Pandas 学习
1.为什么使用Pandas
- pandas的优势
-
增强图表可读性
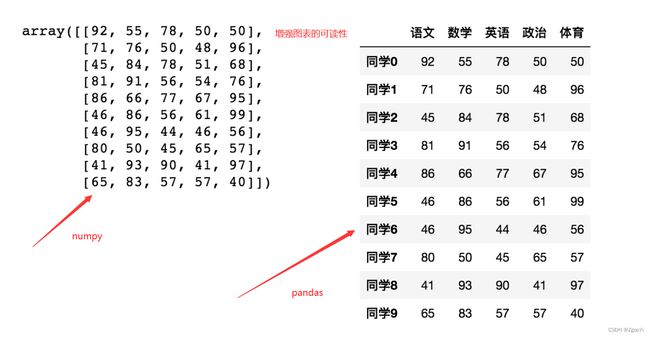
-
便捷的数据处理能力
-
-
读取文件方便
-
封装了Matplotlib、 Numpy的画图和计算
-
2.pandas的数据结构
Pandas中一共有三种数据结构, 分别为: Series、 DataFrame和MultiIndex(老版本中叫Panel ) 。
其中Series是一维数据结构, DataFrame是二维的表格型数据结构, MultiIndex是三维的数据结构。
2.1 Series
Series是一个类似于一维数组的数据结构, 它能够保存任何类型的数据, 比如整数、 字符串、 浮点数等, 主要由一组数据和与之相关的索引两
部分构成。

2.1.1 series 的创建
# 导入pandas
import pandas as pd
pd.Series(data=None, index=None, dtype=None)
参数:
data: 传入的数据, 可以是ndarray、 list等
index: 索引, 必须是唯一的, 且与数据的长度相等。 如果没有传入索引参数, 则默认会自动创建一个从0-N的整数索引。
dtype: 数据的类型

2.1.2 Series的属性
为了更方便地操作Series对象中的索引和数据, Series中提供了两个属性index和values

2.2.DataFrame
DataFrame是一个类似于二维数组或表格(如excel)的对象, 既有行索引, 又有列索引
- 行索引, 表明不同行, 横向索引, 叫index, 0轴, axis=0
- 列索引, 表名不同列, 纵向索引, 叫columns, 1轴, axis=1

2.2.1 DataFrame的创建
# 导入pandas
import pandas as pd
pd.DataFrame(data=None, index=None, columns=None)
参数:
index: 行标签。 如果没有传入索引参数, 则默认会自动创建一个从0-N的整数索引。
columns: 列标签。 如果没有传入索引参数, 则默认会自动创建一个从0-N的整数索引。
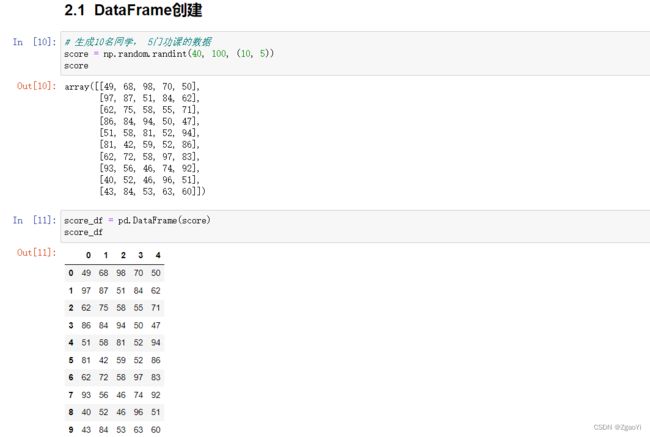

2.2.2 DataFrame的属性
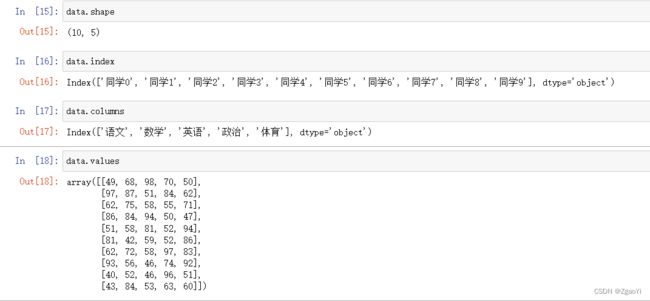

2.2.3 DatatFrame索引的设置
2.2.3.1以某列值设置为新的索引
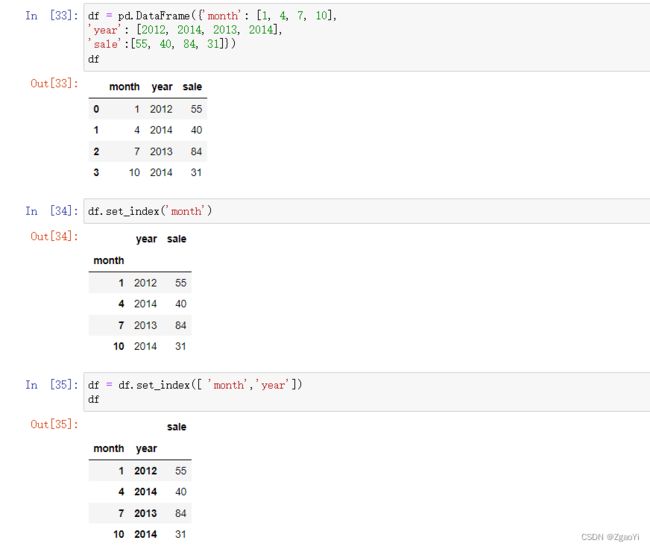
2.2.3.2 重设索引
reset_index(drop=False)
设置新的下标索引
drop:默认为False, 不删除原来索引, 如果为True,删除原来的索引值

2.3.MultiIndex与Panel
2.3.1 MultiIndex
MultiIndex是三维的数据结构;
多级索引(也称层次化索引) 是pandas的重要功能, 可以在Series、 DataFrame对象上拥有2个以及2个以上的索引。
2.3.1.1 multiIndex的特性

2.3.1.2 multiIndex的创建

2.3.2 Panel
2.3.2.1 panel的创建
class pandas.Panel (data=None, items=None, major_axis=None, minor_axis=None)
作用: 存储3维数组的Panel结构
参数:
data : ndarray或者dataframe
items : 索引或类似数组的对象, axis=0
major_axis : 索引或类似数组的对象, axis=1
minor_axis : 索引或类似数组的对象, axis=2

3 基本数据操作
# 读取文件
data = pd.read_csv("./data/stock_day.csv")
# 删除一些列, 让数据更简单些, 再去做后面的操作
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)

3.1 索引操作
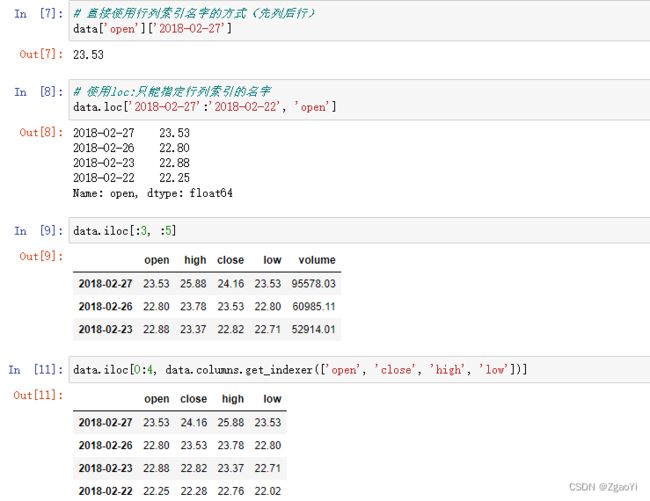
3.1.1 直接使用行列索引(先列后行)
- 获取’2018-02-27’这天的’close’的结果
- 结合loc或者iloc使用索引
- 使用ix组合索引
3.2 赋值操作

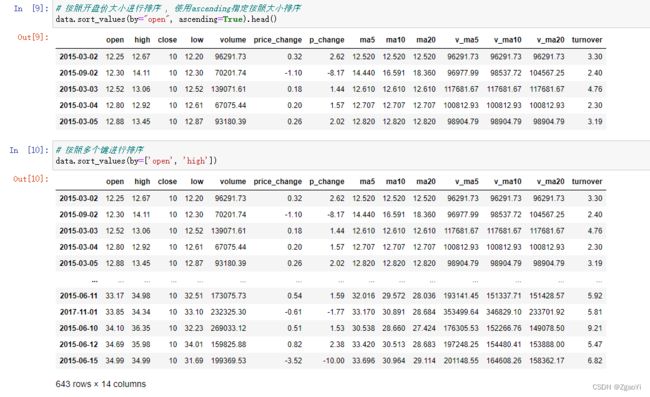
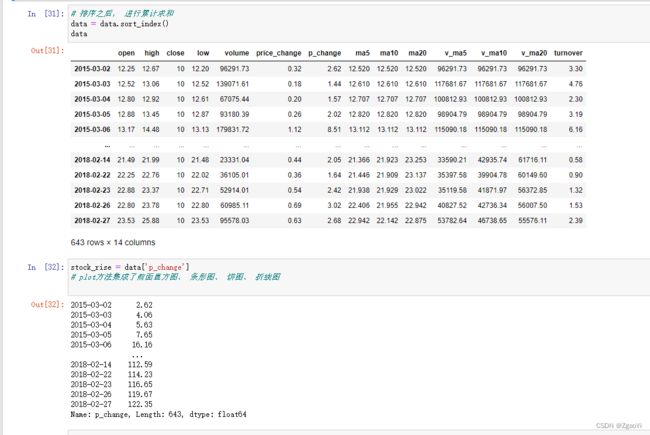
3.3 排序
排序有两种形式, 一种对于索引进行排序, 一种对于内容进行排序
3.3.1 DataFrame排序
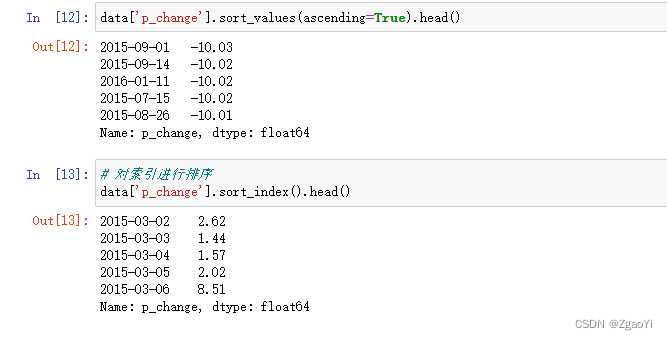
3.3.2 Series排序
- 使用series.sort_values(ascending=True)进行排序,series排序时, 只有一列, 不需要参数
- 使用series.sort_index()进行排序,与df一致
4 DataFrame 运算


4.3 统计运算
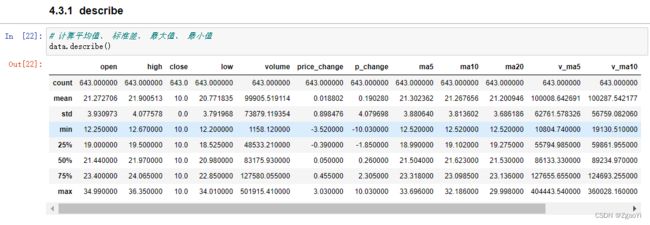
4.3.2 统计函数

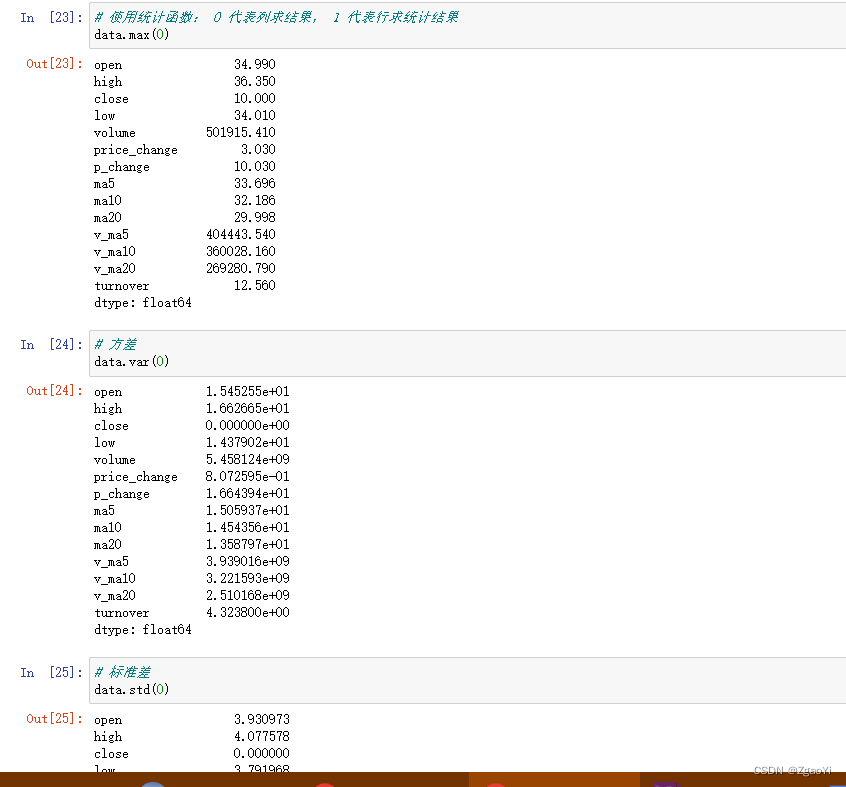

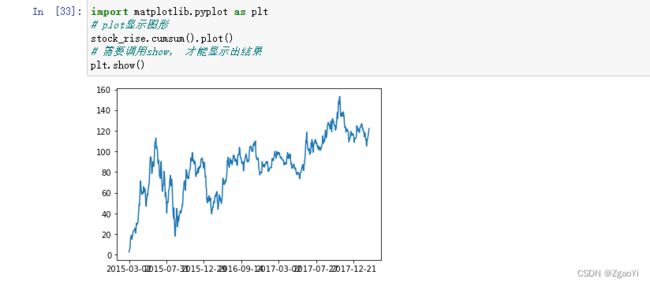
4.3.3 累计统计函数
5.文件读取与存储
我们的数据大部分存在于文件当中, 所以pandas会支持复杂的IO操作, pandas的API支持众多的文件格式, 如CSV、 SQL、 XLS、 JSON、
HDF5。
5.1 CSV
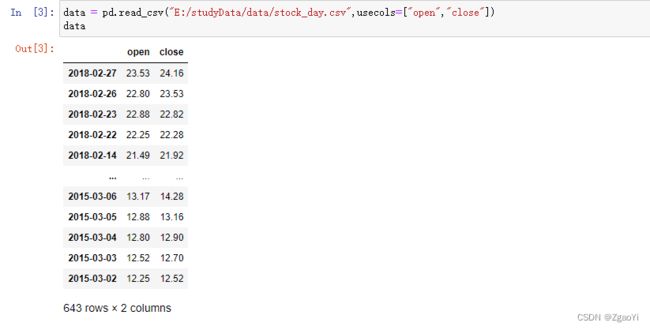
5.1.1 read_csv
pandas.read_csv(filepath_or_buffer, sep =‘,’, usecols )
filepath_or_buffer:文件路径
sep :分隔符, 默认用","隔开
usecols:指定读取的列名, 列表形式
- 举例: 读取之前的股票的数据
5.1.2 to_csv
DataFrame.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, mode=‘w’, encoding=None)
path_or_buf :文件路径
sep :分隔符, 默认用","隔开
columns :选择需要的列索引
header :boolean or list of string, default True,是否写进列索引值
index:是否写进行索引
mode:‘w’: 重写, ‘a’ 追加
# 选取10行数据保存,便于观察数据
data[:10].to_csv("E:/studyData/data/test.csv", columns=['open'])
5.2 hdf5

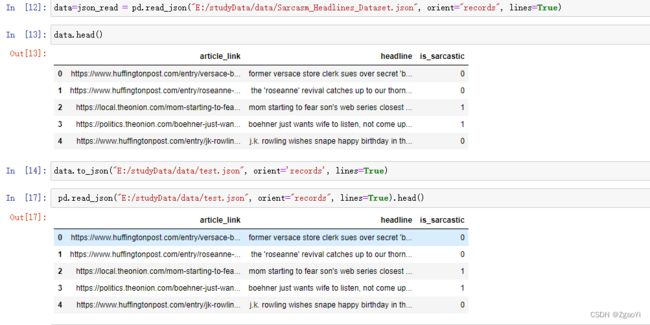
5.3 json
JSON是我们常用的一种数据交换格式, 前面在前后端的交互经常用到, 也会在存储的时候选择这种格式。 所以我们需要知道Pandas如何进行
读取和存储JSON格式。
6.数据高级处理
6.1 缺失值处理
6.1.1 如何处理nan
-
获取缺失值的标记方式(NaN或者其他标记方式)
-
如果缺失值的标记方式是NaN
- 判断数据中是否包含NaN:
- pd.isnull(df),
- pd.notnull(df)
- 存在缺失值nan:
- 1、 删除存在缺失值的:dropna(axis=‘rows’)
- 注: 不会修改原数据, 需要接受返回值
- 2、 替换缺失值:fillna(value, inplace=True)
value:替换成的值
inplace:True:会修改原数据, False:不替换修改原数据, 生成新的对象
- 判断数据中是否包含NaN:
-
如果缺失值没有使用NaN标记, 比如使用"? "
- 先替换‘?’为np.nan, 然后继续处理
6.2.1 电影数据的缺失值处理
6.2.1.1 存在缺失值nan,并且是np.nan
- 电影数据文件获取
# 读取电影数据
movie = pd.read_csv("./data/IMDB-Movie-Data.csv")
- 判断缺失值是否存在
pd.notnull(movie)
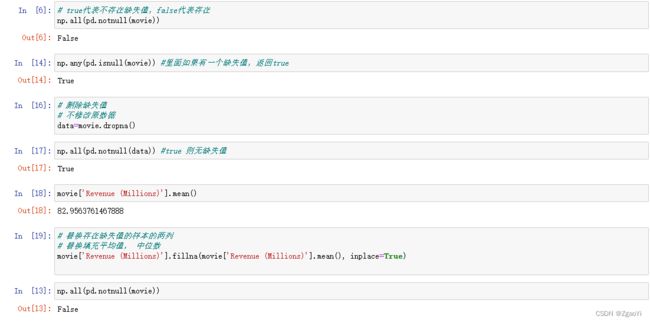
np.all(pd.notnull(movie)) # true代表不存在缺失值,false代表存在
np.any(pd.isnull(movie)) #里面如果有一个缺失值,返回true
# 删除缺失值
# 不修改原数据
data=movie.dropna()
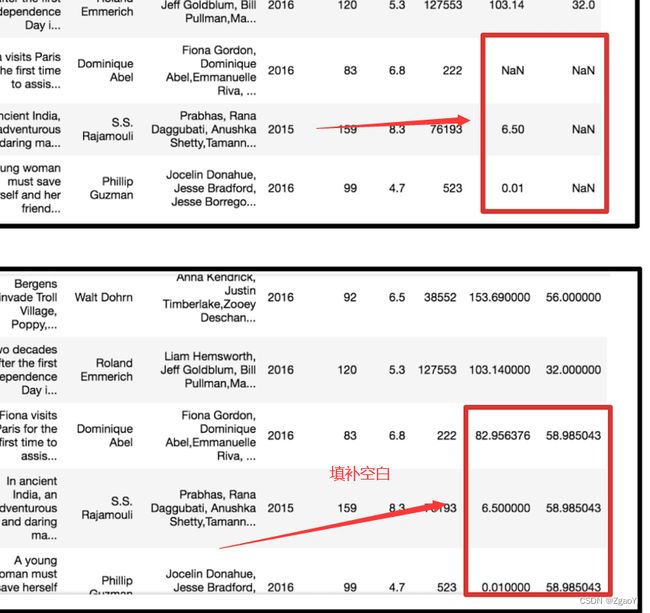
- 替换缺失值
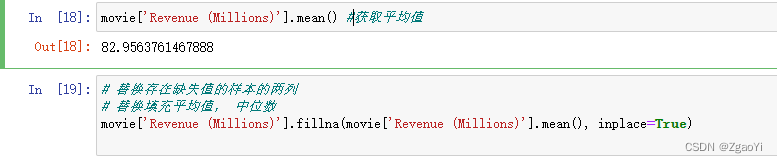
- 替换所有缺失值
for i in movie.columns:
if np.all(pd.notnull(movie[i])) == False:
print(i)
movie[i].fillna(movie[i].mean(), inplace=True)

6.2.1.2不是缺失值nan, 有默认标记的
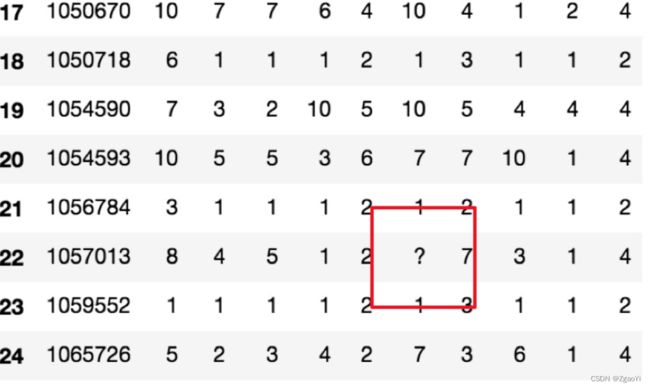
解决办法:
1、 先替换‘?’为np.nan
df.replace(to_replace=, value=)
to_replace:替换前的值
value:替换后的值
# 把一些其它值标记的缺失值, 替换成np.nan
wis = wis.replace(to_replace='?', value=np.nan)
2、 在进行缺失值的处理
# 删除
wis = wis.dropna()
总结:

6.2 数据离散化
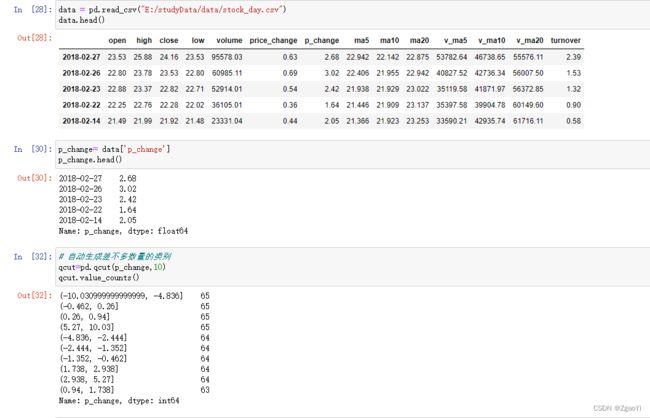
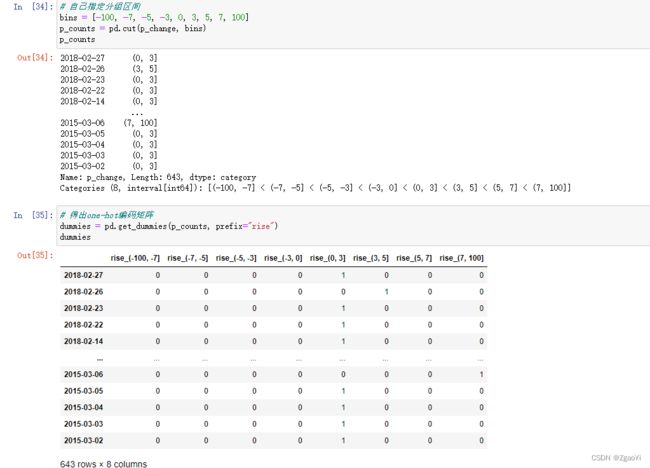
6.2…1股票的涨跌幅离散化
6.3 数据合并
应用pd.concat实现数据的合并
应用pd.merge实现数据的合并
6.3.1 pd.concat实现数据合并
pd.concat([data1, data2], axis=1)
按照行或列进行合并,axis=0为列索引, axis=1为行索引
6.3.2 pd.merge
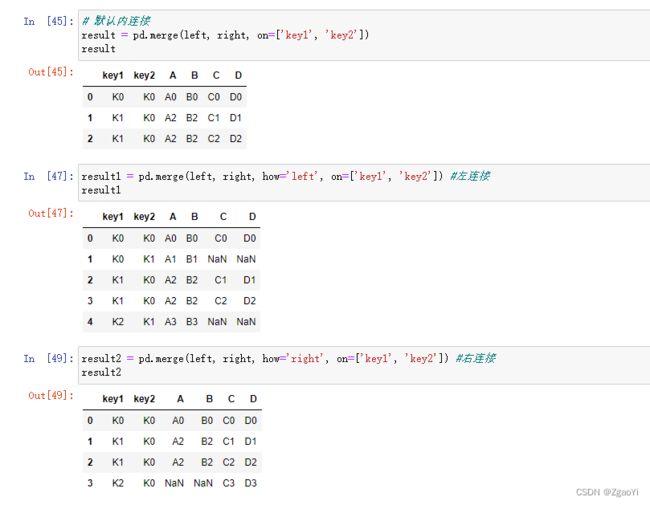
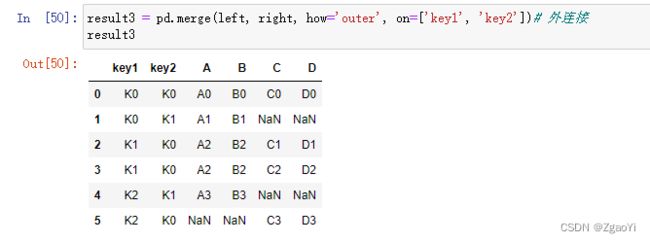
pd.merge(left, right, how=‘inner’, on=None)
可以指定按照两组数据的共同键值对合并或者左右各自
left : DataFrame
right : 另一个DataFrame
on : 指定的共同键
how:按照什么方式连接

6.3.2.1 pd.merge合并

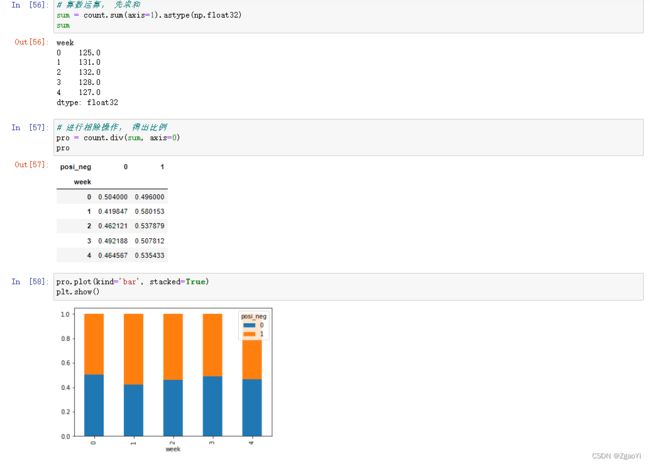
6.3.3 交叉透视表


6.3.4 分组聚合
