Rust 五分钟了解,三十分种入门
Rust 快速入门
- 初始化项目
- 基础
-
- 变量 - 常量
- 数据类型
- 函数
- 注释
- 控制流
- 所有权
-
- 移动
- 克隆
- 所有权与函数
- 返回值与作用域
- 引用与借用
-
- 可变引用
- Slice 类型
-
- 其他类型的 slice
- 结构体
-
- 方法
- 枚举
-
- Option 枚举
- 模式匹配
-
- match
- 通配模式 和 _ 占位符 和 多个匹配 和 守卫条件
- if let 条件表达式 - 语法糖
- while let 条件循环
- 模式匹配 核心理解
- 模式语法
- 项目管理
-
- 模块
- use
- 模块分割进不同文件
- 错误处理
-
- 不可恢复错误
- 可恢复错误
- ? 运算符 - 语法糖
- 常见集合
-
- Vec
- HashMap
- 泛型
- trait
- 生命周期
- 参考
博主是边学边写,有错误请宝贝们指出
初始化项目
编辑器推荐: IDEA + Rust插件
我用的linux , window如何建项目,百度吧亲~
cargo new 项目名
建好后就是这样的,很漂亮是吧
基础
Rust官方学习文档(中文): https://kaisery.github.io/trpl-zh-cn/title-page.html
变量 - 常量
基础
let a:i32=1; //变量默认不可变
//a=2 报错
let mut b=1; //加mut则可变
const c:i32=1; //常量必须指明类型,变量通常可以推断出类型
隐藏特性
可以说就是重新定义了一个变量,只是名字一样而已,当然它并没有破坏作用域
按官方的话说就是: Rustacean 们称之为第一个变量被第二个 隐藏 了,这意味着程序使用这个变量时会看到第二个值
let x = 5;
//这里的x是5
let x = x + 1;//5+1
//可以说这个x和上面的x除了名字一样,其他的完全没有关联
{
let x = x * 2;//6*2
println!("{}", x);//12
let x="abc";//完全没有关联,就算是变类型
println!("{}", x);//abc
}
println!("{}", x);//6
数据类型
| 长度(单位:bit) | 有符号 | 无符号 |
|---|---|---|
| 整型(默认:i32) | ||
| 8-bit | i8 | u8 |
| 16-bit | i16 | u16 |
| 32-bit | i32 | u32 |
| 64-bit | i64 | u64 |
| 128-bit | i128 | u128 |
| arch | isize | usize |
| 浮动数(默认:f64) | ||
| 32-bit | f32 | |
| 64-bit | f64 |
字符类型 char ,大小4字节
布尔类型 bool
let a=123_456i64;//可以在后面加类型指明 字面量 类型,可以用 _ 分割
let a=0xffi16;//16进制
let a:i8 =0o7_i8;//8进制
let a=0b1111_0000_1;//2进制
let a:u8=b'a';//单字节字符,仅限于u8
元组类型
元组是一个将多个其他类型的值组合进一个复合类型的主要方式。元组长度固定:一旦声明,其长度不会增大或缩小
没有任何值的元组 () 是一种特殊的类型,只有一个值,也写成 () 。该类型被称为 单元类型(unit type),而该值被称为 单元值(unit value)。如果表达式不返回任何其他值,则会隐式返回单元值
我喜欢把
单元值叫做空元组
let a:(i32,f32)=(1,2.2);
//a.0 == 1
//a.1 == 2.2
//解构
let (z,x)=a;//z=1,x=2.2
let (z,x,c)=(2,2.2,true);//字面量元组
//用在函数多返回值上面是非常dei劲的
fn f() -> (i32,bool){
return (1,false);
}
数组类型
与元组不同,数组中的每个元素的类型必须相同。Rust 中的数组与一些其他语言中的数组不同,Rust中的数组长度是固定的
let a =[1,2,3];
// [类型;数量]
let a: [i32; 5] = [1, 2, 3, 4, 5];
let a = [1;3];//a= [1,1,1]
函数
表达式和语句这个概念在Rust比较重要
语句(Statements)是执行一些操作但不返回值的指令。表达式(Expressions)计算并产生一个值
如果在表达式的结尾加上分号,它就变成了语句,而语句不会返回值
let a:i32={1};//需要注意的是 {1}是表达式,而这句话的整体是语句
用大括号创建的一个新的块作用域也是一个表达式
在函数签名中,必须 声明每个参数的类型
不能确定,在Rust中{}就是一个表达式,而表达式内部结尾是一个表达式的话,就返回这个表达式,如果没有,则返回空元组
fn 函数名(参数名:参数类型,...) -> 返回类型 {
//代码
}
fn f(x:i32)->i32{
return 1;
//或者 表达式结尾
1
}
关于函数式
//署名函数 , 它本身也是表达式
|参数名:参数类型| 表达式
let f = |x:i32| x+1 ;
let f:fn(i32)->i32=|x| x+1;
let f:fn(i32)->i32=|x:i32| x+1 ;
let f:fn(i32)->i32=|x:i32| {
return x+1;
//或者
x+1
};
let f:fn(fn(i32)->i32)->fn()->();
f = |af:fn(i32)->i32| {
||()
};
注释
//一行
/*
多行
*/
///文档注释
///这玩意支持MarkDown
///官方好像还有一个功能可以把这玩意直接搞成文档,输出出来
控制流
if 表达式
if 本身也是表达式
if true{//注意if只支持 bool类型
}else if true{
}else{
}
let a = if true { }else { 1 };//if是表达式,Rust好像没有三元运算符
// true: a=()空元组 ,false: a=1
//可能宝贝们会想 可不可以使用return ,不能使用,return是用来函数返回值的命令,虽然函数也可以使用 结尾表达式 返回
循环体
loop 无限循环,不知道它出现的意义是啥子,有懂的宝贝,评论一下,蟹蟹
'a:loop {// '标记名: 循环体
break 'a;
}
循环返回
let mut a;
a = 'a:loop {
break 'a;
};//a=()空元组
a = loop{
break 1;
};//a=1
while 正常循环
'a:while true{//只支持bool类型
break 'a;
}
//并不支持循环返回
for 遍历集合
let s=[1;5];
for v in s{// 1,1,1,1,1
println!("{}",v);
}
//需要注意的是 0..5 是 std::ops::Range,稍后描述,下面是它的文档网址
//https://doc.rust-lang.org/std/ops/struct.Range.html
// [0,5)
for v in 0..5{//0,1,2,3,4
println!("{}",s[v]);
}
for v in (0..5).rev(){//4,3,2,1,0
println!("{}",s[v]);
}
所有权
我认为这玩意还是看官方文档的好,快速入门主要还是怕我以后忘记了,然后快速回忆的,不会描述过多的细节
所有权_官方文档
所有权(系统)是 Rust 最为与众不同的特性,它让 Rust 无需垃圾回收(garbage collector)即可保障内存安全。因此,理解 Rust 中所有权如何工作是十分重要的
我喜欢把
所有权叫拥有权,所有者叫拥有者,因为所有这词有点难理解,不过习惯就好
栈(Stack)是固定大小 , 堆(Heap)可变大小
let a="123";//入栈
let a=String::from("123");//入堆
内存在拥有它的变量离开作用域后就被自动释放
{
let s="123";
//内存中存在s
}
//内存中不存在s,以被释放
所有权规则
Rust 中的每一个值都有一个被称为其 所有者(owner)的变量。
值在任一时刻有且只有一个所有者。
当所有者(变量)离开作用域,这个值将被丢弃。
移动
将值赋给另一个变量时移动它。当持有堆中数据值的变量离开作用域时,其值将通过 drop 被清理掉,除非数据被移动为另一个变量所有
let a="123";//入栈
let b=a;//a把值复制给b,入栈
//a,b都有效
let a = String::from("123");//入堆
let b = a;//a移动到b , 这并不像java是做地址引用,并不是浅拷贝
//此时a无效,可以这样理解,a把堆的所有权给了b,或者说 a拥有的空间给了b,a变成穷比了,穷比无法生存
//具体为什么要这么做,你可以看看官方文档,比较多,就不描述了
克隆
如果我们 确实 需要深度复制 堆上的数据,而不仅仅是栈上的数据,可以使用一个叫做
clone()的通用函数
let a = String::from("123");
let b = a.clone();
//此时 a,b 都有效,且互相不影响
所有权与函数
学这玩意,你必须了解 移动 和 栈堆
let s=String::from("123");
f1(s);//s 移动到函数的参数a
//println!("{}",s);//s无效
fn f1(a:String){
}//f函数结束,a被释放,也就是s原有的堆空间被释放
let i=1;
f2(i);//i 复制到函数的参数x
println!("{}",i);//i有效
fn f2(x:i32){
}
返回值与作用域
和 所有权与函数 一个道理
let s=f1();
println!("{}",s);//s有效
let b=f2(s);//s移动到函数参数a上,f2函数把a移动到接受者b上
// println!("{}",s);//s无效
println!("{}",b);
fn f1()-> String{
String::from("123")//移动到接受者,也就是s
}
fn f2(a:String )->String{
a
}
引用与借用
& 符号是 引用 , * 符号是 解引用
Rust引用 和 C指针很像 , 在官方文档第15章<<智能指针>>,我估计和C指针概念差不多
& 符号就是 引用,它们允许你使用值但不获取其所有权
我们将创建一个引用的行为称为 借用(borrowing)
C
int i=1;
int *pi=&i;
printf("%d%d",i,*pi);
Rust
let i:i32=1;
let pi:&i32=&i;// &i 创建一个指向值 i 的引用; i 借给 pi,这样 i 就不会穷死
println!("{}{}",i,pi);//i,pi都有效
可变引用
引用规则:
在任意给定时间,要么 只能有一个可变引用,要么 只能有多个不可变引用。
引用必须总是有效的。
一个引用的作用域从 声明的地方开始一直持续到最后一次使用为止
let a:&mut i32;//可变引用 , 提前是 被引用者 也是可变的
let mut b:i32=1;
a=&mut b;
*a=9;
let a:&i32;//不可变引用
a=&b;
//*a=10;//报错!现在a是&i32,是不可变的
println!("{}",a);//9
可变引用有一个很大的限制:在同一时间只能有一个对某一特定数据的可变引用 ; 这个限制的好处是 Rust 可以在编译时就避免数据竞争
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
//println!("{}", r1);//报错 ,因为r1的作用域包含了二次引用可变
println!("{}", r2);//安全 ,此时r1不存在了
也不能在拥有不可变引用的同时拥有可变引用
let mut s = String::from("hello");
let r1 = &s;
let r2 = &s;
let r3 = &mut s;
//println!("{}, {}", r1, r2);//报错,因为r1和r2的作用域包含了引用可变
println!("{}",r3);//安全得很
总而言之就是 存在一个可变引用时 不能在出现一个引用(可变或不可变)
以上2条几乎没机会触发,毕竟你没必要同时需要多个可变引用,也没必要存在可变引用,需要不可变引用
Slice 类型
slice 是一类引用,所以它没有所有权
语法: &变量[a…b] , 区间[a,b)
字符串 slice的类型声明写作&str
字符串字面值被储存在二进制文件 ,
&str它是一个指向二进制程序特定位置的 slice。这也就是为什么字符串字面值是不可变的;所以&str是一个不可变引用
let a:&str="0123456789";
let b:String=String::from("012345");
println!("{}",&b[..]);// 012345 省略a,b ,a取最小,b取最大
println!("{}",&b[..3]);//012 a取最小
println!("{}",&b[3..]);//345 b取最大
println!("{}",&b[0..3]);//012
其他类型的 slice
…给个例子,其他省略
let a:[i32;5] = [1, 2, 3, 4, 5];
let slice:&[i32] = &a[1..3];
结构体
至于概念就不描述了,来学Rust的估计也都是些 大佬 了
//定义结构体
struct 结构体名 {
int:i32,
long:i64
//字段名1 : 类型1,
//...
}
//创造结构体
let a = 结构体名 {
int: 1,
long:2
//字段名: 值,
//...
};
//结构体更新 - 语法糖
//注意! 更新起到 移动 效果
let b = 结构体名 {
int:5,
..a
};
//b.int = 5
//b.long = 2
//元组结构体
struct 元组结构体名(i32, i32, i32);
let a= 元组结构体名(1,2,3);
//类单元结构体
struct 类单元结构体名;
方法
概念就不描述了
struct 结构体名 {
int:i32,
long:i64
}
impl 结构体名 {
fn new(int:i32,long:i64)->结构体名{//关联函数,没有self,就是关联函数,就类似与 java的静态函数一样,不需要实例对象
//java: 类名.静态方法()
//rust: 结构体名::关联函数()
结构体名 {
int,
long
}
}
fn f(self:&self){}//self非缩写
fn add(&self)->i64{
self.long + self.int as i64
}
fn change(&mut self,int:i32,long:i64){
self.int=int;
self.long=long;
}
fn 自杀(self){
}
}
fn main() {
let mut a:结构体名= 结构体名::new(1,2);
a.f();
println!("{}",a.add());//3
a.change(5,5);//若 a 是不可变,就会报错
println!("{}",a.add());//10
a.自杀();//所有权 移动 到 "自杀"方法里
// println!("{}",a.add());//a 自杀了,会报错,这个"自杀"函数好无聊,哈哈
}
可以定义多个impl块
枚举
可以将任意类型的数据放入枚举成员中,枚举类型也可以
enum B{
bb
}
enum ABC{
A,
B(B),
C(i32,String),
D{x:i32,y:i32},
E()
}
fn main() {
let a = ABC::A;
let b = ABC::B(B::bb);
let c = ABC::C(1,String::from("a"));
let d = ABC::D {x:1,y:2};
let e = ABC::E();
}
枚举也可以定义方法
impl ABC{
fn a(&self){
}
}
C风格用法
enum Color {
Red = 0xff0000,
Green = 0x00ff00,
Blue = 0x0000ff,
}
enum Number {//从0开始
Zero,
One,
Two,
}
fn main() {
println!("{}",Color::Red as i32);//16711680
println!("{}",Number::Zero as i32);//0
}
Option 枚举
Option 类型应用广泛因为它编码了一个非常普遍的场景,即一个值要么有值要么没值
Rust 并没有很多其他语言中有的空值功能。空值(Null )是一个值,它代表没有值。在有空值的语言中,变量总是这两种状态之一:空值和非空值。
Rust 并没有空值,不过它确实拥有一个可以编码存在或不存在概念的枚举。这个枚举是 Option,而且它定义于标准库中,如下:
enum Option<T> {
None,//None差不多就是null的意思
Some(T),//非null的意思
}
不能确定!,只有Option才存在null的概念,其他类型变量都不存在,也就是你不用担心非Option运行时出现null情况,如果有null那你程序跑不起来的
模式匹配
对于
模式匹配这个概念,我也有点模糊,坐等学到后面自然懂,哈哈
match
match 表达式必须是 穷尽(exhaustive)的,意为 match 表达式所有可能的值都必须被考虑到
模式由如下一些内容组合而成:
字面值
解构的数组、枚举、结构体或者元组
变量
通配符
占位符
语法:
match 值 {
模式 => 表达式
}
通配模式 和 _ 占位符 和 多个匹配 和 守卫条件
例子:
enum ABC {
A,
B,
C,
D(i32)
}
fn main() {
let a=ABC::D(9);
let x =match a {
ABC::A | ABC::B => 1,// 用 | 符 分割,代表多个匹配
ABC::D(c) if c > 0 => {c},//通过`if`引入子分支的守卫条件
_ => 0 //占位符,必须包含ABC枚举的全部,否则会报错,因为 match 表达式必须是 穷尽(exhaustive)的
};
println!("{}",x);//9
let a=0;
let x = match a {
b => {//b==a , 通配 和 占位不可同时出现,也没必要同时出现
b+1
}
//_ => { //你也完全可以写成这样
// a+1
//}
};
println!("{}",x);//1
}
if let 条件表达式 - 语法糖
if let 表达式的缺点在于其穷尽性没有为编译器所检查,而 match 表达式则检查了
语法:
if let 模式 = 值 表达式
你还可以使用 else if let , 甚至和 if 一起使用
例如:
let a=ABC::B;
let x = if let ABC::A = a { 0 }
else if let ABC::B = a { 1 }
else if 1==1 { 2 }
else {3};
println!("{}",x);//1
我认为就是加强了if, 因为if只能接受bool类型,没有模式匹配那么强大
while let 条件循环
只要模式匹配就一直进行 while 循环
语法:
while let 模式 = 值 {
}
模式匹配 核心理解
关于提高理解程度,建议读官方的文档(可反驳性)
模式有两种形式:refutable(可反驳的)和 irrefutable(不可反驳的)
函数参数、 let 语句和 for 循环只能接受不可反驳的模式,因为通过不匹配的值程序无法进行有意义的工作。if let 和 while let 表达式被限制为只能接受可反驳的模式,因为根据定义他们意在处理可能的失败:条件表达式的功能就是根据成功或失败执行不同的操作
match匹配分支必须使用可反驳模式,除了最后一个分支需要使用能匹配任何剩余值的不可反驳模式
let a=1;//不可反驳
if let Some(x) = a_value { };//可反驳 , 匹配则执行大括号内的代码
模式语法
官方文档入口,哦耶~
用 .. 忽略剩余值
@ 绑定
使用 @ 可以在一个模式中同时测试和保存变量值
上面已经描述一部分了,具体见官方文档
项目管理
模块
mod 模块关键字
pub 代表公共,默认私有,除了枚举可以影响孩子,其他都需要单独声明
crate 是根模块
孩子可以访问父亲,私有的也可以
在Rust中,模块就像文件系统一样,它们有 路径,可以通过use将功能引入到当期作用域
在模块内,我们还可以定义其他的模块,模块还可以保存一些定义的其他项,比如结构体、枚举、常量、特性、或者函数
绝对路径从 crate 根开始,以 crate 名或者字面值 crate 开头。
相对路径从当前模块开始,以 self、super 或当前模块的标识符开头。
mod A {//A的父模块是 crate
struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
mod B {
use crate::A;//绝对路径
use super::super::A;//相对路径
pub fn b(){//pub代表公共,默认私有
A::a();//访问父模块的私有a函数
}
}
fn a(){
B::b();
}
}
use
使用 use 把对应功能 引入当前作用域
//不需要use
println!("{}",std::cmp::min(1,2));
//use std::*;
println!("{}",cmp::min(1,2));
//use std::cmp::*;
println!("{}",min(1,2));
//use std::cmp::min;
println!("{}",min(1,2));
// 部分引用
use std::cmp::{min, max};
use std::{cmp};
use std::{cmp::min, cmp::max};
//---
use std::io;
use std::io::Write;
use std::io::{self, Write};//等价于上面2行
//---
//在本地取个别名,和 js 那个一样
use std::cmp as 别名
重导出 pub use
fn main() {
B::a();
}
mod A{
pub fn a(){}
}
mod B{
pub use super::A::a;//就像把引用过来的功能,直接加入B模块了
// use super::A::a;
}
模块分割进不同文件
我的理解是 mod 模块名; 是声明子模块,pub mod 模块名;是暴露(公开,公共)子模块
根模块是main.rs 或 lib.rs , mod.rs估计就是根据目录名来决定模块名,还有一种方法,就是在/src下建 A.rs,不过没这个方便好看
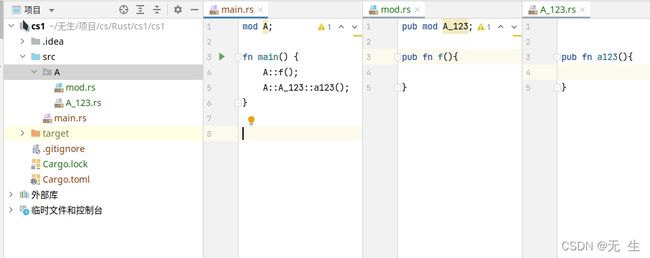 这个就和 普通的差不多,只不过是把 内容写到文件去了,上图和下文差不多的意思,但是构建项目,你不可能全塞到一个文件里
这个就和 普通的差不多,只不过是把 内容写到文件去了,上图和下文差不多的意思,但是构建项目,你不可能全塞到一个文件里
mod A {
pub mod A_123 {
pub fn a123(){
}
}
pub fn f(){
}
}
fn main(){
A::f();
A::A_123::a123();
}
错误处理
不可恢复错误
panic! 不可恢复错误(异常)
 总而言之调用
总而言之调用 panic! 宏,程序就会死亡
比如你程序生病了,你不想程序死亡,你可以选择治疗它,那治疗就是 可恢复错误
当然,有必死的情况,比如数组越界,所以你得注意程序的逻辑
可恢复错误
enum Result<T, E> {
Ok(T),
Err(E),
}
其实这和Option是一个逻辑,返回不同的情况,作出不同的处理
在概念上,就完全可以把它说成错误,虽然它是枚举,就比如 返回1是正常,返回0是异常,只是形式不同
Result就是告诉你,它可能无法达到预期,达到预期就OK,没有达到就Err
//比如存在文件 就OK,其他都Err
if let Ok(file) = File::open("a.txt") {
print!("ok");
}else if let Err(e) = File::open("a.txt"){//可以省略成 eles,写这么长只是为了提供理解,而且你可能需要提取异常信息e
println!("err");
//panic!("给爷死!"); //如果你的意图是,Err就去世,那么就可以加上它
match e.kind() {
ErrorKind::NotFound => 0 ,//精准异常信息,当然这是库提供的,而不是Rust的特性,所以说 模式匹配太棒了
_ => ()
}
}
//上面的代码要是java来,那不得 try catch 个很多行
让我们的代码在精简一点
let f = File::open("a.txt").unwrap();
let f = File::open("a.txt").expect("Err");
看看源码

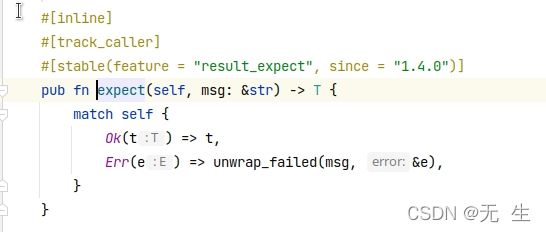

通过源码我们看到,就是通过方法简化了 match,并且调用了panic!
如果你并不想在当前函数处理错误,你可以选择返回错误,让调用当前函数者去处理 , 比如上面的File::open()就是返回错误,让调用者去处理
? 运算符 - 语法糖
实现了 FromResidual 的类型的函数中可以使用 ? 运算符
Result 和 Option 都实现了
Result Err就返回
Option None就返回
fn f() -> Result<String , io::Error>{
let a:File = File::open("123.txt")?;//若返回值是Err,则函数直接返回Err,若是OK,则返回Ok内的值,比如:File
File::open("123.txt")?.read_to_string(&mut String::from("132"))?;//链式调用,和js很像
//当然你提前,是函数返回类型是 Result ,不然它咋返回,是不是.
//在有些情况,甚至可以使用 ?? 的写法
Ok(String::from("ok"))
}
常见集合
Vec
Vec 的功能就类似 java的 List 一样, 泛型,可变成数组
vec! 宏,提供方便
//这三个s是一样的
let mut s:Vec<i32> = Vec::new();
s.push(3);
s.push(3);
s.push(3);
let s = vec![3,3,3];
let s = vec![3;3];
for i in &s {
println!("{}",i);// 3 3 3
}
println!("{}",&s[0]);//3
// println!("{}",&s[55]); //异常代码
if let Some(i) = s.get(55) {
println!("{}",i);// s.get() 不溢出就会运行这行代码
} else {
println!("None!");//s.get(55) 溢出了,但是没有报错,因为它返回None
}
常用操作
let mut s = vec![0,1,2,3,4];
s.sort();//排序
s.push(5);//结尾增加
println!("{}",s.len());//6
s.remove(5);//删除下标5的数据
println!("{}",s.get(0).unwrap());//0
println!("{}",&s[0]);//0
println!("{}",s.pop().unwrap());//返回4 , 移除最后一个并返回它
for v in &s{
println!("{}",v);//0 1 2 3
}
s[0]=111;//修改
println!("{}",s.contains(&111));//true ,如果有给定值,就返回ture
println!("{}",s.is_empty());//false ,如果向量不包含任何元素,则返回true
s.retain(|&i| i%2!=0);//条件筛选
println!("{:?}",s);// [111,1,3]
HashMap
HashMap 哈系表
常用操作
use std::collections::HashMap;
let mut map = HashMap::new();
map.insert("a",1);//写入
map.insert("a",2);//写入,会覆盖
map.entry("a").or_insert(11);//不存在key则写入
*map.get_mut("a").unwrap() = 9;//改变它
println!("{}",map.get("a").unwrap());//9 ,读
for (key, value) in &map {//遍历
println!("{}: {}", key, value);// a: 9
}
泛型
概念就不描述了
fn f<T>(t:&T)->&T{//函数泛型
t
}
enum Option<T> {//枚举泛型
Some(T),
None,
}
struct ABC<T,R>{//结构体泛型
x:T,
y:R
}
impl<T> ABC<T,i32> {//方法泛型 ,在创建结构体时 如果R泛型不是i32,那么下面的方法不可见 ,你也可以写成 impl ABC {} ,这里只是介绍一下
fn new_T_i32(t:T) -> ABC<T,i32>{//但是关联函数可见
ABC { x:t, y:0 }
}
fn x(&self) -> &T{
&self.x
}
fn y(&self) -> i32{
self.y
}
}
我爱了,特别是方法泛型,太美了~
trait
这就类似与java的接口,俗称定一堆公共行为
不过这玩意可比java的接口强太多了
孤儿规则: 不能为外部类型实现外部 trait (这条规则确保了其他人编写的代码不会破坏你代码)
trait A{
fn f(&self)->usize;
fn f2(&self){//默认实现
println!("默认实现{}",self.f());
}
}
impl A for String {// impl trait for 类型 ; 没有违背孤儿规则, A是内部的
fn f(&self) -> usize {
self.len() + 100
}
}
fn main() {
//没错,你的String添加这个方法了
//这跟 Kotlin的扩展特性一样,酷毙了!
let s=String::from("123");
println!("{}",s.f());
s.f2();
}
fn f(i:&impl A) -> &impl A{//参数和返回值
i
}
fn f2<T: A>(i:&T){//加强泛型(限制泛型类型,对应类型必须实现A)
}
fn f3(i:& (impl A + B)){//指定多个实现,必须实现A和B,缺一不可,B也是一个trait,你还可以 A+B+C+...
}
fn f4<T: A+B>(i:&T){//耶~
}
//如果真的需要 A+B+C+... ,那不得太丑了,所以美化 where 出现了
fn f5<T>(i:&T)
where T:A+B+C+... {
}
//最NB的来啦
trait ToString {
fn a(&self);
}
impl<T: Display> ToString for T {
fn a(&self) {
println!("aa");
}
}
fn main() {
1.a();//aa
}
你没有看错,它通过实现了特定的trait的类型 有条件地实现了trait
意思就是 实现了 Display 的全部类型 都实现一遍 ToString ,所以 1.a() 是没有问题的, 太nb了,太爱了
这意味着 你可以随时随地给多个trait增加trait,就类似与给它们增加一个父亲一样,它们这些trait都有父亲trait的行为
生命周期
Rust 生命周期 - 链接
参考
官方文档
30分钟学习-Rust :英文文档