c++邮递员投递经过特定点_简单聊聊centerNet:将目标当成点-1.论文

CenterNet:将目标视为点
《Objects as Points》
Date:20190417
Author:德克萨斯大学奥斯汀分校 和 UC 伯克利 ariXiv:
https://arxiv.org/abs/1904.07850arxiv.orggithub:
https://github.com/xingyizhou/CenterNetgithub.com看到这篇文章海很惊讶,虽然现在很多关于Anchor-Free相关的论文,将目标视作一个点,这个还是很新颖的一个创新,并且还开源了代码.并且centernet 不仅可以在目标检测上应用,还可以应用到姿势估计和3D目标检测上.
0.摘要:
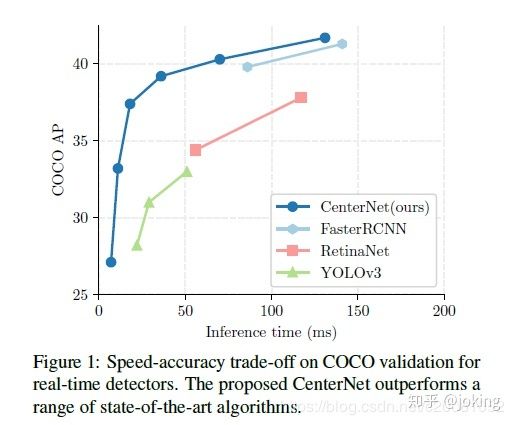
目标检测是将图像中的对象用轴对齐框标识出来。大多成功的目标检测器都先穷举出潜在目标位置,然后对该位置进行分类。这是浪费,低效的,并且需要额外的后续处理。在本文中,我们采用不同的方法,构建模型时将目标作为一个点——即目标BBox的中心点。我们的检测器采用关键点估计来找到中心点,并回归到其他目标属性,例如尺寸,3D位置,方向,甚至姿态。我们的基于中心点的方法CenterNet比相应的基于边界框的检测器具有端到端可微分,更简单,更快速和更准确的特点。我们的模型实现了速度和精确的最好权衡,以下是其性能:CenterNet在MS COCO数据集上实现了最佳的速度 - 准确性权衡,其中28.1%的AP为142 FPS,37.4%的AP为52 FPS,45.1%的AP为1.4 FPS的多尺度测试。我们使用相同的方法来估计KITTI基准中的3D边界框和COCO关键点数据集上的人体姿势。同复杂的多阶段方法比较,我们的取得了有竞争力的结果,而且做到了实时的。(谷歌翻译,会有些不通顺的)
1.介绍:
目标检测 驱动了 很多基于视觉的任务,如 实例分割,姿态估计,跟踪,动作识别。且应用在下游业务中,如 监控,自动驾驶,视觉问答。当前检测器都以bbox轴对称框的形式紧紧贴合着目标。对于每个目标框,分类器来确定每个框中是否是特定类别目标还是背景。One stage detectors 在图像上滑动复杂排列的可能bbox(即锚点),然后直接对框进行分类,而不会指定框中内容( One-stage detectors slide a complex arrangement ofpossible bounding boxes, called anchors, over the imageand classify them directly without specifying the box con-tent. )。Two-stage detectors 对每个潜在框重新计算图像特征,然后将那些特征进行分类(Two-stage detectors recompute image-features for each potential box, then classify those features)。后处理,即 NMS(非极大值抑制),通过计算Bbox间的IOU来删除同个目标的重复检测框。这种后处理很难区分和训练,因此现有大多检测器都不是端到端可训练的(Post-processing, namely non-maxima suppression, then re-moves duplicated detections for the same instance by com-puting bounding box IoU. This post-processing is hard todifferentiate and train, hence most current detectorsare not end-to-end trainable. )。尽管如此,在过去的五年中,这些想法取得了很好的成功经验。然而,基于滑动的窗口的物体检测器有点浪费,因为它们需要枚举所有可能的物体位置和尺寸。
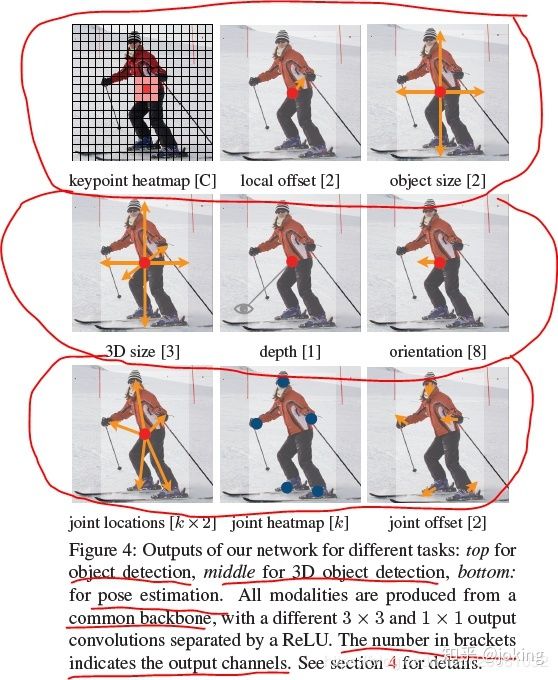
本文通过目标中心点来呈现目标(见图2),然后在中心点位置回归出目标的一些属性,例如:对象大小(size),尺寸( dimension), 3D范围(3D extent), 方向(orientation), 位置(pose)。 而目标检测问题变成了一个标准的关键点估计问题。我们仅仅将图像传入全卷积网络,得到一个热力图,热力图峰值点即中心点,每个特征图的峰值点位置预测了目标的宽高信息。

我们的方法是很通用,只需很少的努力对我们的模型做一些拓展到其他任务。我们提供了关于3D物体检测和多人人体姿态估计的实验,通过预测每个中心点的附加输出(见图4)。
对于3D BBox检测,我们直接回归得到目标的深度信息,3D框的尺寸,目标朝向;
对于人姿态估计,我们将关节点(2D joint)位置作为中心点的偏移量,直接在中心点位置回归出这些偏移量的值。
由于模型设计简化,因此运行速度较高(见图1)我们的网络运行速度达到142 FPS,带有28.1%COCO边界框AP值。Witha精心设计的关键点检测网络,DLA-34 ,我们的网络在52 FPS下实现了37.4%的COCO AP。配备了最先进的关键点估算网络,Hourglass-104 和多尺度测试,我们的网络以1.4 FPS达到45.1%的COCO AP。在3D边界框估计和人体姿态估计方面,我们以更高的干扰速度与最先进的技术竞争。(速度针对挺快的)
2. Related work相关工作
通过区域分类进行物体检测(Object detection by region classification):第一个成功的深层物体探测器之一RCNN,从大量区域候选物中对物体位置进行测量,并使用深度网络对每个物体进行了分类。Fast-RCNN改为使用图像特征来节省计算量。但是,这两种方法都依赖于慢速低级别区域提取方法。
具有隐式锚点的对象检测(Object detection with implicit anchors:FasterRCNN 在检测网络内生成区域提取网络(RPN)。它在低分辨率图像网格周围对固定形状的边界框(锚点)进行采样,并将其分类为“前景与否”。一个锚被标记为地面,其中带有一个> 0.7重叠的任何地面真实对象,背景带有<0.3重叠,否则忽略。每个生成的区域建议再次被分类将提议分类器更改为多类别这种形式是一级探测器的基础。对一级探测器的几个改进包括锚形状,不同的特征分辨率,以及不同样本之间的损失加权。
我们的方法与基于锚点的one-stage方法相近。中心点可看成形状未知的锚点(见图3)。但存在几个重要差别(本文创新点):
第一,我们分配的锚点仅仅是放在位置上,没有尺寸框。没有手动设置的阈值做前后景分类。(像Faster RCNN会将与GT IOU >0.7的作为前景,<0.3的作为背景,其他不管);
第二,每个目标仅仅有一个正的锚点,因此不会用到NMS,我们提取关键点特征图上局部峰值点(local peaks);
第三,CenterNet 相比较传统目标检测而言(缩放16倍尺度),使用更大分辨率的输出特征图(缩放了4倍),因此无需用到多重特征图锚点;

通过关键点估计做目标检测(Object detection by keypoint estimation): 我们并非第一个通过关键点估计做目标检测的。CornerNet将bbox的两个角作为关键点;ExtremeNet 检测所有目标的 最上,最下,最左,最右,中心点;所有这些网络和我们的一样都建立在鲁棒的关键点估计网络之上。但是它们都需要经过一个关键点grouping阶段,这会降低算法整体速度;而我们的算法仅仅提取每个目标的中心点,无需对关键点进行grouping 或者是后处理;
单目3D 目标检测(Monocular 3D object detection):3D BBox检测为自动驾驶赋能。Deep3Dbox使用一个 slow-RCNN 风格的框架,该网络先检测2D目标,然后将目标送到3D 估计网络;3D RCNN在Faster-RCNN上添加了额外的head来做3D projection;Deep Manta 使用一个 coarse-to-fine的Faster-RCNN ,在多任务中训练。而我们的模型同one-stage版本的Deep3Dbox 或3D RCNN相似,同样,CenterNet比它们都更简洁,更快。
3.初步( Preliminary)
令
为输入图像,其宽W,高H。我们目标是生成关键点热力图
,其中R 是输出stride(即尺寸缩放比例),C是关键点类型数(即输出特征图通道数);关键点类型有: C = 17 的人关节点,用于人姿态估计; C = 80 的目标类别,用于目标检测。我们默认采用下采用数为R=4 ;
表示检测到的关键点;
表示背景;我们采用了几个不同的全卷积编码-解码网络来预测图像 I 得到的
:stacked hourglass network堆叠沙漏网络 , upconvolutional residual networks (ResNet), deep layer aggregation层次聚类 (DLA) 。
我们训练关键点预测网络时参照了Law和Deng (H. Law and J. Deng. Cornernet: Detecting objects as
paired keypoints. In ECCV, 2018.) 对于 Ground Truth(即GT)的关键点 c ,其位置为
,计算得到低分辨率(经过下采样)上对应的关键点
. 我们将 GT 关键点 通过高斯核
分散到热力图
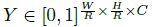
上,其中
是目标尺度-自适应 的标准方差。如果对于同个类 c (同个关键点或是目标类别)有两个高斯函数发生重叠,我们选择元素级最大的。训练目标函数如下,像素级逻辑回归的focal loss:

其中
和
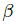
是focal loss的超参数,实验中两个数分别设置为2和4, N是图像 I 中的关键点个数,除以N主要为了将所有focal loss归一化。
由于图像下采样时,GT的关键点会因数据是离散的而产生偏差,我们对每个中心点附加预测了个局部偏移
所有类别 c 共享同个偏移预测,这个偏移同个 L1 loss来训练:

只会在关键点位置
做监督操作,其他位置无视。下面章节介绍如何将关键点估计用于目标检测。
4.目标作为点Objects as Points
令
是目标 k (其类别为
,我们用 关键点估计
来得到所有的中心点,此外,为每个目标 k 回归出目标的尺寸
。为了减少计算负担,我们为每个目标种类使用单一的尺寸预测
,我们在中心点位置添加了 L1 loss:

我们不将scale进行归一化,直接使用原始像素坐标。为了调节该loss的影响,将其乘了个系数,整个训练的目标loss函数为:
实验中,
,
,整个网络预测会在每个位置输出 C+4个值(即关键点类别C, 偏移量的x,y,尺寸的w,h),所有输出共享一个全卷积的backbone;对于每一种情况,backbone的特征通过单独的3×3卷积,ReLU和另一个1×1卷积。图4显示了网络输出的概述。第5节和补充材料包含其他建筑细节。

4.1: 从点到Bbox
在推理的时候,我们分别提取热力图上每个类别的峰值点。如何得到这些峰值点呢?做法是将热力图上的所有响应点与其连接的8个临近点进行比较,如果该点响应值大于或等于其八个临近点值则保留,最后我们保留所有满足之前要求的前100个峰值点。令
是检测到的 c 类别的 n 个中心点的集合。
每个关键点以整型坐标
的形式给出。
作为测量得到的检测置信度, 产生如下的bbox:
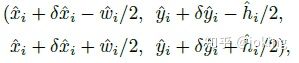
其中
是偏移预测结果;
是尺度预测结果;所有的输出都直接从关键点估计得到,无需基于IOU的NMS或者其他后处理。
4.2: 3D 检测
3D检测是对每个目标进行3维bbox估计,每个中心点需要3个附加信息:depth, 3D dimension, orientation。我们为每个信息分别添加head.
对于每个中心点,深度值depth是一个维度的。然后depth很难直接回归!我们参考【D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In NIPS, 2014.】对输出做了变换。
其中
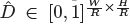
, 该通道使用了两个卷积层,然后做ReLU 。我们用L1 loss来训练深度估计器。
目标的3D维度是三个标量值。我们直接回归出它们(长宽高)的绝对值,单位为米,用的是一个独立的head :
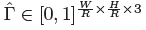
和L1 loss;
方向默认是单标量的值,然而其也很难回归。我们参考【A. Mousavian, D. Anguelov, J. Flynn, and J. Kosecka.
3d bounding box estimation using deep learning and geometry. In CVPR, 2017.】, 用两个bins来呈现方向,且in-bins回归。特别地,方向用8个标量值来编码的形式,每个bin有4个值。对于一个bin,两个值用作softmax分类,其余两个值回归到在每个bin中的角度。
4.3: 人姿态估计
人的姿态估计旨在估计 图像中每个人的k 个2D人的关节点位置(在COCO中,k是17,即每个人有17个关节点)。因此,我们令中心点的姿态是 kx2维的,然后将每个关键点(关节点对应的点)参数化为相对于中心点的偏移。 我们直接回归出关节点的偏移(像素单位)
,用到了L1 loss;我们通过给loss添加mask方式来无视那些不可见的关键点(关节点)。此处参照了slow-RCNN。
为了refine关键点(关节点),我们进一步估计k 个人体关节点热力图
,使用的是标准的bottom-up 多人体姿态估计【4,39,41】,我们训练人的关节点热力图使用focal loss和像素偏移量,这块的思路和中心点的训练雷同。我们找到热力图上训练得到的最近的初始预测值,然后将中心偏移作为一个grouping的线索,来为每个关键点(关节点)分配其最近的人。具体来说,令
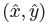
是检测到的中心点。第一次回归得到的关节点为:
我们提取到的所有关键点(关节点,此处是类似中心点检测用热力图回归得到的,对于热力图上值小于0.1的直接略去):
for each joint type j from the corresponding heatmap
然后将每个回归(第一次回归,通过偏移方式)位置
,考虑到只对检测到的目标框中的关节点进行关联。
5.实施细节Implementation details
我们实验了4个结构:ResNet-18, ResNet-101, DLA-34, Hourglass-104. 我们用deformable卷积层来更改ResNets和DLA-34,按照原样使用Hourglass 网络。

Hourglass
堆叠的Hourglass网络通过两个连续的hourglass 模块对输入进行了4倍的下采样,每个hourglass 模块是个对称的5层 下和上卷积网络,且带有skip连接。该网络较大,但通常会生成最好的关键点估计。
ResNet
Xiao et al. [55]等人对标准的ResNet做了3个up-convolutional网络来dedao更高的分辨率输出(最终stride为4)。为了节省计算量,我们改变这3个up-convolutional的输出通道数分别为256,128,64。up-convolutional核初始为双线性插值。
DLA
即Deep Layer Aggregation (DLA),是带多级跳跃连接的图像分类网络,我们采用全卷积上采样版的DLA,用deformable卷积来跳跃连接低层和输出层;将原来上采样层的卷积都替换成3x3的deformable卷积。在每个输出head前加了一个3x3x256的卷积,然后做1x1卷积得到期望输出。
Training
训练输入图像尺寸:512x512; 输出分辨率:128x128 (即4倍stride);采用数据增强方式:随机flip, 随机scaling (比例在0.6到1.3),裁剪,颜色jittering;采用Adam优化器;
在3D估计分支任务中未采用数据增强(scaling和crop会影响尺寸);
更详细的训练参数设置(学习率,GPU数量,初始化策略等)见论文~~
Inference
采用3个层次的测试增强:没增强,flip增强,flip和multi-scale(0.5,0.75,1.25,1.5)增强;我们。对于翻转,我们在解码边界框之前平均网络输出。对于多尺度,我们使用NMS来合并结果。这些增强会产生不同的速度 - 准确性权衡,如下一节所示。(For flip, we average the network outputs before decoding bounding boxes. For multi-scale,we use NMS to merge results.)
6. Experiments实验

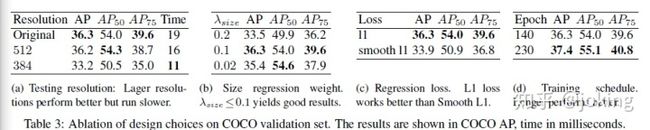
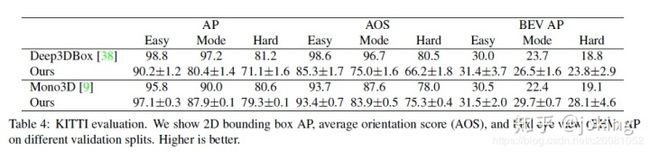


文章网络结构细节信息见下图:

7.总结
总之,我们提出了一个新的对象表示:作为点。我们的CenterNet对象检测器建立在成功的关键点估计网络的基础上,找到对象中心,并根据它们的大小进行恢复。该算法简单,快速,准确,端到端可区分,无需任何NMS后处理。这个想法很普遍,除了简单的二维检测外,还有广泛的应用。CenterNet可以在一个单一的前向传递中监视一系列其他对象属性,例如aspose,3D方向,深度和范围。我们最初的实验令人鼓舞,为实时物体识别和相关任务开辟了新的方向。