Python爬虫——Urllib
目录
一、urllib库使用
二、请求对象的定制
三、编解码
1.get请求方式:urllib.parse.quote()
2.get请求方式:urllib.parse.urlencode()
3.post请求方式(百度翻译)
四、ajax的get请求(豆瓣电影前十页数据)
五、ajax的post请求(KFC前三页数据)
六、URLError\HTTPError
八、Handler处理器
九、代理服务器
1.代理ip
2.代理池
一、urllib库使用
# 模拟浏览器向服务器发送请求urllib . request . urlopen ()response 服务器返回的数据response的数据类型是 HttpResponse字节 ‐‐> 字符串#解码decoderesponse.read.decode('utf-8')字符串 ‐‐> 字节编码encoderead () 字节形式读取二进制 扩展: rede ( 5 ) 返回前几个字节readline () 读取一行readlines () 一行一行读取 直至结束#获取状态码response.getcode ()# 获取 urlresponse.geturl ()#获取 headersresponse.getheaders ()#下载urllib . request . urlretrieve (url,'文件名')请求网页请求图片请求视频
import urllib.request
url = 'http://www.baidu.com'
response = urllib.request.urlopen(url)
content = response.read().decode('utf-8')
content = response.read(5)
content = response.readline()
content = response.readlines()
print(response.getcode())
print(response.geturl())
print(response.getheaders())
urllib.request.urlretrieve(url,"baidu.html")
url_img = 'https://img0.baidu.com/it/u=4012520431,1093551712&fm=253&fmt=auto&app=138&f=JPEG?w=333&h=500'
urllib.request.urlretrieve(url_img,"lisa.jpg")
url_video = 'http://mediaplay.kksmg.com/2021/11/12/h264_450k_mp4_SHNewsHD30000002021111237854878091_aac.mp4'
urllib.request.urlretrieve(url_video,'飞船抵达国际空间站.mp4')二、请求对象的定制
把上面的url = 'http://www.baidu.com' 修改为:url = 'https://www.baidu.com' 运行时会发现显示出来的数据不全,这是因为我们遇到了反扒,而遇到反扒的原因是我们在访问时给到的数据不够完整。
UA介绍: User Agent中文名为用户代理,简称UA,它是一个特殊字符串头,使得服务器能够识别客户使用的操作系统及版本、CPU类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等。
查找自己电脑本机的User-Agent:打开谷歌浏览器 --> 右键点击检查 --> 点击网络(network)--> 刷新本网页 --> 点击‘名称’下面的第一个文件 --> 在右方表头(header)最下方就可以找到自己的User-Agent。
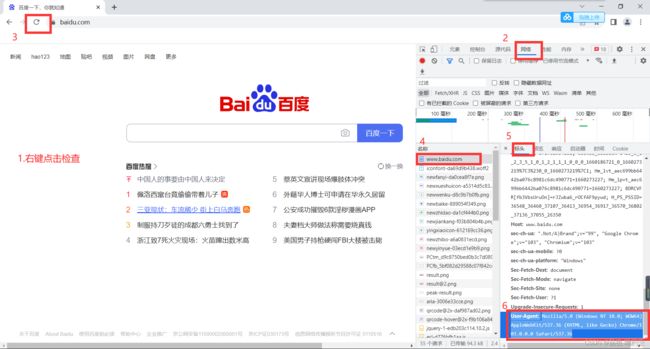
# 使用urllib来获取百度首页的源码
import urllib.request
# (1)定义url
url = 'https://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
# 因为urlopen方法中不能存储字典,所以headers不能传递进去
# 请求对象定制
# 注意:因为参数顺序的问题,不能直接写url和headers 原参数中间还有一个data,所以我们需要关键字传参
request = urllib.request.Request(url=url,headers=headers)
# (2)模拟浏览器向服务器发送数据
response = urllib.request.urlopen(request)
# (3)获取响应中的页面的源码
content = response.read().decode('utf-8')
# (4)打印数据
print(content)三、编解码
1.get请求方式:urllib.parse.quote()
urllib.parse.quote()方法可以把一个词转化为对应的unicode编码。
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd='
# 请求对象定制是为了解决反扒的第一种手段
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
# 将周杰伦三个字变为unicode编码格式
# 我们需要依赖于urllib.parse
name = urllib.parse.quote('周杰伦')
url = url + name
# 请求对象的定制
request = urllib.request.Request(url=url,headers = headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的内容
content = response.read().decode('utf-8')
# 打印数据
print(content)2.get请求方式:urllib.parse.urlencode()
在上个案例中使用rllib.parse.quote()方法可以传递一个参数,但是如果我们有两个参数或者更多是我们就需要使用 urllib.parse.urlencode()方法了。
import urllib.parse
import urllib.request
# https://www.baidu.com/s?wd=周杰伦&sex=男
base_url = 'https://www.baidu.com/s?'
data = {
'wd' : '周杰伦',
'sex' : '男',
'location' : '中国台湾省'
}
new_data = urllib.parse.urlencode(data)
# 请求资源路径
url = base_url + new_data
# 请求对象定制是为了解决反扒的第一种手段
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
# 请求对象的定制
request = urllib.request.Request(url = url,headers = headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取网页源码的数据
content = response.read().decode('utf-8')
# 打印数据
print(content)3.post请求方式(百度翻译)
以百度翻译为例:
案例一:
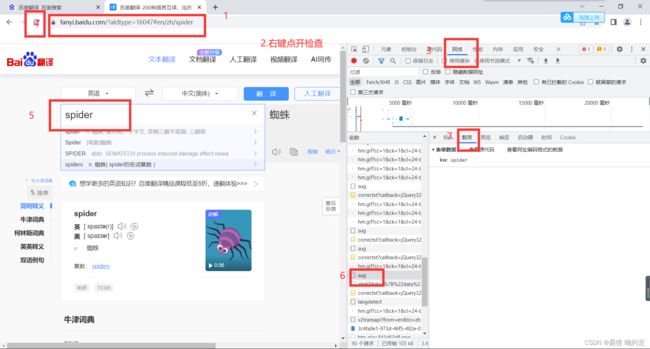
# post请求案例一
import urllib.request
import urllib.parse
import json
url = 'https://fanyi.baidu.com/sug'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
data = {
'kw' : 'spider'
}
# post请求的参数 必须进行编码
data = urllib.parse.urlencode(data).encode('utf-8')
# post的请求参数,是不对拼接在url的后面的 而是需要放在请求对象定制的参数中
# post请求的参数必须进行编码
request = urllib.request.Request(url = url,data = data,headers = headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 将字符串json转换为python的字典
obj = json.loads(content)
print(obj)案例二:
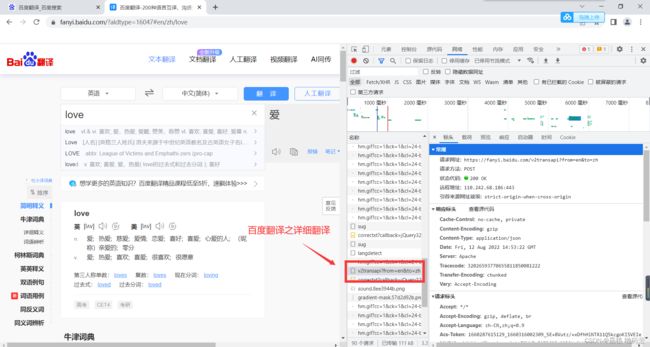
# post请求案例二:百度翻译之详细翻译
import urllib.request
import urllib.parse
import json
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Acs-Token': '1660287615129_1660351591633_SE+8Vutz/+xDfhHlNTX11Q5kcgoKISVEIe3SKT1Bgt14HAKcuMDbax4acagAshcT8VVEnI0Z3f2EmC0ROVo9hMRZJky17OvVYSml3pGHkcHTy9YebViI/TgqvJaWl6MAuuGwsSOY6fxCTXCDw1zKYYUSfHsSfU4FUmPxMBWn2EsXi9SK17J17TPgSR8OJe6/GiW0AGEngAfwqz4T+93PyimjaSfw4OCm/W2LMVy8Ugn8k9wcxIFSCMOFmCChJ/MSE3B/EehmL+bd4eA0PQ8kVC5hi5I8hFk9Y09NfSeUCmowcdtfxbcYvzR64aBXqLf5',
'Connection': 'keep-alive',
'Content-Length': '133',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'BIDUPSID=532072A821136DF8C2EB95AA81E78D9C; PSTM=1660186655; BAIDUID=532072A821136DF854C5AFDE13568E28:FG=1; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BAIDUID_BFESS=532072A821136DF854C5AFDE13568E28:FG=1; ZFY=sYlYXnP5MlA5Wb:Bj2GuHKBIx1zBseY:BhnC9G7hWJ0ic:C; RT="z=1&dm=baidu.com&si=spox3tvdb8&ss=l6pvshek&sl=1&tt=1ek&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=27g&ul=80v&hd=82o"; BA_HECTOR=8g8ha4a1050h2ka40h2h427j1hfbght16; APPGUIDE_10_0_2=1; FANYI_WORD_SWITCH=1; REALTIME_TRANS_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; BDUSS=lDckh2LUFyakVYfjNiR2w0a09YNVY0VVBzfk9BcDluWEgyQUhXeE1IZlItaDFqRUFBQUFBJCQAAAAAAAAAAAEAAADL8CCSWkwxMTcxMTI3AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANFt9mLRbfZiQW; BDUSS_BFESS=lDckh2LUFyakVYfjNiR2w0a09YNVY0VVBzfk9BcDluWEgyQUhXeE1IZlItaDFqRUFBQUFBJCQAAAAAAAAAAAEAAADL8CCSWkwxMTcxMTI3AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAANFt9mLRbfZiQW; BDRCVFR[feWj1Vr5u3D]=I67x6TjHwwYf0; delPer=0; PSINO=2; H_PS_PSSID=36548_36460_37115_37107_36413_36954_36917_36802_37136_26350; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1660314249,1660351574; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1660351588; ab_sr=1.0.1_OTlkYmM1ZmIxNmVhYTg0NWVhZWFjNDg0MGJlY2RlNmI1YzM3MDE4NmY5ZWEwNzM2NzRmOWViNjFjMDM3ODA1OTNmODM0OTAxNmZhYmQ0OGE0NDA0MjU2NTRmNjljYmMxYjExZTZjYThkOWI2MDhmZTA3NjY3OGU2M2JmNmE0YmEyOGRkZjAyMzY1NjZiZGI5ZDRlMmIxNWRiYWU3YTNjOTQxODBiMDQwODg3ZjAzOWIzMTU5YjQ0ZjJmZDljNmVi',
'Host': 'fanyi.baidu.com',
'Origin': 'https://fanyi.baidu.com',
'Referer': 'https://fanyi.baidu.com/?aldtype=16047',
'sec-ch-ua': '".Not/A)Brand";v="99", "Google Chrome";v="103", "Chromium";v="103"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
data = {
'from': 'en',
'to': 'zh',
'query': 'lo',
'transtype': 'realtime',
'simple_means_flag': '3',
'sign': '646722.867699',
'token': '98b2765edb67461fe2e8773520d0e91b',
'domain': 'common',
}
# post请求的参数 必须进行编码 并且调用encode方法
data = urllib.parse.urlencode(data).encode('utf-8')
# 请求对象的定制
request = urllib.request.Request(url = url,data = data,headers = headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8','ignore')
# 将字符串json转换为python的字典
obj = json.loads(content)
print(obj)四、ajax的get请求(豆瓣电影前十页数据)

# get请求
# 获取豆瓣电影的前十页数据,并且保存起来
# 第一页 https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=0&limit=20
# 第二页 https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20
# 第三页 https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=40&limit=20
# 第四页 https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=60&limit=20
# ......
# page 1 2 3 4
# start 0 20 40 60
#
# start (page - 1 ) * 20
# 请求对象定制
# 获取响应的数据
# 下载数据
import urllib.parse
import urllib.request
#请求对象的定制方法
def create_request(page):
base_url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start' : (page - 1) *20,
'limit' : 20
}
data = urllib.parse.urlencode(data)
url = base_url + data
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers)
return request
# 获取响应数据方法
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
# 下载的方法
def down_load(page,content):
with open('douban_'+ str(page) +'.json','w',encoding='utf-8')as fp:
fp.write(content)
# 程序入口
if __name__ == '__main__':
satrt_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束的页码'))
for page in range(satrt_page,end_page+1):
request = create_request(page)
content = get_content(request)
down_load(page,content)下载好的数据查看时,可是使用ctrl+alt+l 快捷键进行格式化,方便查看。
五、ajax的post请求(KFC前三页数据)
# post请求 KFC官网前三页数据
# 第一页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 北京
# pid:
# pageIndex: 1
# pageSize: 10
# 第二页
# http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname
# cname: 北京
# pid:
# pageIndex: 2
# pageSize: 10
import urllib.request
import urllib.parse
# 请求对象定制
def create_request(page):
base_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname'
data = {
'cname': '北京',
'pid':'',
'pageIndex': page,
'pageSize': 10
}
data = urllib.parse.urlencode(data).encode('utf-8')
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=base_url,data=data,headers=headers)
return request
# 获取网页源码
def get_content(request):
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
return content
# 下载
def down_load(page,content):
with open('kfc_'+ str(page) + '.json','w',encoding='utf-8')as fp:
fp.write(content)
# 程序入口
if __name__ == '__main__':
start_page = int(input('请输入起始页码'))
end_page = int(input('请输入结束页码'))
for page in range(start_page,end_page+1):
request = create_request(page)
content = get_content(request)
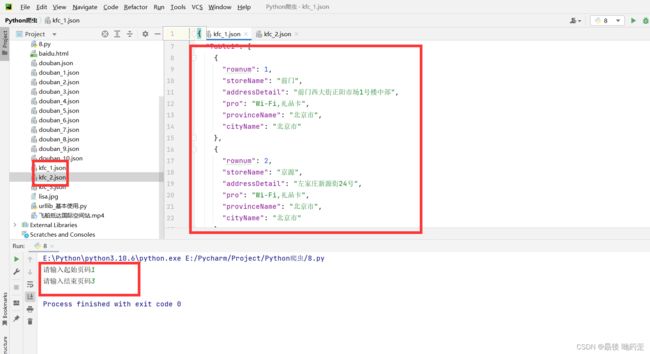
down_load(page,content)效果:
六、URLError\HTTPError
import urllib.request
import urllib.error
# url = 'https://blog.csdn.net/z1171127310/article/details/1262473344'
url = 'http://goudan111.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
try:
request = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf-8')
print(content)
except urllib.error.HTTPError:
print('系统正在升级。。。')
except urllib.error.URLError:
print('我都说了 系统正在升级。。。')七、cookie登录(QQ空间)
# 微博的cookie登录
# 使用场景:数据采集的时候,需要绕过登录,然后进入到某个页面
# 个人信息页面时utf-8 但是还是报了编码错误,因为并没有进入到个人信息页面,而是跳转到了登录页面,登录页面不是utf-8所以报错。
import urllib.request
url = 'https://user.qzone.qq.com/1171127310/infocenter'
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': '1171127310_todaycount=0; 1171127310_totalcount=29657; uin=o1171127310; skey=@1c2vFzRLb; RK=Y02VE6eAQP; ptcz=bf44fdb20b8c10bc10c7eeb146c84a61ef7123206e24f4c3e005a345c3265378; p_uin=o1171127310; pt4_token=kG0gP1AXh3vhn1Yq1l2PoWXvSu1s1P1yeafLfTffIuw_; p_skey=wlc1g6ZsTihytGjRqxqLEnfPlWr*5JiDjHJCeiPpJCA_; Loading=Yes; qz_screen=1536x864; pgv_pvid=1895878954; pgv_info=ssid=s3577922304; QZ_FE_WEBP_SUPPORT=1; cpu_performance_v8=7',
'if-modified-since': 'Sat, 13 Aug 2022 08:54:13 GMT',
'q-guid': '8e45603f6446a50831a18f40377988cb',
'q-info': 'F0D8GzBmUkF40gaihAcKXOp27oJXLZP7cH54b1Rgo6zzq8QYsXx2imY8PJbMAM8CE1MGA3gv3y3Q0pYmhBm1ed9rK2Dmk0cSrWoNL7dl/IAU1aFoYcbEOk2EobaleIYuv/uAemhm4DWPXyrdRfbVX4DgpjCaDyEgStGQFE6vAN3ridccqE+ztf/Zjox1Hd70psltS08iw3z/77UGU/v+HxMzhHdb0ly6t+St8u2JGcc=',
'q-ua2': 'PR=PC&CO=WBK&QV=3&PL=WIN&PB=GE&PPVN=11.1.0.5140&COVC=049400&CHID=45094&RL=1920*1080&MO=QB&VE=GA&BIT=64&OS=10.0.19043',
'sec-ch-ua': '";Not A Brand";v="99", "Chromium";v="94"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.172.400 QQBrowser/11.1.5140.400',}
# 请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器向服务器发送请求
response = urllib.request.urlopen(request)
# 获取响应的数据
content = response.read().decode('utf-8')
# 将数据保存在本地
with open('qq空间.html','w',encoding='utf-8')as fp:
fp.write(content)八、Handler处理器
# handler处理器
# 需求:使用hander来访问百度 获取网页源码
import urllib.request
url = 'http://www.baidu.com'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers)
# handler build_opener open
# (1)获取handler对象
handler = urllib.request.HTTPHandler()
# (2)获取opener对象
opener = urllib.request.build_opener(handler)
# (3)调用open方法
response = opener.open(request)
# 以上三步等价于 response = urllib.request.urlopen(request) 但是使用该三步可以方便于之后使用代理IP
content = response.read().decode('utf-8')
print(content)九、代理服务器
1.代理ip
当自身ip被封时,可以使用代理ip
代理ip免费网址:国内高匿免费HTTP代理IP - 快代理
#
import urllib.request
url = 'https://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
#请求对象的定制
request = urllib.request.Request(url=url,headers=headers)
# 模拟浏览器访问服务器
# response = urllib.request.urlopen(request)
proxies = {
'http':'58.215.201.98:56566'
}
# handler builder_opener open
handler = urllib.request.ProxyHandler(proxies= proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
# 获取响应的信息
content = response.read().decode('utf-8')
# 保存在本地
with open('daili.html','w',encoding='utf-8')as fp:
fp.write(content)2.代理池
import random
import urllib.request
proxies_pool = [
{'http':'58.215.201.98:56566111'},
{'http':'58.215.201.98:56566222'},
]
proxies = random.choice(proxies_pool)
url = 'https://www.baidu.com/s?wd=ip'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36'
}
request = urllib.request.Request(url=url,headers=headers)
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
response = opener.open(request)
content = response.read().decode('utf-8')
with open('daili2.html','w',encoding='utf-8')as fp:
fp.write(content)