redis学习七redis的集群:主从复制、CAP、PAXOS、Cluster分片集群(二)
redis学习七redis的集群:主从复制、CAP、PAXOS、Cluster分片集群
-
-
- redis分布式遇到的多种情况
-
- 采用sharding分片
- hash环
- 预分区解决的办法
- 使用redis twemproxy
-
- 弊端
- 使用redis predixy
- redis cluster(分配槽位)演示
-
redis分布式遇到的多种情况
1、首先要控制让redis尽量轻一点
客户端按业务去划分redis,存入不同业务类型的数据

但是有的时候可能根据业务拆不开这个数据了,那么这种方案就实现不了了。
采用sharding分片
那么可以按照一些hash算法加上取模去拆分,模的数就是redis的实例数

此方式的弊端,模的数值是固定的,会影响分布式下的扩展,因为一个数在模3模4模10取得的结果是不一样的,可能扩展了以后就取不到数据了。

随机扔,用一个统一的key去存,这个key是个list,另一个客户端只需要进行rpop。
topic和partition其实是kafka的概念
从概念上讲,topic只是一个逻辑概念,代表了一类消息,也可以认为是消息被发送到的地方。通常可以使用topic来区分实际业务
一个topic拆成了多个partition,每个partition可以分散到不同的机器上,这样就可以把单机的压力分散到多台机器上。因此topic在kafka中是一个逻辑上的概念,实际存储单元都是partition。
最后一种是一致性hash算法:

一般他们的一致性hash计算会把它规划成一个环形的hash计算
hash环
每个node都经过一个hash算法计算出一个环形hash所在的位置,然后data来了【包含了redis的key】,也是计算hash,找到环上的某个位置,这个环上除了通过node计算出来的点是物理的,其他的都是虚拟的点【就是data通过hash计算没落在物理点上的其他点】,再将物理点通过排序的方式放在一个treeMap上面,然后算出
data的值之后在treeMap上面去找,找到最近的值,找到最近的值所代表的物理机,再将数据写入到
对应的机器上面。

这种方式的优点是加节点,的确可以分担其他节点的压力的,并且
不会造成全局洗牌。
缺点:
新增节点会造成一小部分数据不能命中,则会造成问题
1、redis击穿,会把数据访问压力给到mysql,然后再放到redis
2、解决方案:每次去取离我最近的2个物理节点(这种方案
更倾向于redis作为缓存而不是数据库)
3、数据倾斜为题解决方案,可以让node1后面依次拼10个
数字,然后让node2后面依次拼接10个数字,这样就会从原来的两个物理节点
发展为20个物理节点。
如上都是通过客户端去连接的,这样会造成客户端的连接成本很高

那么如何去解耦连接,才能降低对server连接的压力呢?
通过类似于反向代理的方式来解决,通过代理层去实现我们上面三个sharding分片的逻辑

这样只需要关注代理层的性能就可以了,那么如何解决代理层的压力呢?

预分区解决的办法
如上三种分片模式只是解决了缓存的问题,并没有解决redis作为数据库使用的问题。
预分区,为了应对以后redis数量不断扩展而使用的,需要rehash,比如现在只有两个redis,以后可能
会扩展为十个。
如下:比如是对十取模,

两个节点各分配了五个槽位,如果扩展为三个节点的话:
在节点1中找到对应3和4槽位的数据传输给redis3,节点2只需要将8和9的数据传输给redis3。

redis集群预分区:
客户端随便连任意redis,然后get一个k1,然后在redis里面进行一个hash取模运算,并且redis
里面存所有其他的redis分片的映射关系,如果不是当前访问的redis的话,则给客户端返回
需要去redirect重定向到哪台redis上面去,然后再由客户端进行跳转【无主模型,主主模型】

这样对数据分治以后了,聚合操作很难实现,如事务(取多个key,多个key不在一个redis里面),
所以引入了hashtag,交给使用者去实现

使用redis twemproxy
网址 https://github.com/twitter/twemproxy

首先执行yum install nss
再执行yum install -y git





然后进入src会发现有如下文件:

进入script文件会发现有如下初始化文件:




所以如果我们要操作系统中让它变为一个服务来使用的话:

将文件变为可执行文件:

然后再找它的配置文件:


拷贝到刚才创建的目录下面:

再将可执行程序拷贝到我们的usr/bin下面


下一步修改配置文件:

配置文件的使用方式可以参照git上面的readme的configuration

再配置成如下形式:
端口后面对应的值是他的权重。

然后再启动两个redis实例:
在data目录里面创建6379和6380文件,在当前目录启动redis,当前目录会作为redis的一个持久化目录


然后再连接到6380:

然后启动好之后,再来启动我们的代理:


启动代理之后则用我们代理的端口号去连接我们的redis


然后分别客户端6379和6380进入redis里面:


发现6379有k1和k2然而6380只有k1,从而客户端只需要关注22122端口即可
弊端
因为数据是分治的,不支持keys *,也不支持watch和muti

使用redis predixy
这里找到redis直接编译了的然后下载



配置信息参照文档: https://github.com/joyieldInc/predixy/blob/master/doc/config_CN.md

我们来看predixy.conf:

再找到service

可以看到可以导入别的文件,但是只能出现一种


这里先配置哨兵的:

然后进入哨兵配置文件:
通过26379的哨兵,监控36379和46379的master,同理26380和26381也一样配置。

分别启动26380和26381的哨兵:

然后再建立两套主从




如上启动了两套主从以及对应哨兵:
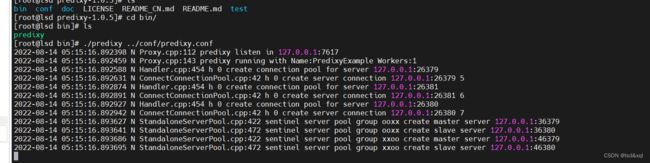
然后就能通过代理去访问redis了

通过set一个统一的oo让它跑在固定的一台机器上面,但是这个方式是不支持事务的,因为我后台配置了两套主从,没有redis
自身的机制好

predixy事务只支持单套的:
进入predixy哨兵配置文件

删除一个group即可,这样哨兵只会往其中一个主从复制里面来写了,删除之后再来启动

重连即可使用事务了

redis cluster(分配槽位)演示

进入README:配置步骤如下

然后再看create-cluster的脚本
#!/bin/bash
# Settings
BIN_PATH="../../src/"
CLUSTER_HOST=127.0.0.1
PORT=30000
TIMEOUT=2000
NODES=6 //对应六台机器
REPLICAS=1//从的数量是1 ,每个主上面有一个从,三主三从
PROTECTED_MODE=yes
ADDITIONAL_OPTIONS=""
# You may want to put the above config parameters into config.sh in order to
# override the defaults without modifying this script.

在启动脚本发现六个实例跑起来了,然后再分片,找到分片的命令

然后发现槽位分为0-5640 5641-10922 10923-16383这三个

下面replica表示从节点之间的关系,然后连接30001端口的redis实例

会返回一个错误叫我用30003来操作,这种情况就应该重新连一下加一个带c(cluster)的参数



然后在30001上面进行事务操作,然后set k2发现直接跳到 30003上面去了,再执行事务的话是控制不住的


同时也可以执行事务:

然后我们下面来还原

这种方式来写的话就可以应对于真实的物理机分片了:
此时要在redis启动的时候加上 cluster-enabled yes 这个配置

它的其他命令还包含了重新分片,增加节点,删除节点,重新均衡等

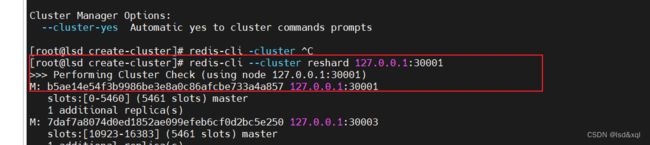
想移动多少个槽位:


输入从哪里移动


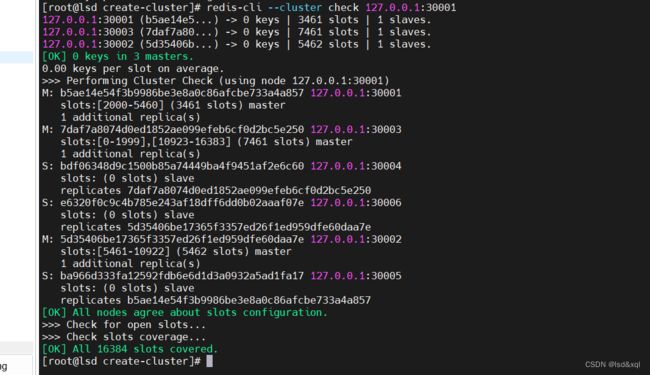
如上能看到槽位分配的信息。