大数据系统运维
docker是什么
Docker 是一个开源的应用容器引擎,基于 [Go 语言](https://www.runoob.com/go/go-tutorial.html) 并遵从 Apache2.0 协议开源。
Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。其优势在于创建、销毁启动速度快,体积小占用系统资源远远低于虚拟机;可更快速的交付和部署、集群管理。可扩展:可以增加并自动分发容器副本。可堆叠:可以垂直和即时堆叠服务。更简单的管理:使用 Docker,只需要小小的修改,就可以替代以往大量的更新工作。所有的修改都以增量的方式被分发和更新,从而实现自动化并且高效的管理。
教程可见Docker 教程 | 菜鸟教程
docker架构

docker的三个概念
镜像(Image)
模板
容器(Container)
运行环境、完整的操作系统
仓库(Repository)
| 概念 | 说明 |
|---|---|
| Docker 镜像(Images) | Docker 镜像是用于创建 Docker 容器的模板,比如 Ubuntu 系统。 |
| Docker 容器(Container) | 容器是独立运行的一个或一组应用,是镜像运行时的实体。 |
| Docker 客户端(Client) | Docker 客户端通过命令行或者其他工具使用 Docker SDK (Redirecting…) 与 Docker 的守护进程通信。 |
| Docker 主机(Host) | 一个物理或者虚拟的机器用于执行 Docker 守护进程和容器。 |
| Docker Registry | Docker 仓库用来保存镜像,可以理解为代码控制中的代码仓库。 Docker Hub(https://hub.docker.com) 提供了庞大的镜像集合供使用。 一个 Docker Registry 中可以包含多个仓库(Repository);每个仓库可以包含多个标签(Tag);每个标签对应一个镜像。 通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 <仓库名>:<标签> 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 latest 作为默认标签。 |
| Docker Machine | Docker Machine是一个简化Docker安装的命令行工具,通过一个简单的命令行即可在相应的平台上安装Docker,比如VirtualBox、 Digital Ocean、Microsoft Azure。 |
centos下docker安装
自动化安装
curl -sSL https://get.daocloud.io/docker | sh
手动安装
安装要求:
Docker 支持 64 位版本 CentOS 7/8,并且要求内核版本不低于 3.10
uname -r 查看内核版本号
3.10.0-327.el7.x86_64
如果有旧版本可以使用如下命令卸载
$ yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-engine
注:sudo命令用于针对单个命令授予临时权限。某些命令需要 root用户的权限,如果不想直接切换到root用户,就可以使用sudo命令。使用方法是在原有命令之前加上sudo +空格。
如何配置sudo权限
1、在root下执行visudo命令,等同于vi /etc/sudoers
2、在root ALL=(ALL) ALL下
添加如下内容
(用户名) ALL=(ALL) ALL
想免除密码输入加上NOPASSWD:
(用户名) ALL=(ALL) NOPASSWD: ALL
保存并退出
注:为避免因权限问题而出现bug本次操作全部以root用户身份进行
使用yum安装
-
更新yum源
-
yum update
-
安装需要的软件包, yum-util 提供yum-config-manager功能,另外两个是devicemapper驱动依赖的
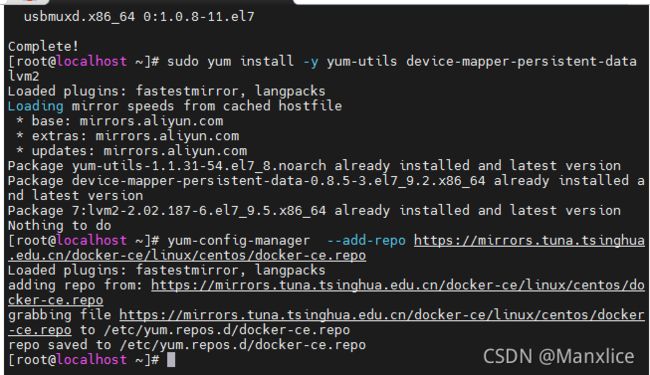
yum install -y yum-utils device-mapper-persistent-data lvm2
-
设置yum源
yum-config-manager --add-repo [https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/docker-ce.repo](https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/docker-ce.repo)
-
可以查看所有仓库中所有docker版本,并选择特定版本安装
yum list docker-ce --showduplicates | sort -r
-
安装docker
$ yum install docker-ce #由于repo中默认只开启stable仓库,故这里安装的是最新稳定版17.12.0
-
启动docker
systemctl start docker
-
通过运行 hello-world 映像来验证是否正确安装了 Docker Engine-Community
docker run hello-world
运行结果
Hello from Docker! This message shows that your installation appears to be working correctly.
docker使用
docker hello world
docker run ubuntu /bin/echo "hello world"
docker:Docker 的二进制执行文件
run: 运行一个容器。
ubuntu 指定要运行的镜像,Docker 首先从本地主机上查找镜像是否存在,如果不存在,Docker 就会从镜像仓库 Docker Hub 下载公共镜像
/bin/echo "Hello world": 在启动的容器里执行的命令
docker run -i -t ubuntu /bin/bash
-t: 在新容器内指定一个伪终端或终端。
-i: 允许你对容器内的标准输入 (STDIN) 进行交互
常用操作
运行 exit 命令或者使用 CTRL+D 来退出容器
通过 docker ps 来查看运行的容器
[root@localhost ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
CONTAINER ID: 容器 ID。 IMAGE: 使用的镜像。 COMMAND: 启动容器时运行的命令。 CREATED: 容器的创建时间。 STATUS: 容器状态。 状态有7种:
-
created(已创建)
-
restarting(重启中)
-
running 或 Up(运行中)
-
removing(迁移中)
-
paused(暂停)
-
exited(停止)
-
dead(死亡) PORTS: 容器的端口信息和使用的连接类型(tcp\udp)。 NAMES: 自动分配的容器名称。
后台运行容器
docker run -itd --name ubuntu-test ubuntu /bin/bash
加了 -d 参数默认不会进入容器
进入容器
docker attach ID
docker exec :推荐大家使用 docker exec 命令,因为此退出容器终端,不会导致容器的停止。
docker exec -it 4b243e926588 /bin/bash
使用 docker stop 命令来停止容器
镜像操作
列出本地主机上的镜像
[root@localhost ~]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE ubuntu latest 1318b700e415 4 weeks ago 72.8MB hello-world latest d1165f221234 5 months ago 13.3kB
-
REPOSITORY:表示镜像的仓库源
-
TAG:镜像的标签
-
IMAGE ID:镜像ID
-
CREATED:镜像创建时间
-
SIZE:镜像大小
获取一个新的镜像
[root@localhost ~]# docker pull ubuntu:13.10 13.10: Pulling from library/ubuntu Image docker.io/library/ubuntu:13.10 uses outdated schema1 manifest format. Please upgrade to a schema2 image for better future compatibility. More information at Update deprecated schema image manifest version 2, v1 images | Docker Documentationa3ed95caeb02: Pull complete 0d8710fc57fd: Pull complete 5037c5cd623d: Pull complete 83b53423b49f: Pull complete e9e8bd3b94ab: Pull complete 7db00e6b6e5e: Pull complete Digest: sha256:403105e61e2d540187da20d837b6a6e92efc3eb4337da9c04c191fb5e28c44dc Status: Downloaded newer image for ubuntu:13.10 docker.io/library/ubuntu:13.10

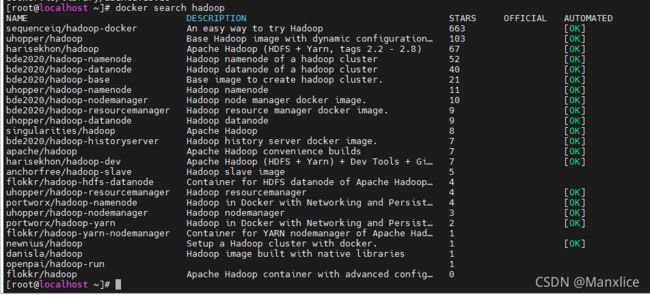
查找镜像
[root@localhost ~]# docker search hadoop NAME DESCRIPTION STARS OFFICIAL AUTOMATED sequenceiq/hadoop-docker An easy way to try Hadoop 663 [OK] uhopper/hadoop Base Hadoop image with dynamic configuration… 103 [OK] harisekhon/hadoop Apache Hadoop (HDFS + Yarn, tags 2.2 - 2.8) 67 [OK] bde2020/hadoop-namenode Hadoop namenode of a hadoop cluster 52 [OK] bde2020/hadoop-datanode Hadoop datanode of a hadoop cluster 40 [OK] kiwenlau/hadoop Run Hadoop Cluster in Docker Containers 23
Docker基本指令补充:
查看所有容器(包括停止的容器) docker ps -a
删除全部容器(包括停止的容器)docker rm -f $(docker ps -aq)
容器连接
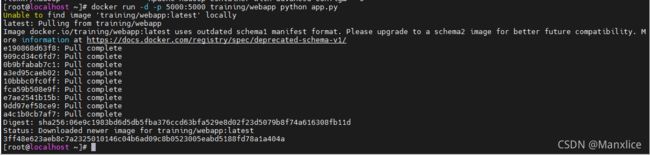
网络端口映射
docker run -d -p 5000:5000 training/webapp python app.py
-
-P :是容器内部端口随机映射到主机的高端口。
-
-p : 是容器内部端口绑定到指定的主机端口。
制定容器绑定网络地址
指定容器绑定的网络地址
docker run -d -p 127.0.0.1:5001:5000 training/webapp python app.py
可以通过访问 127.0.0.1:5001 来访问容器的 5000 端口
![]()
容器命名
docker run -d -P --name runoob training/webapp python app.py
![]()
新建网络
docker network create -d bridge test-net
新建一个桥接(bridge)网络,命名为test-net

连接容器
docker run -itd --name test1 --network test-net ubuntu /bin/bash
新建一个容器命名为test1,镜像为ubuntu,并连接到网络test-net

docker run -itd --name test2 --network test-net ubuntu /bin/bash
再新建一个容器命名为test2,镜像为ubuntu,并连接到网络test-net

docker exec -it test1 /bin/bash
进入容器test1
![]()
ping test2

若能ping通则网络无问题
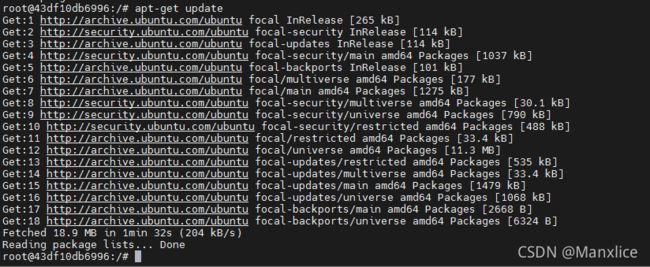
若无ping,则可以安装
apt-get update apt install iputils-ping

配置DNS
在宿主机的 /etc/docker/daemon.json 文件中增加以下内容来设置全部容器的 DNS:
{ "dns" : [ "114.114.114.114", "8.8.8.8" ] }
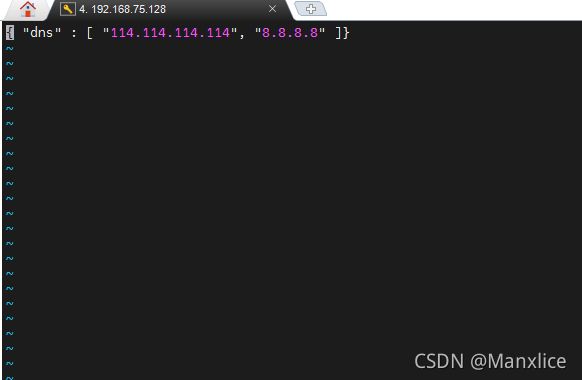
设置后,启动容器的 DNS 会自动配置为 114.114.114.114 和 8.8.8.8。
配置完,需要重启 docker 才能生效。
systemctl restart docker
查看容器的 DNS 是否生效可以使用以下命令,它会输出容器的 DNS 信息:
$ docker run -it --rm ubuntu cat etc/resolv.conf

dockerfile
什么是dockerfile
Dockerfile 是一个用来构建镜像的文本文件,文本内容包含了构建镜像所需的指令和说明。
FROM 和 RUN 指令
FROM:定制的镜像都是基于 FROM 的镜像,这里的 nginx 就是定制需要的基础镜像。后续的操作都是基于 nginx。 RUN:用于执行后面跟着的命令行命令。
RUN命令格式
普通shell 格式,终端的普通命令
exec格式,RUN ["可执行文件", "参数1", "参数2"]
例:RUN ["./test.php", "dev", "offline"] 等价于 RUN ./test.php dev offline
构建镜像
再dockerfile存放目录下执行构建动作
1、在当前目录下新建名为dockerfile的文件
mkdir dockerfile
文件内容如下
FROM nginx RUN echo '这是一个本地构建的nginx镜像' > /usr/share/nginx/html/index.html
2、执行命令构建镜像
docker build -t nginx:v3 .
其中的.为上下文路径,
是指 docker 在构建镜像,有时候想要使用到本机的文件(比如复制),docker build 命令得知这个路径后,会将路径下的所有内容打包。
如果未说明最后一个参数,那么默认上下文路径就是 Dockerfile 所在的位置。
注意:上下文路径下不要放无用的文件,因为会一起打包发送给 docker 引擎,如果文件过多会造成过程缓慢。
docker文件指令详解
COPY
复制指令,从上下文目录中复制文件或者目录到容器里指定路径。
COPY [--chown=
[--chown=
源路径可以为通配符格式
目标路径无需创建好,如无目标路径则自行创建
COPY hom* /mydir/
COPY hom?.txt /mydir/
ADD
ADD 指令和 COPY 的使用格类似(同样需求下,官方推荐使用 COPY)。功能也类似,不同之处如下:
-
ADD 的优点:在执行 <源文件> 为 tar 压缩文件的话,压缩格式为 gzip, bzip2 以及 xz 的情况下,会自动复制并解压到 <目标路径>。
-
ADD 的缺点:在不解压的前提下,无法复制 tar 压缩文件。会令镜像构建缓存失效,从而可能会令镜像构建变得比较缓慢。具体是否使用,可以根据是否需要自动解压来决定。
CMD
类似于 RUN 指令,用于运行程序,但二者运行的时间点不同:
-
CMD 在docker run 时运行。
-
RUN 是在 docker build。
作用:为启动的容器指定默认要运行的程序,程序运行结束,容器也就结束。CMD 指令指定的程序可被 docker run 命令行参数中指定要运行的程序所覆盖。
如果 Dockerfile 中如果存在多个 CMD 指令,仅最后一个生效。
ENV
设置环境变量,定义了环境变量,那么在后续的指令中,就可以使用这个环境变量。
ENV
实例
ENV NODE_VERSION 7.2.0
ARG
构建参数,与 ENV 作用一致。不过作用域不一样。ARG 设置的环境变量仅对 Dockerfile 内有效,也就是说只有 docker build 的过程中有效,构建好的镜像内不存在此环境变量。
练习:在docker里创建可以使用JDK的镜像
FROM centos:7 WORKDIR /jdk RUN mkdir -p /jdk ADD jdk-8u231-linux-x64.tar.gz /jdk ENV JAVA_HOME /jdk/jdk1.8.0_171 ENV PATH $JAVA_HOME/bin:$PATH
docker compose安装
什么是docker compose
Compose 是用于定义和运行多容器 Docker 应用程序的工具。通过 Compose,您可以使用 YML 文件来配置应用程序需要的所有服务。然后,使用一个命令,就可以从 YML 文件配置中创建并启动所有服务。
YAML
本节参考YAML 入门教程 | 菜鸟教程
基本语法
-
大小写敏感
-
使用缩进表示层级关系
-
缩进不允许使用tab,只允许空格
-
缩进的空格数不重要,只要相同层级的元素左对齐即可
-
'#'表示注释
数据类型
YAML 支持以下几种数据类型:
-
对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
-
数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
-
纯量(scalars):单个的、不可再分的值
YAML 对象
对象键值对使用冒号结构表示 key: value,冒号后面要加一个空格。
也可以使用 key:{key1: value1, key2: value2, ...}。
还可以使用缩进表示层级关系;
key: child-key: value
child-key2: value2
YAML 数组
以 - 开头的行表示构成一个数组:
-A
-B
-C
YAML 支持多维数组,可以使用行内表示:
key: [value1, value2, ...]
数据结构的子成员是一个数组,则可以在该项下面缩进一个空格。
例子
companies:
-
id: 1
name: company1
price: 200W
-
id: 2
name: company2
price: 500W意思是 companies 属性是一个数组,每一个数组元素又是由 id、name、price 三个属性构成。
数组也可以使用流式(flow)的方式表示:
companies: [{id: 1,name: company1,price: 200W},{id: 2,name: company2,price: 500W}]
纯量
纯量是最基本的,不可再分的值,包括:
-
字符串
-
布尔值
-
整数
-
浮点数
-
Null
-
时间
-
日期
实例
boolean:
- TRUE #true,True都可以
- FALSE #false,False都可以
float:
- 3.14
- 6.8523015e+5 #可以使用科学计数法
int:
- 123
- 0b1010_0111_0100_1010_1110 #二进制表示
null:
nodeName: 'node'
parent: ~ #使用~表示null
string:
- 哈哈
- 'Hello world' #可以使用双引号或者单引号包裹特殊字符
- newline
newline2 #字符串可以拆成多行,每一行会被转化成一个空格
date:
- 2018-02-17 #日期必须使用ISO 8601格式,即yyyy-MM-dd
datetime:
- 2018-02-17T15:02:31+08:00 #时间使用ISO 8601格式,时间和日期之间使用T连接,最后使用+代表时区引用
& 锚点和 * 别名,可以用来引用:
defaults: &defaults
adapter: postgres
host: localhost
development:
database: myapp_development
<<: *defaults
test:
database: myapp_test
<<: *defaults相当于
defaults:
adapter: postgres
host: localhost
development:
database: myapp_development
adapter: postgres
host: localhost
test:
database: myapp_test
adapter: postgres
host: localhost& 用来建立锚点(defaults),<< 表示合并到当前数据,* 用来引用锚点。
Compose 使用的三个步骤
-
使用 Dockerfile 定义应用程序的环境。
-
使用 docker-compose.yml 定义构成应用程序的服务,这样它们可以在隔离环境中一起运行。
-
最后,执行 docker-compose up 命令来启动并运行整个应用程序。
compose安装
curl -L "https://get.daocloud.io/docker/compose/releases/download/1.12.0/docker-compose-(uname−s)−(uname -s)-(uname−s)−(uname -m)" -o /usr/local/bin/docker-compose
下载并安装
chmod +x /usr/local/bin/docker-compose
更改权限可执行
测试安装是否成功
$docker-compose -version
docker-compose version 1.12.0, build b31ff33
升级
pip install --upgrade backports.ssl_match_hostname
yml 配置指令
version
指定本 yml 的写法格式(格式的版本)
services
服务列表,用数组形式展现,每个服务可为一个容器
image
指定服务所用镜像
container_name
指定容器名字,而非默认
restart
-
no:是默认的重启策略,在任何情况下都不会重启容器。
-
always:容器总是重新启动。(docker重启时)
-
on-failure:在容器非正常退出时(退出状态非0),才会重启容器。
-
unless-stopped:在容器退出时总是重启容器,但是不考虑在Docker守护进程启动时就已经停止了的容器
networks
配置容器连接的网络,引用顶级 networks 下的条目
实例
services: some-service: networks: some-network: aliases: - alias1 other-network: aliases: - alias2 networks: some-network: # Use a custom driver driver: custom-driver-1
自定义扩展网卡
实例
networks: extnetwork: #自定义网络名称 ipam: #ip地址管理 config: #配置信息 - subnet: 172.20.0.0/16 #网段管理 gateway: 172.20.0.1 #网关地址
ipv4_address
为服务的容器指定一个静态 IP 地址
networks: hadoop-hdfs: ipv4_address: 172.25.1.100
ports
映射端口
实例
ports: - "50070:50070" - "9000:9000"
extra_hosts
添加主机名的标签,就是往 /etc/hosts 文件中添加一些记录
extra_hosts: - "hadoop-nn:172.25.1.100" - "hadoop-dn1:172.25.1.101" - "hadoop-dn2:172.25.1.102" - "hadoop-dn3:172.25.1.103"
docker安装hadoop
hadoop是什么
Hadoop 是一个开源的分布式计算和存储框架,由 Apache 基金会开发和维护。
Hadoop 为庞大的计算机集群提供可靠的、可伸缩的应用层计算和存储支持,它允许使用简单的编程模型跨计算机群集分布式处理大型数据集,并且支持在单台计算机到几千台计算机之间进行扩展。
Hadoop 使用 Java 开发,所以可以在多种不同硬件平台的计算机上部署和使用。其核心部件包括分布式文件系统 (Hadoop DFS,HDFS) 和 MapReduce。
教程可见1.0 Hadoop 教程 | 菜鸟教程
基础环境镜像
这里基础环境换成了ubuntu,ubuntu我并不熟悉,但是备课材料使用了ubuntu,时间紧张就直接使用了,为保证课程内容的连贯性,后面有时间我会换成centos,也很有可能没有后面了
构建基础环境步骤
(1)为了精简镜像,所以基础镜像采用ubuntu:14.04 (2)ubuntu:14.04中apt下载非常慢,因此将/etc/apt/sources.list中更换为阿里云源,内容如下: deb http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiverse deb http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-security main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-updates main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-proposed main restricted universe multiverse deb-src http://mirrors.aliyun.com/ubuntu/ trusty-backports main restricted universe multiverse (3)基础镜像中未安装ssh服务,需要安装openssh-server和openssh-client服务 (4)生成免密登录秘钥,并配置为当前容器可免密登录自己(因为之后我们创建的所有的容器都是基于该镜像,因此设置了可免密登录自己即是各容器直接可免密登录,这是Docker给我们带来的一个非常方便的设计) (5)在/ect/ssh目录下添加ssh_config文件,文件内容如下: Host localhost StrictHostKeyChecking no Host 0.0.0.0 StrictHostKeyChecking no Host hadoop-* StrictHostKeyChecking no UserKnownHostsFile=/dev/null Host spark-* StrictHostKeyChecking no UserKnownHostsFile=/dev/null Host zk-* StrictHostKeyChecking no UserKnownHostsFile=/dev/null (6)创建ssh服务启动目录/var/run/sshd (7)修改root用户密码为root,并将工作目录切换为/root (8)指定容器启动时运行的命令为后台启动sshd服务 (9)通过docker build构建ubuntu-ssh:v1镜像
参考实例dockerfile
FROM ubuntu:14.04 ADD sources.list /etc/apt RUN apt-get update && \ apt-get install openssh-server openssh-client -y RUN mkdir -p /var/run/sshd RUN echo 'root:root' | chpasswd RUN mkdir /root/.ssh && ssh-keygen -q -P '' -t dsa -f /root/.ssh/id_dsa RUN cat /root/.ssh/id_dsa.pub >> /root/.ssh/authorized_keys ADD ssh_config /etc/ssh EXPOSE 22 WORKDIR /root CMD /usr/sbin/sshd -D
执行并生成镜像
docker build -t ubuntu-ssh:v1 .

验证 docker images
[root@localhost 01-ubuntu-ssh]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
ubuntu-ssh v1 29e9be0474af 9 seconds ago 260MB
免密登陆

制作jdk镜像
因为Hadoop、Zookeeper、Spark依赖于JVM,因此本模块功能为构建JDK镜像作为Hadoop、Zookeeper和Spark的基础镜像。
设计思路
(1)采用2.1中构建的ubuntu-ssh:v1作为基础镜像
(2)将jdk-8u231-linux-x64.tar.gz(也可采用其他版本,建议1.8JDK)复制并解压到/root/apps目录下,为了精简镜像,解压完成后需要将jdk-8u231-linux-x64.tar.gz删除。
(3)配置Java的环境变量
(4)通过docker build构jdk1.8:v1镜像
dockerfile实现
FROM ubuntu-ssh:v1
MAINTAINER manRUN mkdir -p /root/apps
COPY jdk-8u231-linux-x64.tar.gz /root
RUN tar -zxvf jdk-8u231-linux-x64.tar.gz -C apps/ &&\
mv /root/apps/jdk1.8.0_231 /root/apps/java &&\
rm -f jdk-8u231-linux-x64.tar.gzENV JAVA_HOME=/root/apps/java
ENV PATH=$JAVA_HOME/bin:$PATH
CMD /usr/sbin/sshd -D

测试思路
通过jdk1.8:v1镜像启动一个容器,在容器中输入java –version或javac –version,如果能输出java版本,则镜像构建成功。
hadoop部署
集群规划
hdfs集群规划
| 容器主机名 /容器名 | 容器IP(网络名称hadoop-hdfs) | 节点进程 | 容器启动镜像 |
| hadoop-nn | 172.25.1.100 | NameNode、SecondaryNameNode | namenode:v1 |
| hadoop-dn1 | 172.25.1.101 | DataNode | datanode:v1 |
| hadoop-dn2 | 172.25.1.102 | DataNode | datanode:v1 |
| hadoop-dn3 | 172.25.1.103 | DataNode | datanode:v1 |
yarn集群规划
| 容器主机名 /容器名 | 容器IP(网络名称hadoop-yarn) | 节点进程 | 容器启动镜像 |
| hadoop-rm | 172.24.1.100 | ResourceManager | resourcemanager:v1 |
| hadoop-nm1 | 172.24.1.101 | NodeManager | nodemanager:v1 |
| hadoop-nm2 | 172.24.1.102 | NodeManager | nodemanager:v1 |
| hadoop-nm3 | 172.24.1.103 | NodeManager | nodemanager:v1 |
设计思路
当容器启动时,需要启动hdfs的所有进程,因此设计为需要定义namenode和datanode两个镜像文件。因为hdfs和yarn的需要的配置文件相同,因此先自定义一个hadoop-base的基础镜像,然后再分别构建namenode、datanode、resourcemanager和nodemanager镜像。
构建hadoop-base镜像
基础步骤
(1)2.2中构建的jdk1.8:v1作为基础镜像
(2)将hadoop-2.7.6.tar.gz(可采用其他版本)复制到容器的/root目录下并解压至/root/apps目录下,为了精简镜像,需要将hadoop-2.7.6.tar.gz删除。
(3)创建/root/hdfs/namenode、/root/hdfs/datanode(hdfs-site.xml指定目录)和/root/apps/hadoop/logs(启动namenode时产生的日志文件保存在该目录下)目录
(4)配置Hadoop环境变量
(5)将配置文件复制的/tmp/目录下,并在/tmp/下移动到$HADOOP_HOME/etc/hadoop/目录中
(8)通过docker-build构建hadoop-bash:v1镜像
dockerfile实例
FROM jdk1.8:v1 COPY hadoop-2.7.6.tar.gz /root RUN tar -zxvf hadoop-2.7.6.tar.gz -C apps/ && \ mv /root/apps/hadoop-2.7.6 /root/apps/hadoop && \ rm -rf /root/apps/hadoop-2.7.6.tar.gz && \ mkdir -p /root/hdfs && \ mkdir -p /root/hdfs/namenode && \ mkdir -p /root/hdfs/datanode && \ mkdir -p /root/apps/hadoop/logs ENV HADOOP_HOME=/root/apps/hadoop ENV PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH COPY config/* /tmp/ RUN mv /tmp/hadoop-env.sh $HADOOP_HOME/etc/hadoop/hadoop-env.sh && \ mv /tmp/hdfs-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml && \ mv /tmp/core-site.xml $HADOOP_HOME/etc/hadoop/core-site.xml && \ mv /tmp/mapred-site.xml $HADOOP_HOME/etc/hadoop/mapred-site.xml && \ mv /tmp/yarn-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml
构建namenode镜像
基础步骤
(1)构建的hadoop-bash:v1作为基础镜像 (2)namenode节点需要格式化,因此运行hadoop namenode –format命令 (3)将run.sh(启动namenode和sshd的脚本)复制到/root下并添加执行权限 (3)指定数据卷/root/hdfs (4)暴露端口50070和9000 (5)指定容器启动运行run.sh脚本 (6)通过docker-build构建namenode:v1镜像
dockerfile实例
FROM hadoop-base:v1 MAINTAINER man COPY config/* /tmp/ RUN mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \ mv /tmp/run.sh /root/run.sh RUN chmod +x /root/ run.sh RUN hdfs namenode -format VOLUME /root/hdfs EXPOSE 50070 9000 CMD /root/run.sh
相应的run.sh文件
#!/bin/bash echo "启动namenode" hadoop-daemon.sh start namenode echo "启动SSH服务" /usr/sbin/sshd -D
构建datanode镜像
基础步骤
(1)构建的hadoop-bash:v1作为基础镜像 (2)将run.sh(启动datanode和sshd的脚本)复制到/root下并添加执行权限 (3)指定容器启动运行run.sh脚本 (4)通过docker-build构建datanode:v1镜像
dockerfile实例
FROM hadoop-base:v1 MAINTAINER man COPY config/* /tmp/ RUN mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \ mv /tmp/run.sh /root/run.sh RUN chmod +x /root/ run.sh CMD /root/run.sh
相应的run.sh文件
#!/bin/bash echo "启动datanode" hadoop-daemon.sh start datanode echo "启动SSH服务" /usr/sbin/sshd -D
构建resourcemanager镜像
基础步骤
(1)构建的hadoop-bash:v1作为基础镜像 (2)将run.sh(启动resourcemanager和sshd的脚本)复制到/root下并添加执行权限 (3)暴露端口8080 (4)指定容器启动运行run.sh脚本 (5)通过docker-build构建resourcemanager:v1镜像
dockerfile实例
FROM hadoop-base:v1 MAINTAINER man COPY config/* /tmp/ RUN mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \ mv /tmp/run.sh /root/run.sh RUN chmod +x /root/ run.sh EXPOSE 8088 CMD /root/run.sh
相应的run.sh
#!/bin/bash echo "启动resourcemanager" yarn-daemon.sh start resourcemanager echo "启动SSH服务" /usr/sbin/sshd -D
构建nodemanager镜像
基础步骤
(1)构建的hadoop-bash:v1作为基础镜像 (2)将run.sh(启动nodemanager和sshd的脚本)复制到/root下并添加执行权限 (3)指定容器启动运行run.sh脚本 (4)通过docker-build构建node:v1镜像
dockerfile实例
FROM hadoop-base:v1 MAINTAINER man COPY config/* /tmp/ RUN mv /tmp/slaves $HADOOP_HOME/etc/hadoop/slaves && \ mv /tmp/run.sh /root/run.sh RUN chmod +x /root/ run.sh CMD /root/run.sh
相应的run.sh
#!/bin/bash echo "启动nodemanager" yarn-daemon.sh start nodemanager echo "启动SSH服务" /usr/sbin/sshd -D
测试:
每个镜像创建完成后可以单独启动为一个容器(需要注意的是容器主机名必须与配置文件指定的主机名相同),然后进入容器查看是否有相应的进程运行,如果存在进程则镜像构建成功,如果没有进程可查看启动日志。
hdfs容器化部署
部署步骤
(1)创建docker-compose.yml文件 (2)指定docker-compose版本为3(也可以采用2) (3)定义名称为hadoop-hdfs的网络,网络驱动指定为bridge,subnet为172.25.1.0/24,网关为172.25.1.1 (4)分别指定hadoop-nn、hadooo-dn1、hadoop-dn2、hadoop-dn3服务,每个服务的重启策略为always,network采用hadoop-hdfs,并添加容器主机名和ip映射,hadoop-nn服务将50070和9000端口映射到DockerHost的50070和9000端口 (5)通过docker-compose up –d启动hdfs服务。 (6)通过WebUI方式测试(浏览器中输入DockerHOST的IP:50070),查看每个节点的运行状态。
docker-compose.yml实例
hadoop-dn1: image: datanode:v1 container_name: hadoop-dn1 hostname: hadoop-dn1 restart: always networks: hadoop-hdfs: ipv4_address: 172.25.1.101 extra_hosts: - "hadoop-nn:172.25.1.100" - "hadoop-dn1:172.25.1.101" - "hadoop-dn2:172.25.1.102" - "hadoop-dn3:172.25.1.103" hadoop-dn2: image: datanode:v1 container_name: hadoop-dn2 hostname: hadoop-dn2 restart: always networks: hadoop-hdfs: ipv4_address: 172.25.1.102 extra_hosts: - "hadoop-nn:172.25.1.100" - "hadoop-dn1:172.25.1.101" - "hadoop-dn2:172.25.1.102" - "hadoop-dn3:172.25.1.103" hadoop-dn3: image: datanode:v1 container_name: hadoop-dn3 hostname: hadoop-dn3 restart: always networks: hadoop-hdfs: ipv4_address: 172.25.1.103 extra_hosts: - "hadoop-nn:172.25.1.100" - "hadoop-dn1:172.25.1.101" - "hadoop-dn2:172.25.1.102" - "hadoop-dn3:172.25.1.103" networks: hadoop-hdfs: driver: bridge ipam: driver: default config: - subnet: 172.25.1.0/24

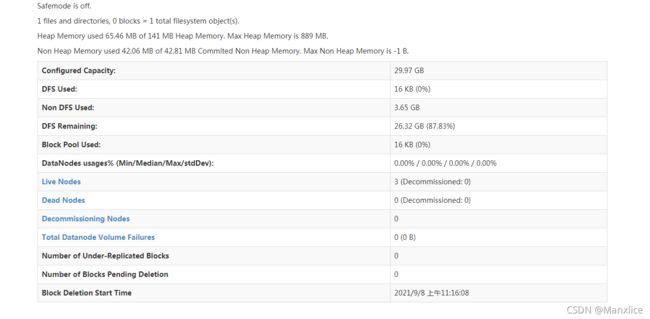
YARN容器化部署
部署步骤
(1)创建docker-compose.yml文件 (2)指定docker-compose版本为3(也可以采用2) (3)定义名称为hadoop-yarn的网络,网络驱动指定为bridge,subnet为172.24.1.0/24,网关为172.24.1.1 (4)分别指定hadoop-rm、hadooo-nm1、hadoop-nm2、hadoop-nm3服务,每个服务的重启策略为always,network采用hadoop-yarn,并添加容器主机名和ip映射,hadoop-rm服务将8088端口映射到DockerHost的8088端口 (5)通过docker-compose up 启动yarn服务。 (6)通过WebUI方式测试(浏览器中输入DockerHOST的IP:8088),查看每个节点的运行状态。
docker-compose.yml实例
version: "3" services: hadoop-rm: image: resourcemanager:v1 container_name: hadoop-rm hostname: hadoop-rm restart: always networks: hadoop-yarn: ipv4_address: 172.24.1.100 ports: - "8088:8088" extra_hosts: - "hadoop-rm:172.24.1.100" - "hadoop-nm1:172.24.1.101" - "hadoop-nm2:172.24.1.102" - "hadoop-nm3:172.24.1.103" hadoop-nm1: image: nodemanager:v1 container_name: hadoop-nm1 hostname: hadoop-nm1 restart: always networks: hadoop-yarn: ipv4_address: 172.24.1.101 extra_hosts: - "hadoop-rm:172.24.1.100" - "hadoop-nm1:172.24.1.101" - "hadoop-nm2:172.24.1.102" - "hadoop-nm3:172.24.1.103" hadoop-nm2: image: nodemanager:v1 container_name: hadoop-nm2 hostname: hadoop-nm2 restart: always networks: hadoop-yarn: ipv4_address: 172.24.1.102 extra_hosts: - "hadoop-rm:172.24.1.100" - "hadoop-nm1:172.24.1.101" - "hadoop-nm2:172.24.1.102" - "hadoop-nm3:172.24.1.103" hadoop-nm3: image: nodemanager:v1 container_name: hadoop-nm3 hostname: hadoop-nm3 restart: always networks: hadoop-yarn: ipv4_address: 172.24.1.103 extra_hosts: - "hadoop-rm:172.24.1.100" - "hadoop-nm1:172.24.1.101" - "hadoop-nm2:172.24.1.102" - "hadoop-nm3:172.24.1.103" networks: hadoop-yarn: driver: bridge ipam: driver: default config: - subnet: 172.24.1.0/24


docker安装zookeeper
什么是zookeeper
zookeeper实际上是yahoo开发的,用于分布式中一致性处理的框架。最初其作为研发Hadoop时的副产品。由于分布式系统中一致性处理较为困难,其他的分布式系统没有必要费劲重复造轮子,故随后的分布式系统中大量应用了zookeeper,以至于zookeeper成为了各种分布式系统的基础组件,其地位之重要,可想而知。著名的hadoop、kafka、dubbo 都是基于zookeeper而构建。
官网:Apache ZooKeeper
集群规划
| 容器主机名/容器名 | 容器IP(网络名称zk-network) |
| zk1 | 172.26.1.101 |
| zk2 | 172.26.1.102 |
| zk3 | 172.26.1.103 |
镜像启动操作
实现思路
(1)2.2中构建的jdk1.8:v1作为基础镜像 (2)将zookeeper-3.4.12.tar.gz(可采用其他版本)复制到容器的/root目录下并解压至/root/apps目录下,为了精简镜像,需要将zookeeper-3.4.12.tar.gz删除。 (3)配置Zookeeper环境变量,并定义MYID变量(docker-compose运行时传递参数到MYID,并写入到zookeeper的datadir中的myid文件中) (4)将配置文件复制的/tmp/目录下,并在/tmp/下移动到$ZOOKEEPER_HOME/conf /目录中 (5)将start-zk.sh(启动zookeeper和sshd服务)复制到/root下并添加执行权限 (6)创建zoo.conf配置文件中指定的datadir目录 (7)指定/root/data/zookeeper为数据卷 (8)暴露2181端口 (9)指定容器启动时运行start-zk.sh脚本
dockerfile实例
FROM jdk1.8:v1
COPY zookeeper-3.4.12.tar.gz /root
RUN tar -zxvf zookeeper-3.4.12.tar.gz -C apps/ && \
mv /root/apps/zookeeper-3.4.12 /root/apps/zookeeper && \
rm -rf /root/zookeeper-3.4.12.tar.gz
ENV ZOOKEEPER_HOME=/root/apps/zookeeper
ENV PATH=$ZOOKEEPER_HOME/bin:$PATH
ARG MYID
COPY conf/* /tmp/
RUN mv /tmp/zoo.cfg $ZOOKEEPER_HOME/conf/zoo.cfg && \
mv /tmp/start-zk.sh /root/start-zk.sh
RUN chmod +x /root/start-zk.sh
RUN mkdir -p /root/data/zookeeper && echo ${MYID} > /root/data/zookeeper/myid
VOLUME /root/data/zookeeper
EXPOSE 2181
CMD /root/start-zk.sh
容器化部署
实现思路
(1)创建docker-compose.yml文件 (2)指定docker-compose版本为3(也可以采用2) (3)定义名称为zk-network的网络,网络驱动指定为bridge,subnet为172.26.1.0/24,网关为172.26.1.1 (4)分别指定zk1、zk2、zk3,每个服务的重启策略为always,network采用zk-network,并添加容器主机名和ip映射,每个容器都要映射端口到当前DockerHost主机中,为了避免端口冲突,所以主机中的端口分别采用2181、2182和2183 (5)通过docker-compose up –d启动zookeeper服务。
docker-compose.yml实例
version: "3" services: zk1: build: context: /root/zookeeper-s/zookeeper/ dockerfile: /root/zookeeper-s/zookeeper/dockerfile args: MYID: 1 container_name: zk1 hostname: zk1 restart: always networks: zk-network: ipv4_address: 172.26.1.101 ports: - "2181:2181" extra_hosts: - "zk1:172.26.1.101" - "zk2:172.26.1.102" - "zk3:172.26.1.103" zk2: build: context: /root/zookeeper-s/zookeeper/ dockerfile: /root/zookeeper-s/zookeeper/dockerfile args: MYID: 2 container_name: zk2 hostname: zk2 restart: always networks: zk-network: ipv4_address: 172.26.1.102 ports: - "2182:2181" extra_hosts: - "zk1:172.26.1.101" - "zk2:172.26.1.102" - "zk3:172.26.1.103" zk3: build: context: /root/zookeeper-s/zookeeper/ dockerfile: /root/zookeeper-s/zookeeper/dockerfile args: MYID: 3 container_name: zk3 hostname: zk3 restart: always networks: zk-network: ipv4_address: 172.26.1.103 ports: - "2183:2181" extra_hosts: - "zk1:172.26.1.101" - "zk2:172.26.1.102" - "zk3:172.26.1.103" networks: zk-network: driver: bridge ipam: driver: default config: - subnet: 172.26.1.0/24
测试
(1)首先通过docker-compose ps查看服务是否正常运行
(2)可分别进入容器通过zkServer.sh status查看状态,用JSP查看进程
(3)通过zookeeper的客户端分别远程访问Docker主机IP:2181、Docker主机IP:2182、Docker主机IP:2183,如果能正常连接,则zookeeper集群部署成功。
docker安装Spark
什么是Spark
Spark最初由美国加州伯克利大学的AMP实验室于2009年开发,Spark是一种通用的大数据计算框架,是基于RDD(弹性分布式数据集)的一种计算模型。通俗讲就是可以分布式处理大量极数据的,将大量集数据先拆分,分别进行计算,然后再将计算后的结果进行合并。
Apache Spark的功能
快速 - 使用最先进的DAG调度程序,查询优化器和物理执行引擎,为批处理和流数据提供高性能。 易于使用 - 它有助于使用Java,Scala,Python,R和SQL编写应用程序。它还提供80多个高级运算符。 通用性 - 它提供了一系列库,包括SQL和DataFrames,用于机器学习的MLlib,GraphX和Spark Streaming。 轻量级 - 它是一种轻型统一分析引擎,用于大规模数据处理。 无处不在 - 它可以轻松运行在Hadoop,Apache Mesos,Kubernetes,独立或云端。
集群规划
| 容器主机名 /容器名 | 容器IP(网络名称spark-network) | 节点进程 | 容器启动镜像 |
| spark-master1 | 172.27.1.100 | master、HistoryServer | spark-master:v1 |
| spark-master2 | 172.27.1.120 | master | spark-master:v1 |
| spark-worker1 | 172.27.1.101 | worker | spark-worker:v1 |
| spark-worker2 | 172.27.1.102 | worker | spark-worker:v1 |
| spark-worker3 | 172.27.1.103 | worker | spark-worker:v1 |
设计与实现思路
spark-master镜像
基础步骤
(1)2.2中构建的jdk1.8:v1作为基础镜像 (2)将spark-2.3.4.tar.gz(可采用其他版本)复制到容器的/root目录下并解压至/root/apps目录下,为了精简镜像,需要将spark-2.3.4.tar.gz删除。 (3)配置Spark环境变量 (4)将配置文件(指导老师讲解配置文件并提供给学生)复制的/tmp/目录下,并在/tmp/下移动到$SPARK_HOME/conf/目录中 (5)创建 /root/apps/spark/logs目录(spark启动时的日志文件输出到本目录下) (6)将run.sh(启动master和historyserver服务)复制到/root下并添加执行权限 (7)暴露8080和7077端口 (8)指定容器启动时运行run.sh脚本
dockerfile实例
FROM jdk1.8:v1 COPY spark-2.3.4.tar.gz /root RUN tar -zxvf spark-2.3.4.tar.gz -C apps/ && \ mv /root/apps/spark-2.3.4-bin-hadoop2.7 /root/apps/spark && \ rm -rf /root/spark-2.3.4.tar.gz ENV SPARK_HOME=/root/apps/spark ENV PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH COPY conf/* /tmp/ RUN mv /tmp/spark-env.sh $SPARK_HOME/conf/spark-env.sh && \ mv /tmp/slaves $SPARK_HOME/conf/slaves && \ mv /tmp/spark-defaults.conf $SPARK_HOME/conf/spark-defaults.conf && \ mv /tmp/run.sh /root/run.sh RUN chmod +x /root/run.sh RUN mkdir -p /root/apps/spark/logs EXPOSE 8080 7077 CMD /root/run.sh
spark-worker镜像
基础步骤
(1)2.2中构建的jdk1.8:v1作为基础镜像 (2)将spark-2.3.4.tar.gz(可采用其他版本)复制到容器的/root目录下并解压至/root/apps目录下,为了精简镜像,需要将spark-2.3.4.tar.gz删除。 (3)配置Spark环境变量 (4)将配置文件(指导老师讲解配置文件并提供给学生)复制的/tmp/目录下,并在/tmp/下移动到$SPARK_HOME/conf/目录中 (5)创建 /root/apps/spark/logs目录(spark启动时的日志文件输出到本目录下) (6)将run.sh(启动worker,因为现在有两个master节点,所以需要启动worker时需要判断哪个节点的master时主节点)复制到/root下并添加执行权限, (7)指定容器启动时运行run.sh脚本
dockerfile实例
FROM jdk1.8:v1 ENV DEBIAN_FRONTEND noninteractive RUN apt-get install curl -y COPY spark-2.3.4.tar.gz /root RUN tar -zxvf spark-2.3.4.tar.gz -C apps/ && \ mv /root/apps/spark-2.3.4-bin-hadoop2.7 /root/apps/spark && \ rm -rf /root/spark-2.3.4.tar.gz ENV SPARK_HOME=/root/apps/spark ENV PATH=$SPARK_HOME/bin:$SPARK_HOME/sbin:$PATH COPY conf/* /tmp/ RUN mv /tmp/spark-env.sh $SPARK_HOME/conf/spark-env.sh && \ mv /tmp/slaves $SPARK_HOME/conf/slaves && \ mv /tmp/spark-defaults.conf $SPARK_HOME/conf/spark-defaults.conf && \ mv /tmp/run.sh /root/run.sh RUN chmod +x /root/run.sh RUN mkdir -p /root/apps/spark/logs EXPOSE 8080 7077 CMD /root/run.sh
部署安装
基础步骤
(1)先在HDFS中创建spark-history的目录(spark-default中指定的historyserver保存数据的目录) (2)创建docker-compose.yml文件 (3)指定docker-compose版本为3(也可以采用2) (4)定义名称为spark-network的网络,网络驱动指定为bridge,subnet为172.27.1.0/24,网关为172.27.1.1 (5)分别指定spark-master1、spark-master2、spark-worker1,spark-worker2、 spark-worker3服务,每个服务的重启策略为always,network采用spark-network,并添加容器主机名和ip映射,spark-master1、spark-master2将8080和7077端口映射到Docker主机的8080和7077端口。 (6)通过docker-compose up –d启动Spark服务。
docker-compose.yml实例
version: "3" services: spark-master1: image: spark-master:v1 container_name: spark-master1 hostname: spark-master1 restart: always networks: spark-network: ipv4_address: 172.27.1.100 ports: - "8081:8080" - "7078:7077" extra_hosts: - "spark-master1:172.27.1.100" - "spark-master2:172.27.1.120" - "spark-worker1:172.27.1.101" - "spark-worker2:172.27.1.102" - "spark-worker3:172.27.1.103" spark-master2: image: spark-master:v1 container_name: spark-master2 hostname: spark-master2 restart: always networks: spark-network: ipv4_address: 172.27.1.120 ports: - "8080:8080" - "7077:7077" extra_hosts: - "spark-master1:172.27.1.100" - "spark-master2:172.27.1.120" - "spark-worker1:172.27.1.101" - "spark-worker2:172.27.1.102" - "spark-worker3:172.27.1.103" spark-worker1: image: spark-worker:v1 container_name: spark-worker1 hostname: spark-worker1 restart: always networks: spark-network: ipv4_address: 172.27.1.101 extra_hosts: - "spark-master1:172.27.1.100" - "spark-master2:172.27.1.120" - "spark-worker1:172.27.1.101" - "spark-worker2:172.27.1.102" - "spark-worker3:172.27.1.103" spark-worker2: image: spark-worker:v1 container_name: spark-worker2 hostname: spark-worker2 restart: always networks: spark-network: ipv4_address: 172.27.1.102 extra_hosts: - "spark-master1:172.27.1.100" - "spark-master2:172.27.1.120" - "spark-worker1:172.27.1.101" - "spark-worker2:172.27.1.102" - "spark-worker3:172.27.1.103" spark-worker3: image: spark-worker:v1 container_name: spark-worker3 hostname: spark-worker3 restart: always networks: spark-network: ipv4_address: 172.27.1.103 extra_hosts: - "spark-master1:172.27.1.100" - "spark-master2:172.27.1.120" - "spark-worker1:172.27.1.101" - "spark-worker2:172.27.1.102" - "spark-worker3:172.27.1.103" networks: spark-network: driver: bridge ipam: driver: default config: - subnet: 172.27.1.0/24
问题总结:
1.WARNING: IPv4 forwarding is disabled. Networking will not work
解决方案
vi /etc/sysctl.conf
新增一行
net.ipv4.ip_forward=1
重启network服务
systemctl restart network
查看是否修改成功
sysctl net.ipv4.ip_forward
(返回为"net.ipv4.ip_forward = 1",表示成功)