有哪些SQL优化的手段?
文章目录
-
-
- 1.1 SQL的性能分析
-
- 1.1.1 通过 show status 命令了解各种 SQL 的执行频率
- 1.1.2 慢查询日志
- 1.1.3 profile分析
- 1.1.4 通过 EXPLAIN 分析低效 SQL 的执行计划
- 1.2 常用的SQL语句优化
-
1.1 SQL的性能分析
当面对一个有 SQL 性能问题的数据库时,我们应该首先进行系统的分析,使得能够尽快定位问题 ,并通过优化SQL 从而解决问题。
1.1.1 通过 show status 命令了解各种 SQL 的执行频率
MySQL 客户端连接成功后,通过 show [session|global]status 命令可以提供服务器状态信息。show [session|global] status 可以根据需要加上参数“session”或者“global”来显示 session 级(当前连接)的统计结果和 global 级(自数据库上次启动至今)的统计结果。如果不写,默认使用参数是“session”。
show status like 'Com_%';

Com_xxx 表示执行xxx操作,Value表示每个 xxx 语句执行的次数,通常比较关心的是以下几个统计参数。
- Com_select:执行 SELECT 操作的次数,一次查询只累加 1。
- Com_insert:执行 INSERT 操作的次数,对于批量插入的 INSERT 操作,只累加一次。
- Com_update:执行 UPDATE 操作的次数。
- Com_delete:执行 DELETE 操作的次数。
通过以上几个参数,可以很容易地了解当前数据库的应用是以插入更新为主还是以查询操作为主,以及各种类型的 SQL 大致的执行比例是多少。对于更新操作的计数,是对执行次数的计数,不论提交还是回滚都会进行累加。
对于事务型的应用,通过 Com_commit 和 Com_rollback 可以了解事务提交和回滚的情况,对于回滚操作非常频繁的数据库,可能意味着应用编写存在问题。
此外,以下几个参数便于用户了解数据库的基本情况。
- Connections:试图连接 MySQL 服务器的次数。
- Uptime:服务器工作时间。
- Slow_queries:慢查询的次数。
1.1.2 慢查询日志
通过慢查询日志定位那些执行效率较低的 SQL 语句。慢查询日志会记录超出自己设置的时间还没有执行完毕的sql。默认情况下,MySQL数据库并不启动慢查询日志,需要我们手动来设置这个参数,如果不是调优需要的话,一般不建议启动该参数,因为开启慢查询日志会或多或少带来一定的性能影响。慢查询日志支持将日志记录写入文件,也支持将日志记录写入数据库表。
SHOW VARIABLES LIKE '%slow_query_log%';
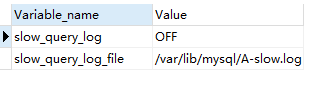
默认情况下slow_query_log的值为OFF,表示慢查询日志是禁用的,可以通过设置slow_query_log的值来开启。
开启慢查询日志sql:
SET GLOBAL slow_query_log=1;
设置慢查询的超时时间(以秒为单位):
SET GLOBAL long_query_time=2;
使用set global slow_query_log=1开启了慢查询日志只对当前数据库生效,MySQL重启后则会失效。如果要永久生效,就必须修改配置文件my.cnf。
1.1.3 profile分析
- 查看profile是否可用:
SELECT @@profiling;

- 开启profile:
SET profiling = 1;
- 查看当前会话下的所有sql执行时间:
SHOW PROFILES;
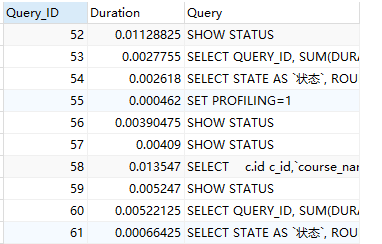
- 查看具体sql的每个步骤消耗时间:
SHOW PROFILE FOR QUERY xx; -- xx是上图的query_id

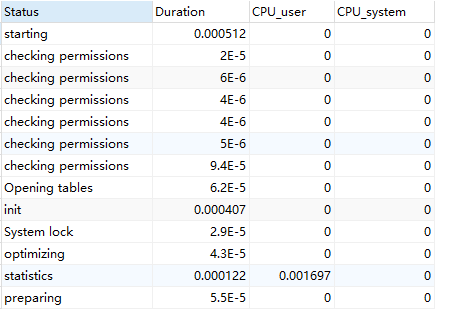
- 查看具体sql的cpu消耗时间:
SHOW PROFILE cpu FOR QUERY xx; -- xx是query_id
1.1.4 通过 EXPLAIN 分析低效 SQL 的执行计划
explain是非常重要的关键字,通过explain我们可以获得以下信息:
- 表的读取顺序
- 数据读取操作的操作类型
- 哪些索引可以使用
- 哪些索引被实际使用
- 表之间的引用
- 每张表有多少行被优化器查询
使用方法:explain + SQL语句,例如:
explain select * from user where id = 100030011

- id字段

id可以认为是查询序列号,每一个id代表一个select,一句sql有两个select,就会有两行数据,两个id,不同的id代表不同的子查询。
- id相同执行顺序由上至下。
- id不同,id值越大优先级越高,越先被执行。
- id为NULL最后执行。
- select_type:表示查询的类型
常见的类型有:
| select_type | description |
|---|---|
| SIMPLE | 简单表,即不使用表连接或者子查询 |
| PRIMARY | 包含子查询时,外层查询就显示为 PRIMARY |
| UNION | UNION 中的第二个或者后面的查询语句 |
| SUBQUERY | 子查询中的第一个 SELECT |
- table:输出结果集的表
显示这一行的数据是关于哪张表的,有时不是真实的表名字,也可能是表的别名。
- type:表示表的连接类型
性能由好到差的连接类型为:system、const、eq_ref、ref、ref_or_null、index_merge、unique_subquery、index_subquery、range、index、all等。
| type | description |
|---|---|
| system | 表中仅有一行,即常量表 |
| const | 单表中最多有一个匹配行,例如 primary key 或者 unique index |
| eq_ref | 对于前面的每一行,在此表中只查询一条记录,简单来说,就是多表连接中使用 primary key或者 unique index |
| ref | 与 eq_ref 类似,区别在于不是使用 primary key 或者 unique index,而是使用普通的索引 |
| ref_or_null | 与 ref 类似,区别在于条件中包含对 NULL 的查询 |
| index_merge | 索引合并优化 |
| unique_subquery | in 的后面是一个查询主键字段的子查询 |
| index_subquery | 与 unique_subquery 类似,区别在于 in 的后面是查询非唯一索引字段的子查询 |
| range | 单表中的范围查询 |
| index | 对于前面的每一行,都通过查询索引来得到数据 |
| all | 对于前面的每一行,都通过全表扫描来得到数据 |
- possible_keys:表示查询时,可能使用的索引。
- key:表示实际使用的索引。
- key_len:索引字段的长度。
- rows:扫描行的数量。
- Extra:执行情况的说明和描述。
1.2 常用的SQL语句优化
- 不要使用 SELECT *, 必须使用 SELECT <字段列表> 查询。查找哪个字段,就写具体的字段。例如:
select name, age from user where address = 123;
原因:
- 消耗更多的 CPU 和 IO 以网络带宽资源
- 无法使用和覆盖索引
- 可减少表结构变更带来的影响
- 不要使用不含字段列表的 INSERT 语句,例如:
-- 不使用:
insert into t values ('a','b','c');
-- 应该使用:
insert into t(c1,c2,c3) values ('a','b','c');
- 避免使用子查询,可以把子查询优化为 join 操作。
子查询性能差的原因:
子查询的结果集无法使用索引,通常子查询的结果集会被存储到临时表中,不论是内存临时表还是磁盘临时表都不会存在索引,所以查询性能会受到一定的影响。特别是对于返回结果集比较大的子查询,其对查询性能的影响也就越大。由于子查询会产生大量的临时表也没有索引,所以会消耗过多的 CPU 和 IO 资源,产生大量的慢查询。
- 避免使用 JOIN 关联太多的表。
-
对于 MySQL 来说,是存在关联缓存的,缓存的大小可以由 join_buffer_size 参数进行设置。
-
在 MySQL 中,对于同一个 SQL 多关联(join)一个表,就会多分配一个关联缓存,如果在一个 SQL 中关联的表越多,所占用的内存也就越大。
-
如果程序中大量的使用了多表关联的操作,同时 join_buffer_size 设置的也不合理的情况下,就容易造成服务器内存溢出的情况,就会影响到服务器数据库性能的稳定性。
-
同时对于关联操作来说,会产生临时表操作,影响查询效率,MySQL 最多允许关联 61 张表,建议不超过 5 个。
- 减少同数据库的交互次数。
- 数据库更适合处理批量操作,合并多个相同的操作到一起,可以提高处理效率。
- 禁止使用 order by rand() 进行随机排序。
-
order by rand() 会把表中所有符合条件的数据装载到内存中,然后在内存中对所有数据根据随机生成的值进行排序,并且可能会对每一行都生成一个随机值,如果满足条件的数据集非常大,就会消耗大量的 CPU 和 IO 及内存资源。
-
推荐在程序中获取一个随机值,然后从数据库中获取数据的方式。
- WHERE 从句中禁止对列进行函数转换和计算。
-
对列进行函数转换或计算时,会导致引擎放弃使用索引而进行全表扫描。
-
这样的查询也会导致全表扫描:
select id from student where name like '%李%',可以考虑使用全文索引。
- 在明显不会有重复值时使用 UNION ALL 而不是 UNION。
- UNION 会把两个结果集的所有数据放到临时表中后再进行去重操作
- UNION ALL 不会再对结果集进行去重操作
- 拆分复杂的大 SQL 为多个小 SQL。
- 大 SQL 逻辑上比较复杂,需要占用大量 CPU 进行计算
- MySQL 中,一个 SQL 只能使用一个 CPU 进行计算
- SQL 拆分后可以通过并行执行来提高处理效率