AI量化开源之qlib的回测结果与报表可视化
"百天计划"之19篇,关于“AI+量化,财富与成长感悟”。
今天的核心内容是回测结果分析,此内容与传统量化无太大差异。
量化结果的风险、收益指标“年化”,解读,以及时间序列可视化。
01 关于AI+
人工智能的方向一定是生产力发展的必然。
不过从上世纪中期,图灵提出的假设,现在仍然遥不可及。
机器学习和人工智能这几十年来起起伏伏,当下有点高点往下的意味。深度学习靠大数据、算力,大模型喂养,而且对于场景的泛化性能一般。
AI和美貌一样,叠加任何一个领域都是王炸,唯有单出是死局。
所以“AI+”很重要。
目前能着手做的是“AI+量化”,还有一个大的方向是AI+生命科学,比如AI辅助新药发现,这里听上去就非常令人兴奋和有价值。
02 回测结果评估与分析
接昨天从这段回测代码获得结果:
portfolio_metric_dict, indicator_dict = backtest(executor=executor, strategy=strategy, **backtest_config)
回测函数返回两个dict, 一个是组合的metric, 另一个是指标indicator,两者均是dict类型,key是“1day”。
portfolio_metric_dict = {'1day':
report_normal_df, positions_normal
}
从dict里把这个tuple读出来,前者是dataframe,后者是一个dict。
df的信息有账户,收益率,换手率,总成本,成本,市值,现金,以及基准收益率等的“时间序列“信息。

positions_normal是一个字典,key是日期,对应的是仓位信息:
from qlib.contrib.evaluate import risk_analysis
收益风险分析: 输入参数是”收益率序列“
report_normal["return"]
计算:收益率(均值),风险(标准差),夏普比(信息比率),最大回撤。
mean = r.mean()
std = r.std(ddof=1)
annualized_return = mean * N
information_ratio = mean / std * np.sqrt(N)
max_drawdown = (r.cumsum() - r.cumsum().cummax()).min()
data = {
"mean": mean,
"std": std,
"annualized_return": annualized_return,
"information_ratio": information_ratio,
"max_drawdown": max_drawdown,
}
如下是我自己之前写的风险收益分析代码:
这里计算逻辑不同,我算的收益是就是组合真实的 最后一天与第一天比,
然后把它年化(按复利的形式);
而qlib取的是这段时间每天收益率的 算术平均,然后把算术平均简单*1年的交易日数。
accu_return = round(df_equity.iloc[-1] - 1, 3) annu_ret = round((accu_return + 1) ** (252 / count) - 1, 3) #标准差 std = round(df_rates.std() * (252 ** 0.5),3) #夏普比 sharpe = round(annu_ret / std, 3) #最大回撤 mdd = round((df_equity / df_equity.expanding(min_periods=1).max()).min() - 1, 3)
目前,我不太认同这种超额收益的计算方式,对于个人投资者,我们更关心绝对收益率。当然df['return']有了之后,这一块我们完全可以按照自己的逻辑来计算风险收益。
03 可视化报表
qlib的报表功能,一共两大类:分析仓位和分析模型

def visual(self, report_normal):
import plotly
from qlib.contrib.report.analysis_position.report import report_graph
fig = report_graph(report_normal, show_notebook=False)
plotly.offline.plot(fig[0], filename="result.html")
核心函数是report_graph,传入参数就是前面的report_normal。
qlib的可视化调用的是plotly,作了很好的封装,不过有一点不好的地方,它还是自己按”超额收益“的逻辑,把各种时间序列画出来。
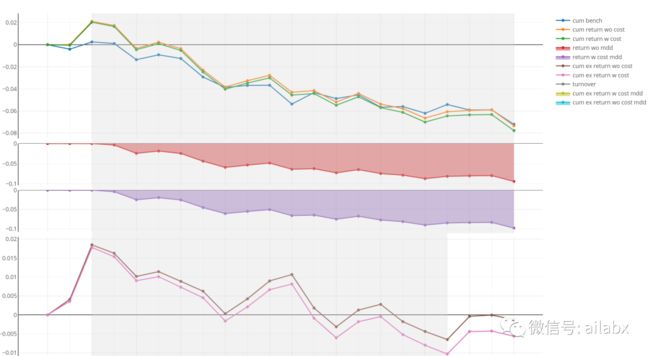
核心计算代码如下:
report_df = pd.DataFrame() report_df["cum_bench"] = df["bench"].cumsum() report_df["cum_return_wo_cost"] = df["return"].cumsum() report_df["cum_return_w_cost"] = (df["return"] - df["cost"]).cumsum() # report_df['cum_return'] - report_df['cum_return'].cummax() report_df["return_wo_mdd"] = _calculate_mdd(report_df["cum_return_wo_cost"]) report_df["return_w_cost_mdd"] = _calculate_mdd((df["return"] - df["cost"]).cumsum()) report_df["cum_ex_return_wo_cost"] = (df["return"] - df["bench"]).cumsum() report_df["cum_ex_return_w_cost"] = (df["return"] - df["bench"] - df["cost"]).cumsum() report_df["cum_ex_return_wo_cost_mdd"] = _calculate_mdd((df["return"] - df["bench"]).cumsum()) report_df["cum_ex_return_w_cost_mdd"] = _calculate_mdd((df["return"] - df["cost"] - df["bench"]).cumsum()) # return_wo_mdd , return_w_cost_mdd, cum_ex_return_wo_cost_mdd, cum_ex_return_w report_df["turnover"] = df["turnover"] report_df.sort_index(ascending=True, inplace=True)
这里没什么特别的地方,我可能会重写这块逻辑。
score_ic_graph,就是前面的文章说过的,把ic和rank_ic两个序列画散点图:

qlib还有另外一些图,不过都是基于结果dataframe里或者之前ic分析里序列数据的一些可视化,ploty的用法不够简洁,而且很多指标并非我们关心。
这一块后续有需要的时候,再看代码都来得及,就是展开说明了。
小结:
AI+是一个重要的方向,AI如何赋能数据密集型的产业,行业。
量化是我们直接就可以上手的。
另外像生物制药领域,非常有价值,也值得关注。
可视化这一块,考虑自己实现(bokeh或者pyecharts都可,当然这块并非最重要的,而且也仅是一次性的活,可以陆续补充)。