BizTalk开发系列(三十四) Xpath
更多内容请查看:BizTalk动手实验系列目录
XPath 是在 XML 文档中查找信息的语言,在BizTalk的开发中应用非常广泛,当然你可以不必先学Xpath再去学BizTalk。但是如果对Xpath有一定了解的话,在很多应用下会使你的开发更加快捷。为了方便查阅整理了一些Xpath常识和实际实例给开发过程提供个参考。由于BizTalk还未支持Xpath 2.0,所以以下的例子都是基于W3C 1.0规范。
Xpath的重要性[实际的场景] 之前做一个升级的项目,在项目中需要对XML进行节点查找并比较里面相应的值,通过比较结果再选取它的父节点。由于接收到的XML文件节点值经常会多带一些空格。所以原有的系统是在自定义类库中循环选择节点值,删除左右空格然后再比较,取值。当然在还没有了解Xpath之前这么做可以。但了解了之后可以使用更简单的方法就可以解决了。接下来我会在下面提到解决办法。
基础及概念 XPath 使用路径表达式在 XML 文档中选取节点。Xpath的路径包括绝对路径(以斜杠开头)和相对路径(不以斜杠开头)。节点是通过沿着步(step)来选取的,步与步之间使用斜杠("/") 分割。通常我们使用的Xpath表达式例如:/Root/Person 其实是步的一种简写方式,如果使用步的语法来写的话应该是:/child::Root/child::Person
步包括:
- 轴(axis) 定义所选节点与当前节点之间的树关系
- 节点测试(node-test) 识别某个轴内部的节点
- 零个或者更多谓语(predicate) 更深入地提炼所选的节点集
语法:
轴名称::节点测试[谓语]
下面列出了最常用的路径表达式:
| 表达式 |
描述 |
| nodename |
选取此节点的所有子节点 |
| / |
从根节点选取 |
| // |
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . |
选取当前节点 |
| .. |
选取当前节点的父节点 |
| @ |
选取属性 |
另外由于XML是一个树型结构因此节点与节点之间有相应的关系,以下为节点之间的关系:
- 父(Parent)每个元素以及属性都有一个父。
- 子(Children)元素节点可有零个、一个或多个子。
- 同胞(Sibling)拥有相同的父的节点。
- 先辈(Ancestor)某节点的父、父的父,等等。
- 后代(Descendant)某个节点的子,子的子,等等。
以上都是一些概念上的东西,不太理解也没有关系,只是为了统一一下概念而以。下面结合实例来和大家一起讲探讨一下Xpath在实际开发过程中的应用。可能有一些是比较基础的,就纯粹当个参考。
Xpath实践
在做实例前先准备一下执行Xpath的环境,XML Spy是一款比较好的XML相关的开发测试工具,只可惜是收费的。如果有条件的话建议还是使用XML Spy。另外免费的工具里也有不错的选择,SketchPath就是其中的一款,下图为SketchPath的使用过程截图,该工具可以自动高亮显示Xpath查询的区域,底部还带有函数提醒功能等,比较适合在学习中使用。
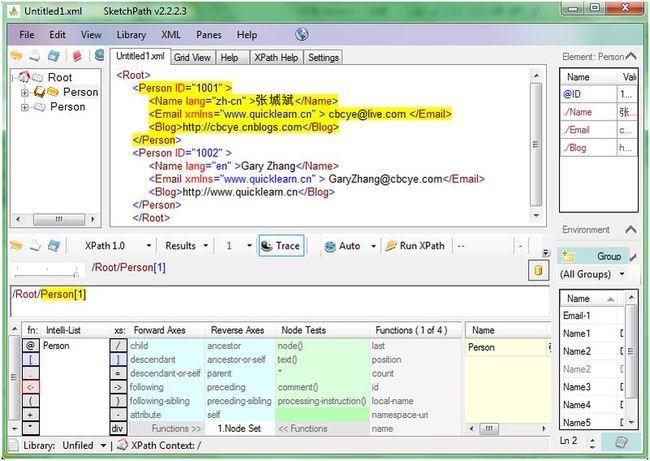
测试使用的XML源
选择节点
| 表达式 |
描述 |
| Root |
选取此节点的所有子节点 |
| /Root |
选取根元素 Root 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| Root/Person |
选取所有属于 Root 的子元素的 Person 元素。 |
| //Name |
选取所有 Name 子元素,而不管它们在文档中的位置。 |
| Root//Name |
选择所有属于 Root 元素的后代的 Name 元素,而不管它们位于 Root 之下的什么位置 |
| //@lang |
选取所有名为 lang 的属性 |
| /Root/Person/* |
选取 Person 元素的所有子节点 |
| //* |
选取所有的元素 |
| //Person[@*] |
选取所有带属性的Person元素 |
| /Root/Person[1]/Name | /Root/Person[1]/Blog |
选取第一个Person节点下的Name和Blog节点 |
使用谓语(Predicates)
谓语用来查找某个特定的节点或者包含某个指定的值的节点。谓语被嵌在方括号中。
| 表达式 |
描述 |
| /Root/Person[1] |
选取属于 Root 子元素的第一个 Person 元素。 |
| /Root/Person[last()] |
选取属于 Root 子元素的最后一个 Person 元素。 |
| /Root/Person[last()-1] |
选取属于 Root 子元素的倒数第二个 Person 元素。 |
| /Root/Person[position()<3] |
选取属于 Root 子元素的前两个 Person 元素。 |
| //Person[@ID] |
选取所有拥有名为 ID 的属性的 Person 元素。 |
| //Person[@ID="1001"] |
选取所有 Person 元素,且这些元素拥有值为 1001 的 ID 属性。 |
| /Root/Person[@ID>1001]/Blog |
选取所有 Root 元素的 Person 元素的Blog元素,且其中的 Person元素的ID 属性的值须大于 1001。 |
经常使用到的函数
函数:fn:local-name()
说明:返回当前节点的名称或指定节点集中的第一个节点 - 不带有命名空间前缀,由于在BizTalk中使用的XML一般是含有命名空间约束的,因此使用这个函数可以根据节点的名称来查找而不用管命名空间是否匹配。
例子:/Root/Person[1]/*[local-name()="Email"] 结果:返回所有节点名称为Email的节点。 注意:由于示例的XML文档的Email节点受命名空间约束,所以使用/Root/Person[1]/Email的方式是取不到值的。
函数:fn:namespace-uri()
说明:返回当前节点或指定节点集中第一个节点的命名空间 URI
例子:/Root/Person[1]/*[local-name()="Email"]/namespace-uri() 结果:www.quicklearn.cn
函数:fn:count((item,item,...))
说明:返回节点的数量
例子:count(/Root/Person) 结果:2
函数:fn:normalize-space(string)
fn:normalize-space()
删除指定字符串的开头和结尾的空白,并把内部的所有空白序列替换为一个,然后返回结果。如果没有 string 参数,则处理当前节点。
例子:normalize-space(" The Space ") 结果: The Space
这个函数也是前文中提到的解决办法,具体使用大家自己试一下吧。
其他例子
| 表达式 |
描述 |
| /Root/Person/Name[@lang="en"]/preceding::Blog |
选取Name节点中lang属性值为en的同级Blog节点 |
| string(/Root/Person[1]/Name/text()) |
选取第一个Person节点下的Name节点值,并以string类型输出 |
| number(/Root/Person[1]/@ID) |
选取第一个Person节点下的ID属性值,并以number类型输出 |
| /Root/Person/Name[@lang="en"]/../*[local-name()="Email"]/text() |
选取Name节点中lang属性值为en的节点的同级节点Email的值 |
参考资料