重磅发布 , 阿里云全链路数据湖开发治理解决方案
阿里云重磅更新全链路数据湖解决方案,主要包含开源大数据平台E-MapReduce(EMR) + 一站式大数据数据开发治理平台DataWorks + 数据湖构建DLF + 对象存储OSS等核心产品。
近日,阿里云EMR重磅推出新版数据湖Datalake,100%兼容社区大数据开源组件,具备极强的弹性能力,支持D数据湖构建DLF,数据湖存储OSS和OSS-HDFS,支持Delta Lake、Hudi、Iceberg三种湖格式。同时新版本Datalake对接阿里云一站式大数据开发治理平台DataWorks,沉淀阿里巴巴十多年大数据建设方法论,为客户完成从入湖、建模、开发、调度、治理、安全等全链路数据湖开发治理能力,帮助客户提升数据的应用效率。
另外,解决方案提供了“统一元数据管理、数据入湖、数据存储、缓存加速、弹性计算、容器、数据分析、任务编排、运维管理,以及安全”等全面数据湖能力。通过了工业和信息化部中国信息通信研究院大数据能力专项评测,荣获“云原生数据湖基础能力专项评测证书”。
阿里云全链路数据湖开发治理解决方案架构
阿里云全链路数据湖开发治理解决方案使用OSS/OSS–HDFS作为数据湖存储,DLF作为数据湖构建和管理工具,JindoFS进行湖缓存加速,EMR作为弹性计算引擎进行湖计算,DataWorks进行数据开发和治理。DataWorks各模块与DataLake深度集成,从而实现一站式数据湖开发治理。

EMR新版数据湖集群
核心运维管控能力介绍
弹性能力
- 弹性伸缩支持按集群负载和按时间2种模式
- 弹性伸缩组支持多种实例规格
- 支持抢占式实例(相较按量付费成本降低80%以上)
- 支持成本优化模式(弹性比例的按量付费+包年包月)
集群管控能力
- 分钟级别创建和扩容集群,无需手动部署和启动服务
- 完善的集群监控和告警体系,覆盖硬件和引擎服务,支持配置告警模板
新版数据湖对比Hadoop集群优势
性能更优
- 速度加快
新版数据湖集群节点组扩容速度得到明显提升,单批次大规模节点扩容速度提升80%
| Hadoop |
DataLake |
|
| 弹性扩容 10 节点 |
4分钟 |
1分10秒 |
| 弹性扩容 50 节点 |
8分钟 |
1分30秒 |
| 弹性扩容 100节点 |
10分钟 |
1分50秒 |
- 支持并发
支持任务节点(task节点类型)多节点组并行扩缩容,能够覆盖多种使用场景,业务效率成倍提升。
功能更全
- 弹性伸缩能力更强
可以同时配置按时间伸缩和按负载伸缩;支持优先下线负载低的节点;配置规则不依赖于是否运行弹性伸缩活动,可灵活修改配置(仅影响下一次触发)。
- 执行逻辑更贴近使用场景
多方位调研用户真实使用场景,功能执行逻辑设计更贴近业务实际。如:
1)弹性伸缩扩容策略支持多实例选择并按顺序弹出(兜底库存不足场景),弹性伸缩缩容支持配置优雅下线并默认按负载选择目标节点下线(减少缩容时对集群任务影响)
2)同一节点组多个弹性规则同时触发时,默认按照用户规则排序依次生效(灵活应对多种使用场景)
- 操作体验优化
更丰富的配置提示和操作引导,并新增配置项预校验逻辑,降低用户学习成本和操作失败概率。
成本更省
- 弹性伸缩性能更优,功能覆盖更广泛的场景
弹性伸缩生效更快,支持功能更全。可以帮助用户更快更好地对硬件资源进行敏捷管理,根据业务需要设置相关策略,自动变更集群规模,减少硬件资源浪费。
- 通过灵活配置抢占式实例进一步压缩成本
在新增节点组时,提供完善的抢占式实例配置策略和兜底策略供用户配置,用户可以根据其业务诉求灵活配置,通过配置抢占式实例能够进一步压缩成本。
与Hadoop集群全面对比
| 模块 |
功能项 |
新版数据湖集群 |
Hadoop集群 |
| 集群 |
集群创建时间 |
平均时间小于5分钟。 |
平均时间小于10分钟。 |
| 集群节点组新增节点 |
平均时间小于3.5分钟。 |
平均时间小于10分钟。 |
|
| 开放API |
支持。 |
支持。 |
|
| 域名支持 |
Private Zone。 |
hosts地址映射。 |
|
| 磁盘扩容 |
支持热扩容,无需重启集群服务。 |
不支持热扩容,需重启集群服务生效。 |
|
| 节点组 |
交换机 |
可以在新建节点组时选择交换机。 |
仅支持在集群创建时选择,集群创建后不可更改。 |
| 挂载公网 |
|
|
|
| 附加安全组 |
支持。 |
不支持。 |
|
| 部署集 |
|
功能受限。 |
|
| 节点组状态 |
支持。 |
不支持。 |
|
| 混合节点 |
支持同规格的不同机型混合。 |
|
|
| 弹性伸缩 |
弹性伸缩 |
弹性伸缩与节点组解耦,从独立的功能模块转为节点组操作,使用更加便捷。 |
需要专用的弹性伸缩组,该节点组不可进行手动扩缩容。 |
| 伸缩规则 |
|
|
|
| 伸缩记录 |
丰富了弹性伸缩记录信息。在查看详情页面新增了触发规则快照和执行结果参数,能够快速查看触发原因和变更节点信息。 |
提供基础的伸缩记录列表。 |
|
| 指标采集频率 |
每30秒采集一次。 |
每30秒采集一次。 |
|
| 伸缩活动生效时间 |
规则应用后1~30秒。 |
规则应用后1~2分钟。 |
|
| 扩缩容 |
扩缩容活动 |
|
|
| 高可用与软件应用 |
高可用 |
不再支持本地MySQL作为Hive Metastore数据库。 |
支持本地MySQL作为Hive Metastore数据库。 |
| 支持部署集,3台Master分布在不同底层硬件以降低硬件风险。 |
默认不支持部署集。 |
||
| NameNode与Resource Manager部署于3节点,并不再支持2 Master模式。 |
Namenode与Resource Manager仅部署于2节点,支持2 Master模式。 |
||
| 集群应用组件 |
支持可选 |
必选 + 可选。 |
|
| Spark2与Hadoop3组合 |
支持。 |
不支持。 |
|
| Spark3与Hadoop2组合 |
支持。 |
EMR-3.38.0之后版本支持同时部署。 |
DataWorks全链路开发治理能力介绍
DataWorks基于EMR-Datalake、EMR-Clickhouse、CDP等大数据引擎,为数据湖/数据仓库/湖仓一体等解决方案提供统一的全链路大数据开发治理平台。作为阿里巴巴数据中台的建设者,DataWorks从2009年起不断沉淀阿里巴巴大数据建设方法论,通过智能数据建模、全域数据集成、高效数据开发、主动数据治理(数据质量、数据地图等)、全面数据安全、快速分析服务六大全链路数据治理的能力,与数万名政务/金融/零售/互联网/能源/制造等客户携手,助力产业数字化升级。

智能数据建模
DataWorks智能数据建模沉淀阿里巴巴数据中台建模方法论,以维度建模为基础,从数仓规划、数据标准、维度建模、数据指标四个方面,以业务视角对业务的数据进行诠释,让数据仓库的建设向规范化,可持续发展方向演进。针对Datalake的智能数据建模能力将在2022年8月份正式发布。
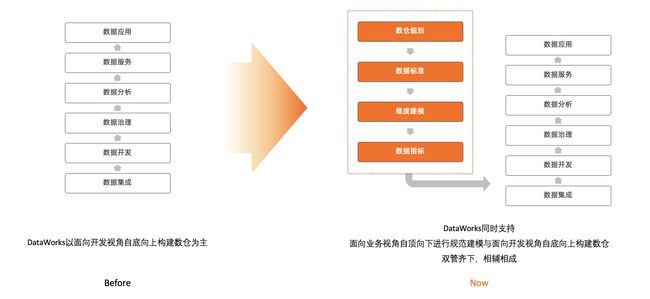
全域数据集成
DataWorks数据集成是开源DataX的商业化团队,在数据湖场景下支持50+种数据源之间的离线同步,包含数据湖常见的HDFS、Hive、HBase、OSS、Kafka等数据源,MySql、Oracle、SQLServer等数据库。同时,针对IDC>>云上、云厂商>>云厂商、云产品>>云产品、云账号>>云账号等各种同步场景,提供网络连通的解决方案,让客户在复杂网络环境、丰富的异构数据源之间,依旧保持高速稳定的数据移动能力。
高效数据开发
DataWorks数据开发(DataStudio)与运维中心面向EMR-Datalake、EMR-CK、CDH等引擎,提供可视化开发的主界面,赋予用户智能代码开发、多引擎混编工作流、规范化任务发布的强大能力,帮助用户轻松构建数据湖、离线数仓、实时数仓与即席分析系统,保证数据生产的高效与稳定。
数据开发-核心开发调度能力
- 支持EMR Hive、EMR MR、EMR Spark SQL、EMR Spark、EMR shell、EMR Presto、EMR Impala、EMR Spark Streaming共八种节点。
- 远超开源的超大规模调度稳定能力(双11单日千万级任务实例)
- 分钟/小时/天/周/月多种调度周期
- 业务流程全局参数/节点上下文传参

数据开发-多种可视化数据对象管理及控制节点
- 可视化资源文件上传(HDFS/OSS)
- 可视化管理UDF(Java)
- 可视化建表(支持HDFS/OSS)
- 归并、赋值、顺序、循环、分支等控制节点。
- 多种调度周期混合编排
- 可视化业务流程编排

数据开发-智能SQL编辑器
- 语法高亮
- 关键词自动补全
- 表/字段信息提示
- 函数信息提示
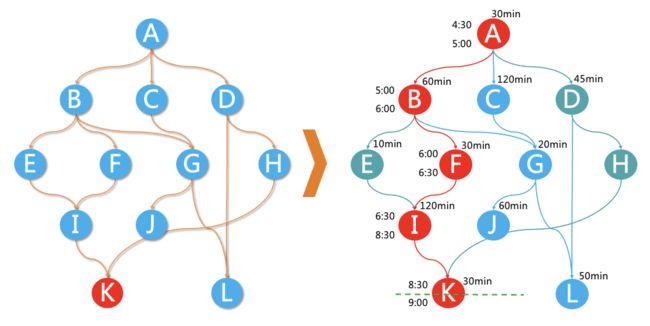
任务运维-运行诊断
运行诊断可帮助用户快速定位任务出错原因,例如
- 上游依赖未完成
- 调度资源不足
- 数据质量规则拦截
- 基线破线
同时拥有补数据相关能力,方便用户快速处理运维情况。在告警方面,运维中心支持多种告警方式
- 支持Webhook(钉钉、微信、飞书)、电话、短信、邮件等多渠道告警
- 支持基于值班表配置告警人员,

任务运维-智能基线
智能基线是DataWorks独创的监控技术,具备国家专利,用户无需配置每个任务的告警时间,仅需配置最终产出节点的告警时间,智能基线会基于历史的任务运行情况,在核心任务可能无法准时产出时,做提前告警,保障核心任务的生产稳定。
主动数据治理
DataWorks数据治理包含数据治理中心、数据质量、数据地图等多个产品,覆盖事前、事中、事后的数据生命周期,通过数据治理健康分、质量规则、数据大血缘等能力,将书面的数据治理规范落地成平台化的产品能力,让数据治理不再一个 “阶段性项目”,而是一个“可持续的运营项目”。
数据质量
EMR HIVE节点支持DataWorks数据质量规则,内置37种数据质量规则模板,可以进行可视化、批量数据质量规则配置,提高数据质量规则配置效率。同时该模块与数据开发调度深度集成,可通过调度触发规则运行,节省计算资源,及时发现问题。
- 支持37种内置数据质量模板规则
- 支持批量配置规则、规则模板
- 支持绑定调度引擎并在质量报警时阻塞业务流程
- 支持动态阈值(顶会论文技术,算法自动判定告警阈值)
- 支持SQL自定义规则
- 支持短信、邮件、钉钉告警
- 支持自定义数据质量报告
- 支持质量问题处理记录
同时,数据质量支持强弱规则设置,进行灵活的运维控制。
- 强规则,直接阻塞下游任务运行,防止问题数据污染下游,浪费下游执行的计算资源
- 弱规则,只告警,不阻塞任务运行,针对一些非核心任务。

数据地图
数据地图支持完整的EMR-Datalake元数据体系,可以针对表名、字段名进行快速搜索,基于表、字段血缘浏览上下游关系快速找表,包括:
- 支持表基础信息、业务描述信息、产出信息等
- 支持分区、字段的明细信息与变更记录
- 支持表的产出信息解析(包括对表写入数据 或者 创建分区的调度任务)
- 支持表、字段的血缘信息解析(实时解析)
- 支持对表进行分级分类、收藏等操作
- 支持全局检索、按类目导航检索、按类目过滤
表基础信息:
表血缘信息:
全面数据安全
在数据安全方面,DataWorks支持Datalake引擎数据全生命周期的安全管理。包括以下5个方面:
数据传输安全
- 数据源访问控制
数据存储安全
- 存储加密
- 数据备份
数据处理安全
Ranger精细化数据授权管控
规范化开发流程,开发环境、生产环境执行身份独立管理
数据交换安全
数据脱敏
通用数据安全
RBAC权限模型
操作行为审计
LDAP认证管理
快速分析服务
SQL查询:完善的SQL查询编辑器,支持即席查询Hive、SparkSQL、Impala

电子表格:即席分析数据,Web类型的Excel
数据服务:低代码快速搭建ClickHouse API
开通购买
快速开通使用
快速入门:DataWorks on EMR快速入门 - 开源大数据平台E-MapReduce - 阿里云
使用须知:DataWorks On EMR开发流程(必读) - 大数据开发治理平台 DataWorks - 阿里云
迁移助手
调度任务迁移
为了帮助客户快速将原有的调度任务迁移到DataWorks上使用,我们提供了迁移助手,支持以下任务迁移能力:
- 支持Airflow,Oozie,Azkaban工作流迁移
- 支持EMR数据开发一键迁移至DataWorks
- 工作空间之间各种数据对象迁移
