实战 | 实时的目标检测与识别简单应用
![]()
吃粽子迎端午
![]()
计算机视觉研究院专栏
作者:Edison_G
最近总是有很多入门的朋友问我,我进入计算机视觉这个领域难不难?是不是要学习很多知识?到底哪个方向比较好?

长按扫描二维码关注我们
一、问题来源
最近总是有很多入门的朋友问我,我进入计算机视觉这个领域难不难?是不是要学习很多知识?到底哪个方向比较好?
这些问题其实我也不好回答他们,只能衷心告诉他们,如果你对这领域特别感兴趣,那你可以进来试试玩玩,如果试过了玩过了,觉得这不是你喜欢的领域,那你可以立马退出,选择你喜欢的领域方向。我个人一直认为,科研这个东西,真的是要有兴趣爱好,这是你动力和创新的源泉。只有对自己选择的领域有兴趣,有动力深入挖掘,我觉得一定会做得很好,可能还会创造出许多意想不到的结果。
如果现在你们入门的朋友,选择了目标检测类,你们可以没事玩玩今天说的框架和网络,这个过程真的可以学习很多东西,只要你愿意花费时间和精力去深入,现在我们闲话少说,直接进入正题。
二、我们来分析
正如我之前说的:深度学习近期总结分析。在目标检测中,有很多经典的网络框架,比如RCNN,SSP,Fast RCNN。其中Fast RCNN就使用Selective Search来进行候选区域,但是速度依然不够快。今天的主角(Faster R-CNN)则直接利用RPN(Region Proposal Networks)网络来计算候选框。RPN以一张任意大小的图片为输入,输出一批矩形候选区域,每个区域对应一个目标分数和位置信息。Faster R-CNN中的RPN结构如图所示。
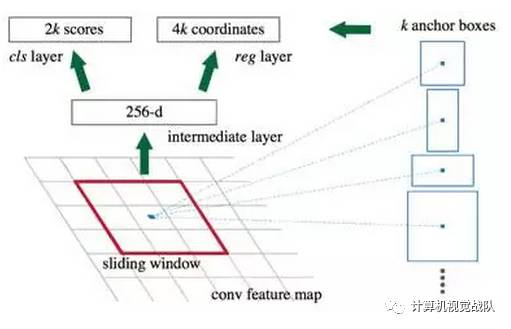
Faster RCNN的主要步骤如下:
特征提取:同Fast RCNN,以整张图片为输入,利用CNN得到图片的特征层;
候选区域:在最终的卷积特征层上利用k个不同的矩形框(Anchor Box)进行提名,k一般取9;
分类与回归:对每个Anchor Box对应的区域进行object/non-object二分类,并用k个回归模型(各自对应不同的Anchor Box)微调候选框位置与大小,最后进行目标分类。
总之,Faster RCNN抛弃了Selective Search,引入了RPN网络,使得候选区域、分类、回归一起共用卷积特征,从而得到了进一步的加速。但是,Faster RCNN需要对两万个Anchor Box先判断是否是目标(目标判定),然后再进行目标识别,分成了两步。
今天就来讲讲怎么简单操作该网络,以便后期有兴趣的朋友再次基础上做出改进。
三、简单入门实践
git官网的py-faster-rcnn源码
终端输入:cd /home/**(您服务器的名字)
git clone --recursive https://github.com/rbgirshick/py-faster-rcnn.git
生成Cython模块
终端输入:cd /home/**(您服务器的名字)/py-faster-rcnn/lib
make
生成Caffe和pycaffe
终端输入:cd /home/**(您服务器的名字)/py-faster-rcnn/caffe-fast-rcnn
cp Makefile.config.example Makefile.config
打开Makefile.config,修改之处可以根据您自己需求修改(比如你要使用Python,GPU等功能)
保存退出。
终端输入:cd /home/**(您服务器的名字)/py-faster-rcnn/caffe-fast-rcnn
mkdir build
cd build
cmake ..(注意这是两个句点,不要忘记)
make all -j16("‐j16"是使用 CPU 的多核进行编译,可以提速,根据您自己
硬件调整)
make install
make runtest -j16
make pycaffe(编译pycaffe)
下载fetch_fast_rcnn_models
终端输入:cd /home/**(您服务器的名字)/py-faster-rcnn
./data/scripts/fetch_faster_rcnn_models.sh
运行demo.py
终端输入:cd /home/home/**(您服务器的名字)/py-faster-rcnn/tools
./demo.py

到这几,基本的都完成了,接下来就是实现自己的数据train和demo。
1
首先制作自己的数据集
(如果您用公共数据集,那就可以忽略这步骤)
保留data/VOCdevkit2007/VOC2007/Annotations和ImageSets和JPEGImages文件夹名称,删除其中所有的文件(保留文件夹)。其中Annotations保存标签txt转换的xml文件,ImageSets保存train.txt、trainval.txt、test.txt、val.txt四个文件分别储存在layout、main和Segmentation文件夹中,最后JPEGImages保存所训练的数据。
然后,Annotations中xml文件的制作。该部分的代码我会放在公众平台的共享文件菜单中。最后做出来的效果就是如下所示:

最终生成的格式如下:

最后在ImageSets中的trainval文件中,根据你自己来划分!
2
修改参数和文件
prototxt配置文件
models/pascal_voc/ZF/faster_rcnn_alt_opt文件夹下的5个文件,分别为:stage1_rpn_train.pt、stage1_fast_rcnn_train.pt、stage2_rpn_train.pt、stage2_fast_rcnn_train.pt和fast_rcnn_test.pt,修改格式如下:
(1)stage1_fast_rcnn_train.pt和stage2_fast_rcnn_train.pt修改参数:
num_class:2(识别1类+背景1类),cls_score中num_output:2,bbox_pred中num_output:8
(2)stage1_rpn_train.pt和stage2_rpn_train.pt修改参数:
num_class:2(识别1类+背景1类)
(3)fast_rcnn_test.pt修改参数:
cls_score中num_output:2,bbox_pred中num_output:8(只有这2个)
修改lib/datasets/pascal_voc.py
self._classes = ('__background__', # always index 0 'zongzi')(只有这一类)
修改lib/datasets/imdb.py
数据整理,在一行代码为:
boxes[:, 2] = widths[i] - oldx1 - 1 下加入代码:
for b in range(len(boxes)):
if boxes[b][2]< boxes[b][0]:
boxes[b][0] = 0
修改完pascal_voc.py和imdb.py后进入lib/datasets目录下删除原来的pascal_voc.pyc和imdb.pyc文件,重新生成这两个文件,因为这两个文件是python编译后的文件,系统会直接调用。
终端进入lib/datasets文件目录输入:
python(此处应出现python的版本)
>>>importpy_compile
>>>py_compile.compile(r'imdb.py')
>>>py_compile.compile(r'pascal_voc.py')
3
现在我们开始训练自己数据
终端进入py-faster-rcnn下输入:
./experiments/scripts/faster_rcnn_alt_opt.sh0 ZF pascal_voc
4
运行demo
运行demo,即在py-faster-rcnn文件夹下终端输入:
./tools/demo.py --net zf
其中修改/tools/demo.py为:
(1) CLASSES =('__background__', 'zongzi')
(2) NETS ={'vgg16': ('VGG16', 'VGG16_faster_rcnn_final.caffemodel'),
'zf': ('ZF', 'ZF_faster_rcnn_final.caffemodel')}
四、实验效果
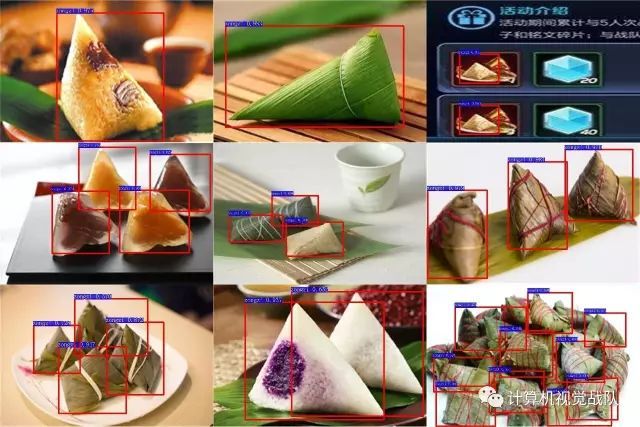
注:有部分目标没有检测出来,可能是由于目标遮挡,重叠造成,所以往后需要我们大家做的就是,怎么去解决实际生活中遇到的种种问题,利用所学的知识和自己的创新去改进,优化!
由于今天是端午假,大家都会吃粽子,所以今天的目标检测就是“粽子”,通过各种渠道得到粽子的训练和测试数据集,最后得到如下部分的结果可视化图。
© THE END
转载请联系本公众号获得授权
![]()
计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式