【Leetcode刷题笔记之链表篇】面试题 02.04. 分割链表
博客主页:大家好我叫张同学
欢迎点赞 收藏 留言 欢迎讨论!
本文由 【大家好我叫张同学】 原创,首发于 CSDN
✨精品专栏(不定时更新) 【数据结构+算法】 【做题笔记】【C语言编程学习】
☀️ 精品文章推荐
【C语言进阶学习笔记】三、字符串函数详解(1)(爆肝吐血整理,建议收藏!!!)
【C语言基础学习笔记】+【C语言进阶学习笔记】总结篇(坚持才有收获!)
| 前言 |
为什么要写
刷题笔记?
写博客的过程也是对自己刷题过程的梳理和总结,是一种耗时但有效的方法。
当自己分享的博客帮助到他人时,又会给自己带来额外的快乐和幸福。
(刷题的快乐+博客的快乐,简直是奖励翻倍,快乐翻倍有木有QAQ)
| 题目内容 |
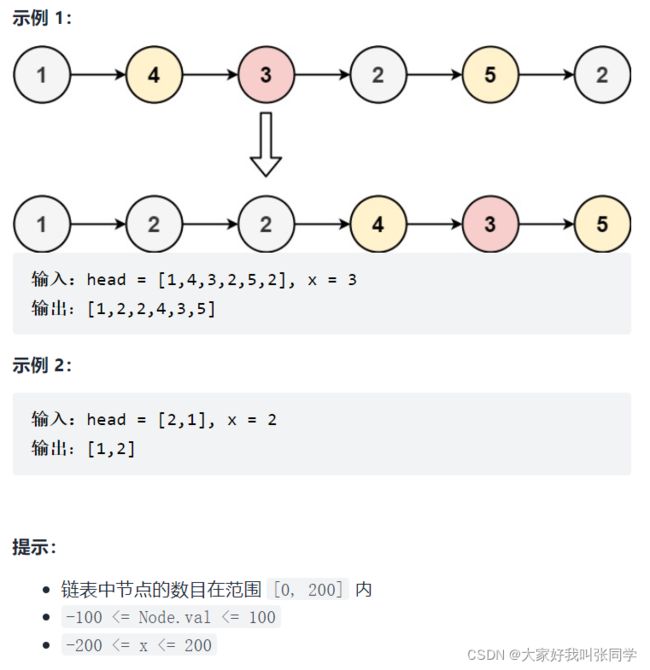
给你一个链表的头节点
head和一个特定值x,请你对链表进行分隔,使得所有小于 x的节点都出现在大于或等于 x的节点之前。你
不需要保留每个分区中各节点的初始相对位置。
原题链接(点击跳转)
| 贪吃蛇玩法 |
总体而言,要想实现分割链表的目的有两种大的思路。一种是不创建新的链表,直接在原链表上面进行相应的操作。另一种是创建一个新的链表,将原来的链表挪到新链表中,同时达到想要的效果。
我们先来学习第一种思路,也不创建新的链表,直接在原链表上面进行操作。
对于链表相关的OJ题目,尤其是单链表题目,一定要考虑链表为空和仅有一个结点这两种特殊场景。本题中我们先判断链表是否为空,若为空,直接返回原链表头节点head。(这样可以简化后续思考和编写代码的难度)
if(head == NULL || head->next == NULL)
return head;
接下来,我们就只需考虑链表至少有两个结点的情况。通过先遍历一遍链表,找到链表的尾节点tail,然后再重新遍历一遍链表,将val值大于等于k的结点尾插到tail后面即可。

//找尾
struct ListNode* tail = head;
while(tail->next){
tail = tail->next;
}

在画图分析的过程中,我们可以发现,如果cur重新遍历链表将前面大于等于k的结点尾插到tail后面,那么整个过程终止的条件是什么?是cur走到链表结尾,也就是while(cur != NULL)吗?但是问题是cur真的可以走到链表的结尾吗?继续往下走我们会发现好像进入了死循环了,永远都不会满足while终止的条件。

为了解决这个问题,我们需要一个标记点mark,来帮助我们确定停止的位置,我们想要的是cur遍历一遍链表,而不是死循环(就像是贪吃蛇一样,一直吃,吃到尾巴就结束了)。所以在一开始找到尾节点tail后,应该把这个位置标记起来,帮助我们确定while循环终止的条件。

通过图解分析,我们可以确定,当cur到达mark点时就停止了,不管mark点处的val值是否小于k,该点的位置都不需要变动。
| 完整代码 |
//在原链表上操作
struct ListNode* partition(struct ListNode* head, int x){
if(head == NULL || head->next == NULL)
return head;
//找尾
struct ListNode* tail = head;
while(tail->next){
tail = tail->next;
}
//从头遍历将val >= x的结点尾插到tail后面
struct ListNode *prev = NULL,*cur = head,*mark = tail;
while(cur != mark){
struct ListNode* next = cur->next;
if(cur->val >= x){
if(cur == head)
head = next;
cur->next = tail->next;
tail->next = cur;
tail = tail->next;
if(prev)
prev->next = next;
}
else{
prev = cur;
}
cur = next;
}
return head;
}

| 尾插合并法 |
具体思路是:将原链表中val值小于k的结点尾插到新链表newhead中。这样遍历一遍原链表后,val值小于k的结点就全部到新链表newhead了,剩下的结点都是val值大于等于k的,直接将剩下的结点全部尾插到新链表newhead中即可。
| 算法图解 |

| 函数实现 |
struct ListNode* partition(struct ListNode* head, int x){
struct ListNode *cur = head,*prev = NULL;
struct ListNode *newhead,*tail;
newhead = tail = NULL;
while(cur){
struct ListNode* next = cur->next;
if(cur->val < x){
if(cur == head){
head = next;
}
if(tail == NULL){
cur->next = tail;
newhead = tail = cur;
}
else{
cur->next = tail->next;
tail->next = cur;
tail = tail->next;
}
if(prev){
prev->next = next;
}
}
else
prev = cur;
cur = next;
}
//合并两个链表
if(tail)
tail->next = head;
else
newhead = head;
return newhead;
}

| 代码优化 |
为了简化函数内部的判断逻辑,我们可以使用带哨兵位的头节点guard来优化以上代码。要注意使用完哨兵位头节点后,对其进行释放,避免内存泄漏!
struct ListNode* partition(struct ListNode* head, int x){
struct ListNode *cur = head,*prev = NULL;
struct ListNode* guard = (struct ListNode*)malloc(sizeof(struct ListNode));
guard->next = NULL;
struct ListNode *newhead,*tail;
newhead = tail = guard;//新链表直接指向哨兵位
while(cur){
struct ListNode* next = cur->next;
if(cur->val < x){
if(cur == head){
head = next;
}
cur->next = tail->next;
tail->next = cur;
tail = tail->next;
if(prev){
prev->next = next;
}
}
else
prev = cur;
cur = next;
}
//合并两个链表
tail->next = head;
newhead = newhead->next;
free(guard);//释放哨兵位
return newhead;
}
