生产脚本1
1、用户登录失败五次写入黑名单禁止登陆
通过lastb获取登录失败的IP及登录失败的次数
#!/usr/bin/bash
# 通过lastb获取登录失败的IP及登录失败的次数
lastb | awk '{print $3}' | grep ^[0-9] | sort | uniq -c | awk '{print $1"\t"$2}' > /tmp/host_list
list=`cat /tmp/host_list`
line=`wc -l /tmp/host_list | awk '{print $1}'`
count=1
# 如果/tmp/host_list中有数据,循环至少需要执行一次
while [[ "$line" -ge "$count" ]]; do
ip_add=`echo $list | awk '{FS="\t"} {print $2}'`
num=`echo $list | awk '{FS="\t"} {print $1}'`
# 登录失败达到5次就将该IP写入文件
if [[ "$num" -ge 5 ]]; then
grep "$ip_add" /etc/hosts.deny &> /dev/null
if [[ "$?" -gt 0 ]]; then
# --------> 此处添加当前系统时间,请根据实际情况定义日期格式
echo "# $(date +%F' '%H:%M:%S)" >> /etc/hosts.deny
echo "sshd:$ip_add" >> /etc/hosts.deny
fi
fi
let count+=1
# 删除已经写入文件的IP
sed -i '1d' /tmp/host_list
# 修改$list变量
list=`cat /tmp/host_list`
done
# 清空临时文件
echo '' > /tmp/host_list
exit 0
~
~
~ 2、日志切割脚本
vi runlog.sh
#!/bin/bash
# 设置日志文件存放目录
logs_path="/var/log/nginx/"
backup_path="/var/log/nginx/logs/"
# 设置pid文件
pid_path="/run/nginx.pid"
# 重命名日志文件
mv ${logs_path}/access.log ${backup_path}/access_$(date -d "yesterday" +"%Y%m%d").log
mv ${logs_path}/error.log ${backup_path}/error_$(date -d "yesterday" +"%Y%m%d").log
# 向nginx主进程发信号重新打开日志
kill -USR1 `cat ${pid_path}`
# 压缩
gzip ${backup_path}/access_$(date -d "yesterday" +"%Y%m%d").log
gzip ${backup_path}/error_$(date -d "yesterday" +"%Y%m%d").log
# 删除超过指定时间的日志文件,单位:天
find $backup_path -name "*.gz" -type f -mtime +30 -exec rm -rf {} \;3、nginx状态监控脚本
#!/bin/bash
nginx=/usr/local/nginx/sbin/nginx
read -ep "请输入要执行的命令(start/stop/status/reload):" sta
case $sta in
#启动nginx选项
start)
#先检测nginx是否已经启动
netstat -nlpt | grep nginx &> /dev/null
if [ $? -eq 0 ];then
echo "nginx已经启动!"
else
echo "开始启动nginx!"
$nginx
fi
;;
#停止nginx运行
stop)
$nginx -s stop
#判断nginx是否已经停止
if [ $? -eq 0 ];then
echo "nginx已经停止运行!"
else
echo "nginx停止失败,请重试!"
fi
;;
#nginx的状态
status)
netstat -nlpt | grep nginx &> /dev/null
if [ $? -eq 0 ];then
echo "nginx已经启动!"
else
echo "nginx没有运行!"
fi
;;
#重载nginx
reload)
$nginx -s reload
if [ $? -eq 0 ];then
echo "nginx重载成功!"
else
echo "nginx重载失败,请重试!"
fi
;;
*)
echo "请按提示正确输入!"
;;
esac
4、监控系统中的cpu、内存、硬盘、、使用率超过85%进行邮件告警
#!/bin/bash
now=`date +%Y-%m-%d` #显示现在的时间日期
#cpu使用值
cpu_warn='85'
#mem空闲值本机器为4000所以设置成15%也就是600
mem_warn='600'
#disk使用值
disk_warn='85'
#---cpu
item_cpu () {
cpu_idle=`top -b -n 1 | grep Cpu | awk '{print $8}'|cut -f 1 -d "."` #top -b -n 1 查看所有运行的经常的状态 grep cpu 过滤出cpu的那一项 awk '{print $8}’ 打印出第八项 cut -f 1 -d "." 显示第一个字段的内容以. 号作为分隔符。这段话就是用来计算cpu的空闲率
cpu_use=`expr 100 - $cpu_idle` #cpu的使用率=100-cpu空闲率
echo "$now 当前cpu使用率为 $cpu_use" >> /tmp/monitoring.log #输出结果到指定的文档
if [ $cpu_use -gt $cpu_warn ] #当cpu的使用率大于我们设定的使用率时
then
echo "cpu过载请及时处理" | mail -s "cpu运行状态" [email protected] #警报信息发送到邮箱
else
echo "cpu运行状态良好" | mail -s "cpu运行状态" [email protected]
fi
}
#---mem
item_mem () {
#MB为单位
mem_free=`free -m | grep "Mem" | awk '{print $4+$6}'` #查看内存使用状态过滤出men的哪一项并打印出第四项加第六项的值
echo "$now 当前内存剩余空间为 ${mem_free}MB" >> /tmp/monitoring.log #内存空闲值输出到指定文档
if [ $mem_free -lt $mem_warn ] #如果空闲值小于我们设定的值
then
echo "内存过载请及时处理 " | mail -s "内存运行状态" [email protected]
#输出警告提示发送到邮箱
else
echo "内存运行状态良好 " | mail -s "内存运行状态" [email protected]
fi
}
item_disk () {
disk_use=`df -P | grep /dev/mapper/centos-root | grep -v -E '(tmp|boot)' | awk '{print $5}' | cut -f 1 -d "%"`
#查看硬盘的情况过滤出主硬盘那一项打印出第五项输出以%为分割点的第一个字符
echo "$now 当前磁盘使用率为 $disk_use" >> /tmp/monitoring.log #使用率输出到指定文档
if [ $disk_use -gt $disk_warn ] #如果使用率大于我们设定的值输出结果
then
echo "硬盘过载及时处理" | mail -s "硬盘运行状态" [email protected] #输出硬盘过载并发送到指定的邮箱
else
echo "硬盘运行状态良好" | mail -s "硬盘运行状态" [email protected]
fi
}
item_cpu
item_mem
item_disk5、监控系统中的IO await大于70进行邮件告警(可使用邮箱163、QQ、139、网易等)

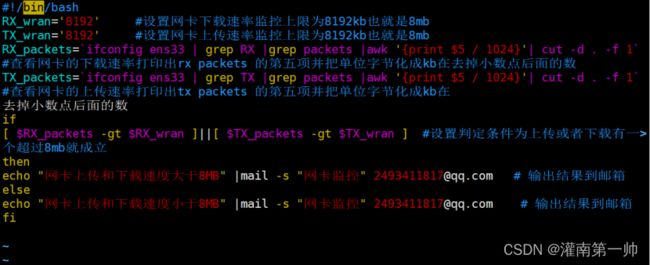
6、监控系统中的网络流量下载上传超过8M(可变)进行邮件告警(可使用邮箱163、QQ、139、网易等)
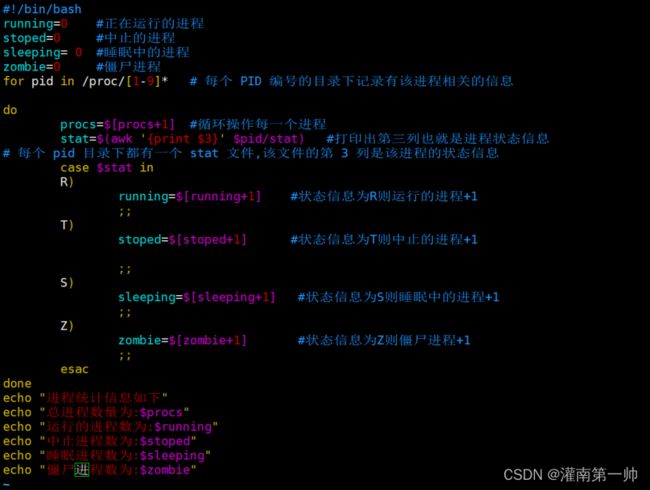
7、统计 Linux 进程相关数量信息
8、备份数据库表结构及表数据
在实际生产中常常针对数据库有这样的需求:
- 要求同时导出某数据库中所有数据表的表结构和数据;
- 要求仅导出部分表结构和每个表中数据数据;
- 要求仅导出某数据表的表结构和部分数据。
mysqldump -u ${user_name}@${datanode} \
-h ${proxy_ip} \
-P ${proxy_port} \
-p${pwd} \
--default-character-set=utf8 \
--hex-blob \
--events \
--routines \
--triggers \
--single-transaction \
--set-gtid-purged=ON \
--skip-lock-tables \
--no-create-db \
--no-create-info \
--complete-insert \
--databases ${db_name} \
--tables ${table_name} \
--where="TRANS_DT='20211214'" > result.sql
选项
--default-character-set=${charset_name} :指定通过变量 ${charset_name} 指定的字符集作为默认字符集;
--hex-blob :使用 16 16 16 进制格式导出二进制字段;
--events 或 -E :在导出的结果中包含事件调度器事件(Event Scheduler events),该选项需要用户对于数据库具有 EVENT 权限;
--routines 或 -R:在导出的结果中包含存储过程或函数,该选项需要用户对于数据库具有全局的 SELECT 权限;
--triggers :在导出的结果中包含每个数据表中的触发器,该选项默认生效,可以使用 --skip-triggers 来关闭;
--single-transaction:该选项使得再导出数据之前先将事务隔离级别设置为可重复读即 REPEATABLE READ ,然后向服务器发送一个 START TRANSACTION SQL 语句。
该选项仅对支持事务的数据表有效(如使用 InnoDB 引擎的数据表),最终可以实现导出的数据库中所有支持事务的数据表状态都在 START TRANSACTION 语句发出后的时间点一致;
对于使用 MyISAM 或者 MEMORY 这些不支持事务的引擎创建的数据表,导出的过程中这些数据表的状态是会发生改变的,如果希望实现上述类似的效果,则需要使用Flush tables with read lock; (简称 FTWRL)对整个数据库加全局读锁;
当使用该选项正在导出数据时,为了确保最终导出的数据有效(即数据表内容正确且 binlog 一致),其他和该数据库建立的连接不能使用下列任何语句:ALTER TABLE , CREATE TABLE , DROP TABLE , RENAME TABLE 以及 TRUNCATE TABLE 操作,因为可重复读即 REPEATABLE READ 隔离状态无法隔离上述语句,所以如果使用上述语句将导致导出的数据不正确或导出数据失败;
该选项和 --lock-tables 选项是互斥的,因为锁表即 LOCK TABLES 会导致任何未提交的事务隐式提交。
--lock-tables 或 -l :该选项会针对每一个被导出的数据库,在进行数据导出之前锁上其中的所有数据表,每个数据库中所有表的加锁级别都是 READ LOCAL ,此时对于使用 MyISAM 的数据表是可以进行数据并发插入的。
对于使用 InnoDB 这样支持事务的引擎,此时使用 --single-transaction 选项更为合适,因为后者压根无需锁表;
一些选项如 --opt 会自动开启 --lock-tables 选项,如果你不希望这样的效果,可以在所有选项之后加上 --skip-lock-tables 选项。
--set-gtid-purged=${value} :该选项用于使用基于 GTID (即全局事务标识符:Global Transaction Identifier)实现复制(replication)的服务器(即 gtid_mode=ON)。
该选项可控制 @@SESSION.sql_log_bin=0 语句是否包含在最终导出的数据文件中,在后续载入导出的数据文件时,该语句可以避免生成 binlog ;
当 ${value} 为 ON 时,SET @@SESSION.sql_log_bin=0 会被包含了最终导出的数据文件中。需要注意的是,如果指定该选项但是服务器上没有开启 GTID 机制,则会发生错误。
--skip-lock-tables :
--no-create-db 或 -n:如果指定了 --databases 或 --all-databases 选项,则该选项在导出数据文件中不包括 CREATE DATABASE 语句。
--no-create-info 或 -t:在导出的数据文件中不写入 CREATE TABLE 语句。
--complete-insert 或 -c:使用包括字段名的全插入语句。
--databases ${db_name} 或 -B:导出多个数据库。通常, mysqldump 会将命令行第一个名称参数视为数据库名,后续所有名称参数视为表名,使用这个选项,命令会将所有名称参数视为数据库名。CREATE DATABASE 和 USE 语句也会被包含在输出中;
该选项还可以用于导出 performance_schema 数据库,对于该数据库,即使指定 --all-databases 选项也不会导出。
--tables ${table_name} :mysqldump 命令将该选项之后的参数都视为数据表名。
9、预防脑裂脚本
检测思路:正常情况下keepalived的VIP地址是在主节点上的,如果在从节点发现了VIP,就设置报警信息。脚本(在从节点上)如下:
vim split-brainc_check.sh
#!/bin/bash
# 检查脑裂的脚本,在备节点上进行部署
LB01_VIP=192.168.1.229
LB01_IP=192.168.1.129
LB02_IP=192.168.1.130
while true
do
ping -c 2 -W 3 $LB01_VIP &>/dev/null
if [ $? -eq 0 -a `ip add|grep "$LB01_VIP"|wc -l` -eq 1 ];then
echo "ha is brain."
else
echo "ha is ok"
fi
sleep 5
done