第五章 数据库设计和事物
1.练习
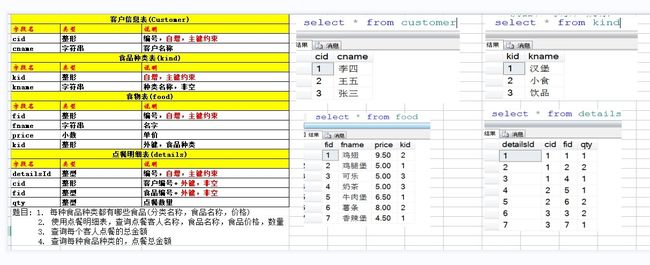
#建表
create table customer(
cid int primary key auto_increment,
cname char(10)
);
create table kind(
kid int primary key auto_increment,
kname varchar(10)
);
create table food(
fid int primary key auto_increment,
fname varchar(5),
price decimal(5,2),
kid int
);
create table details(
detaildId int primary key auto_increment,
cid int,
fid int,
qty int,
constraint fk_cid foreign key(cid) references customer(cid),
constraint fk_fid foreign key(fid) references food(fid)
);#插入数据
insert into customer
select 1,'李四' union
select 2,'王五' union
select 3,'张三';
insert into kind(kname)
value ('汉堡'),('小食'),('饮品')
insert into food(fname,price,kid)
value
('鸡翅',9.50,2),
('鸡腿堡',5.00,1),
('可乐',5.00,3),
('奶茶',5.00,3),
('牛肉堡',6.50,1),
('薯条',8.00,2),
('香辣堡',4.50,1)
insert into details(cid,fid,qty)
value
(1,1,1),
(1,2,2),
(1,4,1),
(2,5,1),
(2,6,2),
(3,3,2),
(3,7,1)#每种分类都有哪些食品(分类名称,食品名称,分类价格)
select (select kname from kind where kid = f.kid),fname,price
from food f
order by kid;
#使用点餐明细表,查询点餐客人名称,食品名称,食品价格,数量
select (select cname from customer where cid = d.cid),
(select fname from food where fid = d.fid),
(select price from food where fid = d.fid),
qty
from details d;
#查询每个客人点餐的中金额
select (select cname from customer where cid = d.cid),
sum(qty*(select price from food where fid = d.fid))
from details d
group by cid;
#查询每种食品分类的点餐总金额
select (select kname from kind where kid =f.kid) ,
sum(price * (select qty from details where fid = f.fid))
from food f
group by f.kid;2.数据库三大范式(设计规则)
范式:Normal Format,符合某一种级别的关系模型的集合,表示一个关系内部各属性之间的联系的合理化程度,一个数据库表之间的所有字段之间的联系的合理性。
①范式是离散数学里的概念;
②范式目标是在满足组织和存储的前提下使数据结构冗余最小化;
③范式级别越高,表的级别就越标准。
目前数据库应用到的范式有一下几层:
①第一范式:1NF
②第二范式:2NF
③第三范式:3NF
除此以外还有BCNF范式:4NF,5NF
一个数据库表设计的是否合理,要从增删改查的角度去思考,操作是否方便。
2.1 第一范式(1NF)
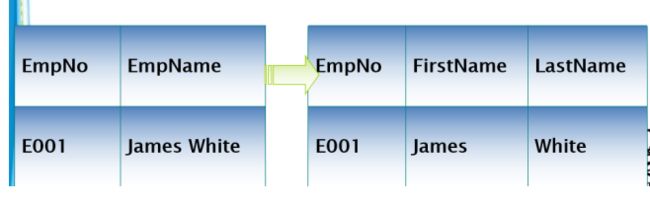
确保每一列的原子性;如果每列都是不可再分的最小单位,即满足第一范式。
比如: 外国人的名字可以分为FirstName和LastName,所以设计表的时候要把名字分开。
2.2 第二范式(2NF)
在满足第一范式的基础上,确保每列都与主键相关,不能出现部分依赖,即满足第二范式。
第二范式处理冗余数据的删除问题,当某张表中的信息依赖于该表中其它的不是主键部分的列的时候,通常会违反第二范式。

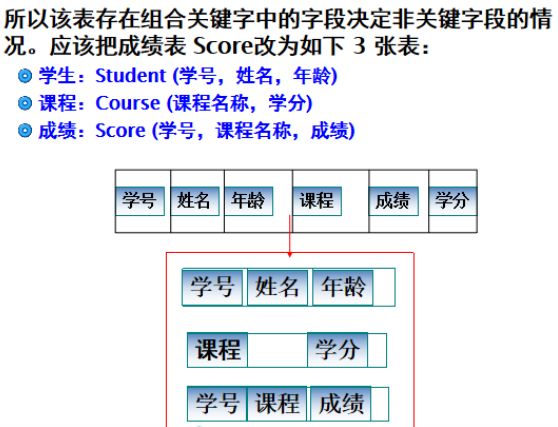
2.3 第三范式(3NF)
在满足了第二范式的基础上,并且确保每列都与主键直接相关而不是间接相关,则满足第三范式。
假设A,B,C是关系R的3个属性,如果A->B且B->C,则通过这个依赖关系,可以得出A->C,如上所述,依赖A->C是传递依赖。

在设计数据库的时候,要在满足自己需求的前提下,尽可能的满足三大范式。
3. 表间的关系
①一对一关系: 一个学号对一个姓名
在设计数据库时如果是一对一关系,直接设计成一张表(如果在字段非常多的情况下,可以做合理的分表);
②一对多(多对一)关系: 一个老师多个班级
设计时主要是通过外键关联;
③多对多关系: 学生对课程
设计数据库时,多对多关系,需要一个中间表进行关联。
4. 事物管理
4.1 为什么需要事物管理
事务是指逻辑上的一组操作,组成这组操作的各个单元,要不全成功要不全失败,即一组sql中哪怕有一条失败也会失败。
默认情况下,mysql的事务是自动提交的,也就是执行了增删改语句之后,数据直接持久化到磁盘上,不能撤销,但是如果改为手动事务之后,更新过的数据,在没有使用commit提交时,可以通过roollback进行撤回。
4.2 使用事务解决问题
转账案例:张三给李四转账
#创建银行帐号表
create table bank
(
bid int primary key auto_increment,
account varchar(20),
money int
)
select * from bank;
insert into bank
(account,money)
values
('张三',10000),
('李四',10000)
处理1:
#开启事务
start transaction;
update bank
set money = money - 3000
where account='张三'
select * from bank
#在向李四转钱之前,发生错误了,此时回滚事务
rollback;处理2:
#开启事务
start transaction;
update bank
set money = money - 3000
where account='张三'
update bank
set money = money + 3000
where account= '李四'
select * from bank
#提交事务
commit;
4.3 数据库事务的原理
如果不写start transaction/begin;和commit;此时事务默认开启自动提交;在数据库中,事务都是自动提交的,事务的自动提交就是执行语句完成之后就立刻持久化到数据库中。
start transaction/begin;开始事务
rollback;回滚事务
commit;提交事务
4.4 事务的特征ACID
① 原子性(Atomicity)
事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节,事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有发生一样.也就是说事务是一个不可分割的整体,就像化学中学过的原子,是物质构成的基本单位;
② 一致性(Consistency)
事务开始前和结束后,数据库的数据完整性约束没有被破坏,事务前后操作数据是一致的;(如:A向B转账,不可能A扣了钱,B却没收到)
③ 隔离性(Isolation)
一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰,两个事务之间是有隔离级别,隔离级别的不同会导致出现不同的问题;(产生的三种问题:脏读,幻读,不可重复读)
④ 持久性(Durability)
持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的,接下来的其他操作或故障不应该对其有任何影响。
4.5 事务的并发问题
数据库事务无非就两种: 查询数据的事务(select)、更新数据的事务(update,insert)
在没有事务隔离控制的时候,多个事务在同一时刻对同一数据的操作可能就会影响到结果,通常有四种情况:
①两个更新事务同时修改一条数据时,会出现数据丢失,绝对不允许出现;
②一个更新事务更新一条数据时,另一个读取事务读取了还没提交的更新,这种情况下会出现读取到脏数据;
③一个读取事务读取一条数据时,另一个更新事务修改了这条数据,这时就会出现不可重现的读取;
④一个读取事务读取时,另一个插入事务插入了一条新数据,这样就可能多读出一条数据,出现幻读。
前三种是对同一条数据的并发操作,对程序的结果可能产生致命影响,尤其是金融等实时性,准确性要求极高的系统,绝不容许这三中情况的出现。
事务的并发问题:
①脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
②不可重复读:事务 A 多次读取同一数据,事务B在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果不一致
③A事务查询了某个Id的记录,发现为空,准备插入该编号的记录,此时B事务先做了插入,并做了提交,此时A事务插入同编号的记录时触发了主键重复的异常,对于A事务而言,第一次读的结果就像发生了幻觉。
不可重复读侧重于修改,幻读侧重于新增或删除,解决不可重复读的问题只需锁住满足条件的行,解决幻读需要锁表。
4.6 MySQL事务隔离级别(用于解决事务并发问题)
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
| 未提交读(read-uncommitted) | 是 | 是 | 是 |
| 不可重复读(read-committed) | 否 | 是 | 是 |
| 可重复读(repeatable-read) | 否 | 否 | 是 |
| 串行化(serializable) | 否 | 否 | 否 |
对于MySQL的Innodb的默认事务隔离级别是重复读(repeatable read),可以通过下面的命令查看:
mysql> SELECT @@tx_isolation;--5.7版本
mysql> SELECT @@transaction_isolation; --8.0版本
#设置mysql的隔离级别:
#set session transaction isolation level 设置事务隔离级别
#设置read uncommitted级别:
set session transaction isolation level read uncommitted;
#在该隔离级别下,并发事务可以读取未提交的数据,可能导致脏读、不可重复读、幻读等问题
#设置read committed级别:
set session transaction isolation level read committed;
#在该隔离级别下,并发事务只能读取提交过的数据,可以避免脏读问题,但是可能导致不可重复读、幻读等问题,这是大多数数据库系统的默认隔离级别(但不是MySQL默认的)
#设置repeatable read级别:
set session transaction isolation level repeatable read;
#在该隔离级别下,在同一事务中多次查询数据都能保证一致,可以避免不可重复读问题,但是可能导致幻读等问题
#设置Serializable(可串行化)
set session transaction isolation level serializable;
# 这是最高的隔离级别,它通过强制事务排序,使之不可能相互冲突,从而解决幻读问题,简言之,它是在每个读的数据行上加上共享锁,在这个级别,可能导致大量的超时现象和锁竞争