
- make_archive()函数:压缩打包
"""
语法:make_archive(base_name, format, root_dir=None, base_dir=None, verbose=0,dry_run=0, owner=None, group=None, logger=None)
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径
format: 压缩或者打包格式 "zip", "tar", "bztar", "gztar"
root_dir : 将哪个目录或者文件打包(也就是源文件)
"""
#把当前目录下的file_1.csv打包压缩
shutil.make_archive('file_1.csv','gztar',root_dir='C:/Users/wuzhengxiang/Desktop/股票数据分析')
#结果
'C:\\Users\\wuzhengxiang\\Desktop\\股票数据分析\\file_1.csv.tar.gz'
- rmtree()函数:递归删除文件
"""
shutil.rmtree(path[, ignore_errors[, onerror]])
"""
#删除文件夹
shutil.rmtree('C:/Users/Desktop/test2')
24. glob.glob()函数:查找符合条件的文件
- glob是python自己带的一个文件操作相关模块,用它可以查找符合自己目的的文件,类似于Windows下的文件搜索,支持通配符操作,*,?,[]这三个通配符,*代表0个或多个字符,?代表一个字符,[]匹配指定范围内的字符,如[0-9]匹配数字。
- 返回所有匹配的文件路径列表(list);该方法需要一个参数用来指定匹配的路径字符串(字符串可以为绝对路径也可以为相对路径),其返回的文件名只包括当前目录里的文件名,不包括子文件夹里的文件。
import glob
#获得C盘下的所有txt文件
glob.glob(r’c:*.txt’)
#获得指定目录下的所有jpg文件
glob.glob(r’E:\pic**.jpg’)
#获得当前目录上一级目录的py文件
glob.glob(r’../*.py’)