Mahout in action 中文版-2.推荐器的介绍-2.1~2.2
2 推荐器的介绍
本章概要:
Mahout中的推荐器
推荐器实战一瞥
推荐引擎精度与质量评估
基于一个真实数据集的测试:GroupLens
每天我们都会对一些喜欢的、不喜欢的甚至不关心的事物进行一些评价。这中行为往往是无意识的。你在收音机上听到一首歌,你可能会因为它的美妙或者难听而注意到它,也可能直接忽略。这样的情形也会非常普遍的发生在人们对于T恤、沙拉酱、滑雪场、发型、脸型或者电视节目。
尽管人们的口味多种多样,但是它遵从一定的模式。人们往往会喜欢和他们偏好相似的事物。比如我爱吃培根生菜番茄三明治,你可以猜到我也喜欢火鸡三明治,因为这两种三明治很相似。或者说,我们可以认为一个人很可能会喜欢一些相似的东西。
这些模式可以帮助我们预测一个人的好恶,而推荐就是预测人们喜好事物的模式,我们可以利用它来发现一些新的有价值的东西。
上面已经介绍了关于推荐的一些思路,这一章,我们将会用Mahout来体验一下如何去构建一个简单的推荐引擎,然后了解其原理,给你一个直观的感受。
2.1 什么是推荐(recommendation)
你购买这本书肯定是有原因的。或许是因为这本书和你所经常浏览的书挨的很近,于是翻了翻发现很有用,或许你看到和你一样很喜欢机器学习的同事的书架上也摆着这本书,也或许这个同事直接向你推荐过这本书。
虽然原因各不相同,但是最终效果都是你发现了新的东西:你通过和你兴趣相似的人来发现新的你所感兴趣的东西(如:来自同事的推荐)。另一方面,一些和你所喜欢的东西相似的事物,你往往也会喜欢(如:在书架和你喜欢的书摆放的很近的书)。事实上,这两种情形就刻画出了推荐引擎的两个基本算法:”user-based”和”item-based”。
2.1.1 协同过滤(Collaborative filtering),不是基于内容的推荐
严格的说,上述场景是协同过滤的例子——它仅仅基于已知的用户(users)与项目(items)的关系。这种技术不需要知道项目本身的属性特征,从某种角度讲这是它的一种优势。而且,这种推荐技术不关心项目本身是什么。
还有一些其他基于项目内容的推荐技术,这些往往被称作“content-based”。例如,一个朋友向你推荐一本书,这本书是钱钟书写的,这样就可以看做是基于内容的,因为这个推荐的理由是因为这本书的一个属性:作者。虽然Mahout对一些基于内容的推荐也提供了一些方法,但是Mahout没有对于这种框架的推荐直接实现。
这些基于内容的推荐技术本身并没有什么错,相反它在一些很专门的领域可以有很好的效果。而且也可以被当做很有意义的框架去实现。在构建一个关于书的”Content-Based”的框架时,首先要选定书的哪些特征作为属性,比如:页数、作者、出版商、颜色、字体等等。并且你还需要决定这些属性的重要程度如何。然而这种技术就很难在其他的推荐领域中适用,比如你用它去推荐一个披萨,显然不合适,因为披萨没有“页数”这样的属性。
因为这个原因,Mahout没有过多的去将这种推荐技术。不过这种类型的推荐Mahout是可以构建的,我们将在下一章看到一个约会网站用到的相关推荐技术。
到此,是时候该用Mahout体验一下协同过滤的威力了!
2.2 构建第一个协同过滤引擎
Mahout包括了几种推荐引擎,事实上它开始就是传统的基于用户和基于内容的推荐,当然它也实现了其他几种算法。不过现在我们要先探索一个基于用户的推荐器。
2.2.1 建立输入
开始探索的一个好的方法就是先找一个琐碎的小例子。数据的输入时推荐的基础。这些数据会以Mahout语言来表示一种“偏好”程度,因为推荐系统很擅长表示用户与项目之间的关联程度,这种“关联”即是所谓的“偏好”。在数据中,用户和项目显得尤为重要。一个偏好(preference)包含一个User ID 和一个 Item ID,然后再用一个值来代表偏好的程度。ID在Mahout中用整数表示,而偏好可以使任何数字类型的,值越大表示偏好程度越高。例如:我们把偏好程度分为五个档次:1-5,那么1可以表示非常讨厌,5代表非常喜欢。
新建一个文本用来存储输入数据,我们用1到5的整数来表示有五个用户,101到104来代表四本书,也就是说这些整数分别是用户个书的ID。每一项采用逗号隔开的方式写入。下面是一个数据的样例,文件名为intro.csv 。
清单2.1 输入数据文件intro.csv的内容

通过对文件数据的观察,我们发现user 1 和 5 的偏好差不多,他们共同喜欢book 101,而对102就差一些,对103更差。同样的1和4都喜欢101和103,User 1和User 2正好相反等等。下面这个图可以大致的说明上述数据的关系:
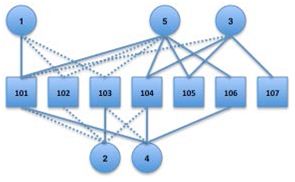
图 2.1 用户与项目关系图,虚线代表负关系(不喜欢),实线代表正关系(喜欢)
2.2.2 建立推荐器
你会向User 1推荐那一本呢?不是101,102或103——因为他已经知道这些书了,我们推荐给他的必须是他不知道的。直觉上我们知道4和5和1比较像,所以推荐给1 4和 5都喜欢的可能比较合理。也就是说104、105、106都在备选之列。而104的偏好为4.5和4,所以我们猜最应该推荐104。好吧,眼见为实,我们跑一下程序:
清单2.2 一个简单的基于用户的Mahout推荐器程序
package mia.recommender.ch02;
import org.apache.mahout.cf.taste.impl.model.file.*;
import org.apache.mahout.cf.taste.impl.neighborhood.*;
import org.apache.mahout.cf.taste.impl.recommender.*;
import org.apache.mahout.cf.taste.impl.similarity.*;
import org.apache.mahout.cf.taste.model.*;
import org.apache.mahout.cf.taste.neighborhood.*;
import org.apache.mahout.cf.taste.recommend er.*;
import org.apache.mahout.cf.taste.similarity.*;
import java.io.*;
import java.util.*;
class RecommenderIntro {
public static void main(String[] args) throws Exception {
DataModel model = new FileDataModel(new File("intro.csv")); A
UserSimilarity similarity = new PearsonCorrelationSimilarity (model
UserNeighborhood neighborhood =
new NearestNUserNeighborh ood (2, similarity, model);
Recommender recommender = new GenericUserBasedRecommender (
model, neighborhood, similarity); B
List<RecommendedItem > recommendations =
recommender.recommend(1, 1); C
for (RecommendedItem recommendation : recommendations) {
System.out.println(recommendation);
}
}
}
A 加载数据文件
B 建立推荐引擎
C 给User 1 推荐 1 个项目
为了简介,后续的代码我们会省略头部的imports、类声明、函数声明。只贴出程序中的核心代码。为了更好的可视化基本组件之间的关系,请看图2.2。不是所有的Mahout推荐器都想这样,因为某些会使用不同的组件。下图给出的是该例子中各组件之前的关系。
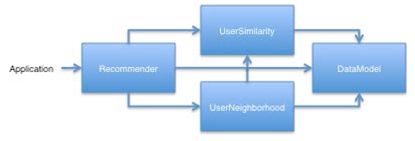
图2.2 基于用户的推荐器的组件简图
在后续章节要详细介绍上述组件之间,我们可以大致的总结一下他们在整个推荐器中所扮演的角色。DataModel负责存储和提供用户、项目、偏好的计算所需要的数据。UserSimiliarity提供了一些基于某种算法的用户相似度度量的方法。UserNeighborhood定义了一个和某指定用户相似的用户集合。最后,Recommender利用所有的组件来为一个用户产生一个推荐结果,另外他也提供了一系列的相关方法。
2.2.3 分析输出结果
用你所喜欢的IDE去运行这个程序,得出的结果应该如此:RecommendedItem [item:104, value:4.257081]
这个程序的要求是获取一个排名最高的推荐结果,结果只有一个。推荐器把104推荐给了User 1。更进一步,推荐器还给出了偏好的一个量化值4.3,因为这个值是所有推荐结果中最高的,所以被输出了出来。
结果看起来不太坏,值得被推荐的107并没有消失,只是因为107和一个口味和1不同的用户产生了关联。结果为104是在情理之中的,因为104的分数比106的要高。更进一步,104的“偏好指数”介于4.0与4.5之间也是合理的,因为4和5对104的偏好指数分别为4.0和4.5。
光从数据的表面很难知道正确结果,但是推荐引擎可以通过一些绝妙的方法给出很有说服力的结果。如果你觉得这个小小的程序从一堆杂乱的数据中给出了有用而且不明显的结果令你感到一阵愉悦的话,那么说明机器学习的世界是为你而存在的!
简单的说,像上面的小数据对于构建推荐系统是微不足道的。在现实生活中,数据是十分庞大的,而且充满了噪音。例如,一个新闻网站为读者推荐新闻文章。偏好通过点击数来计算,但是这样得来的偏好指数很可能是假的——也许某个读者点击进去发现自己不喜欢或者是点击错误才进去的。也有可能很多的点击操作是在登录之前发生的,这样我们就不能把这些点击数与某个用户关联起来。另外,你也可以试想一下数据量,很可能在一个月中会有上亿计的点击数。
高效准确的从数据集中得出推荐结果是非常重要的。接下来我们将以案例研究的方式去呈现Mahout是如何解决这些问题的。这些案例将会展示为何一些标准方法会产生非常差的结果,或者吃掉了很多内存和CPU,另外也会展示如何去配置和自定义Mahout来提升它的性能。
(翻译 By 花考拉)