7.pytorch自然语言处理-循环神经网络与分词
一、基础知识
1、tokenization分词
分词,分出的每一个词语叫做token
*清华大学API:THULAC;或者直接用jieba
可以切分为词语,或者完全分成一个一个字
2、N-gram
表示把连续的N个词语作为特征,帮助获取词语特征的方法,感觉类似于卷积神经网络中的池化操作,将特征选择放大
import jieba
text="分词 >_<,英文tokenization,也叫word segmentation,是一种操作,它按照特定需求,把文本切分成一个字符串序列(其元素一般称为token,或者叫词语)。"
cuted=jieba.lcut(text)#cut结果是一个生成器,lcut结果直接是一个列表
[cuted[i:i+2] for i in range(len(cuted)-1)]#这里将连续的两个词语作为特征
#cuted[i:i+2],len(cuted)-1是连续两个词语。N=3就-2输出:
[['分词', ' '],
[' ', '>'],
['>', '_'],
['_', '<'],
['<', ','],
[',', '英文'],
['英文', 'tokenization'],
['tokenization', ','],
[',', '也'],
['也', '叫'],
['叫', 'word'],
['word', ' '],
[' ', 'segmentation'],
['segmentation', ','],
[',', '是'],
['是', '一种'],
['一种', '操作'],
['操作', ','],
[',', '它'],
['它', '按照'],
['按照', '特定'],
['特定', '需求'],
['需求', ','],
[',', '把'],
['把', '文本'],
['文本', '切'],
['切', '分成'],
['分成', '一个'],
['一个', '字符串'],
['字符串', '序列'],
['序列', '('],
['(', '其'],
['其', '元素'],
['元素', '一般'],
['一般', '称为'],
['称为', 'token'],
['token', ','],
[',', '或者'],
['或者', '叫'],
['叫', '词语'],
['词语', ')'],
[')', '。']]比较好的参考博客:自然语言处理NLP中的N-gram模型_蕉叉熵的博客-CSDN博客_n-gram
但是N-gram存在文本长度增加参数空间爆炸式增长问题,不适用于我的数据。应该使用word2vec
3、VSM空间向量模型
用连续的稠密向量去刻画一个word的特征,并建立一个从向量到概率的平滑函数模型,使得相似的词向量可以映射到相近的概率空间上,即向量空间模型(Vector Space Model,以下简称VSM)。
基于Bag of Words Hypothesis,构造term-document矩阵,每个行表示词典中的一个词,列表示训练语料中的文章,则可以提取行向量作为语义向量。
类似地,可以基于Distributional Hypothesis构造一个word-context的矩阵,term-document矩阵会给经常出现在同一篇document里的两个word赋予更高的相似度;而word-context矩阵会给那些有着相同context的两个word赋予更高的相似度。后者相对于前者是一种更高阶的相似度,因此在传统的信息检索领域中得到了更加广泛的应用。不过,这种co-occurrence矩阵仍然存在着数据稀疏性和维度灾难的问题。
4、word2vec【感觉很有用但是没咋看懂】
CBoW模型(Continuous Bag-of-Words Model)等价于一个词袋模型的向量乘以一个embedding矩阵,从而得到一个连续的embedding向量
5、文本向量化
方式:转化为one-hot编码//转为word-embedding
-
one-hot编码
将每一个token用一个长度为N的向量进行表示,但是结果是稀疏矩阵,占用巨大空间。
-
word-embedding
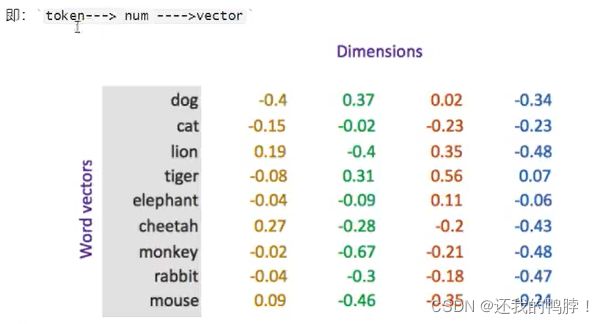
使用浮点型稠密矩阵进行表示,向量会使用不同的维度表示,得到m行n列矩阵。(100,256,300)。其中向量中的每一个值都是超参数,初始值随机生成。将文本中每一个词语转化为向量,句子用向量表示(相加求均值等)
首先将token用数字表示,然后再用向量表示。向量的每个维度都是训练出来的值。
#torch.nn.Embedding(num_embeddings,embedding_dim)
embedding=nn.Embedding(vocab_size,300)#首先实例化
input_embeded=embedding(input)#获取input数据embedding操作之后的结果其中,num_embeddings表示词典的大小
embedding_dim表示embedding的维度,即不重复词语的个数
得到的结果可以理解成,原来是一个数字表示一个词,现在变成一个向量,也就是二维数据变成三维了。
二、情感分类
1、数据集准备
如何完成基础的dataset构建与dataloader准备
batch中文本长度不一致,如何处理成相同长度
如何将batch中的文本转为数字序列
关于re.sub函数的介绍:flag还有后面S的含义
python正则表达式 re.sub的各个参数的详细解释_林新发的博客-CSDN博客_python re sub
2、模型
3、训练
4、评估