每日刷题:链表 oj (二)
目录
一、链表分割
二.链表的回文结构
三. 相交链表
一、链表分割
细节要求:不能改变原来数据顺序。
方法一:建立一个哨兵位(新头节点),将表中的小于 X 的数据节点依次链接在新节点后,形成新链表,然后再将剩余节点(大于X的节点)链接在新链表后 。

实现细节:1.因为要将小于的数据节点按原顺序链接在一起,当抽出节点时,要记得将前后节点 链接,(形成小节点链接在一起,大节点链接在一起的效果)
2.因为要保持分割后的数据顺序不变,所以,最后要链接第一个大于X的节点,
进而链接余下所有大于X的节点,否则会漏掉数据。
3.有两个特殊情况,全小于或全大于X的情况,只返回原链表。
ListNode* partition(ListNode* pHead, int x) {
// write code here
ListNode* first ,*New,*Last,*Next;
Last = New = first = Next = NULL;
New = (struct ListNode*)malloc(sizeof(struct ListNode));//新建哨兵位
New->next = pHead;
ListNode* tem = New;
for (int i = 1; pHead; pHead = Next)
{
Next = pHead->next;
if (i && pHead->val >= x) //遇到大于的
{
first = pHead;
i--;
Last = pHead; //这里Last记录第一个大于X的节点
}
if (pHead->val < x) //遇到小于的
{
New->next = pHead;
if(Last) //判断是否有大于X的节点
Last->next = pHead->next;
New = New->next;
}
else
Last = pHead;
}
if (first) //(如果不是全小于的情况)
New->next = first; //就链接剩余所有大于X的节点
return tem->next;
}二.链表的回文结构

解题:方法一 和 方法二
(回文结构:一个数列反转后与原数列相同,如:1 2 1 和 1 2 2 1)
方法一:由于链表长度有限(<=900),定义一个数组,存入链表数据,将数组数据倒着与原链 表相比(就是判断反转的它和原来的它是否相同)。
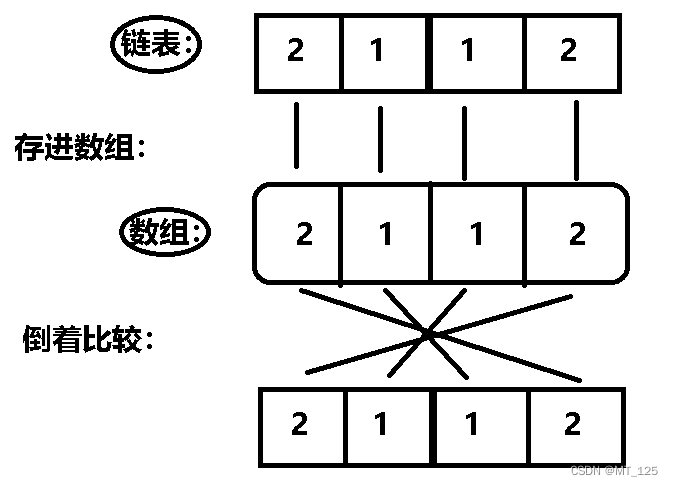
bool chkPalindrome(ListNode* A) {
// write code here
int arr[900] = { 0 };
struct ListNode* Tem = A;
int i = 0;
for (; Tem; Tem = Tem->next, i++)
{
arr[i] = Tem->val; //存入数组
}
i--;
for (; i != -1; i--, A = A->next) //倒着遍历数组
{
if (arr[i] != A->val) //倒着比较
{
return false;
}
}
return true;
}(但是方法一:空间复杂度为O(n),方法二可以达到O(1))
方法二:回文结构其实是一种对称结构,1 2 2 1 和 1 2 3 2 1 都是回文结构
方法一中的倒置对比,其实就是将数列的前一半数据和逆序的后一半数据进行对比
(只不过比较了两次:正前半和逆后半比较;正后半和逆前半比较)
所以,我们可以直接将数列的正序的前半段和逆序的后半段比较一次就OK了。
运用快慢指针,找到中间位置,从中间位置划分,将后半段数据逆序,然后于前半段比较。
实现细节:1. 不同的中间位置:链表数据个数不同,中间位置不同。
2. 由于要进行逆序,原链表的结构会发生改变
3. 逆序后结构的改变,使得要定义一个新的中间节点
4. 遍历停止的条件,如下图:
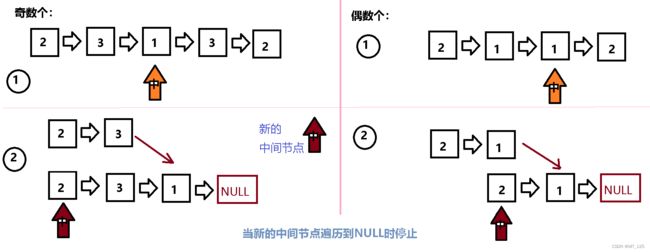
//找中间节点
struct ListNode*Mid(struct ListNode*head)
{
struct ListNode* fast = head;
struct ListNode* slow = head;
for(;fast->next&&fast->next->next;fast = fast->next->next,slow = slow->next);
if(fast->next)
return slow->next;
return slow;
}
//逆序
struct ListNode*reverse(struct ListNode*head)
{
struct ListNode* Last = NULL,*Next = head->next;
for(;head;head = Next)
{
Next = head->next;
head ->next = Last;
Last = head;
}
return Last;
}
//判断回文
bool chkPalindrome(ListNode* A) {
// write code here
struct ListNode* mid = Mid(A); //找中间节点
struct ListNode* head = A;
struct ListNode* New_mid = reverse(mid); //找到新的中间节点
for(;New_mid;New_mid = New_mid->next,head = head->next)
{
if(head->val != New_mid->val) //判断
return false;
}
return true;
}三. 相交链表

相交的节点(就是,地址相同的同一个节点)
解题:方法一 和 方法二
方法一:暴力解题:双层遍历,逐个判断 。
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
for(;headA;headA = headA->next)
{
for(struct ListNode* TemB = headB;TemB;TemB = TemB->next)
{
if(headA == TemB)
return TemB;
}
}
return NULL;
}方法二:相交链表的特点:链表如果有交点 ,则两个链表交点后的节点数一定相同 。
所以我们只要分别找到两链表长度相同时的头节点,然后依次向后遍历,寻找有没有相同的节点就OK了。
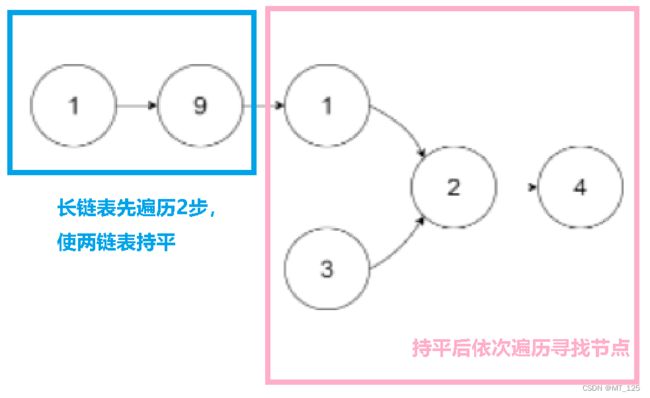
实现细节:
1. 令两链表长度持平:让长的链表先走N步,N为两链表长度差 。
2. 判断长短链表:可以多次if语句,但是有一个相对更简单的逻辑
先定义两个指针,假定长短链表,然后求假定的长短链表的差值,
如果差值大于 0 ,则没问题;如果差值小于 0 ,则再进行修改 。
int Legth(struct ListNode*head) //求链表长度
{
int i = 0;
for(;head;head = head->next,i++);
return i;
}
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
//可以先假定长链表和短链表,如果不对在修改
struct ListNode* shortList = headA,*longList = headB;
int gap = Legth(headB) - Legth(headA); //求链表长度差值
if(gap<0) //判断假定是否有误
{
shortList = headB;
longList = headA;
gap *= -1;
}
for(;gap;gap--,longList = longList->next);//链表持平
for(;longList;longList = longList->next,shortList = shortList->next)
{
if(longList == shortList)
return longList;
}
return NULL;
}