遥感期刊论文速读1(2021年8月12日)
ISPRS Journal 期刊论文2021年3月-5月
- Deep multisensor learning for missing-modality all-weather mapping 用于缺失模态全天候制图的深度多传感器学习
-
- 1.关键点:
- 2.相关工作
- 3.深度多传感器学习
-
- 3.1 The meta-sensory representation hypothesis
- 3.2 Prototype
- 结论
- A Global Context-aware and Batch-independent Network for road extraction from VHR satellite imagery
-
- 1.关键点
- 2. 网络结构
- Building outline delineation: From aerial images to polygons with an improved end-to-end learning framework
-
- 1.关键点
- 2.摘要
- 3. 网络架构
- 4.结论
- Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation
-
- 1. 关键点:域适应、弱监督
- Learning from multimodal and multitemporal earth observation data for building damage mapping
-
- 1.关键点
- 2.摘要
- 3.网络结构
- 4.结论
- GAMSNet: Globally aware road detection network with multi-scale residual learning
-
- 1.关键点
- 2.网络结构
- 3.结论
- 4.写作可以参考
- CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery 用于光学遥感影像变化检测的跨层卷积神经网络
-
- 1.关键点
- 2.网络结构
- 3.结论
- A geographic information-driven method and a new large scale dataset for remote sensing cloud/snow detection 一种地理信息驱动的遥感云/雪检测方法和新的大规模数据集
-
- 1.关键点
- 2.网络结构
- 3.结论
- PBNet: Part-based convolutional neural network for complex composite object detection in remote sensing imagery 基于部分的卷积神经网络,用于遥感影像中复杂复合物体检测
-
- 1.摘要
Deep multisensor learning for missing-modality all-weather mapping 用于缺失模态全天候制图的深度多传感器学习
武大张良培钟燕飞团队论文
1.关键点:
缺失模态问题,meta-sensory representation
针对实际应用场景中,并非所有数据源都可用的,这种缺失模态问题,提出了一种多传感器数据驱动的深度多传感器学习方法,通过学习meta-sensory representation解决该问题。首次提出meta-sensory representation假设,揭示了基于不同传感器数据训练的深层模型的本质区别在于:传感器不变操作和传感器特征操作的参数分布。这里有点像解耦出特定传感器的知识和传感器无关的知识。基于该假设,提出了一个学习meta-sensory representation的原型网络。该网络通过对知识保持机制进行建模,使用提出的差异对齐操作(DiffAlignOp)来学习元感觉表征。DiffAlignOp使原型网络能够动态生成特定于传感器的网络,以便从无需注册的多传感器数据中收集监控信号。这种动态的网络生成是可区分的。因此,可以获得多传感器梯度来学习meta-sensory representation。
为了展示深度多传感器学习的灵活性和实用性,本文进行了全天候映射在缺失通道场景中的应用。在空间分辨率为0.5m的高分辨率光学图像和SAR图像组成的大型公共多传感器全天候地图数据集上进行的实验结果表明,深度多传感器学习在性能和稳定性方面优于其他学习方法,并揭示了meta-sensory representation在多传感器遥感应用中的重要性。
2.相关工作
- 知识迁移
finetune,域适应等。缺点是缺乏知识保留机制,在迁移的过程中容易忘记预训练的表达,因此多传感器遥感影像需要一种知识保留的学习方法。(一般迁移到新领域的时候,在适应新领域的数据分布时,会一定程度上忘记旧领域的知识,这也是增量/持续学习着重要解决的问题) - 知识蒸馏
也是说广义知识蒸馏(KD),可以看作模态蒸馏。以多种传感器学习到的表达为教师模型,以单一模态传感器数据为学生模型的输入,将教师模型学习到的知识转移到学生模型。数据要求较高。 - 自监督
自监督能从未标记的数据学习到优异的特征表达。但是同样对数据需求较高。
3.深度多传感器学习
核心思想在于利用免注册的多传感器数据从知识保留的角度学习meta-sensory representation,(我翻译为“元传感器表征”),用于学习训练原型网络并将其应用于缺失模态场景的全天候制图。
3.1 The meta-sensory representation hypothesis
通过SAR和光学模型的卷积、BN的权重,BN的bias进行距离度量,提出了该假设。
3.2 Prototype
主要思想就是学习到元传感器表达和特定的传感器表达(如RGB-Net学习到的特征表达和SAR-Net学习到特征表达)。
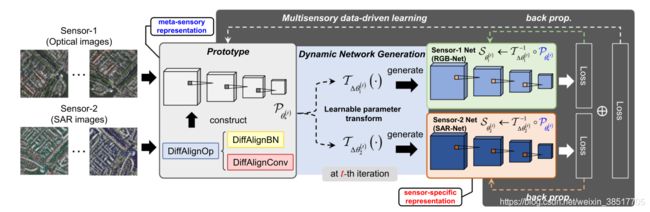
##
结论
在本文中,我们提出了一种多传感器数据驱动的学习方法,即深度多传感器学习,它通过学习元传感器表示来利用多传感器数据,在知识保留的新视角下,进行缺失模态全天候映射。为了探索元感官表征,首先提出了元感官表征假设,其中我们发现在来自不同传感器的数据上训练的深度模型的本质区别在于传感器不变和传感器特定的参数分布操作。基于这个假设,我们进一步提出了一个原型网络,以无注册的方式学习元感官表征,用于知识保留机制,该机制由许多 DiffAlignOps 构建。 DiffAlignOp 构建块为原型网络提供了动态网络生成的能力。这意味着原型网络可以使用多传感器数据进行训练,以获得更强大的元感官表示,从而在缺失模态场景中改进特定于传感器的深度模型。在大型公共多传感器数据集上获得的实验结果表明,深度多传感器学习比其他方法表现更好且更稳定。此外,综合消融研究表明,深度多传感器学习可以有效地利用多传感器数据来改善元传感器表征,从而改进传感器特定的表示。同时,当多传感器数据类型越多时,深度多传感器学习可以带来更多改进,这显着提升了多传感器数据在多传感器遥感应用中的开发潜力。未来,我们将进一步探索多传感器协作遥感应用的元传感器表示,例如使用高光谱图像和超高分辨率图像的细粒度土地覆盖制图,超越缺失模态应用场景。
A Global Context-aware and Batch-independent Network for road extraction from VHR satellite imagery
地大武汉关庆峰、朱琪琪团队。
1.关键点
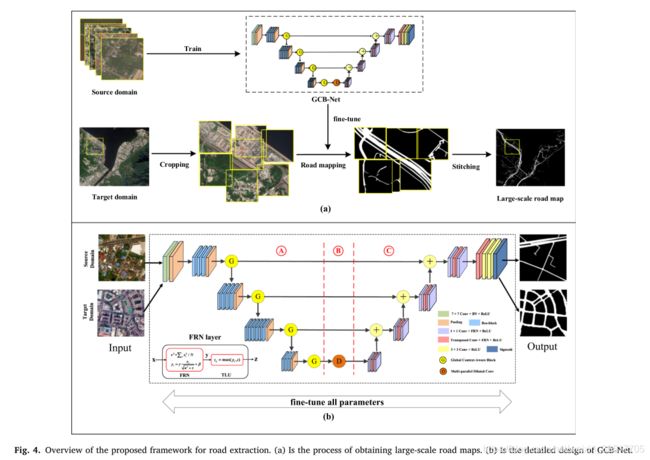
全局上下文感知模块(GCA)和Batch-independent(滤波器响应归一化FRN,消除Batch依赖)
前者用于集成全局上下文特征,后者用于增强原始基础网络,消除批量依赖以加速学习并进一步提升模型的鲁棒性。
提出一个大规模道路提取数据集。
2. 网络结构
Building outline delineation: From aerial images to polygons with an improved end-to-end learning framework
1.关键点
建筑物轮廓线绘制
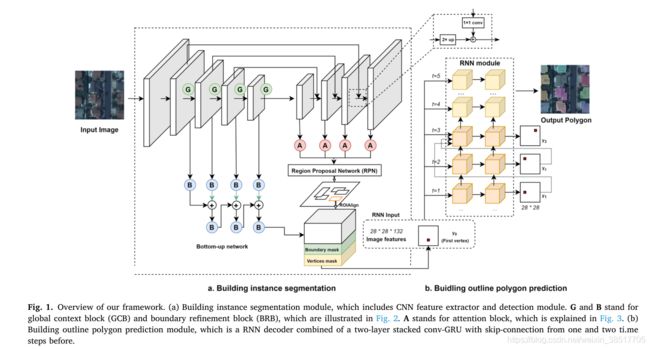
提出一种方法,该方法可以在端到端的深度学习框架内以矢量格式预测正则化建筑轮廓。
2.摘要
我们框架的主要思想是学习预测建筑物关键顶点的位置并按顺序连接它们。所提出的方法基于PolyMapper。我们通过引入全局上下文和边界细化块来升级特征提取,并添加通道和空间注意模块以提高检测模块的有效性。此外,我们引入了堆叠 conv-GRU 以进一步保留顶点之间的几何关系并加速推理。我们在两个大规模 VHR-RS 建筑提取数据集上测试了我们的方法。与 Mask R-CNN 和 PolyMapper 相比,COCO 和 PoLiS 指标的结果表现出更好的性能。具体来说,与 PolyMapper 相比,我们实现了 4.2 掩模平均精度 (mAP) 和 3.7 平均平均召回率 (mAR) 绝对改进。此外,定性比较表明,我们的方法显着改善了各种形状建筑物的实例分割。
3. 网络架构
4.结论
在这项工作中,我们研究了一种改进的端到端学习框架,用于多边形格式的正则化建筑轮廓提取。我们方法的整体工作流程基于 CNN RNN 架构,其中 CNN 作为图像特征提取器,RNN 一次解码一个多边形顶点。给定输入的 VHR RS 图像,我们的方法可以自动生成拓扑结果。该框架将传统的多步骤工作流程(包括特征提取、语义分割、矢量化和形状细化)转变为改进的端到端深度学习架构。这是从遥感图像构建轮廓映射的完全自动化的飞跃。此外,由于建筑对象被描述为独立的对象实例,它们可以被进一步分析以提取其他特征,例如屋顶类型和建筑功能,从而实现更详细的映射、3D 重建和规划应用。在地球观测大数据时代背景下,该方法在自动化、精确制图和更新等应用场景中具有很大的泛化潜力。在 PolyMapper (Li et al., 2019) 的工作之后,我们引入了几项改进,包括对主干、检测和循环模块的增强。除了 COCO 度量之外,我们还应用了 PoLiS 距离度量,通过考虑多边形之间的位置精度和形状差异来评估结果。我们在两个开源基准数据集上的结果表明,考虑到定量和定性标准,在描绘建筑轮廓方面具有很高的准确性。我们的方法在建筑物形状规则且排列稀疏的地区(例如北美和中国的城市地区)显示出高性能。在布置更紧凑且屋顶材料复杂的情况下(例如,在非正规住区或贫民窟),性能可以进一步提高。另一个具有挑战性的情况是形状复杂的大型联排别墅,这是许多欧洲城市的典型情况。对于未来的工作,我们计划从以下角度改进框架:(1)将轻量级模型引入主干或检测模块;或 (2) 对多任务学习应用统一优化,例如将不确定性带入多任务损失函数中;或 (3) 引入 3D 信息以进一步提高提取的有效性
Learning deep semantic segmentation network under multiple weakly-supervised constraints for cross-domain remote sensing image semantic segmentation
多重弱监督约束下学习深度语义分割网络用于跨域遥感图像语义分割
武大和阿里巴巴
1. 关键点:域适应、弱监督
为了缓解语义分割跨域导致的性能衰减,添加了多个弱监督约束(包括弱监督传递不变约束(WTIC)、弱监督伪标签约束(WPLC)和弱监督旋转一致性约束(WRCC) )
具体来说,就是采用DualGAN把目标域数据集转换到源域数据集,类似于风格迁移。
本文在两种跨域的场景进行实验,包括跨地理位置和跨成像模式,验证了模型的优越性。数据集和代码已公开https://github.com/te-shi/MUCSS
Learning from multimodal and multitemporal earth observation data for building damage mapping
从多模态和多时相地球观测数据中学习建筑物损毁制图。
1.关键点
考虑三种灾害类型(地震、海啸和台风),分析灾前灾后影像采用相同和不同和融合模态数据对制图的影响。
2.摘要
地球观测 (EO) 技术,如光学成像和合成孔径雷达 (SAR),为持续监测不断发展的城市环境提供了极好的手段。值得注意的是,在大规模灾害(例如海啸和地震)的情况下,响应时间非常紧迫,来自两种数据模式的图像可以相互补充,以准确传达灾难后果中的完整损坏情况。然而,由于天气和卫星覆盖等多种因素,哪种数据模式将首先用于快速灾害响应工作通常是不确定的。因此,可以利用所有可访问的 EO 数据集的新方法对于灾害管理至关重要。在这项研究中,我们开发了一个用于构建损伤映射的全局多模态和多时态数据集。我们纳入了三种灾害类型(即地震、海啸和台风)的建筑物损坏特征,并考虑了三种建筑物损坏类别。全球数据集包含每次灾难前后获得的高分辨率 (HR) 光学图像和高到中等分辨率的 SAR 数据。使用这个综合数据集,我们分析了用于损伤映射的五种数据模态场景:单模(光学和 SAR 数据集)、跨模态(灾前光学和灾后 SAR 数据集)和模式融合场景。我们基于深度卷积神经网络 (CNN) 算法定义了用于损坏建筑物语义分割的损坏映射框架。我们还将我们的方法与另一种最先进的损伤映射模型进行了比较。结果表明,我们的数据集与深度学习网络一起,为所有数据模式场景提供了可接受的预测。我们还发现,交叉模态映射的结果与融合传感器和光学模式分析获得的结果相当。
3.网络结构

4.结论
在这项研究中,我们创建了一种新的 BDD,考虑了三个层次的损坏和多个多模态卫星图像(光学成像和 SAR 数据),特别适用于未来灾害情况下的应急响应。我们提出了一个基于注意力 U-Net 架构的损伤映射框架。考虑到紧急灾害响应数据可用性的不同和现实场景(单模式、跨模式以及光学和 SAR 数据集的融合),该网络经过了广泛的训练。此外,我们将我们的结果与使用 xView2 挑战赛获胜解决方案的修改版本的第二个模型进行了比较。我们使用光学图像和融合数据集证明了我们提出的模型和基于 xView2 的模型具有一致的性能。==此外,我们发现我们用光学图像训练的网络可以准确地提取和分类建筑物损坏,而无需任何额外的输入(建筑物蒙版)。此外,通过整合灾前光学图像和灾后SAR数据,可以获得可接受的分类结果。==在未来的研究中,我们将通过包括来自世界各地的其他大规模灾害以及具有多种空间分辨率的遥感数据来扩展我们数据集的当前版本。此外,我们计划考虑到训练和测试数据集的灾难性拆分来分析不同的学习场景。这项研究的结果是开发一个全面运行的全天候建筑物损坏测绘系统的初始阶段。
GAMSNet: Globally aware road detection network with multi-scale residual learning
GAMNet:具有多尺度残差学习的全局感知道路检测网络
张良培钟燕飞团队
1.关键点
针对道路提取的碎片化问题,同时考虑图像的复杂背景。在分析现有道路检测方法的基础上,发现捕获远程依赖可以显著提高道路识别性能。因此提出了一种多尺度残差学习的新型全局感知道路检测网络(GAMS-Net)。其中,应用多尺度残差学习获得多尺度特征并扩展感受野,并使用全局感知操作捕获空间上下文依赖关系和通道间依赖关系。通过长距离捕获有用信息,GAMS-Net 可以显着提高道路识别性能。使用公开的 DeepGlobe 道路数据集和大尺度图像验证了所提出方法的优点,实验结果证实了所提出方法的优越性。
2.网络结构

3.结论
在这项研究中,提出了一种用于道路检测的具有多尺度残差学习的新型全局感知网络(GAMS-Net),可以有效提高道路检测性能。道路具有自然连通性,但常见的道路检测网络具有局部感受野。为了解决这个问题,GAMS-Net 专注于提供多尺度特征并扩大残差块中的感受野,同时从网络瓶颈中的空间和通道维度捕获长距离依赖关系。本研究获得的实验结果表明,当道路被树木、建筑物等造成的遮挡和阴影遮挡时,以及道路纹理非常粗糙时,所提出的GAMS-Net方法可以有效提高道路检测结果。与周围物体相似。在线评估和离线实验的定量结果也证实了所提出方法的优越性。同时,GAMS-Net在转移到其他新的大规模区域时表现比其他模型好得多,展示了其强大的泛化能力。然而,对于训练集中看不见的图像仍然存在性能下降。在我们未来的工作中,我们将进行一些相关的研究,以减少训练图像和测试图像来自不同区域时的领域差距。
4.写作可以参考
CLNet: Cross-layer convolutional neural network for change detection in optical remote sensing imagery 用于光学遥感影像变化检测的跨层卷积神经网络
武大遥感与信息工程学院Zhi Zhenga, Yi Wana,, Yongjun Zhanga,, Sizhe Xianga, Daifeng Pengb,c, Bin Zhanga
代码地址:https://skyearth.org/public ation/project/CLNet
1.关键点
跨层模块结合多尺度特征和多级上下文信息。CLB (cross-layer block)
设计的 CLB 从一个输入开始,然后分成两个平行但不对称的分支,利用不同的步长提取多尺度特征;来自相反分支但具有相同大小的特征图被连接起来以合并多级上下文信息。设计的 CLB 聚合了多尺度特征和多级上下文信息,因此所提出的 CLNet 可以重用提取的特征信息并捕获复杂场景中准确的像素变化。
2.网络结构
两张图分别是整体网络结构和CLB模块的细节。
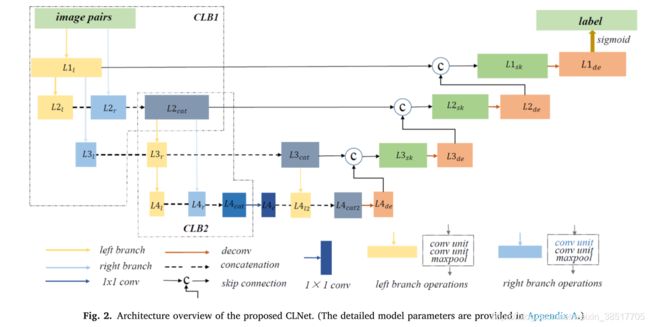
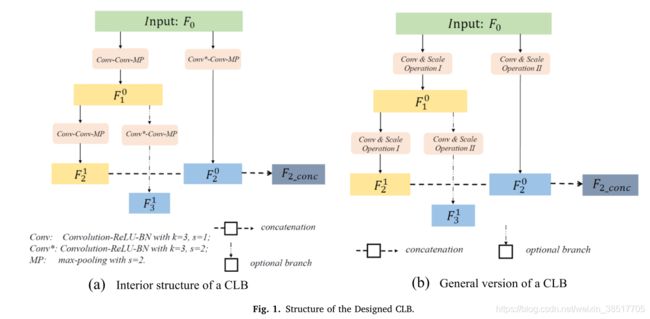
主要是对于同一个输入,采用不同步长的卷积核进行处理,然后再拼接到一起。
3.结论
在本文中,针对双时态 ORSICD(Pixel-wise optical remote sensing imagery change detection ) 提出了一种名为 CLNet 的新型端到端卷积神经网络,其中嵌入了两个新的 CLB。设计的 CLB 可以有效地聚合多尺度特征和多级上下文信息,并且能够以最小的额外内存要求重用信息。在公共 VHR 数据集和两个建筑物变化检测数据集上的实验表明,与几种 SOTA 方法相比,所提出的 CLNet 获得了更高的准确性,生成了更好的变化图,并实现了具有竞争力的准确性/效率权衡,这证明了提议的 CLNet。此外,由于输入图像对作为网络输入集成在一起,因此它具有扩展到多时态图像序列的变化检测任务的巨大潜力。设计的 CLB 是一个通用模块,因此可以使用一些基本/高级模块进行扩展。此外,本文提出的 CLNet 仍有一些局限性(即其大量参数,增加了 GPU 内存需求)。未来的工作将集中在将设计的 CLB 转移到其他遥感任务和设计新的轻量级 ORSICD 架构上。
A geographic information-driven method and a new large scale dataset for remote sensing cloud/snow detection 一种地理信息驱动的遥感云/雪检测方法和新的大规模数据集
1.关键点
把经纬度、高程信息和图像同时输入到一个双输入的DenseUnet中,利用free的地理信息先验知识防止云和雪的误判。比如在高海拔区域,白色的可能是雪;但是在低海拔低纬度的夏季,白色的一定是云。
2.网络结构

以上的辅助图指的就是经度图、纬度图和高程图,前两者可以从影像的文件名里以一定的规则转化为栅格图像。
3.结论
在本文中,提出了一种名为“地理信息驱动神经网络(GeoInfoNet)”的遥感图像云雪检测新方法。与以往单纯基于图像数据进行检测的方法不同,该方法将图像和地理信息(海拔、纬度和经度)结合起来进行训练和检测。还构建了一个用于云雪检测的大型数据集,其中包含4,168个场景和相应的地理信息。大量实验验证了集成地理信息用于云雪检测任务的有效性。该方法在很大程度上优于其他最先进的方法。此外,还呈现了可视化以显示该方法学习的内容以及网络的不同部分对检测任务的贡献程度。未来的工作包括四个部分。第一部分是网络计算效率的提升。第二部分工作是整合其他类型的地理信息(如太阳高度角、成像时间、温度等)。第三,云影将在未来的工作中重点关注,并将此信息源整合到数据集中。最后,将研究特定位置的时间序列中的云雪检测(或多时间云雪检测)。
PBNet: Part-based convolutional neural network for complex composite object detection in remote sensing imagery 基于部分的卷积神经网络,用于遥感影像中复杂复合物体检测
1.摘要
年来,基于深度学习的算法为刚性物体检测带来了很大的改进。除了刚性物体外,遥感图像还包含许多复杂的复合物体,如污水处理厂、高尔夫球场、机场等,它们既没有固定的形状,也没有固定的尺寸。在本文中,我们通过实验验证现有方法在检测复合物体方面的结果不够令人满意。因此,我们提出了一个统一的基于部分的卷积神经网络(PBNet),它是专门为遥感图像中的复合目标检测而设计的。 PBNet 将复合对象视为一组部件,并将部件信息合并到上下文信息中以改进复合对象检测。正确的零件信息可以指导复合物体的预测,从而解决各种形状和尺寸带来的问题。为了生成准确的零件信息,我们设计了一个零件定位模块,以仅使用边界框注释来学习零件点的分类和定位。上下文细化模块旨在通过聚合局部上下文信息和全局上下文信息来生成更具辨别力的特征,从而增强零件信息的学习并提高特征表示的能力。我们从公共数据集中选择了三类典型的复合对象进行实验,以验证我们方法的检测性能和泛化能力。同时,我们针对一种典型的复杂复合对象(即污水处理厂)构建了一个更具挑战性的数据集。它是指来自权威机构和专家的相关信息。该数据集包含长江流域七个城市的污水处理厂,覆盖范围广泛。在两个数据集上的综合实验表明,PBNet 超越了现有的检测算法并达到了最先进的准确性。