先上整体效果图:
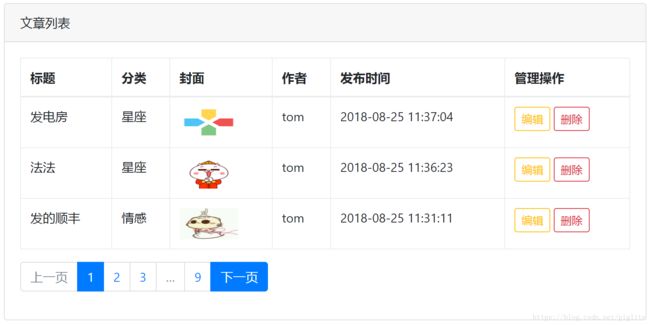
然后是分页图详情:



与本例相关的路由和模板包括:
路由:views.py
@app.route('/blog/list/', methods=['GET'])
@login_required
def blog_list(page=None):
...
模板:blog_list.html和pages.html
blog_list.html作为博客页面,pages.html模板为分页页面,呈现时会在blog_list.html中导入pages.html的内容。
{%import 'pages.html' as pg%}
{{pg.my_paginage(pagination,'art_list')}}
首先从路由开始:
路由的设计思路是根据查询的页码作为参数,利用FlaskSQLAlchemy的Model进行查询并对查询结果进行分页处理。
@app.route('/blog/list/', methods=['GET'])
@login_required
def blog_list(page=None):
#每个人只能看自己发表的blog
if not page:
page = 1
from models import Blog
from models import User
user_id = User.query.filter_by(username=session['user']).first().id
#paginate方法返回一个sqlalchemy.Pagination类型对象
blogs = Blog.query.filter_by(user_id=user_id).order_by(Blog.addtime.desc()).paginate(page=page,per_page=3)
category=[(1, '情感'), (2, '星座'), (3, '爱情')]
return render_template('blog_list.html', title='博客列表',session=session,blogs=blogs.items,category=category,pagination=blogs)
分析一下上述代码:
1. @app.route装饰器定义了路由
2. @login_required是自定义装饰器,用来限定只有登录用户才可以浏览博客列表,未登录用户会进入登录页面
3. 作为Model的Blog中有一个外键属性user_id引用着用户表,用来记录博客的作者信息
4. blogs是一个FlaskSQLAlchemy中的Pagination类型对象。一个Query对象调用paginate方法就获得了Pagination对象。paginate方法传入了两个参数,一个是当前页,另一个是每一页最多显示多少博客。paginate的返回值为代表当前页的Pagination对象。一个Paginationi对象的常用属性有:
- items 当前页面中的所有记录(比如当前页上有5条记录,items就是以列表形式组织这5个记录)
- query 当前页的query对象(通过query对象调用paginate方法获得的Pagination对象)
- page 当前页码(比如当前页是第5页,返回5)
- prev_num 上一页页码
- next_num 下一页页码
- has_next 是否有下一页 True/False
- has_prev 是否有上一页 True/False
- pages 查询得到的总页数 per_page 每页显示的记录条数
- total 总的记录条数
常用方法有:
- prev() 上一页的分页对象Pagination
- next() 下一页的分页对象Pagination
- iter_pages(left_edge=2,left_current=2,right_current=5,right_edge=2)
- iter_pages 用来获得针对当前页的应显示的分页页码列表。
- 假设当前共有100页,当前页为50页,按照默认的参数设置调用iter_pages获得的列表为:
- [1,2,None,48,49,50,51,52,53,54,55,None,99,100]
5. 渲染blog_list.html模板时,传入渲染时需要的若干参数,比较重要的是传入blogs参数用来让模板显示查询出来的应该在本页面中显示的博客信息,另外是传入pagination参数,利用传入的Pagination对象的相关属性方法动态生成分页的相关内容。
看一下pages.html模板的内容:
{%macro my_paginate(pagination,url)%}
{%endmacro%}
分析一下上述页面代码:、
整体来说就是根据当前对“上一页”,“页码”和“下一页”进行不同的设置
1. 使用JinJa2的宏,定义my_paginate方法,传入路径和pagination对象作为参数。通过调用宏的执行生成分页内容。
2. 通过设置class为pagination,可以使用FlaskBootStrap预置CSS样式
3. 利用JinJa2的if语句根据当前页是否还有前一页使用不同的元素和class。
如果当前页有上一页,则pagination对象的has_prev为True,此时li标签的class为page-item和active,采用的BootStrap样式意 为此时上一页是可点的。点击后跳转的链接会是url_for函数根据传入的路由方法名称(也就是url参数值)并添加上page参数,参数值为当前页码-1
如果当前页没有上一页,则pagination对象的has_prev为False,此时li标签的class为page-item和disable,采用的BootStrap样 式意为此时上一页是不可点的。跳转的链接会是#
4. 与“上一页”处理类似的是对“下一页”的处理。如果当前页有下一页时设置样式和点击跳转路径,如果没有下一页了,则设置为 不可点击并且跳转路径为#
5. 利用iter_page(1,1,3,1)会获得基于当前页应该显示的页码列表。如上面截图所示,如果当前页是第4页,获得的分页列表内容 就是[1,None,3,4,5,6,None,9],如果当前页是第9页,获得的分页列表内容是[1,None,8,9]
6. 利用JinJa2的for语句遍历列表,如果是页码,就根据页码生成a标签中的文字并设置跳转路径并添加上page参数。如果是None,a标签中的文字为实体名表示的省略号,路径为“#”。额外的,如果遍历时获得了当前页码所对应的数字时,为li标签的class属性添加上额外的active以获得额外的样式。
最后在blog_list.html中要引入pages.html
{%import 'pages.html' as pg%}
{{pg.my_paginate(pagination,'blog_list')}}
在blog_list.html中导入pages.html模板并调用pages.html中定义的my_pagination宏,传入两个参数,第一个参数是pagination对象,这个参数是从views.py中渲染blog_list.html的时候传入的,另外一个就是一个字符串'blog_list',它对应的是views.py中路由方法的名称,有了这个名称在my_paginate中就可以利用url_for函数进行路由方法对应路径的寻找。
到此这篇关于Flask快速实现分页效果示例的文章就介绍到这了,更多相关Flask 分页内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!