Mahout in action 中文版-3.推荐器的数据表达-3.2
3.2 内存中的数据模型
DataMode是推荐器总输入数据的一种抽象。推荐算法需要用它来实现高效的访问数据。例如,DataModel可以在输入数据中提供一列用户,或者提供与某项目关联的所有偏好值,也或者提供对一个项目集合感兴趣的所有用户ID。本小节精选出一些关于DataModel的API来做一番介绍,这些API可以再官方文档中查阅到详细说明。
3.2.1 GenericDataModel
GenericDataModel是最简单的数据模型的实现,它是“内存版”的。当你希望在内存中构建你的数据模型时,它比较适合你,而非基于硬盘中的文件和数据库。它所接收的偏好是以FastByIDMap存储用户ID去映射PreferenceArrays而实现的。
清单3.2 用GenericDataModel去定义输入数据模型的示例代码
FastByIDMap<PreferenceArray> preferences =
new FastByIDMap<PreferenceArray>();
PreferenceArray prefsForUser1 = new GenericUserPreferenceArray(10); A
prefsForUser1.setUserID(0, 1L);
prefsForUser1.setItemID(0, 101L); B
prefsForUser1.setValue(0, 3.0f); B
prefsForUser1.setItemID(1, 102L);
prefsForUser1.setValue(1, 4.5f);
… (8 more)
preferences.put(1L, prefsForUser1); C
DataModel model = new GenericDataModel(preferences); D
A 为用户1定义一个PreferenceArray
B 添加10个偏好
C 将偏好集合与用户1关联
D 创建数据模型对象DataModel
GenericDataModel会占用多少内存呢?存储偏好是其主要的内存消耗。相关测试表明,每个偏好平均在Java heap中占28字节。其中除了包含这些信息还包含了一些索引。如果你愿意的话可以在加载一个GenericDataModel后调用System.gc()几次,然后比较Runtime.totalMemory()和Runtime.freeMemory()的结果。虽然方法比较粗糙,但是它给出了对数据内存消耗合理的解释。
3.2.2 基于文件的数据
一般情况下你可能不会直接使用GenericDataModel,而你在使用FileDataModel时会遇到它,因为FileDataModel会从文件中读取数据然后存放在内存中,这时GenericDataModel就登场了。
一般的文件都会像第一章中讲述的那样,存放着用逗号隔开的数据记录,每一行都包括一个用户ID、项目ID、偏好指数。标签文件(Tab-separated)、“.zip”或“.gz”文件也是如此。顺便提一句,采用压缩文件个很不错的方法,因为数据量往往比较大,压缩显得格外节约空间。
3.2.3 Refreshable组件
当谈了关于加载数据的一些内容,重新加载数据也是非常有用的,相关接口为Refreshable。它由一些推荐相关组件实现。它仅仅有一个方法refresh(Collection<Refreshable>)。它可以在询问最新数据的依赖关系后,来简单的请求重新载入组件、重新计算以及刷新自己的状态。例如,一个Recommender对象可以对它所使用的DataModel调用refresh()来对数据重新计算内部索引。循环依赖和共享依赖被很好的处理,如图3.3所示:
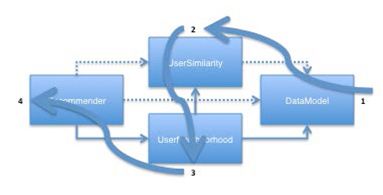
图3.3 基于用户的推荐系统各组件之间的简单依赖关系,箭头所示为组件刷新数据的次序
注意一点,出于性能的考虑,FileDataModel只有被请求更新时才会重新加载数据文件,它不会自动的检测文件更新或者定期的去加载文件。这也正是为何会存在一个refresh()方法。你可能不太愿意去使用FileDataModel本身或者其他依赖于数据的对象去调用refresh(),那么用推荐器直接去调用可能是个不错的选择:
清单3.3 为推荐系统触发一次更新
DataModel dataModel = new FileDataModel(new File("input.csv");
Recommender recommender = new SlopeOneRecommender(dataModel);
...
recommender.refresh(null); A
A 先更新DataMode,然后再更新它自己
关于规模的讨论遍及本书的每个角落,我们将强调一个关于FileDataModel对象的另一个重要特性:“更新文件”。文件的更新往往是很少部分的更新,或者说,上亿条数据之中可能才有一条。如果对于仅有少量更新的大文件完全的拷贝,将是毫无效率而言的。
3.2.4“更新文件”(Update files)
FileDataModel支持一种“更新文件”。这是一种在读取主数据文件之后可以对其进行重写的文件。它可以表示:新的数据记录被添加;已存在的记录被更新,而被删除的数据吧偏好指数置空即可。
举了例子,下面是一个“更新文件的例子”:
清单3.4 更新文件样例
1,108,3.0
1,103,
上述文件内容代表更新(添加)用户1对项目108的偏好值3.0,然后删除用户1对项目103的偏好记录。
这些“更新文件”必须存在于主数据文件的所在目录中,它们的名称需要以主数据文件的前缀相一致。如果主数据文件名为foo.txt.gz,那么更新文件的名字应该为foo.1.txt.gz和foo.2.txt.gz。需要指出的是,这些数据文件可以是压缩的。
3.2.5 基于数据库的数据
有时候数据量可以达到连内存也装不下的地步。一旦偏好记录达到上千万的级别,内存就需要几千兆字节的空间。这样的内存在一些条件下是无法满足的。
还好Mahout支持从数据库中获取数据。Mahout中的很多类都是为了在数据库中去计算数据而实现的。
需要注意的是,在数据库中运行不同量级的推荐器要比在内存运行慢得多。这不是数据库的错;经过恰当的配置,数据库在索引和检索信息方面的效率可以表现的十分优秀,但是相比之下,它的检索、整理、序列化、传输以及反序列化过程的开销还是要比优化后内存中的数据结构要大得多。这些作为数据推进器大大提升了推荐算法的速度。除了在别无选择或者数据量不大并且因为集成需要而使用一张表格的数据的时候,它还是十分令人满意的。
3.2.6 JDBC与MySQL
我们可以通过JDBCDataModel来访问偏好数据。它的唯一子类MySQLJDBCDataModel.用来访问MySQL 5.x。它可以很好的访问这一系列版本的MySQL,甚至其他的数据库,因为它内部使用了ANSI SQL。如果需要的话,创建一个变种版本也不是很难,只要你用特定数据库的SQL语法。
表3.1 ‘taste_preferences’在MySQL中的默认表模式

默认的,程序认为所有的偏好信息都存在taste_preferences表中,字段user_id、item_id、preference分别代表了用户ID、项目ID和偏好指数。
3.2.7 由JNDI进行配置
另外我们假设包含这个表的数据库也可以被一些在JNDI中注册的DataSource对象访问,叫做jdbc/taste。什么是JNDI,你会有这个疑问吗?如果你在一个Web应用程序中应用推荐引擎,而且用了servlet容器,像Tomcat或者Resin,那么你很可能已经间接的用到它了。如果你在Tomcat上配置过数据库(server.xml),那么你将会发现典型配置中会出现JNDI的身影。你可以把你的数据库配置成jdbc/taste,这样JDBCDataModel就可以用了。下面是一段有用的Tomcat上的配置片段:
清单:3.5 Tomcat上的JNDI配置
<Resource
name="jdbc/taste"
auth="Container"
type="javax.sql.DataSource"
username="user"
password="password"
driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/mydatabase"/>
上面的一些默认名字可以根据你的环境重写。你不需要对数据库和它的字段进行命名。
3.2.8 由代码方式配置
你也可以不必用JNDI进行配置。下面有个很有用的关于配置MySQLJDBCDataModel的例子,它使用了MySQL的连接驱动(http://www.mysql.com/products/connector/)以及和一个自定义表格的DataSource。
清单 用代码配置DataSource
MysqlDataSource dataSource = new MysqlDataSource();
dataSource.setServerName("my_database_host");
dataSource.setUser("my_user");
dataSource.setPassword("my_password");
dataSource.setDatabaseName("my_database_name");
JDBCDataModel dataModel = new MySQLJDBCDataModel(
dataSource, "my_prefs_table", "my_user_column",
"my_item_column", "my_pref_value_column");
上面是为推荐引擎访问数据库的所有代码。你通过它会得到一个匹配的DataModel。然而在MySQLJDBCDataModel相关文档中声明过,在为推荐引擎正确配置数据库和数据驱动时,应该尤为注意:
用户ID和项目ID都不能为空,而且需要建立索引
用户ID和项目ID为联合主键
列的数据类型在Java中应为long和float型。在MySQL中应为BIGINT和FLOAT类型
注意调优缓存和查询缓存(查看javadoc)
使用MySQL的连接驱动时,应该注意一些参数值的设置,例如cachePreparedStatements要设置为true。然后参照javadoc查看建议值设置
上述内容基本涵盖了DataModel在推荐引擎框架中的基本应用。另外有一点应该提一下:有时候偏好值是可以为空的。可能你觉得很奇怪,因为偏好值是一条记录的最核心的数据。然而有时候这种表达也是相当有用的。
(翻译 By 花考拉)