.numpy()
Tensor.numpy()将Tensor转化为ndarray,这里的Tensor可以是标量或者向量(与item()不同)转换前后的dtype不会改变
a = torch.tensor([[1.,2.]]) a_numpy = a.numpy() #[[1., 2.]]
.item()
将一个Tensor变量转换为python标量(int float等)常用于用于深度学习训练时,将loss值转换为标量并加,以及进行分类任务,计算准确值值时需要
optimizer.zero_grad()
outputs = model(data)
loss = F.cross_entropy(outputs, label)
#计算这一个batch的准确率
acc = (outputs.argmax(dim=1) == label).sum().cpu().item() / len(labels) #这里也用到了.item()
loss.backward()
optimizer.step()
train_loss += loss.item() #这里用到了.item()
train_acc += acc
.cpu()
将数据的处理设备从其他设备(如.cuda()拿到cpu上),不会改变变量类型,转换后仍然是Tensor变量。
.detach()和.data(重点)
.detach()就是返回一个新的tensor,并且这个tensor是从当前的计算图中分离出来的。但是返回的tensor和原来的tensor是共享内存空间的。
举个例子来说明一下detach有什么用。 如果A网络的输出被喂给B网络作为输入, 如果我们希望在梯度反传的时候只更新B中参数的值,而不更新A中的参数值,这时候就可以使用detach()
a = A(input) a = a.deatch() # 或者a.detach_()进行in_place操作 out = B(a) loss = criterion(out, labels) loss.backward()
Tensor.data和Tensor.detach()一样, 都会返回一个新的Tensor, 这个Tensor和原来的Tensor共享内存空间,一个改变,另一个也会随着改变,且都会设置新的Tensor的requires_grad属性为False。这两个方法只取出原来Tensor的tensor数据, 丢弃了grad、grad_fn等额外的信息。
tensor.data是不安全的, 因为 x.data 不能被 autograd 追踪求微分
这是为什么呢?我们对.data进行进一步探究
import torch
a = torch.tensor([4., 5., 6.], requires_grad=True)
print("a", a)
out = a.sigmoid()
print("out", out)
print(out.requires_grad) #在进行.data前仍为true
result = out.data #共享变量,同时将requires_grad设置为false
result.zero_() # 改变c的值,原来的out也会改变
print("result", result)
print("out", out)
out.sum().backward() # 对原来的out求导,
print(a.grad) # 不会报错,但是结果却并不正确
'''运行结果为:
a tensor([4., 5., 6.], requires_grad=True)
out tensor([0.9820, 0.9933, 0.9975], grad_fn=)
True
result tensor([0., 0., 0.])
out tensor([0., 0., 0.], grad_fn=)
tensor([0., 0., 0.])
'''
由于更改分离之后的变量值result,导致原来的张量out的值也跟着改变了,但是这种改变对于autograd是没有察觉的,它依然按照求导规则来求导,导致得出完全错误的导数值却浑然不知。
那么我们继续看看.detach()

可以看到将.data改为.detach()后程序立马报错,阻止了非法的修改,安全性很高
我们需要记住的就是:
- .data 是一个属性,二.detach()是一个方法;
- .data 是不安全的,.detach()是安全的。
补充:关于.data和.cpu().data的各种操作
先上图
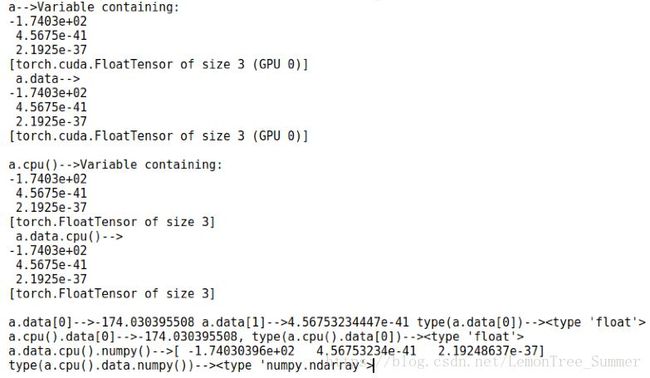
仔细分析:
1.首先a是一个放在GPU上的Variable,a.data是把Variable里的tensor取出来,
可以看出与a的差别是:缺少了第一行(Variable containing)
2.a.cpu()和a.data.cpu()是分别把a和a.data放在cpu上,其他的没区别,另外:a.data.cpu()和a.cpu().data一样
3.a.data[0] | a.cpu().data[0] | a.data.cpu()[0]是一样的,都是把第一个值取出来,类型均为float
4.a.data.cpu().numpy()把tensor转换成numpy的格式
总结
到此这篇关于pytorch中.numpy()、.item()、.cpu()、.detach()以及.data使用的文章就介绍到这了,更多相关pytorch .numpy()、.item()、.cpu()、.detach()及.data内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!