Kubernetes部署(七):k8s项目交付----(4)日志收集
介绍
- 日志,对于任何系统来说都是及其重要的组成部分。在计算机系统里面,更是如此。但是由于现在的计算机系统大多比较复杂,很多系统都不是在一个地方,甚至都是跨国界的;即使是在一个地方的系统,也有不同的来源,比如操作系统,应用服务,业务逻辑等等,他们都在不停产生各种各样的日志数据。根据不完全统计,我们全球每天大约要产生2EB的数据。
- K8S系统里的业务应用是高度“动态化”的,随着容器编排的进行,业务容器在不断的被创建、被摧毁、被迁移(漂)、被扩缩容...
- 面对如此海量的数据,又是分布在各个不同地方,如果我们需要去查找一些重要的信息,难道还是使用传统的方法,去登陆到一台台机器上查看?看来传统的工具和方法已经显得非常笨拙和低效了。于是,一些聪明人就提出了建立一套集中式的方法,把不同来源的数据集中整合到一个地方。
日志是在做k8s容器云的时候,不得不做的一件事。当把业务应用容器化后,由于docker 基于AUFS,所以底包固化在容器里面,真正容器运行起来的时候,给附加一层可读写层,所以日志打在可读写层。意味着容器销毁,日志丢失销毁。可读写层不会被持久化到宿主机上。
问题:
1、日志是打散的,因为业务不一定调度到哪个运算节点的容器上。
2、随着我们业务特征的变化,业务容器可能扩缩容,造成业务日志是2份,然后又变成1份,然后有变化4份。解决方案:持久化,集中存放(中间件)
日志重要性:排错、回溯等
日志存放:以前都存在关系型数据库中 ,导致数据量很大。后期把交易、流水等日志直接存在ES里不进行落盘,但考虑会增加网络带宽、节点负载的压力,毕竟落盘数据丢失的风险小等因素。所以80%中国的企业一般要求都落盘
所以需要这样一套日志收集、分析的系统:
- 收集--能够采集多种来源的日志数据。 工具:流式日志收集器(日志是通过进程向磁盘申请打数据落盘,进程都是一行一行向磁盘打数据。流式日志收集器工作原理是,你打一行到磁盘,我就收集一行。它不是按照一个字、一个词收集)
- 传输--能够稳定的把日志数据传输到中央系统 ( 传输仰仗消息队列做解耦 )。在传统的ELK模型下中,日志是如何被Elasticsearch(ES)接受?在ES中有两种传输模型,在ES启动后,一是开启基于tcp socket(监听9300端口跟ES通信),让想传输给ES的组件通过9300把日志传递给ES。二是开启基于HTTP RESTful API (监听9200端口跟ES通信),让想传输给ES的组件通过9200把日志传递给ES。基于协议方式不一致,其区别很大。
- 存储--可以将日志以结构化数据的形式存储起来(比如搜索引擎后台的数据就是结构化数据存储)。找到一个存储的方法,能够把落盘的日志以一种结构化数据存储起来,比如关系型数据库,它是以二维表这种结构化数据形式存储的。如普罗米修斯中TSDB,它是以时间序列方式存储监控项、监控项对应的监控维度、监控过滤条件的,这种存储的方法也是一种结构化数据方式。总结就是把杂乱无章的数据必须结构化形式落盘。这样才能实现像搜索引擎这种,搜索指定的日志、指定的某台机器的指定日志。结构化收集日志,在早期的时候,需要把日志改成json形式,通过json这种规规矩矩的结构化数据的格式存储在ES中。xml、yaml、json都为结构化数据的格式
- 分析--支持方便的分析、检索的平台。最好有GUl管理系统(带有图形界面的前端,方便看日志)。
- 警告--能够提供错误报告,监控机制的监控工具。根据收集上来的日志,通过匹配规则,分析语句配置告警方法,告知日志中存在问题。)
优秀的社区开源解决方案-- ELK Stack:
- E-- ElasticSearch 基于倒排索引。mysql的innodb默认使用是B+Tree,它使用的就是正排索引,什么是正排索引,例如一首诗知道这首诗的名字,这样才能获取诗内容。什么是倒排索引,知道诗的内容关键字,反推出符合这些条件的这些诗的名字。ES作为倒排索引就是把这写内容的关键词做成分词(或者叫索引),ES有各种各样的分词器,可以把关键词做成索引,通过搜索 索引,反向的获得符合这些索引的日志
- L -- LogStash 流式日志收集器。
- K -- Kibana 提供前端页面查看数据。
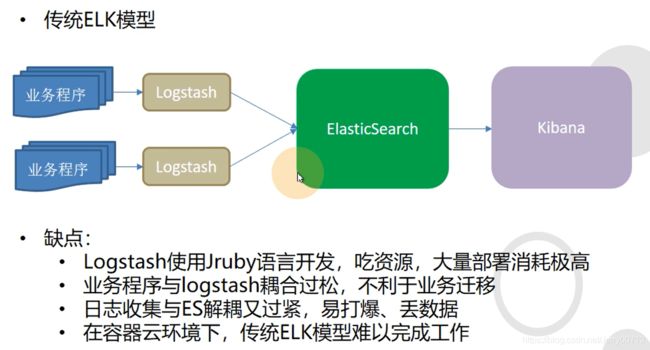
传统ELK缺点:
- Logstash使用Jruby开发(ruby语法java语言开发),所以运行logstash需要启动 jvm虚拟机,分配 jvm内存,导致吃大量资源,如果大规模部署,每一个业务都需要Logstash收集日志,在发送ES,就需要投入更多的硬件资源。
- 业务程序与 logstash耦合过松,不利于业务迁移。业务容器跟logstash对然在一台机器部署,但是程序是分开(不是一套程序)。不论你的业务容器是spring boot 还是java -jar的方式启动的,还是tomcat这种catalina.sh这种启动的,都不能在启动的时候,带动logstash启动。logstash有自己的启动方法,可能是servicelogstash start 或者 init.d下启动logstash 或者systemctl start logstash方法启动logstash,不管怎么启动,业务容器跟logstash启动方式都不是同时的,说明耦合度有点松,我希望业务容器起来,logstash也起来。希望业务容器停止,logstash也停止。希望业务容器能迁移到别的机器,logstash不用怎么动也跟着迁移一起迁移过去,退一步讲就算不是一起迁移过去,把logstash单独迁移后,由于每台设备logstash的配置需要按照实际情况配置,所以不能按照统一模板需要修改,还需要浪费大量时间去配置。当然了你可以编写启动脚本,把业务容器、logstash启动方式写在一起,但如果要迁移怎么办
- 曰志收集与ES耦合又过紧,数据量大的情况下容易给ES打爆,导致丟数据。logstash收集日志后直接往ES打,中间没有任何隔离,可能会导致ES给打爆,丟数据,所以希望把Logstash跟ES耦合降低,最好变成异步。传统后期ELK架构在Logstash跟ES中间加了一层Redis做缓冲,也是一种思路,但此文档使用另外一套方案。
- 在容器云环境下,传统ELK模型难以完成工作。最简单的问题,因为logstash需要在每一台业务容器上部署,如和让业务容器跟logstash进行高度耦合,在每个业务容器中还要进行logstash部署么,如何保证logstash、业务进程的正常启动。
由于Logstash功能虽然强大,但是它依赖java、在数据量大的时候,Logstash进程会消耗过多的系统资源,这将严重影响业务系统的性能,而filebeat就是一个完美的替代者,filebeat是Beat成员之一,基于Go语言,没有任何依赖,配置文件简单,格式明了,同时也是一款流式日志收集器,而filebeat比logstash更加轻量级,所以占用系统资源极少,非常适合安装在生产机器上,所以filebeat替代了Logstash位置,部署在业务设备上,在通过redis作为filebeat跟Logstash之间的缓存,大大的减轻了Logstash的压力,也减轻ES压力。所以到目前为止传统ELK业务结构为(业务+filebeat→redis→logstash→ES)

k8s中用另外一套ELK:

1、由轻量级的filebeat替代了Logstash位置,跟业务容器一对一绑定,做业务容器的日志收集。我们知道k8s中,最小的单元是pod,而一个pod中可以存在多个容器(containers)。所以让业务容器跟filebeat容器进行边车模式(Kubernetes 设计模式_Jerry00713的博客-CSDN博客)绑定运行在一起形成一个pod。这样就可以实现ks8s启动pod,会拉起两个容器(containers),实现业务容器跟filebeat容器耦合度变紧。而边车模式是让两个容器共享UTS+USER+IPC名称空间,隔离了NET+NAT+FS+PID,既有耦合又有不同,最后让两个容器放在一个pod跑。
2、什么是kafka,kafka托管于Apache基金会的一个消息队列软件。它支持发布订阅模型,什么是发布订阅,简单的说就是我发布一条信息,然后通知各各跟我连接的订阅者,我有这么一条信息,在每个订阅者需要用到我发布的内容时候,订阅者回主动去拉取,而不是我去推给各个订阅者。具体的原理是,发布者在接收到消息后,会将发布的消息分为不同的类别的消息(topic),可以理解为把一堆符合要求的信息,起一个名字叫topic××,发送者不会将topic的内容直接发送给订阅者,这意味着发布者和订阅者不知道彼此的存在。在发布者和订阅者之间存在第三个组件,称为消息代理或调度中心或中间件,它维持着发布者和订阅者之间的联系,过滤所有发布者传入的(topic)并相应地分发它们给订阅者。同样的,订阅者可以表达对一个或多个类别的兴趣,只接收感兴趣的消息。所以在订阅者想要接收发布者,对应(topic)内的内容后,会请求拉取发布者,名字是topic××对应的的内容。如果当一个(topic)的状态发生改变时,比如更新topic里面的内容后,所有依赖于它的对象都将得到通知,并自动更新。所以使用这么模型后,filebeat上把日志传递给kafka后,kafka给这个日志一个topic,相当于给这个日志起一个名字,然后告诉各个订阅者,我有这个名字(topic)的日志了,如果想要,告诉我你要的是这个名字topic,我在给里面的内容,如果这个topic名字的内容发生更新,也会及时通知连接的订阅者。
3、kafka/redis缓存软件在filebeat到ES之间做了解耦,日志从filebeat传递给kafka/redis,然后在经过logstash给到了ES,ES不直接对接filebeat。所以多数的数据都会先存在kafka/redis,在由logstash给到ES,即使ES意外宕机,还没存入ES的数据量也是很少的一部分,不会像filebeat/logstash直接对ES,filebeat/logstash没有缓存机制,直接有多少给ES多少,ES很容易打爆宕机,导致大量数据丢失,所以说进行了解耦
4、为什么filebeat收集日志,发送日志给kafka/redis,然后kafka/redis直接把日志传递给ES不就行了么,还需要Logstash?因为ES只能被接收、没有主动拉的动作。而filebeat、Logstash是流式日志收集器,他们的功能,就是主动去拉、然后把拉取日志发送给对端,也就是ES。在这套架构中,如果在kafka和ES中加入了Logstash,可以更好的过滤日志。比如filebeat可以只负责把日志收集上来,它不对日志进行过滤更改json等格式,传递到kafka/redis后,Logstash在拉取kafka的日志后,由Logstash统一对日志进行过滤更改json等格式,在发送给ES。或者让filebeat按照日志种类进行划分,传递给kafka形成topic后,被Logstash获取后,进行二次编辑,并修改为json格式在发送给ES。
5、日志以topic形式去kafka上发布,logstash在需要的时候,比如不忙的时候,主动去取这个topic,然后logstash再去ES中打,实际上是一个异步的过程。什么叫同步:filbeat数据直接传递给ES,没有Kafka、logstash,这个过程中filbeat软件是不管ES状态,filbeat只要没问题就只管一直发,这就要求ES必须保持跟filebeat同步接受数据,会导致如果量级别大,ES受不住丢数据。什么叫异步:filebeat传递给kafka,数据会留在kafka,在lotstash需要调取的时候,才会去kafka中拉取数据,lotstash在发送给ES。异步缺点:kibana看日志的时候有一点延迟,但是不大,因为kafka的吞度量比lotstash、ES大的多。
6、为什么加入kafka/redis就能起到缓解ES压力,首先知道不管是kafka还是redis都是缓存机制。如果没有kafka/redis,假如前端使用的是logstash,logstash直接对接的是ES,如果是一个logstash或者10个logstash对接一个ES,在日志量不是很大的前提下完全是可以,不需要给ES做缓存。但是每部署一个业务或者容器,就要部署一个logstash,如果是100个业务呢,100个logstash对接一个ES?由于logstash只是一个收发的软件,他就把日志收集过滤后形成json格式发送ES,而ES软件只能傻傻接受,如果ES受不了了,就会丢数据。但是如果在logstash/filebeat 之间加一个kafka/redis就不一样了。我们假设logstash、ES都按照最大处理收、发日志量(软件也有性能瓶颈),他们的比例是1个ES最大能承受5个logstash同时打入日志。所以我们就部署一个ES,然后在ES前,kafka后部署5个logstash,假设目前业务服务是100个容器,也就是100个logstash/filebeat同时发送给kafka,kafka作为缓存机制的软件,100完全不怕,到kafka后,kafka告诉5个logstash,我有100份日志等你来拿,而5个logstash会按照自己的最大能力获取日志,然后过滤修改json格式发送给ES,而ES完全能接收5个logstash同时并发。而后续这5个logstash拿一点发送一点,ES也是不间断的收到一点处理一点,最后把kafka的缓存日志处理完
7、在这套架构中,kafka通过对filebeat收集上来的日志,使用不同的topic进行区分日志。生产应用中,一个应用往往要起多个副本,比如上图k8s-Prod中框起来的两个(pod/filebeab)是由一个deployment资源,部署的2个同一种业务的pod,既然是一个业务,不管几份都应该放在一起看日志,所以这份业务(两个副本)要打在一个topic,这样传递给kafka后,才能实现收集同一种业务(同一种topic)日志。所以在kafka中不同的业务是用不同的topic区分是那种业务的日志。而在ES中是用不同的index-pattern区分是那种业务的日志。在ES中通过不同的index-pattern给不同的index分环境。
一、构造dubbo-demo-Tomcat项目
dubbo服务的消费者是一个提供了web接口的dubbo服务,所以他有一个http页面,而提供http页面项目既可以用Spring Boot编译成jar包(因为Spring Boot内置了一个java的web服务器--轻量级jetty),也可以把项目打包成war包,让tomcat运行war包。
而我们第一件就是把之前用Spring Boot编译成jar包的(dubbo-demo-consumer)消费者项目,改造编译成war包,让Tomcat启动消费者项目,因为tomcat项目打出的日志比较多,方便我们实验查看日志。改造项目编译成war包,让Tomcat启动war包,势必要修改源代码,在源代码中就的声明编译成war包,所以需要另外一套源代码(dubbo-demo-tomcat)
1、准备Tomcat的镜像底包
1.1、下载镜像
[root@hdss7-200 ~]# cd /opt/src/
[root@hdss7-200 src]# wget https://mirrors.bfsu.edu.cn/apache/tomcat/tomcat-8/v8.5.50/bin/apache-tomcat-8.5.50.tar.gz
[root@hdss7-200 src]# mkdir /data/dockerfile/tomcat
[root@hdss7-200 src]# tar xfv apache-tomcat-8.5.50.tar.gz -C /data/dockerfile/tomcat/
[root@hdss7-200 src]# cd /data/dockerfile/tomcat/ && rm -rf apache-tomcat-8.5.50/webapps/* # 删除webapps目录下的所有项目,后续自己创建
1.2、优化tomcat
1.2.1、优化启动项
关闭tomcat的AJP端口。AJP端口是跟apache快速结合的。 以前会使用apache+tomcat架构,而apache不用http协议跟tomcat通信,而是直接去和tomcat的8009端口通信。正常现在几乎前端是用nginx,而nginx+tomcat架构使用http协议跟后端的tomcat通信。所以我们为了节约资源,关闭AJP,不用tomcat监听8009。
声明:xml格式文件,使用注释的格式为
1、如果使用的是Tomcat:v8.5.50
# 在server.xml配置文件中,搜索AJP,按照如下配置,对进行修改8009进行注释
[root@hdss7-200 tomcat]# vi /data/dockerfile/tomcat/apache-tomcat-8.5.50/conf/server.xml改成

2、如果使用的是Tomcat:v8.5.63
# 在server.xml配置文件中,搜索AJP,按照如下配置,对进行修改8009进行注释
[root@hdss7-200 tomcat]# vi /data/dockerfile/tomcat/apache-tomcat-8.5.63/conf/server.xml改成
1.2.2、配置日志
tomcat默认会打好几种页面的日志(tomcat自带+自定义业务)。tomcat自带业务,比如tomcat提供了本地的一个管理页面,但在使用tomcat的时候,都是调用自己的业务的页面,这些tomcat自带页面根本不用,反而影响扰乱收集业务日志。所以需要在配置文件中注释掉,让tomcat不打自带(3manager、4host-manager)等页面的日志。
[root@hdss7-200 tomcat]# vi /data/dockerfile/tomcat/apache-tomcat-8.5.50/conf/logging.properties
# 默认配置:
handlers = 1catalina.org.apache.juli.AsyncFileHandler, 2localhost.org.apache.juli.AsyncFileHandler, 3manager.org.apache.juli.AsyncFileHandler, 4host-manager.org.apache.juli.AsyncFileHandler, java.util.logging.ConsoleHandler
3manager.org.apache.juli.AsyncFileHandler.level = FINE
3manager.org.apache.juli.AsyncFileHandler.directory = ${catalina.base}/logs
3manager.org.apache.juli.AsyncFileHandler.prefix = manager.
3manager.org.apache.juli.AsyncFileHandler.encoding = UTF-8
4host-manager.org.apache.juli.AsyncFileHandler.level = FINE
4host-manager.org.apache.juli.AsyncFileHandler.directory = ${catalina.base}/logs
4host-manager.org.apache.juli.AsyncFileHandler.prefix = host-manager.
4host-manager.org.apache.juli.AsyncFileHandler.encoding = UTF-8
# 注释3manager、4host-manager开头的、删除handlers中3manager、4host-manager:
handlers = 1catalina.org.apache.juli.AsyncFileHandler, 2localhost.org.apache.juli.AsyncFileHandler, java.util.logging.ConsoleHandler
#3manager.org.apache.juli.AsyncFileHandler.level = FINE
#3manager.org.apache.juli.AsyncFileHandler.directory = ${catalina.base}/logs
#3manager.org.apache.juli.AsyncFileHandler.prefix = manager.
#3manager.org.apache.juli.AsyncFileHandler.encoding = UTF-8
#4host-manager.org.apache.juli.AsyncFileHandler.level = FINE
#4host-manager.org.apache.juli.AsyncFileHandler.directory = ${catalina.base}/logs
#4host-manager.org.apache.juli.AsyncFileHandler.prefix = host-manager.
#4host-manager.org.apache.juli.AsyncFileHandler.encoding = UTF-8让tomcat业务日志多打些,所以日志级别改成INFO (FINE简略打,INFO详细打)
[root@hdss7-200 conf]# vi /data/dockerfile/tomcat/apache-tomcat-8.5.50/conf/logging.properties
默认配置:
1catalina.org.apache.juli.AsyncFileHandler.level = FINE
2localhost.org.apache.juli.AsyncFileHandler.level = FINE
java.util.logging.ConsoleHandler.level = FINE
修改:
1catalina.org.apache.juli.AsyncFileHandler.level = INFO
2localhost.org.apache.juli.AsyncFileHandler.level = INFO
java.util.logging.ConsoleHandler.level = INFO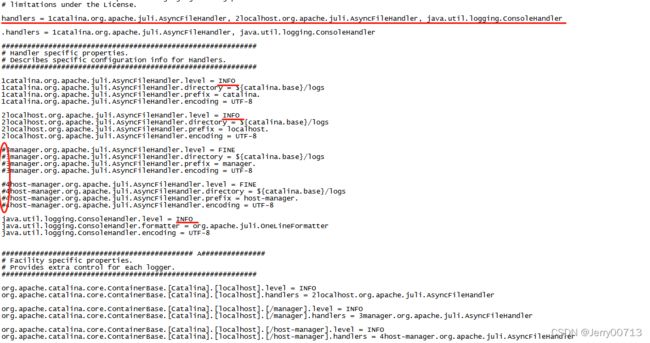
catalina log是运行中的日志,它主要记录运行的一些信息,尤其是一些异常错误日志信息 。
localhost log 是访问日志信息,它记录的访问的时间,IP,访问的资料等相关信息。
1.3、准备dockerfile
[root@hdss7-200 tomcat]# vi /data/dockerfile/tomcat/Dockerfile
From harbor.od.com:180/public/jre8:8u112
RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo 'Asia/Shanghai' >/etc/timezone
ENV CATALINA_HOME /opt/tomcat
ENV LANG zh_CN.UTF-8
ADD apache-tomcat-8.5.50/ /opt/tomcat
ADD config.yml /opt/prom/config.yml
ADD jmx_javaagent-0.3.1.jar /opt/prom/jmx_javaagent-0.3.1.jar
WORKDIR /opt/tomcat
ADD entrypoint.sh /entrypoint.sh
CMD ["/entrypoint.sh"]
- RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo 'Asia/Shanghai' >/etc/timezone # RUN运行命令参数,相当于sh -c,绝对路径下的/bin/cp拷贝命令,整体的意思是设置本地时间为正确的,修改本地时区为“ETC/UTC”。具体查看Linux的时间和时区设置_Jerry00713的博客-CSDN博客
- ENV CATALINA_HOME /opt/tomcat # ENV设置CATALINA_HOME环境变量等于/opt/tomcat,tomcat启动的时候会调用CATALINA_HOME环境变量下value值,把这值当作工作目录,tomcat启动脚本中的参数,都是相对在这个目录下执行启动命令等等,所有容器中tomcat的目录存放在/opt/tomcat下,启动tomcat才不会报错(https://blog.csdn.net/Jerry00713/article/details/123072779)
- ENV LANG zh_CN.UTF-8 # ENV设置语言编码环境变量LANG=zh_CN.UTF-8
- ADD apache-tomcat-8.5.50/ /opt/tomcat # 在宿主机中,和Dockerfile 同级目录下,也就是/data/dockerfile/tomcat/目录下,有一个apache-tomcat-8.5.50/目录,这个目录放到容器的/opt/目录下,并给apache-tomcat-8.5.50重命名为tomcat
- ADD config.yml /opt/prom/config.yml # 此配置文件,是提供给Prometheus使用,如果tomcat部署在k8s集群外,还要用Prometheus的自动功能去发现tomcat,就需要配置config.yml,然后在到Prometheus去配置file_sd_configs(基于文件的自动发现),就能实现Prometheus的自动功能去发现tomcat。但是如果tomcat部署在k8s集群中,就不需要基于文件的自动发现,Prometheus会通过基于K8S集群自动发现tomcat。所以在这配不配无所谓https://blog.csdn.net/Jerry00713/article/details/124097631
- ADD jmx_javaagent-0.3.1.jar /opt/prom/jmx_javaagent-0.3.1.jar # jmx_javaagent-0.3.1.jar 这个jar包专门收集jvm信息的,可以比作一个exporter,提供http的12346的接口,通过此接口获取jvm信息。
- WORKDIR /opt/tomcat # 工作目录
- ADD entrypoint.sh /entrypoint.sh # 添加脚本
- CMD ["/entrypoint.sh"] # 通过运行这个脚本启动
---
rules:
- pattern: '.*'[root@hdss7-200 tomcat]# ll
drwxr-xr-x. 9 root root 220 3月 8 14:33 apache-tomcat-8.5.50
-rw-r--r--. 1 root root 29 3月 8 19:29 config.yml
-rw-r--r--. 1 root root 406 3月 8 19:25 Dockerfile
-rw-r--r--. 1 root root 367417 5月 10 2018 jmx_javaagent-0.3.1.jar
[root@hdss7-200 tomcat]# vi /data/dockerfile/tomcat/entrypoint.sh
#!/bin/bash
M_OPTS="-Duser.timezone=Asia/Shanghai -javaagent:/opt/prom/jmx_javaagent-0.3.1.jar=$(hostname -i):${M_PORT:-"12346"}:/opt/prom/config.yml"
C_OPTS=${C_OPTS}
MIN_HEAP=${MIN_HEAP:-"128m"}
MAX_HEAP=${MAX_HEAP:-"128m"}
JAVA_OPTS=${JAVA_OPTS:-"-Xmn384m -Xss256k -Duser.timezone=GMT+08 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled -XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -Dfile.encoding=UTF8 -Dsun.jnu.encoding=UTF8"}
CATALINA_OPTS=${CATALINA_OPTS}
JAVA_OPTS="${M_OPTS} ${C_OPTS} -Xms${MIN_HEAP} -Xmx${MAX_HEAP} ${JAVA_OPTS}"
sed -i -e "1a\JAVA_OPTS=\"$JAVA_OPTS\"" -e "1a\CATALINA_OPTS=\"$CATALINA_OPTS\"" /opt/tomcat/bin/catalina.sh
cd /opt/tomcat && /opt/tomcat/bin/catalina.sh run 2>&1 >> /opt/tomcat/logs/stdout.log
- M_OPTS="-Duser.timezone=Asia/Shanghai -javaagent:/opt/prom/jmx_javaagent-0.3.1.jar=$(hostname -i):${M_PORT:-"12346"}:/opt/prom/config.yml" # 定义了一个环境变量M_OPTS,其中M_OPTS后面的数值,是java启动参数的一部分,在此脚本最后,java启动的时候,直接调用M_OPTS,就不会显得启动参数冗余。定义了java的-Duser.timezone启动时使用Asia/Shanghai时区。定义了java启动的时候使用javaagent参数启动/opt/prom/jmx_javaagent-0.3.1.jar,并让监控jvm组件的名字是hostname -i本机docker的pod的IP,而M_PORT:-"12346"的意思是,定义一个M_PORT变量名,如果脚本中没有指定M_PORT变量的数值,就默认把12346赋值给M_PORT变量,指定了一个配置/opt/prom/config.yml。
- C_OPTS=${C_OPTS} # 从容器的环境变量中,获取C_OPTS环境变量中数值,把这个数值赋值给我脚本中的变量C_OPTS。也就是C_OPTS等于环境变量中C_OPTS的数值。具体的原理为,在编写delpoyment.yaml资源清单的时候,声明了pod资源时候,在pod资源中定义一个ENV,这个ENV干什么用,ENV翻译过来就是环境变量,在pod资源定义ENV参数后,容器启动后会按照你设定的,人为增加环境变量,所以在ENV中配置C_OPTS=zookeeper地址,这样在容器启动后,环境变量中就会有C_OPTS=zookeeper地址,而在容器启动后,通过运行第一进程后,就会执行entrypoint.sh脚本,在脚本中定义了C_OPTS=${C_OPTS},也就是说脚本中的变量C_OPTS的数值等于环境变量C_OPTS的数值,也就是脚本中C_OPTS=zookeeper地址。因为我们毕竟使用的是dubbo项目,所以必然要连接注册中心,也就是zk,所以在脚本的最后通过获取脚本的变量C_OPTS数值,进而连接那个zookeeper。而这种写的好处是,我们可以在定义pod资源的时候,给C_OPTS赋值一个Apollo的地址。但其实这个地方不定义也行,毕竟脚本中,如果是用一个变量,这个变量没有声明,就会默认调用系统的环境变量
- MIN_HEAP=${MIN_HEAP:-"128m"} # jvm调优参数,最小使用内存。设置MIN_HEAP变量的数据,如果没有指定MIN_HEAP就会默认MIN_HEAP=128m。如果需要指定,编写delpoyment.yaml资源清单的时候,声明了pod资源时候声明一个MIN_HEAP的env。生产一般为2048
- MAX_HEAP=${MAX_HEAP:-"128m"} # jvm调优参数,最大使用内存。
- JAVA_OPTS=${JAVA_OPTS:-"-Xmn384m -Xss256k -Duser.timezone=GMT+08 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:CMSFullGCsBeforeCompaction=0 -XX:+CMSClassUnloadingEnabled
-XX:LargePageSizeInBytes=128m -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=80 -XX:SoftRefLRUPolicyMSPerMB=0 -XX:+PrintClassHistogram -Dfile.encoding=UTF8 - # 启动tomcat的时候,用到Java的什么参数,配置了使用内存、时区、GC回收的方法,默认的也可以配置delpoyment.yaml资源清单的时候,pod资源时候声明env。- CATALINA_OPTS=${CATALINA_OPTS} # 把环境变量CATALINA_OPTS数值传递给脚本的CATALINA_OPTS变量。CATALINA_OPTS是远程调试,是tomcat的内置参数。但此文章中,CATALINA_OPTS没有配置,所有CATALINA_OPTS=空
- JAVA_OPTS="${M_OPTS} ${C_OPTS} -Xms${MIN_HEAP} -Xmx${MAX_HEAP} ${JAVA_OPTS}" # 最后把所有的脚本的变量,通过java启动参数的命令,拼接起来,赋值给JAVA_OPTS,赋值给谁无所谓,因为不是最终结果。
- sed -i -e "1a\JAVA_OPTS=\"$JAVA_OPTS\"" -e "1a\CATALINA_OPTS=\"$CATALINA_OPTS\"" /opt/tomcat/bin/catalina.sh # sed -e "1a" # 通过sed 命令把上述结合的命令插入到/opt/tomcat/bin/catalina.sh第一行。此处才是java启动命令。
- cd /opt/tomcat/bin/catalina.sh run 2>&1 >> /opt/tomcat/logs/stdout.log # 之前使用的是exec java -jar ,让java进程代替第一进程的pid夯在前台运行,这次通过.sh RUN方法能够将脚本挂载到前台运行,所以/opt/tomcat/bin/catalina.sh run 意思是让catalina.sh在前台运行,然后把标准、错误输出重定向到标准输出日志(/opt/tomcat/logs/stdout.log)。
[root@7-200 tomcat]# chmod a+x /data/dockerfile/tomcat/entrypoint.sh # 加执行权限
1.4、制作dockerfile镜像
[root@hdss7-200 tomcat]# docker build . -t harbor.od.com:180/base/tomcat:v8.5.50
[root@hdss7-200 ~]# docker images |grep tomcat
harbor.od.com:180/base/tomcat v8.5.50 802c734abc4c 21 hours ago 378MB
[root@hdss7-200 ~]# docker login harbor.od.com:180
[root@hdss7-200 ~]# docker push harbor.od.com:180/base/tomcat:v8.5.50
2、部署dubbo-demo-Tomcat项目
2.1、如何交付tomcat形式的dubbo服务消费者到k8s
部署dubbo微服务tomcat的版本的消费者,默认代码中连接zk,是通过调用容器环境变量dubbo.registry参数,所以此代码构建依赖于 Apollo的配置中心。

之前jenkins构建的dubbo-demo-consumer是由Spring boot启动,而tomcat类型的消费者跟Spring boot有些许区别。从源代码中体现出,比如dubbo-client/pom.xml下,之前交付dubbo微服务的时候使用的是jar包,在tomcat中使用的是war,一般包类型都在dubbo-client/下的pom.xml中声明,可以自行查看,如果不是war改成使用war而不是jar。除了war地方之外,还有其他的些许不同,还要修改tomcat的环境变量而不是Spring boot等等,所以索性直接使用新的github的tomcat分支代码,不进行对默认的spring boot项目代码修改。
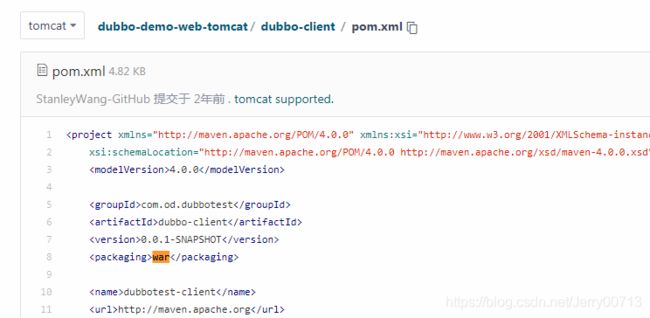
注:如果pom.xml声明的是非war,jenkins构建的时候会出现报错如下
unzip *.war -d ./project_dir unzip: cannot find or open *.war, *.war.zip or *.war.ZIP.意思是,没有找到*.war相关的数据包,因为在构建jenkins脚本中声明了,解压*.war 到./project_dir目录
2.2、 配置Jenkins流水线
在制作Spring boot项目的dubbo微服务消费者(dubbo-demo-consumer)的时候,基于10个参数构建,而tomcat项目多一个root_dir。

tomcat-demo → 选择流水线 → OK
选择(This project is parameterized)被参数化构建:
注:Trim the string自动把内容的左右两侧空格去掉,按照如下图进行构建参数,图略
| 参数名(name) |
类型(type) | 默认(Default) | Trim the string | 描述(description) |
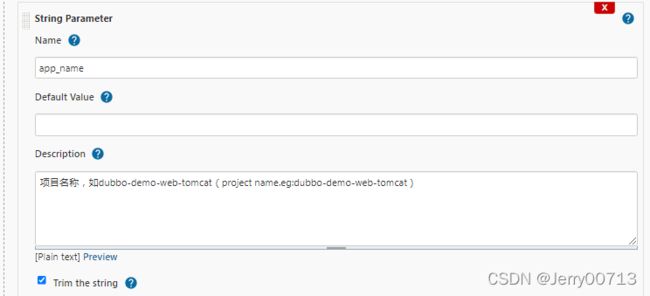
| app_name | string Parameter | √ | 项目名称,如dubbo-demo-web-tomcat(project name.eg:dubbo-demo-web-tomcat) | |
| image_name | string Parameter | √ | docker镜像名称,如 app/dubbo-demo-web-tomcat(project docker image.eg:dubbo-demo-web-tomcat) | |
| git_repo | string Parameter | √ | 项目在git版本仓库的地址,如 https://gitee.com/xxx/dubbo-demo-web-tomcat (project git repository .eg:dubbo-demo-web-tomcat) | |
| git_ver | string Parameter | tomcat | √ | 项目在git仓库中对应的分支或者版本号( git commit id of the project ) |
| add_tag | string Parameter | √ | 日期-时间,和git_ver拼在一起组成镜像的tag,如: 210310_0900(project docker image tag, date_timestamp recommended. e.g:210310_0900) | |
| mvn_dir | string Parameter | ./ | √ | 在哪个目录执行编译,由开发同事提供(project maven directory e.g: ./) |
| target_dir | string Parameter | ./dubbo-client/target | √ | 编译的jar/war文件存放目录,由开发同事提供(the relative path of target file such as .jar or .war package e.g:./dubbo-client/target) |
| mvn_cmd | string Parameter | mvn clean package -Dmaven.test.skip=true | √ | 执行编译所用的指令(maven command. e.g: mvn clean package -Dmaven.test.skip=true ) |
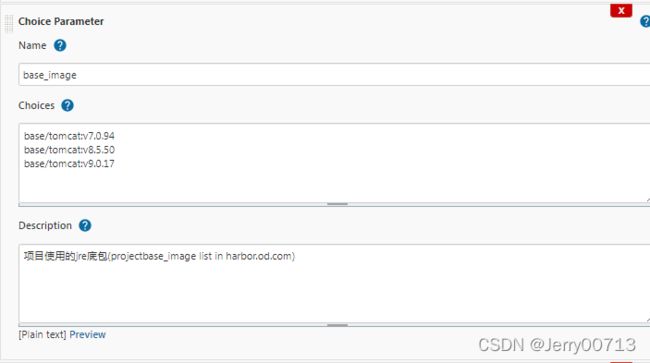
| base_image | choice Parameter | base/tomcat:v7.0.94 base/tomcat:v8.5.50 base/tomcat:v9.0.17 |
项目使用的jre底包(projectbase_image list in harbor.od.com) | |
| maven | choice Parameter | 3.6.1-8u232 3.2.5-7u045 2.2.1-6u025 |
编译时使用的maven目录中的版本号部分(differentmaven edition ) | |
| root_dir | string Parameter | ROOT | √ | 项目放到webapps下面的哪个目录中(webapps dir) |
简单的截取几个:
Pipeline:
pipeline { agent any stages { stage('pull') { //get project code from repo steps { sh "git clone ${params.git_repo} ${params.app_name}/${env.BUILD_NUMBER} && cd ${params.app_name}/${env.BUILD_NUMBER} && git checkout ${params.git_ver}" } } stage('build') { //exec mvn cmd steps { sh "cd ${params.app_name}/${env.BUILD_NUMBER} && /var/jenkins_home/maven-${params.maven}/bin/${params.mvn_cmd}" } } stage('unzip') { //unzip target/*.war -c target/project_dir steps { sh "cd ${params.app_name}/${env.BUILD_NUMBER} && cd ${params.target_dir} && mkdir project_dir && unzip *.war -d ./project_dir" } } stage('image') { //build image and push to registry steps { writeFile file: "${params.app_name}/${env.BUILD_NUMBER}/Dockerfile", text: """FROM harbor.od.com:180/${params.base_image} ADD ${params.target_dir}/project_dir /opt/tomcat/webapps/${params.root_dir}""" sh "cd ${params.app_name}/${env.BUILD_NUMBER} && docker build -t harbor.od.com:180/${params.image_name}:${params.git_ver}_${params.add_tag} . && docker push harbor.od.com:180/${params.image_name}:${params.git_ver}_${params.add_tag}" } } } }解释:
stage('pull') { //get project code from repo # 拉代码 stage('build') { //exec mvn cmd # 编译构建镜像 stage('unzip') { sh "cd ${params.app_name}/${env.BUILD_NUMBER} && cd ${params.target_dir} # cd 到target_dir目录下 && mkdir project_dir && unzip *.war -d ./project_dir" # 创建的project_dir目录 # war包解压到当前创建的project_dir目录下 steps { FROM harbor.od.com:180/${params.base_image} # 从harbor中From这个底包 ADD ${params.target_dir}/project_dir /opt/tomcat/webapps/${params.root_dir} # 意思是(ADD ./project_dir /opt/tomcat/webapps/ROOT)把target_dir目录下project_dir目录重命名为ROOT放到webapps中。 注: [root@hdss7-200 apache-tomcat-8.5.50]# cd webapps/ # 此目录放置网站war包 [root@hdss7-200 webapps]# ll drwxr-x--- 3 root root 283 Dec 22:11:42 ROOT # 如果把源代码放入此目录中,只需要访问dns/网页ip, 比如www.baidu.comn/index.html,ROOT代表的是根。 drwxr-x--- 15 root root 4096 Dec 22:11:42 docs drwxr-x--- 6 root root 83 Dec 22:11:42 examples # 如果把源代码放入非ROOT目录,比如examples此目录中,访问网址就是www.baidu.comn/examples/index.html drwxr-x--- 5 root root 87 Dec 22:11:42 host-manager drwxr-x--- 5 root root 103 Dec 22:11:42 manager
Pipeline tomcat-demo:
app_name 名字尽量应该是gitee一样的,这样会以后好管理 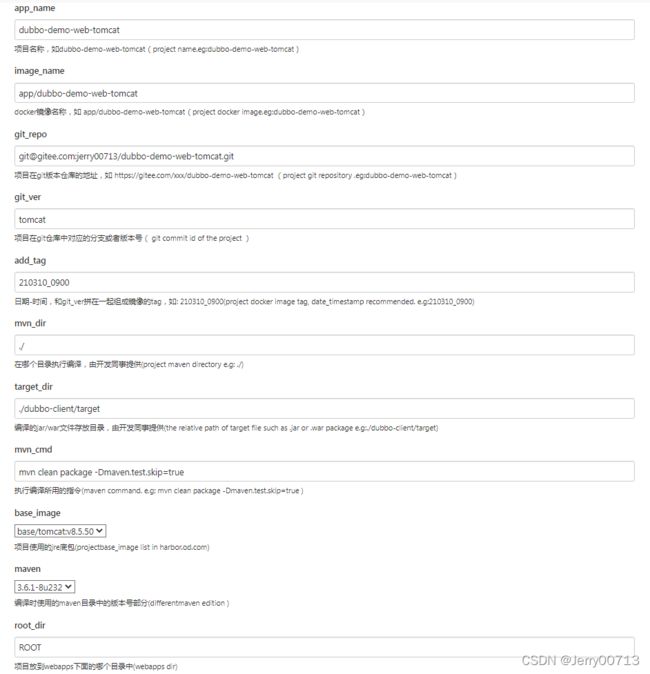
注:需要了解一下tomcat的工作原理,tomcat/webapps目录下的任何一个子目录都可以作为一个 Web 服务目录。什么意思,你可以把web项目打成.war包,放在webapps文件夹下,启动tomcat时会自动解压此目录下*.war包,比如我在tomcat/webapps目录下放了admin.war,启动tomcat时,会释放admin.war,并在当前目录下生成一个admin目录,这个目录下存放的就是一个 Web 服务,比如释放后,admin目录生成一个index.html,如果你网站的域名是www.jerry.com,就需要访问https://www.jerry.com/admin/index.html 。但注意,有一个例外tomcat/webapps/ROOT目录,假如说此目录中有一个网页(tomcat/webapps/ROOT/123.html),就需要访问https://www.jerry.com/123.html 即可,不需要写入ROOT。从jenkins构建参数化脚本查看, unzip *.war -d ./project_dir ADD ${params.target_dir}/project_dir /opt/tomcat/webapps/${params.root_dir},意思是把war包解压到./project_dir 目录,然后把这个./project_dir目录中所有的内容,统统复制到/opt/tomcat/webapps/${params.root_dir}目录下,root_dir是ROOT,所以就是 /opt/tomcat/webapps/ROOT
总结一下上述jenkins的工流程:
1、使用的是jenkins的流水线构建参数,顾名思义,他是通过自定义的脚本,告诉jenkins你应该干什么,你应该从哪拉取代码,从哪编译代码,如何编译代码,编译后如何进行封装完整的tomcat,如何在打包成一个imgae镜像,镜像的名字是什么等等,脚本里面都写了。所以可以修改脚本,使其变成你想要的效果。注:会发现脚本叫有大量的引用变量,为什么的呢
jenkins作为一个流水线发布的软件,它是帮助你简化构建流程,假如脚本中写死了git clone 克隆那个代码,打包做成镜像叫什么, 构建一次tomcat后,后续升级tomcat项目怎么办?还需要在写一遍流水线、然后在流水线上进行参数化构建,那我何必在写一遍流水线呢,流水线内容都是一样的,为什么不直接在流水线脚本上,把可改变的参数进行声明,声明我要引用参数化构建的参数不就行了么。通过这个思想,jenkins把参数化构建的参数,通过一个网页的形式,让你去填写对应的参数中,然后传给流水线脚本
按照当前dubbo-demo-web,落实脚本+参数运行过程:
app_name:dubbo-demo-web-tomcat # 项目名称 image_name:app/dubbo-demo-web-tomcat # jenkins制作完此项目后,打成tomcat镜像应该叫什么名字,此位置设置镜像名的头部,方便自动push到harbar add_tag:20220306_2000 # 此位置打成tomcat镜像的版本号 git_repo:[email protected]:jerry00713/dubbo-demo-web-tomcat.git # 从哪个github或者gitee拉取项目源代码 git_ver:tomcat # 拉取项目源代码后,执行那个分支代码 mvn_dir:./ # 在哪个目录执行编译,由开发同事提供 target_dir:./dubbo-client/target # 编译成jar/war包后,存放在哪,由开发同事提供 mvn_cmd:mvn clean package -Dmaven.test.skip=true # 如何让java源代码编译成war/jar包,其中的参数 base_image:base/tomcat:v8.5.50 # java源代码要运行,需要meaven编译成war/jar包,而运行war/jar包,需要Java的运行环境(jre),JRE是运行Java程序所必须环境的集合,包含JVM标准实现及 Java核心类库。它包括Java虚拟机、Java平台核心类和支持文件。JRE和JDK的区别:https://blog.csdn.net/Jerry00713/article/details/123317705 maven:3.6.1-8u232 # 编译时使用的maven目录中的版本号 root_dir:ROOT # 项目放到webapps下面的哪个目录中1、首先build执行后,Console Output中,第一条为Running on Jenkins in /var/jenkins_home/workspace/tomcat-demo,意思是在jenkins容器上,创建一个/var/jenkins_home/workspace/tomcat-demo目录来进行后续操作,为什么是/var/jenkins_home/之前在配置jenkins的时候讲过。为什么是tomcat-demo,是你创建流水线的时候名字
2、BUILD_NUMBER 变量: 是你在jenkins创建的第几个实例。从1开始,对应的在/var/jenkins_home/workspace/tomcat-demo目录下生成对应的数字,这样才能隔离各个业务
3、sh "git clone ${params.git_repo} ${params.app_name}/${env.BUILD_NUMBER} && cd ${params.app_name}/${env.BUILD_NUMBER} && git checkout ${params.git_ver}"
git clone [email protected]:jerry00713/dubbo-demo-web.git dubbo-demo-web-tomcat/6 # clone [email protected]:jerry00713/dubbo-demo-web.git 克隆镜像 # 到/var/jenkins_home/workspace/tomcat-demo/dubbo-demo-web-tomcat/6目录下 cd dubbo-demo-web-tomcat/6 # 进入/var/jenkins_home/workspace/tomcat-demo/dubbo-demo-web-tomcat/6目录 + git checkout tomcat # 切换到tomcat分支4、sh "cd ${params.app_name}/${env.BUILD_NUMBER} && /var/jenkins_home/maven-${params.maven}/bin/${params.mvn_cmd}"
cd ${params.app_name}/${env.BUILD_NUMBER} cd app/dubbo-demo-web-tomcat/6 # 进入/var/jenkins_home/workspace/tomcat-demo/dubbo-demo-web-tomcat/6目录 /var/jenkins_home/maven-${params.maven}/bin/${params.mvn_cmd /var/jenkins_home/maven-3.6.1-8u232/bin/mvn clean package -Dmaven.test.skip=true # 使用maven命令生成war/jar包5、sh "cd ${params.app_name}/${env.BUILD_NUMBER} && cd ${params.target_dir} && mkdir project_dir && unzip *.war -d ./project_dir"
cd ${params.app_name}/${env.BUILD_NUMBER} cd dubbo-demo-web-tomcat/6 # 进入/var/jenkins_home/workspace/tomcat-demo/dubbo-demo-web-tomcat/6目录 cd ${params.target_dir} cd ./dubbo-client/target # 进入/var/jenkins_home/workspace/tomcat-demo/dubbo-demo-web-tomcat/6/dubbo-client/target目录 mkdir project_dir # 创建/var/jenkins_home/workspace/tomcat-demo/dubbo-demo-web-tomcat/6/dubbo-client/target/dubbo-client/target/project_dir unzip *.war -d ./project_dir" # 将上文生成的*.war解压到/var/jenkins_home/workspace/tomcat-demo/dubbo-demo-web-tomcat/6/dubbo-client/target/dubbo-client/target/project_dir6、writeFile file: "${params.app_name}/${env.BUILD_NUMBER}/Dockerfile", text: """FROM harbor.od.com:180/${params.base_image}
ADD ${params.target_dir}/project_dir /opt/tomcat/webapps/${params.root_dir}"""
sh "cd ${params.app_name}/${env.BUILD_NUMBER} && docker build -t harbor.od.com:180/${params.image_name}:${params.git_ver}_${params.add_tag} . && docker push harbor.od.com:180/${params.image_name}:${params.git_ver}_${params.add_tag}"writeFile file: # 写内容到一个文件,格式为writeFile file:"写入那个文件",text:"""写入什么内容""" {params.app_name}/${env.BUILD_NUMBER}/Dockerfile dubbo-demo-web-tomcat/4/Dockerfile # 写入文件是/var/jenkins_home/workspace/tomcat-demo/dubbo-demo-web-tomcat/4/Dockerfile FROM harbor.od.com:180/${params.base_image} ADD ${params.target_dir}/project_dir /opt/tomcat/webapps/${params.root_dir} FROM harbor.od.com:180/base/tomcat:v8.5.50 ADD ./dubbo-client/target/project_dir /opt/tomcat/webapps/ROOT # dockerfile中FROM一个基础镜像,然后从次镜像中,声明了把project_dir目录下(.war解压的内容)全部放入到/opt/tomcat/webapps/ROOT目录下 cd ${params.app_name}/${env.BUILD_NUMBER} cd dubbo-demo-web-tomcat/6 # 进入目录dubbo-demo-web-tomcat/6 # 构建docker image, push image docker build -t harbor.od.com:180/${params.image_name}:${params.git_ver}_${params.add_tag} . docker build -t harbor.od.com:180/dubbo-demo-web-tomcat:tomcat_20220306_2000 . docker push harbor.od.com:180/${params.image_name}:${params.git_ver}_${params.add_tag}" docker push harbor.od.com:180//dubbo-demo-web-tomcat:tomcat_20220306_2000
构建完成success后,在harbor查看镜像
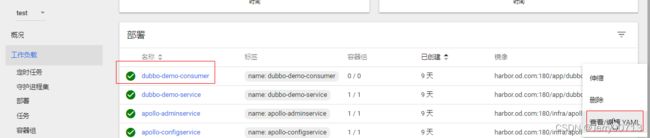
2.3、test名称空间下交付tomcat的微服务
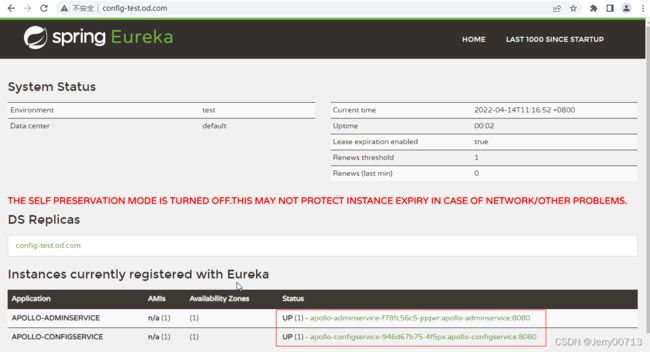
注:由上述讲过,我们部署的项目还是之前的dubbo-demo项目,只不过是之前使用的是spring boot构建的dubbo-demo-consumer消费者,这次用tomcat形式构建了消费者,所以连接的dubbo-demo-service提供者是不变,而且构建的tomcat形式消费者,代码中提示必须连接apollo,所以在test下,我们要把先启动apollo.configservice让Eureka启动、在启动apollo.adminservice
在启动apollo-portal,查看test环境(FAT)下,apollo之前交付的参数是不是正常
在启动dubbo-demo-service让生产者去连接apollo,最后在交付tomcat形式消费者。



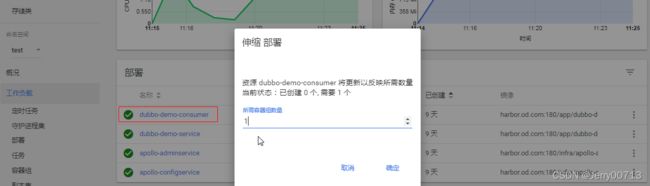
由于我们之前做过dubbo-demo-consumer,所以有两种交付方法,第一可以直接修改dubbo-demo-consumer的资源配置清单,使其调用dubbo-demo-web-tomcat镜像,第二种是重新构建一份新的资源配置清单
第一种(修改dubbo-demo-consumer资源配置清单,调用tomcat版本镜像):
直接修改dubbo-demo-consumer消费者资源配置清单,修改image、env
具体修改如下
# 必须改镜像为tomcat image: harbor.od.com/app/dubbo-demo-consumer:tomcat_210310_0900 # ports中删除声明20880端口,也可以不删除,本来也不用,定义了也没用 { containerPort: 20880, protocol: TCP } # 不是spring boot项目,所以不会策产生jar包,所以删除JAR_BALL,也可以不删除,本来也不用,定义了也没用 env: - name: JAR_BALL value: Dubbo-client.jar # ...... # 必须有环境变量C_OPTS,需要传递给容器C_OPTS等于多少,tomcat源代码需要连接Apollo,从Apollo获取dubbo.registry参数,进而连接zk env: - name: C_OPTS value: -Denv=dev -Dapollo.meta=http://config.od.com修改后,扩容1
第二种(编写dubbo-demo-web-tomcat资源配置清单):
重新构建,准备应用资源配置清单,我们选择先在test命名空间中应用。为了防止冲突,把此之前需要test命名空间中把spring boot项目的dubbo-demo-consumer消费者缩容成0,因为我们直接使用dubbo-demo-consumer的demo-test.od.com域名,就不重新在写一个,然后让test命名空间下的dubbo-demo-web-tomcat去连接dubbo-demo-service,就不创建新的一个生产者。因为之前也说过,消费者除了改成tomcat项目,其他没有变化。
[root@hdss7-200 ~]# mkdir -p /data/k8s-yaml/test/dubbo-demo-web-tomcat;cd /data/k8s-yaml/test/dubbo-demo-web-tomcat
[root@hdss7-200 dubbo-demo-web-tomcat ]# vi dp.yamlkind: Deployment apiVersion: extensions/v1beta1 metadata: name: dubbo-demo-web-tomcat namespace: test labels: name: dubbo-demo-web-tomcat spec: replicas: 1 selector: matchLabels: name: dubbo-demo-web-tomcat template: metadata: labels: app: dubbo-demo-web-tomcat name: dubbo-demo-web-tomcat spec: containers: - name: dubbo-demo-web-tomcat image: harbor.od.com:180/app/dubbo-demo-web-tomcat:tomcat_210310_0900 ports: - containerPort: 8080 protocol: TCP env: - name: C_OPTS value: -Denv=fat -Dapollo.meta=http://config-test.od.com imagePullPolicy: IfNotPresent imagePullSecrets: - name: harbor restartPolicy: Always terminationGracePeriodSeconds: 30 securityContext: runAsUser: 0 schedulerName: default-scheduler strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 maxSurge: 1 revisionHistoryLimit: 7 progressDeadlineSeconds: 600[root@hdss7-200 dubbo-demo-web-tomcat ]# vim svc.yaml
kind: Service apiVersion: v1 metadata: name: dubbo-demo-web-tomcat namespace: test spec: ports: - protocol: TCP port: 8080 targetPort: 8080 selector: app: dubbo-demo-web-tomcat[root@hdss7-200 dubbo-demo-web-tomcat ]# vim ingress.yaml
kind: Ingress apiVersion: extensions/v1beta1 metadata: name: dubbo-demo-web-tomcat namespace: test spec: rules: - host: demo-test.od.com http: paths: - path: / backend: serviceName: dubbo-demo-web-tomcat servicePort: 8080应用资源配置清单
[root@7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/test/dubbo-demo-web-tomcat/dp.yaml deployment.extensions/dubbo-demo-web-tomcat created [root@7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/test/dubbo-demo-web-tomcat/svc.yaml service/dubbo-demo-web-tomcat created [root@7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/test/dubbo-demo-web-tomcat/ingress.yaml ingress.extensions/dubbo-demo-web-tomcat created
访问http://demo-test.od.com/hello?name=tomcat
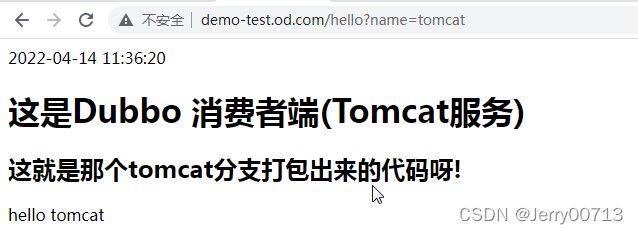
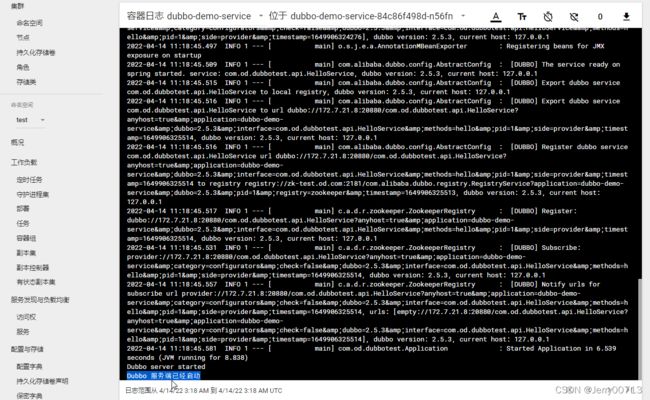
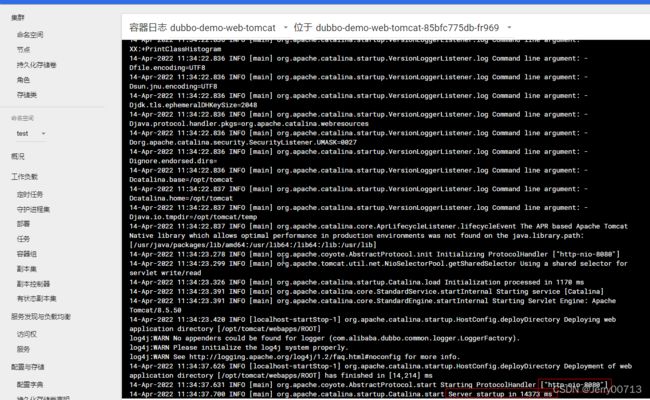
2.4、查看容器启动日志
进入tomcat消费者的容器中,查看/opt/tomcat/logs目录已经生成了一堆日志,到目前为止,产生日志的环境已经搭建完毕,后续开始准备部署ELK来对这些日志收集并管理
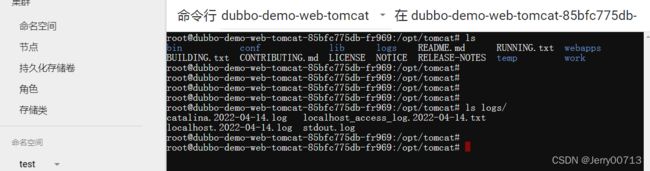
2.5、进入容器查看ROOT目录
进入ROOT目录,查看我们之前所讲述的,.war释放的文件会拷贝到root_dir目录下,也就是ROOT目录
[root@hdss7-21 ~]# kubectl get pod -n test
NAME READY STATUS RESTARTS AGE
apollo-adminservice-f78fc56c5-jqqwr 1/1 Running 0 31m
apollo-configservice-946d67b75-4f5px 1/1 Running 0 31m
dubbo-demo-service-84c86f498d-n56fn 1/1 Running 0 27m
dubbo-demo-web-tomcat-85bfc775db-fr969 1/1 Running 0 11m
[root@hdss7-21 ~]# kubectl exec -it dubbo-demo-web-tomcat-85bfc775db-fr969 -n test bash
root@dubbo-demo-web-tomcat-85bfc775db-fr969:/opt/tomcat# ls /opt/tomcat/webapps/
ROOT
root@dubbo-demo-web-tomcat-85bfc775db-fr969:/opt/tomcat# ls /opt/tomcat/webapps/ROOT/
META-INF WEB-INF
root@dubbo-demo-web-tomcat-85bfc775db-fr969:/opt/tomcat# 二、部署Elasticsearch
2.1 、下载Elasticsearch
安装包下载:Past Releases of Elastic Stack Software | Elastic
Elasticsearch 是一个有状态的服务,能部署在Kubernetes集群中,但不建议,本次实验采用单节点部署Elasticsearch,之前7-11部署了mysql,为了减轻7-11节点压力,Elasticsearch部署在 hdss7-12.host.com (10.4.7.12)节点。注:当前ES使用的是6.8.6版本,本身依赖1.8的jdk,所以必须在hdss7-12上有jdk,恰巧在部署zookpeer的时候部署了1.8的jdk
[root@7-12 ~]# java -version
java version "1.8.0_231"
Java(TM) SE Runtime Environment (build 1.8.0_231-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.231-b11, mixed mode)
[root@hdss7-12 src]# cd /opt/src
[root@hdss7-12 src]# wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.8.6.tar.gz 注意elasticsearch 7以上的版本依赖的是openjdk11
[root@hdss7-12 src]# tar xfv elasticsearch-6.8.6.tar.gz -C /opt/
[root@hdss7-12 src]# ln -s /opt/elasticsearch-6.8.6 /opt/elasticsearch2.2、配置Elasticsearch
[root@hdss7-12 ~]# mkdir -p /data/elasticsearch/{data,logs} # 日志数据目录,生产一般都单独挂载一块新的盘符
[root@hdss7-12 ~]# cd /opt/elasticsearch/config/
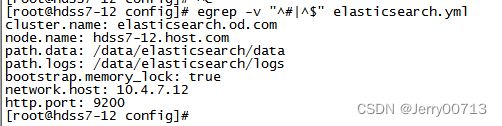
[root@hdss7-12 config ]# vi elasticsearch.yml # 将配置文件中需要配置的#注释去掉并填写参数
cluster.name: elasticsearch.od.com # 给ES集群起名字 node.name: hdss7-12.host.com # ES节点列表 path.data: /data/elasticsearch/data # ES存放的数据目录 path.logs: /data/elasticsearch/logs # ES存放的日志目录 bootstrap.memory_lock: true # ES启动后,申请直接占用一定的内存,其他程序不能占用(锁死内存) network.host: 10.4.7.12 # 监听那个IP http.port: 9200 # 监听那个IP的那个端口
配置优化jvm虚拟机
[root@hdss7-12 ~]# vim /opt/elasticsearch/config/jvm.options # 默认1g,生产中一般不超过32G ...... -Xms512m -Xmx512m
创建普通用户,ES跟etcd一样其他用户起不来
[root@hdss7-12 ~]# useradd -s /bin/bash -M es # 创建一个没有家目录的es用户,并且可以用su命令登录 [root@hdss7-12 ~]# chown -R es.es /data/elasticsearch /opt/elasticsearch-6.8.6useradd命令: -M:不创建家目录 -s:后接着指定用户登陆时使用的shell -s bin/bash user:bin/bash指定用户登录使用的shell,user用户可以使用su 命令登录,登录后开启一个bin/bash -s /sbin/nologin user:nologin就是登陆不了,user用户无法使用su 命令登录
配置文件描述符
文件描述符用于实现对用户资源进行限制,这里限制ES用户,并发进程数/文件数等等
两种方案:
第一:直接在系统默认的文件描述符文件/etc/security/limits.conf 修改,追加如下内容
第二:在/etc/security/limits.d 下添加一个文件,在文件中写入限制条件,因为此目录跟rc.d目录类似,只要在limits.d目录下的文件,都可以对文件描述符修改,如下[root@hdss7-12 ~]# vim /etc/security/limits.d/es.conf
es hard nofile 65536 es soft fsize unlimited es hard memlock unlimited es soft memlock unlimited解释为什么imits.d目录下的文件,可以修改文件描述符:
通过查看limits.conf的配置文件,#Also note that configuration files in /etc/security/limits.d directory 提示说只要在/etc/security/limits.d下以.conf结尾的都可以
调节内核参数
[root@hdss7-12 ~]# sysctl -w vm.max_map_count=262144
[root@hdss7-12 ~]# echo "vm.max_map_count=262144" >> /etc/sysctl.conf ; sysctl -p # 设置永久生效2.3、启动Elasticsearch
# 使用es账户执行/opt/elasticsraech/bin/elasticsraech -d 启动elasticsraech
[root@hdss7-12 ~]# su -c "/opt/elasticsearch/bin/elasticsearch -d" es
或
[root@hdss7-12 ~]# sudo -ues "/opt/elasticsraech/bin/elasticsraech"
或
[root@hdss7-12 ~]# su es -c "/opt/elasticsearch/bin/elasticsearch -d -p /data/elasticsearch/logs/pid" # 指定pid记录的文件
[root@hdss7-12 ~]# netstat -tulpn|grep 9200
tcp6 0 0 10.4.7.12:9200 :::* LISTEN 3063/java2.4、配置Elasticsearch自动启
2.4.1、配置system
[root@hdss7-12 config]# vi /etc/systemd/system/elasticsearch.service
[Unit]
Description=ElasticSearch
Requires=network.service
After=network.service
[Service]
User=es
Group=es
LimitNOFILE=65536
LimitMEMLOCK=infinity
Environment=JAVA_HOME=/usr/java/jdk
ExecStart=/opt/elasticsearch/bin/elasticsearch
ExecReload=/bin/kill -HUP $MAINPID
KillMode=mixed
SuccessExitStatus=143
Restart=on-failure
RestartSec=42s
[Install]
WantedBy=multi-user.target解释:
- User=es Group=es 代表启动命令的时候,使用es用户
- LimitMEMLOCK=infinity 内存的并发不限制,跟limits.d/es.conf异曲同工之处
- Environment=JAVA_HOME=/usr/java/jdk 使用的JAVA_HOME环境变量,可以用过echo $JAVA_HOME获取
- ExecStart 后面就是启动命令,也就是/opt/elasticsearch/bin/elasticsearch
- ExecReload=/bin/kill -HUP $MAINPID ExecReload代表重启的操作,$MAINPID是服务的systemd变量,它指向主应用程序的PID,所以他是kill 掉由systemctl start elasticsearch.service 启动的进程的pid
2.4.2、kill 掉现在的elasticsearch
[root@hdss7-12 config]# ps -ef |grep elasticsearch
es 24378 1 2 12:39 ? 00:01:23 /usr/java/jdk/bin/java -Xms512m -Xmx512m -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Des.networkaddress.cache.ttl=60 -Des.networkaddress.cache.negative.ttl=10 -XX:+AlwaysPreTouch -Xss1m -Djava.awt.headless=true -Dfile.encoding=UTF-8 -Djna.nosys=true -XX:-OmitStackTraceInFastThrow -Dio.netty.noUnsafe=true -Dio.netty.noKeySetOptimization=true -Dio.netty.recycler.maxCapacityPerThread=0 -Dlog4j.shutdownHookEnabled=false -Dlog4j2.disable.jmx=true -Djava.io.tmpdir=/tmp/elasticsearch-742784719104692877 -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=data -XX:ErrorFile=logs/hs_err_pid%p.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintGCApplicationStoppedTime -Xloggc:logs/gc.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=32 -XX:GCLogFileSize=64m -Des.path.home=/opt/elasticsearch -Des.path.conf=/opt/elasticsearch/config -Des.distribution.flavor=default -Des.distribution.type=tar -cp /opt/elasticsearch/lib/* org.elasticsearch.bootstrap.Elasticsearch -d
es 24414 24378 0 12:39 ? 00:00:00 /opt/elasticsearch/modules/x-pack-ml/platform/linux-x86_64/bin/controller
root 34239 6602 0 13:33 pts/0 00:00:00 grep --color=auto elasticsearch
[root@hdss7-12 config]# kill 24378
[root@hdss7-12 config]# ps -ef |grep elasticsearch
root 34308 6602 0 13:33 pts/0 00:00:00 grep --color=auto elasticsearch
2.4.3、启动elasticsearch服务
[root@hdss7-12 config]# systemctl daemon-reload # 更新systemd
[root@hdss7-12 config]# systemctl start elasticsearch.service
[root@hdss7-12 config]# systemctl enable elasticsearch.service # 启动elasticsearch服务
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /etc/systemd/system/elasticsearch.service.2.5、Elasticsearch中添加k8s日志模板
# 添加k8s日志索引模板 [root@hdss7-12 ~]# curl -H "Content-Type:application/json" -XPUT http://10.4.7.12:9200/_template/k8s -d '{ "template" : "k8s*", "index_patterns": ["k8s*"], "settings": { "number_of_shards": 5, "number_of_replicas": 0 } }'解释:
- "template" : "k8s*" 让Elasticsearch的template(匹配规则)参数去匹配k8s*参数
- "number_of_shards":5 ES的分片为5
- "number_of_replicas": 0 默认为1,因为只有一个节点,所以副本集调成0
- 为什么要curl 一个日志索引模板,ES有green、yellow、red三种机制,绿色集群状态正常,有冗余机制。其中黄色代表集群正常,但是没有冗余机制,如果要有冗余机制,根据number_of_replicas的数值,如果是1,代表至少有一个ES设备作为冗余设备(也可以叫至少有一个副本)。默认情况Elasticsearch副本也是为1,所以默认情况下,要想变成green,最起码有一个副本。但是恰巧我们只部署一个ES节点,而默认情况Elasticsearch副本为1,所以会变成yellow,这个时候修改number_of_replicas": 0 ,告诉ES,副本是0,就代表是green。状态变成黄色(警告),会导致莫名其妙的报错,虽然yellow也能用。
三、部署Kafka
Kafka网址:Apache Kafka
Kafka是有状态的服务,一般部署在Kubernetes之外,本次部署在 hdss7-11.host.com(10.4.7.11)。使用Kafka不要超过2.2.0版本,因为后面需要部署的Kafka-manager,他是一个第三方的管理工具,此工具最高只支持到 2.2.0 版本,因此这次部署采用kafka_2.12-2.2.0版本,其中2.12为Scala版本号,2.2.0为kafka版本号。注:Kafka也是依赖jdk,所以必须在hdss7-11上有jdk,在部署zookpeer的时候hdss7-11部署jdk1.8。
3.1、下载Kafka
[root@hdss7-11 ~]# cd /opt/src/
[root@hdss7-11 src]# wget https://archive.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz
[root@hdss7-11 src]# tar xfv kafka_2.12-2.2.0.tgz -C /opt/
[root@hdss7-11 src]# ln -s /opt/kafka_2.12-2.2.0 /opt/kafka3.2、配置Kafka
[root@hdss7-11 ~]# mkdir -pv /data/kafka/logs
[root@hdss7-11 ~]# vim /opt/kafka/config/server.properties # 修改其中的配置文件
log.dirs=/data/kafka/logs # kafka的日志路径
zookeeper.connect=localhost:2181 # 这里可以写一个zk地址,或者集群地址用逗号隔开。由于7-11本机有zk,所以连接本机的zk
log.flush.interval.messages=10000 # 超过10000条日志强制刷新落盘
log.flush.interval.ms=1000 # 每间隔1秒钟时间,刷数据到磁盘
delete.topic.enable=true # 此处在配置文档中没有,在最后添加进去。没有配置delete.topic.enable=true,Kafka 删除topic并不是真正的删除,而是把topic标记为:marked for deletion
host.name=hdss7-11.host.com # 此处在配置文档中没有,在最后添加进去。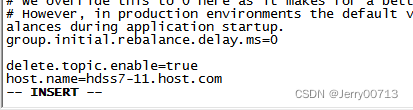
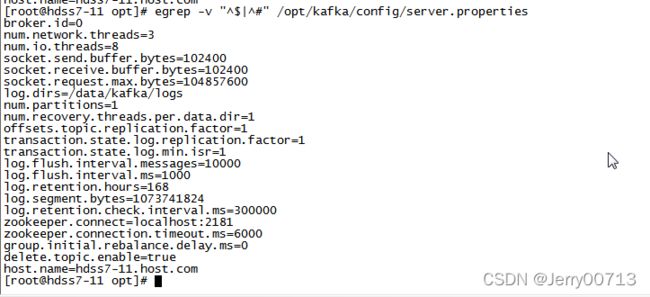
# 为什么kafka需要连接zookeeper:
Kafka主要使用ZooKeeper来保存它的元数据、监控Broker和分区的存活状态,并利用ZooKeeper来进行选举
# delete.topic.enable=true:
elete.topic.enable=true、 auto.create.topics.enable=false 只有这两个参数同时开启,kafka-manager才可以将某个topic删除干净。
auto.create.topics.enable意思是:produce可以推送消息到一个不存在的topic(即:发消息到一个不存在的topic,
系统会帮你按默认参数自动帮你建立这个topic),所以只要这个topic有produce向它推送消息,那么这个topic你是没办法被删除的。
通过kafka-manager删除时,如果删掉了,那么肯定是删干净了(有一定延迟,先标记删除,然后等空闲时间自行进行其他信息删除,
这一漫长的过程也可能会造成没删干净的假象);如果没删掉,这个topic会被标红(后台逻辑是:已经标记为删除了,数据也删了,
但在状态跟实际校验时发现并没有被删除,原因是被produce很快重建了,此时就出现了没删干净的状态,表现为:你新建时提示它已
经存在,你删除时它提示已经标记为删除)
3.3、启动Kafka
[root@hdss7-11 ~]# /opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
[root@hdss7-11 opt]# ps -ef |grep kafka
root 27823 1 9 12:56 pts/0 00:00:13 /usr/java/jdk/bin/java -Xmx1G -Xms1G -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true -Xloggc:/opt/kafka/bin/../logs/kafkaServer-gc.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dkafka.logs.dir=/opt/kafka/bin/../logs -Dlog4j.configuration=file:/opt/kafka/bin/../config/log4j.properties -cp /usr/java/jdk/lib:/usr/java/jdk/lib/tools.jar:/opt/kafka/bin/../libs/activation-1.1.1.jar:/opt/kafka/bin/../libs/aopalliance-repackaged-2.5.0-b42.jar:/opt/kafka/bin/../libs/argparse4j-0.7.0.jar:/opt/kafka/bin/../libs/audience-annotations-0.5.0.jar:/opt/kafka/bin/../libs/commons-lang3-3.8.1.jar:/opt/kafka/bin/../libs/connect-api-2.2.0.jar:/opt/kafka/bin/../libs/connect-basic-auth-extension-2.2.0.jar:/opt/kafka/bin/../libs/connect-file-2.2.0.jar:/opt/kafka/bin/../libs/connect-json-2.2.0.jar:/opt/kafka/bin/../libs/connect-runtime-2.2.0.jar:/opt/kafka/bin/../libs/connect-transforms-2.2.0.jar:/opt/kafka/bin/../libs/guava-20.0.jar:/opt/kafka/bin/../libs/hk2-api-2.5.0-b42.jar:/opt/kafka/bin/../libs/hk2-locator-2.5.0-b42.jar:/opt/kafka/bin/../libs/hk2-utils-2.5.0-b42.jar:/opt/kafka/bin/../libs/jackson-annotations-2.9.8.jar:/opt/kafka/bin/../libs/jackson-core-2.9.8.jar:/opt/kafka/bin/../libs/jackson-databind-2.9.8.jar:/opt/kafka/bin/../libs/jackson-datatype-jdk8-2.9.8.jar:/opt/kafka/bin/../libs/jackson-jaxrs-base-2.9.8.jar:/opt/kafka/bin/../libs/jackson-jaxrs-json-provider-2.9.8.jar:/opt/kafka/bin/../libs/jackson-module-jaxb-annotations-2.9.8.jar:/opt/kafka/bin/../libs/javassist-3.22.0-CR2.jar:/opt/kafka/bin/../libs/javax.annotation-api-1.2.jar:/opt/kafka/bin/../libs/javax.inject-1.jar:/opt/kafka/bin/../libs/javax.inject-2.5.0-b42.jar:/opt/kafka/bin/../libs/javax.servlet-api-3.1.0.jar:/opt/kafka/bin/../libs/javax.ws.rs-api-2.1.1.jar:/opt/kafka/bin/../libs/javax.ws.rs-api-2.1.jar:/opt/kafka/bin/../libs/jaxb-api-2.3.0.jar:/opt/kafka/bin/../libs/jersey-client-2.27.jar:/opt/kafka/bin/../libs/jersey-common-2.27.jar:/opt/kafka/bin/../libs/jersey-container-servlet-2.27.jar:/opt/kafka/bin/../libs/jersey-container-servlet-core-2.27.jar:/opt/kafka/bin/../libs/jersey-hk2-2.27.jar:/opt/kafka/bin/../libs/jersey-media-jaxb-2.27.jar:/opt/kafka/bin/../libs/jersey-server-2.27.jar:/opt/kafka/bin/../libs/jetty-client-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-continuation-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-http-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-io-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-security-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-server-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-servlet-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-servlets-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-util-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jopt-simple-5.0.4.jar:/opt/kafka/bin/../libs/kafka_2.12-2.2.0.jar:/opt/kafka/bin/../libs/kafka_2.12-2.2.0-sources.jar:/opt/kafka/bin/../libs/kafka-clients-2.2.0.jar:/opt/kafka/bin/../libs/kafka-log4j-appender-2.2.0.jar:/opt/kafka/bin/../libs/kafka-streams-2.2.0.jar:/opt/kafka/bin/../libs/kafka-streams-examples-2.2.0.jar:/opt/kafka/bin/../libs/kafka-streams-scala_2.12-2.2.0.jar:/opt/kafka/bin/../libs/kafka-streams-test-utils-2.2.0.jar:/opt/kafka/bin/../libs/kafka-tools-2.2.0.jar:/opt/kafka/bin/../libs/log4j-1.2.17.jar:/opt/kafka/bin/../libs/lz4-java-1.5.0.jar:/opt/kafka/bin/../libs/maven-artifact-3.6.0.jar:/opt/kafka/bin/../libs/metrics-core-2.2.0.jar:/opt/kafka/bin/../libs/osgi-resource-locator-1.0.1.jar:/opt/kafka/bin/../libs/plexus-utils-3.1.0.jar:/opt/kafka/bin/../libs/reflections-0.9.11.jar:/opt/kafka/bin/../libs/rocksdbjni-5.15.10.jar:/opt/kafka/bin/../libs/scala-library-2.12.8.jar:/opt/kafka/bin/../libs/scala-logging_2.12-3.9.0.jar:/opt/kafka/bin/../libs/scala-reflect-2.12.8.jar:/opt/kafka/bin/../libs/slf4j-api-1.7.25.jar:/opt/kafka/bin/../libs/slf4j-log4j12-1.7.25.jar:/opt/kafka/bin/../libs/snappy-java-1.1.7.2.jar:/opt/kafka/bin/../libs/validation-api-1.1.0.Final.jar:/opt/kafka/bin/../libs/zkclient-0.11.jar:/opt/kafka/bin/../libs/zookeeper-3.4.13.jar:/opt/kafka/bin/../libs/zstd-jni-1.3.8-1.jar kafka.Kafka /opt/kafka/config/server.properties
root 28627 6671 0 12:59 pts/0 00:00:00 grep --color=auto kafka
[root@hdss7-11 opt]# netstat -lntp|grep 27823 # 9092默认是kafka与TCP进行通信的端口
tcp6 0 0 10.4.7.11:9092 :::* LISTEN 27823/java
tcp6 0 0 :::39071 :::* LISTEN 27823/java
[root@hdss7-11 opt]# 3.4、配置Kafka自动启
3.4.1、配置system
[root@hdss7-11 ~]# vi /etc/systemd/system/kafka.service
[Unit]
Description=Apache Kafka server (broker)
After=network.target zookeeper.service
[Service]
Type=forking
Environment=PATH=/usr/java/jdk/bin:/usr/java/jdk/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
ExecStart=/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
Restart=always
RestartSec=10
StartLimitInterval=0
LimitNOFILE=265535
[Install]
WantedBy=multi-user.target解释:
- Environment 为设置成你自己的环境变量,可以通过echo $PATH获得,只要使用里面jdk环境变量
- ExecStart 后面就是启动命令,也就是/opt/kafka/bin/kafka-server-start.sh -daemon /opt/kafka/config/server.properties
- Restart=always 只要不是通过systemctl stop来停止服务,任何情况下都必须要重启服务,默认值为no
- RestartSec=10 重启间隔,比如某次异常后,等待5(s)再进行启动,默认值0.1(s)
- StartLimitInterval 无限次重启,默认是10秒内如果重启超过5次则不再重启,设置为0表示不限次数重启
3.4.2、kill 掉现在的kakfa
[root@hdss7-11 opt]# ps -ef |grep kafka
root 27823 1 9 12:56 pts/0 00:00:13 /usr/java/jdk/bin/java -Xmx1G -Xms1G -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true -Xloggc:/opt/kafka/bin/../logs/kafkaServer-gc.log -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=10 -XX:GCLogFileSize=100M -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Dkafka.logs.dir=/opt/kafka/bin/../logs -Dlog4j.configuration=file:/opt/kafka/bin/../config/log4j.properties -cp /usr/java/jdk/lib:/usr/java/jdk/lib/tools.jar:/opt/kafka/bin/../libs/activation-1.1.1.jar:/opt/kafka/bin/../libs/aopalliance-repackaged-2.5.0-b42.jar:/opt/kafka/bin/../libs/argparse4j-0.7.0.jar:/opt/kafka/bin/../libs/audience-annotations-0.5.0.jar:/opt/kafka/bin/../libs/commons-lang3-3.8.1.jar:/opt/kafka/bin/../libs/connect-api-2.2.0.jar:/opt/kafka/bin/../libs/connect-basic-auth-extension-2.2.0.jar:/opt/kafka/bin/../libs/connect-file-2.2.0.jar:/opt/kafka/bin/../libs/connect-json-2.2.0.jar:/opt/kafka/bin/../libs/connect-runtime-2.2.0.jar:/opt/kafka/bin/../libs/connect-transforms-2.2.0.jar:/opt/kafka/bin/../libs/guava-20.0.jar:/opt/kafka/bin/../libs/hk2-api-2.5.0-b42.jar:/opt/kafka/bin/../libs/hk2-locator-2.5.0-b42.jar:/opt/kafka/bin/../libs/hk2-utils-2.5.0-b42.jar:/opt/kafka/bin/../libs/jackson-annotations-2.9.8.jar:/opt/kafka/bin/../libs/jackson-core-2.9.8.jar:/opt/kafka/bin/../libs/jackson-databind-2.9.8.jar:/opt/kafka/bin/../libs/jackson-datatype-jdk8-2.9.8.jar:/opt/kafka/bin/../libs/jackson-jaxrs-base-2.9.8.jar:/opt/kafka/bin/../libs/jackson-jaxrs-json-provider-2.9.8.jar:/opt/kafka/bin/../libs/jackson-module-jaxb-annotations-2.9.8.jar:/opt/kafka/bin/../libs/javassist-3.22.0-CR2.jar:/opt/kafka/bin/../libs/javax.annotation-api-1.2.jar:/opt/kafka/bin/../libs/javax.inject-1.jar:/opt/kafka/bin/../libs/javax.inject-2.5.0-b42.jar:/opt/kafka/bin/../libs/javax.servlet-api-3.1.0.jar:/opt/kafka/bin/../libs/javax.ws.rs-api-2.1.1.jar:/opt/kafka/bin/../libs/javax.ws.rs-api-2.1.jar:/opt/kafka/bin/../libs/jaxb-api-2.3.0.jar:/opt/kafka/bin/../libs/jersey-client-2.27.jar:/opt/kafka/bin/../libs/jersey-common-2.27.jar:/opt/kafka/bin/../libs/jersey-container-servlet-2.27.jar:/opt/kafka/bin/../libs/jersey-container-servlet-core-2.27.jar:/opt/kafka/bin/../libs/jersey-hk2-2.27.jar:/opt/kafka/bin/../libs/jersey-media-jaxb-2.27.jar:/opt/kafka/bin/../libs/jersey-server-2.27.jar:/opt/kafka/bin/../libs/jetty-client-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-continuation-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-http-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-io-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-security-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-server-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-servlet-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-servlets-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jetty-util-9.4.14.v20181114.jar:/opt/kafka/bin/../libs/jopt-simple-5.0.4.jar:/opt/kafka/bin/../libs/kafka_2.12-2.2.0.jar:/opt/kafka/bin/../libs/kafka_2.12-2.2.0-sources.jar:/opt/kafka/bin/../libs/kafka-clients-2.2.0.jar:/opt/kafka/bin/../libs/kafka-log4j-appender-2.2.0.jar:/opt/kafka/bin/../libs/kafka-streams-2.2.0.jar:/opt/kafka/bin/../libs/kafka-streams-examples-2.2.0.jar:/opt/kafka/bin/../libs/kafka-streams-scala_2.12-2.2.0.jar:/opt/kafka/bin/../libs/kafka-streams-test-utils-2.2.0.jar:/opt/kafka/bin/../libs/kafka-tools-2.2.0.jar:/opt/kafka/bin/../libs/log4j-1.2.17.jar:/opt/kafka/bin/../libs/lz4-java-1.5.0.jar:/opt/kafka/bin/../libs/maven-artifact-3.6.0.jar:/opt/kafka/bin/../libs/metrics-core-2.2.0.jar:/opt/kafka/bin/../libs/osgi-resource-locator-1.0.1.jar:/opt/kafka/bin/../libs/plexus-utils-3.1.0.jar:/opt/kafka/bin/../libs/reflections-0.9.11.jar:/opt/kafka/bin/../libs/rocksdbjni-5.15.10.jar:/opt/kafka/bin/../libs/scala-library-2.12.8.jar:/opt/kafka/bin/../libs/scala-logging_2.12-3.9.0.jar:/opt/kafka/bin/../libs/scala-reflect-2.12.8.jar:/opt/kafka/bin/../libs/slf4j-api-1.7.25.jar:/opt/kafka/bin/../libs/slf4j-log4j12-1.7.25.jar:/opt/kafka/bin/../libs/snappy-java-1.1.7.2.jar:/opt/kafka/bin/../libs/validation-api-1.1.0.Final.jar:/opt/kafka/bin/../libs/zkclient-0.11.jar:/opt/kafka/bin/../libs/zookeeper-3.4.13.jar:/opt/kafka/bin/../libs/zstd-jni-1.3.8-1.jar kafka.Kafka /opt/kafka/config/server.properties
root 28627 6671 0 12:59 pts/0 00:00:00 grep --color=auto kafka
[root@hdss7-11 opt]# kill 27823
[root@hdss7-11 opt]# ps -ef |grep kafka
root 31248 6671 0 13:13 pts/0 00:00:00 grep --color=auto kafka
[root@hdss7-11 opt]# 3.4.2、启动kafka服务
[root@hdss7-11 opt]# systemctl daemon-reload # 更新systemd
[root@hdss7-11 opt]# systemctl enable kafka
[root@hdss7-11 opt]# systemctl start kafka # 启动kafka服务
四、部署Kafka-manager
Kafka-manager是一款管理Kafka集群的一个web工具软件
github地址:GitHub - yahoo/CMAK: CMAK is a tool for managing Apache Kafka clusters
版本列表:Releases · yahoo/CMAK · GitHub
4.1、准备Kafka-manager 镜像
方法一:自定义构建官方Kafka-manager镜像
[root@hdss7-200 ~]# cd /data/dockerfile/
[root@hdss7-200 dockerfile]# mkdir kafka-manager
[root@hdss7-200 dockerfile]# vi Dockerfile # 估计20min,而且built可能不成功,要从github上下载一系列资源,升级一些包FROM hseeberger/scala-sbt ENV ZK_HOSTS=10.4.7.11:2181 \ KM_VERSION=2.0.0.2 RUN mkdir -p /tmp && \ cd /tmp && \ wget https://github.com/yahoo/kafka-manager/archive/${KM_VERSION}.tar.gz && \ tar xf ${KM_VERSION}.tar.gz && \ cd /tmp/kafka-manager-${KM_VERSION} && \ sbt clean dist && \ unzip -d / ./target/universal/kafka-manager-${KM_VERSION}.zip && \ rm -fr /tmp/${KM_VERSION} /tmp/kafka-manager-${KM_VERSION} WORKDIR /kafka-manager-${KM_VERSION} EXPOSE 9000 ENTRYPOINT ["./bin/kafka-manager","-Dconfig.file=conf/application.conf"]解释: scala-sbt # 一个底包,相当于jdk镜像包,里面包含(一个运行时环境+开发包),因为kafka是java跟scala写的 ZK_HOSTS=10.4.7.11:2181 # zk地址是写死的 KM_VERSION=2.0.0.2 # 版本使用2.0.0.2 EXPOSE 9000 # 暴露9000端口
方法二:下载非官方Kafka-manager的镜像
准备Kafka-manager 的docker
[root@hdss7-200 ~]# docker image pull stanleyws/kafka-manager:v2.0.0.2 # 这个镜像包里面写死了(kafka-manager:v2.0.0.2 zk地址写死了10.4.7.11:2181) 或者 [root@hdss7-200 ~]# docker load < kafka-manager-v2.0.0.2.tar # 导入kafka-manager:v2.0.0.2,这个镜像包里面(kafka-manager:v2.0.0.2 zk地址写死了10.4.7.11:2181) 或者 [root@hdss7-200 ~]# docker image pull linuxduduniao/kafka-manager:v2.0.0.2
推送到harbor
[root@hdss7-200 ~]# docker image ls -a |grep kafka-manager
harbor.od.com/infra/kafka-manager v2.0.0.2 29badab5ea08 2 years ago 1.36GB
[root@hdss7-200 ~]# docker image tag 29badab5ea08 harbor.od.com:180/infra/kafka-manager:v2.0.0.2
[root@hdss7-200 ~]# docker login harbor.od.com:180
[root@hdss7-200 ~]# docker image push harbor.od.com:180/infra/kafka-manager:v2.0.0.24.2、准备资源配置清单
[root@hdss7-200 dockerfile]# cd /data/k8s-yaml/
[root@hdss7-200 k8s-yaml]# mkdir kafka-manager;cd kafka-manager
[root@hdss7-200 kafka-manager]# vi dp.yaml
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: kafka-manager
namespace: infra
labels:
name: kafka-manager
spec:
replicas: 1
selector:
matchLabels:
app: kafka-manager
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
revisionHistoryLimit: 7
progressDeadlineSeconds: 600
template:
metadata:
labels:
app: kafka-manager
spec:
containers:
- name: kafka-manager
image: harbor.od.com:180/infra/kafka-manager:v2.0.0.2
ports:
- containerPort: 9000
protocol: TCP
env:
- name: ZK_HOSTS
value: zk1.od.com:2181
- name: APPLICATION_SECRET
value: letmein
imagePullSecrets:
- name: harbor
terminationGracePeriodSeconds: 30
securityContext:
runAsUser: 0解释:
apiVersion: extensions/v1beta1
apiVersion: apps/v1 # 在1.6.1后extensions/v1beta1这个api组已经废弃了,使用apps/v1strategy:
type: RollingUpdate # 采用的策略为滚动升级- name: APPLICATION_SECRET # kafka默认从环境变量APPLICATION_SECRET获取密码,如果没有这个登录不进去
value: letmein
[root@hdss7-200 kafka-manager]# vi svc.yaml
apiVersion: v1
kind: Service
metadata:
name: kafka-manager
namespace: infra
spec:
ports:
- protocol: TCP
port: 9000
targetPort: 9000
selector:
app: kafka-manager[root@hdss7-200 kafka-manager]# vi ingress.yaml # web界面需要ingress
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kafka-manager
namespace: infra
spec:
rules:
- host: km.od.com
http:
paths:
- path: /
backend:
serviceName: kafka-manager
servicePort: 90004.3、解析域名
[root@hdss7-11 ~]# vi /var/named/od.com.zone
$ORIGIN od.com.
$TTL 600 ; 10 minutes
@ IN SOA dns.od.com. dnsadmin.od.com. (
2020010501 ; serial
10800 ; refresh (3 hours)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
NS dns.od.com.
$TTL 60 ; 1 minute
dns A 10.4.7.11
$ORIGIN od.com.
$TTL 600 ; 10 minutes
@ IN SOA dns.od.com. dnsadmin.od.com. (
2020010518 ; serial
10800 ; refresh (3 hours)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
NS dns.od.com.
$TTL 60 ; 1 minute
dns A 10.4.7.11
harbor A 10.4.7.200
k8s-yaml A 10.4.7.200
traefik A 10.4.7.10
dashboard A 10.4.7.10
zk1 A 10.4.7.11
zk2 A 10.4.7.12
zk3 A 10.4.7.21
jenkins A 10.4.7.10
dubbo-monitor A 10.4.7.10
demo A 10.4.7.10
config A 10.4.7.10
mysql A 10.4.7.11
portal A 10.4.7.10
zk-test A 10.4.7.11
zk-prod A 10.4.7.12
config-test A 10.4.7.10
config-prod A 10.4.7.10
demo-test A 10.4.7.10
demo-prod A 10.4.7.10
blackbox A 10.4.7.10
prometheus A 10.4.7.10
grafana A 10.4.7.10
km A 10.4.7.10[root@hdss7-11 ~]# systemctl restart named
[root@hdss7-11 ~]# dig -t A km.od.com @10.4.7.11 +short
10.4.7.10
4.3、应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/kafka-manager/dp.yaml
deployment.extensions/kafka-manager created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/kafka-manager/svc.yaml
service/kafka-manager created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/kafka-manager/ingress.yaml
ingress.extensions/kafka-manager created如何判断Linux的负载情况(不在部署)
1、查看uptime的负载
[root@hdss7-21 ~]# uptime 14:05:39 up 14 days, 23:14, 1 user, load average: 3.46, 3.66, 3.672、用top查看负载
[root@hdss7-21 ~]# top top - 14:04:33 up 14 days, 23:13, 1 user, load average: 3.34, 3.72, 3.69 Tasks: 342 total, 3 running, 339 sleeping, 0 stopped, 0 zombie %Cpu0 : 8.3 us, 17.3 sy, 0.0 ni, 74.4 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 7.9 us, 18.3 sy, 0.0 ni, 73.5 id, 0.0 wa, 0.0 hi, 0.4 si, 0.0 st %Cpu2 : 9.5 us, 18.7 sy, 0.0 ni, 71.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu3 : 10.1 us, 17.8 sy, 0.0 ni, 72.1 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 15969464 total, 513356 free, 7024104 used, 8432004 buff/cache KiB Swap: 33554428 total, 33554428 free, 0 used. 7701828 avail M3、如何判断本地的负载是否高
load average: 3.34, 3.72, 3.69 ,load average 负载的意思,3.34为1min平均负载,3.72为5min平均负载,3.69 为10min平均负载
通过执行top命令后,按1后查看为4核,代表如果负载不超过4×2=8 ,就是可以接受的。1核可以处理一个,并排队等待一个。如果多一个就要多等待一个。所以8<3.34 为正常
4.4、配置Kafka-manager
访问http://km.od.com/
点击Add Cluster,进行基础连接配置,连接Kafka
Kafka主要使用ZooKeeper来保存它的元数据、监控Broker和分区的存活状态,并利用ZooKeeper来进行选举。而Kafka-manager是一款管理Kafka集群的一个web工具软件,所以他也需要连接zk,才能做Kafka做的事情,存储元数据监控等。所以他们需要连接一个zk或者zk集群,如果是zk集群的话,以逗号隔开(如zk1.od.com:2181,zk2.od.com:2181,zk3.od.com:2181)。kafka version 填写kafka-manager的版本。剩下其他的都默认

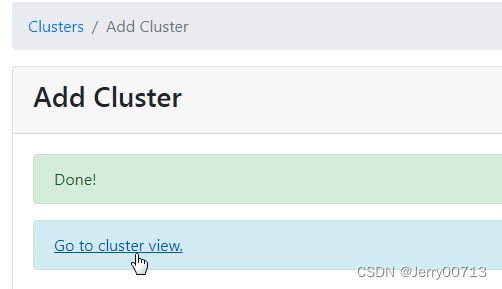
点击save
点击Go to cluster view.
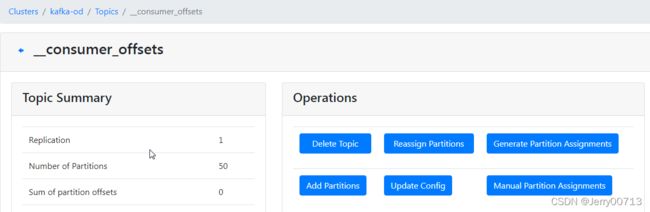
此界面为kafka-od

点击Topic -> List
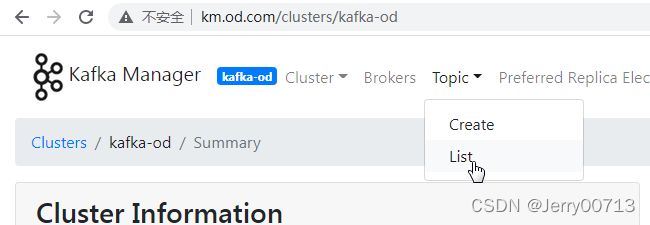
此页面就会列出topics
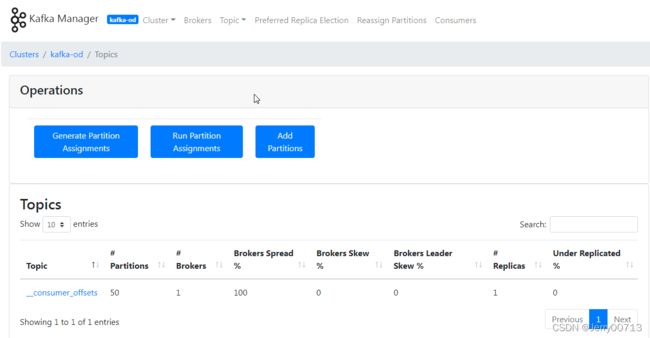
默认列表带一个topics(_consumer_offsets消费者的偏移量),因为kafka本身是发布订阅模型,必须有生产者发布topic主题,然后消费者才能去消费 (kafka作为生产者Producer 生产某个topic对象(可以叫共享资源),放在缓冲池中,然后消费者从缓冲池中取出这个对象,也就是生产者生产一个,消费者取出一个,这样进行循环)。在后续部署filebeat,会讲述filebeat怎么订阅这个主题(topic)
五、部署filebeat
filebeat网址:Download Filebeat • Lightweight Log Analysis | Elastic
filebeat部署原则:
1、把filebeat容器跟业务容器以边车模式,运行在一个pod中。
2、取出业务容器产生出来的日志,并打到kafka中产生topic主题
filebeat选择版本原则:
ES选择的是6.8.6,配套的logstash、filebeat、kafka都用6.8.6最好。但非必须都配套,因为在这个高配的ELK里面,所有的环节通过http通信,所以restful api 接口没有变,所以对版本要求不高, filebeat 使用6.8.6相近的版本问题并不大。filebeat 通过http走9200端口跟kafka通信,所以此次部署使用 7.5.1也没问题。
(RESTful API是REST风格的API,是一套用来规范多种形式的前端和同一个后台的交互方式的协议。RESTful API由后台也就是SERVER来提供前端来调用;前端调用API向后台发起HTTP请求,后台响应请求将处理结果反馈给前端。)
5.1、制作filebeat镜像
方式一:使用Dockerfile 制作全新底包
访问(https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.5.1-linux-x86_64.tar.gz.sha512)后跳转下载并打开,文件中的内容替换到下文的Dockerfile配置文件中的FILEBEAT_SHA1=后的数值。如果想使用其他的版本,就替换其他版本的FILEBEAT_SHA1,此数值类似于MD5校验
![]()

制作filebeat-7.5.1镜像
[root@hdss7-200 ~]# cd /data/dockerfile/
[root@hdss7-200 dockerfile]# mkdir filebeat;cd filebeat
[root@hdss7-200 filebeat]# vi Dockerfile
FROM debian:jessie
ENV FILEBEAT_VERSION=7.5.1 \
FILEBEAT_SHA1=daf1a5e905c415daf68a8192a069f913a1d48e2c79e270da118385ba12a93aaa91bda4953c3402a6f0abf1c177f7bcc916a70bcac41977f69a6566565a8fae9c
RUN set -x && \
apt-get update && \
apt-get install -y wget && \
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-${FILEBEAT_VERSION}-linux-x86_64.tar.gz -O /opt/filebeat.tar.gz && \
cd /opt && \
echo "${FILEBEAT_SHA1} filebeat.tar.gz" | sha512sum -c - && \
tar xzvf filebeat.tar.gz && \
cd filebeat-* && \
cp filebeat /bin && \
cd /opt && \
rm -rf filebeat* && \
apt-get purge -y wget && \
apt-get autoremove -y && \
apt-get clean && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
COPY docker-entrypoint.sh /
ENTRYPOINT ["/docker-entrypoint.sh"]解释:
- && \ # 表示前一个执行后正常了后一个才会执行
- RUN set -x && \ # set -x:在set命令之后执行的每一条命令以及加载命令行中的任何参数都会显示出来,每一行都会加上加号(+),提示它是跟踪输出的标识,代替了每行都要echo显示详细信息。set -x 是开启, set +x是关闭
- apt-get update && \ # debian系统的yum命令为apt-get,所以apt-get update这个命令,会访问源列表(/etc/apt/sources.list 类似于yum中的epel.repo)里的每个网址,并读取软件列表,然后保存在本地电脑。我们在软件包管理器里看到的软件列表,都是通过update命令更新的。
- apt-get install -y wget && \ # 安装wget
- echo "${FILEBEAT_SHA1} filebeat.tar.gz" | sha512sum -c - && \ # 使用sha512sum命令对比本地的filebeat.tar.gz跟官网的filebeat.tar.gz密钥是不是一致。保障安全
- sha512sum -c 命令讲解:sha512sum是md5的一种,通过sha512sum命令可以给任何文件,算出它的密钥,使用方法(sha512sum 文件),随后在shell中返回密钥+文件名
如何使用这个密钥进行,像md5那种校验?第一种使用方法( echo "密钥数值 文件" | sha512sum -c)。
文件可以使用绝对路径也可使用相对路径
第二种使用方法,sha512sum支持把信息放入文件中,在文件中对比。举例子说明,比如使用(sha512sum 123.exe)会在shell中返回123.exe的密钥+文件的名子123.exe,把这个信息,重定向存入到一个文件中,此时文件中就有两个参数(123.exe密钥 123.exe),使用sha512sum -c 文件名,让123.exe文件的密钥 跟 当前目录下123.exe程序的密钥)对比是不是一致

制作entrypoint.sh
[root@hdss7-200 filebeat]# vi docker-entrypoint.sh
#!/bin/bash
ENV=${ENV:-"test"}
PROJ_NAME=${PROJ_NAME:-"no-define"}
MULTILINE=${MULTILINE:-"^\d{2}"}
KAFKA_ADDR=${KAFKA_ADDR:-'"10.4.7.11:9092"'}
cat > /etc/filebeat.yaml << EOF
filebeat.inputs:
- type: log
fields_under_root: true
fields:
topic: logm-${PROJ_NAME}
paths:
- /logm/*.log
- /logm/*/*.log
- /logm/*/*/*.log
- /logm/*/*/*/*.log
- /logm/*/*/*/*/*.log
scan_frequency: 120s
max_bytes: 10485760
multiline.pattern: '$MULTILINE'
multiline.negate: true
multiline.match: after
multiline.max_lines: 100
- type: log
fields_under_root: true
fields:
topic: logu-${PROJ_NAME}
paths:
- /logu/*.log
- /logu/*/*.log
- /logu/*/*/*.log
- /logu/*/*/*/*.log
- /logu/*/*/*/*/*.log
- /logu/*/*/*/*/*/*.log
output.kafka:
hosts: [${KAFKA_ADDR}]
topic: k8s-fb-$ENV-%{[topic]}
version: 2.0.0
required_acks: 0
max_message_bytes: 10485760
EOF
set -xe
if [[ "$1" == "" ]]; then
exec filebeat -c /etc/filebeat.yaml
else
exec "$@"
fi解释:
- ENV=${ENV:-"test"} :定义环境变量,表示收的是那个环境下的日志。比如测试环境、开发环境、生产环境,如果没有定义默认给的是test环境
- PROJ_NAME=${PROJ_NAME:-"no-define"} :定义项目的名字(之前说过相同的项目启动多份pod+filebeat,要把日志打到一份topic,如何做到,相同的项目启动的pod使用同一个PROJ_NAME项目名)。之前说过,要让Kibana按照不同的项目做区分(比如卖自行车项目、卖吃的项目),而这些filebeat传给我Kibana的日志,Kibana检索的时候,势必要用到一个参数对日志做区分是那个项目的日志,如何区分?使用filebeat的PROJ_NAME参数,让相同项目pod上传的日志,都打上相同的标签。比如是dubbo-demo-server这个项目,给filebeat传一个PROJ_NAME名字dubbo-demo-server。就不要给默认没定义no-define。对于kafka来说,其实它也可以不使用topic进行项目区分,之前说过把filebeat传过来的日志kafka原封不动在给logstash,由logstash进行过滤传给ES中不同的index节点,让ES显示的时候,不同的index就是不同的项目。但是我们还有一个需求,就是不但但要区分项目,还要区分这个项目对应的环境,比如卖自行车项目,分测试环境的日志、生产环境的日志。而目前已经使用logstash过滤了项目,在ES不同的index显示项目,怎么还区分环境呢?所以目前的规划是,让相同的项目的filebeat使用相同的PROJ_NAME,在传给kafka。然后由kafka进行项目的区分,然后再由logstash过滤同一个项目中日志,是那个环境下传过来的,按照环境在传递给不同的index,最后让index区分环境。实现由区分项目,还区分环境。
- MULTILINE=${MULTILINE:-"^\d{2}"} :多行匹配,java这样的日志,一条日志很长,可能需要分多行输出,而如果按照一行为一条日志规则,那么日志信息就会凌乱,开发没发看,所以要做多行匹配。使用正则的规则进行匹配多行(filebeat、logstash等收集日志,都是使用正则多行匹配)。
^\d{2}:^表示以什么开头, 以\d表示数字, {2}表示两位数字。这个正则表示以2两位数开头。多条正则是用 | 匹配。
所以MULTILINE=${MULTILINE:-"^\d{2}"} 这条语句的意思是,对每一行做匹配,如果这一行,以2两位数开头,我认为这是一条日志的起始位置,在匹配下一行,如果不满足,把这行拼接到上一行尾部,直到遇到第n行,也是以2两位数开头,则认为是这条日志的结束位置。- KAFKA_ADDR=${KAFKA_ADDR:-'"10.4.7.11:9092"'} # 连接kafka的地址,如果不赋值,默认为10.4.7.11:9092
- cat > /etc/filebeat.yaml << EOF # 以下内容写入filebeat的配置文件etc/filebeat.yaml
filebeat.inputs: # filebeat的配置,从那获取日志
- type: log # 日志类型
fields_under_root: true
fields:
topic: logm-${PROJ_NAME} # 按照项目给topic起名字
paths: # 获取日志的匹配规则,logm叫做多行日志匹配,logu单行日志匹配
- /logm/*.log # 匹配 logm下的一级目录的*.log
- /logm/*/*.log # 匹配 logm下的一级目录的*,匹配二级目录*.log
- /logm/*/*/*.log
- /logm/*/*/*/*.log
- /logm/*/*/*/*/*.log- scan_frequency: 120s # prospector扫描新文件的时间间隔,默认10秒
- max_bytes: 10485760 # 单文件最大收集的字节数,单文件超过此字节数后的字节将被丢弃,默认10MB,需要增大,保持与日志输出配置的单文件最大值一致即可
- multiline.pattern: '$MULTILINE' # 由于是logm,所以获取MULTILINE=^\d{2},做多行正则匹配
- multiline.negate: true # multiline.negate和multiline.match组合,multiline.negate: true和multiline.match: after 连续不匹配的行将被添加到前一个匹配的行。搭配$MULTILINE去判断
- multiline.match: after # 定义多行内容被添加到模式匹配行之后还是之前,默认无,可以被设置为after或者before。意思是搭配$MULTILINE去判断,从以2个数字开头的行开始,第二行不是2个数字开头的,是把第二行拼接到第一行尾部(alter),还是把第二行放在第一行开头(before)
- multiline.max_lines: 100 # 单一多行匹配聚合的最大行数,超过定义行数后的行会被丢弃,默认500。从遇到2个数字开头的为第一行,一直到第101行,都不是2个数字开头,我默认把这条日志丢弃,考虑到这条日志没有价值
- ........
paths: # 单日志匹配,把logu下的5级目录*.log匹配,匹配落盘的是一行收一行收
- /logu/*.log
- /logu/*/*.log
........- output.kafka: # 输出到kafka,filebeat收集到的日志传递给kafka规则
- hosts: [${KAFKA_ADDR}] # 写kafka的地址,上文定义了KAFKA_ADDR:-'"10.4.7.11:9092",如果是集群就是逗号分隔
- topic: k8s-fb-$ENV-%{[topic]} # kafka的topic名字,%{[topic]其中这个topic,是上文定义的(topic: logm-${PROJ_NAME})或者是(topic: logu-${PROJ_NAME}),这个%是filebeat内部配置文件变量。例如k8s-fb-test-logm-dubbo-demo-service。
- version: 2.0.0 # kafka 版本,注意就算使用高于kafka 2.0.0版本,比如2.2.0,也的写2.0.0,如果是低于2.0.0版本,就写实际版本。因为此处如果大于2.0.0报错
- if [[ "$1" == "" ]]; then
exec filebeat -c /etc/filebeat.yaml # 执定配置文件启动- filebeat常见配置项梳理:记Filebeat的prospectors部分配置说明_Jerry00713的博客-CSDN博客_filebeat 筛选filebeat常见配置项梳理_Jerry00713的博客-CSDN博客_filebeat 过滤文件
提权制作
[root@hdss7-200 filebeat]# chmod u+x docker-entrypoint.sh
[root@hdss7-200 filebeat]# docker image build . -t harbor.od.com:180/infra/filebeat:v7.5.1
[root@hdss7-200 filebeat]# docker login harbor.od.com:180
[root@hdss7-200 filebeat]# docker image push harbor.od.com:180/infra/filebeat:v7.5.1
方式二:因为Dockerfile通过wget下载filebeat速度太慢,采用windows环境中下载好的压缩包直接ADD到镜像中
1、下载filebeat镜像并创建Dockerfile
[root@hdss7-200 ~]# cd /data/Dockerfile/
[root@hdss7-200 Dockerfile]# mkdir filebeat;cd filebeat
[root@hdss7-200 Dockerfile]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.5.1-linux-x86_64.tar.gz -O /data/Dockerfile/filebeat/filebeat.tar.gz
[root@hdss7-200 filebeat]# vi Dockerfile
FROM debian:jessie
ADD filebeat.tar.gz /opt/
RUN set -x && tar xzvf /opt/filebeat.tar.gz && cp /opt/filebeat-*/filebeat /bin && rm -fr /opt/filebeat*
COPY docker-entrypoint.sh /
ENTRYPOINT ["/docker-entrypoint.sh"]2、跟 (方式一)配置的entrypoint.sh 一样
[root@hdss7-200 filebeat]# vi docker-entrypoint.sh
#!/bin/bash
ENV=${ENV:-"test"}
PROJ_NAME=${PROJ_NAME:-"no-define"}
MULTILINE=${MULTILINE:-"^\d{2}"}
KAFKA_ADDR=${KAFKA_ADDR:-'"10.4.7.11:9092"'}
cat > /etc/filebeat.yaml << EOF
filebeat.inputs:
- type: log
fields_under_root: true
fields:
topic: logm-${PROJ_NAME}
paths:
- /logm/*.log
- /logm/*/*.log
- /logm/*/*/*.log
- /logm/*/*/*/*.log
- /logm/*/*/*/*/*.log
scan_frequency: 120s
max_bytes: 10485760
multiline.pattern: '$MULTILINE'
multiline.negate: true
multiline.match: after
multiline.max_lines: 100
- type: log
fields_under_root: true
fields:
topic: logu-${PROJ_NAME}
paths:
- /logu/*.log
- /logu/*/*.log
- /logu/*/*/*.log
- /logu/*/*/*/*.log
- /logu/*/*/*/*/*.log
- /logu/*/*/*/*/*/*.log
output.kafka:
hosts: [${KAFKA_ADDR}]
topic: k8s-fb-$ENV-%{[topic]}
version: 2.0.0
required_acks: 0
max_message_bytes: 10485760
EOF
set -xe
if [[ "$1" == "" ]]; then
exec filebeat -c /etc/filebeat.yaml
else
exec "$@"
fi3、提权制作
[root@hdss7-200 filebeat]# chmod u+x docker-entrypoint.sh
[root@hdss7-200 filebeat]# docker image build . -t harbor.od.com:180/infra/filebeat:v7.5.1
[root@hdss7-200 filebeat]# docker login harbor.od.com:180
[root@hdss7-200 filebeat]# docker image push harbor.od.com:180/infra/filebeat:v7.5.15.2、修改资源配置清单
修改dubbo-demo-web-tomcat 资源配置清单,使其启动Tomcat业务容器的时候,边车模式启动filebeat容器
[root@hdss7-200 ~]# cd /data/k8s-yaml/test/dubbo-demo-web-tomcat
[root@hdss7-200 dubbo-demo-web-tomcat]# vi dp.yaml# 此deployment.yaml修改的是apollo章节中test环境下dubbo-demo-consumer服务 # 需要apollo、生产者启动,否则一直报错 kind: Deployment apiVersion: extensions/v1beta1 metadata: name: dubbo-demo-web-tomcat namespace: test labels: name: dubbo-demo-web-tomcat spec: replicas: 1 selector: matchLabels: name: dubbo-demo-web-tomcat template: metadata: labels: app: dubbo-demo-web-tomcat name: dubbo-demo-web-tomcat spec: containers: - name: dubbo-demo-web-tomcat image: harbor.od.com:180/app/dubbo-demo-web-tomcat:tomcat_210310_0900 imagePullPolicy: IfNotPresent ports: - containerPort: 8080 protocol: TCP env: - name: C_OPTS value: -Denv=fat -Dapollo.meta=http://config-test.od.com volumeMounts: - mountPath: /opt/tomcat/logs name: logm - name: filebeat image: harbor.od.com:180/infra/filebeat:v7.5.1 imagePullPolicy: IfNotPresent env: - name: ENV value: test - name: PROJ_NAME value: dubbo-demo-web - name: KAFKA_ADDR value: '"10.4.7.11:9092"' volumeMounts: - mountPath: /logm name: logm volumes: - emptyDir: {} name: logm imagePullSecrets: - name: harbor restartPolicy: Always terminationGracePeriodSeconds: 30 securityContext: runAsUser: 0 schedulerName: default-scheduler strategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 maxSurge: 1 revisionHistoryLimit: 7 progressDeadlineSeconds: 600解释:
-------------------------------------------------------------------------------------------------------------------------
- name: dubbo-demo-web-tomcat # 以下操作都是针对业务容器
volumeMounts:
- mountPath: /opt/tomcat/logs
name: logm
# 在pod资源中声明了一个叫logm名字的volumes,在此资源清单中,logm等于emptyDir{},代表在宿主机中随便开了一个目录,这个目录什么都没有。然后就是把这个目录挂载到业务容器的/opt/tomcat/logs 目录,也就是说,/opt/tomcat/logs目录有什么内容,宿主机的随机目录也会有什么内容
-------------------------------------------------------------------------------------------------------------------------
- name: filebeat # pod资源中又实例化了一个容器叫filebeat ,这样tomcat容器跟filebeat容器都在一个pod资源中,才能进行边车模式,他们共享了主机名、用户名、进程通信。隔离pid、vfs(文件系统)。容器到底隔离了什么?_Jerry00713的博客-CSDN博客。以下操作都是针对filebeat容器
----------------------------------
env: # 给filebeat容器传递env
- name: ENV
value: test
- name: PROJ_NAME # 给filebeat容器传递PROJ_NAME项目名称,也就传递给kafka的项目名字,区分topic
value: dubbo-demo-web
- name: KAFKA_ADDR # 给filebeat容器传递kafka地址
value: '"10.4.7.11:9092"'
----------------------------------
volumeMounts: # filebeat 的容器中,把宿主机的空目录挂在到了/logm
- mountPath: /logm
name: logm
# 在pod资源中声明了一个叫logm名字的volumes,在此资源清单中,logm等于emptyDir{},代表在宿主机中随便开了一个目录,这个目录什么都没有。然后就是把这个目录挂载到filebeat容器的/logm 目录,也就是说,filebeat自己不会在/logm目录创建文件,但由于/logm目录是同步的宿主机的“随机空目录”,而“随机空目录”也不会创建文件,但是宿主机的”随机空目录”同步的是业务容器的/opt/tomcat/logs 目录,他是tomcat的日志路径,所以把tomcat日志的目录同步到了宿主机的“随机空目录”,filebeat容器的有同步了宿主机的“随机空目录”,间接的filebeat容器的/logm目录同步了业务容器的/opt/tomcat/logs 目录。而在filebeat中还配置了获取多行日志是从/logm中获取
-------------------------------------------------------------------------------------------------------------------------
volumes:
- emptyDir: {}
name: logm
# 在pod资源中里面声明了一个存储卷,这个存储卷类型是emptyDir空目录,也就是宿主机会随机产生一个目录,这个目录什么也没有,把这个目录挂载给pod资源,并在pod资源中给这个挂载行为起一个名字叫logm 。emptyDir空目好处是,容器被销毁,这片存储空间被销毁。毕竟日志最后都是被ES收集,容器消亡了,宿主机的目录我后续一个一个手动删除么
-------------------------------------------------------------------------------------------------------------------------
思考:如果不使用边车模式,有其他方案进行日志收集?
可以单独写filebeat的yaml,类型为DeamonSet,在每一个节点自动启动一份。但是缺点比较明显,需要被收集日志的容器,要把所有的日志挂载到宿主机的固定的一个目录里面,比如都存在/data/下,tomcat可以存在/data/tomcat,nginx存在/data/nginx下,然后filebeat收集/data/*的日志。如果每个开发都按照自己的意愿,在业务代码中,日志的路径随自己心意写,那filebeat的匹配规则也需要按照业务容器实际的路径挂载。无形中增加了运维的工作量,而且收集起来特别费劲。如果想让负责每个模块的研发,把日志都打在一个位置,比如都在打/data目录下,我filebeat收集/data下的n级目录就行了,但需要跟开发等沟通,路径能不能挂到这。
其中不需要给filebeat增加service、ingress资源,因为filebeat不需要在k8s集群中被发现,他只需要按照配置传递给kafka日志就行,也没有页面。
5.3、应用配置资源清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/test/dubbo-demo-web-tomcat/dp.yaml
deployment.extensions/dubbo-demo-web-tomcat configured
[root@hdss7-21 ~]# kubectl get pods -n test
NAME READY STATUS RESTARTS AGE
apollo-adminservice-f78fc56c5-jqqwr 1/1 Running 0 4h11m
apollo-configservice-946d67b75-4f5px 1/1 Running 0 4h11m
dubbo-demo-service-84c86f498d-n56fn 1/1 Running 0 4h6m
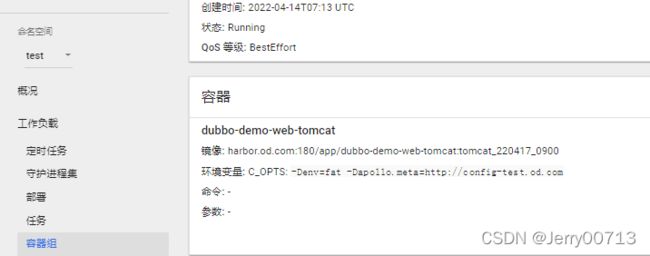
dubbo-demo-web-tomcat-6f89985bbc-8w887 2/2 Running 0 11m5.4、查看tomcat+filebeat容器状态
去k8s中,test名称空间下,查看dubbo-demo-web-tomcat 已经连接config-test.od.com。并最好查看logs是不是有报错

通过容器查看边车模式(不在部署中)
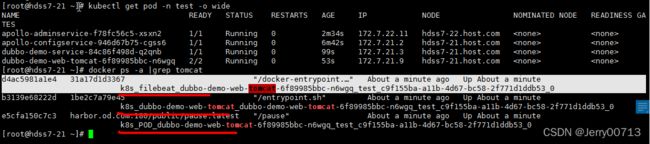
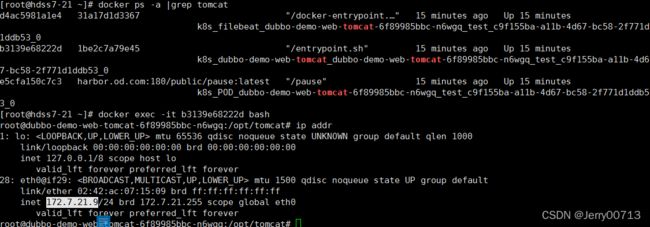
通过docker命令,查看tomcat相关容器,如下一个是tomcat业务容器(k8s_dubbo-demo-web-tomcat),一个是filebeat容器(k8s_filebeat_dubbo-demo-web-tomcat),一个PODS小容器(k8s_POD_dubbo-demo-web-tomcat)帮助业务容器初始化三个名称空间
通过docker exec -it /bin/bash命令,进入filebeat容器(k8s_filebeat_dubbo-demo-web-tomcat),查看/logm下的文件,会有tomcat的日志,说明了共享了tomcat业务容器的/opt/tomcat/logs 目录,所以filebeat容器拿到了tomcat日志
查看filebeat容器的hostname,发现跟tomcat业务容器的名字是一样的,说明两个容器是共享的UTS(UTS命名空间是Linux内核Namespace(命名空间)的一个子系统,主要用来区分主机名和域名的隔离。)
filebeat的容器的IP是172.7.22.5,查看dubbo-demo-web-tomcat业务容器的IP也是172.7.22.5,说明共享了网络名称空间
user是共享的(Linux系统将自身划分为两部分,一部分为核心软件,即是kernel,也称作内核空间,另一部分为普通应用程序,这部分称为用户空间。)
IPC不是共享的,想当于在filebeat中发一个指令不能kill业务容器的pid,所以隔离fs、pid、IPC (IPC的意思为,IPC提供了各种进程间通信的方法,使得各个进程的数据之间允许产生交互。隔离代表进程互不影响,不能交互)






5.5、查看kafka状态
刷新kafka,自动添加刚刚通过filebeat传过来的日志。注意为什么叫这个名字,是从环境变量中获取
访问http://demo-test.od.com/hello?name=tomcat后,刷新页面

通过kubectl exec -it 进入filebeat容器的/logm目录查看日志
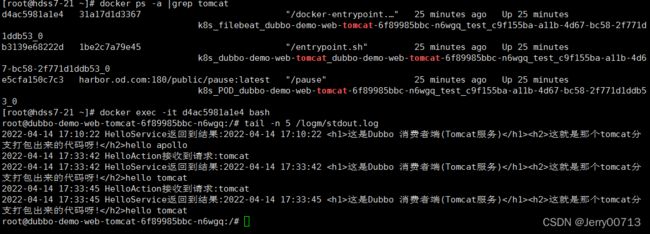
六、部署logstash
部署logstash,logstash跟kafka部署异步是过程,kafka是发布者,logstash是订阅者,所以logstash什么时候从kafka中调取数据,根据logstash的性能每次拿多少。但logstash跟ES是实时同步关系,logstash拿到多少数据,就必须都传给ES,不管ES能不能接收。此文档logstash只运行在一个docker中,未交付k8s中,等后续有时间在另写文档交付。
logstash选型:支持矩阵 | Elastic
总结:ES、logstash、kafka 、filebeat 尽量保持相同版本
6.1、 准备镜像
[root@hdss7-200 ~]# docker image pull logstash:6.8.6
[root@hdss7-200 ~]# docker image ls -a |grep logstash
logstash 6.8.6 d0a2dac51fcb 2 years ago 827MB
[root@hdss7-200 ~]# docker image tag d0a2dac51fcb harbor.od.com:180/infra/logstash:v6.8.6
[root@hdss7-200 ~]# docker login harbor.od.com:180
[root@hdss7-200 ~]# docker image push harbor.od.com:180/infra/logstash:v6.8.6
logstash按照环境区分(test、prod...) 对应的启动几个,因为topic区分项目,logstash区分环境,测试环境启动测试环境的logstash,生产启动生产的logstash,免的互相影响。
6.2、创建配置logstash
在启动logstash之前先创建配置logstash,在运维主机的宿主机上创建,然后把配置用-v 参数挂在logstash的docker
6.2.1、准备测试环境的logstash配置
# 后期如果logstash交付到k8s中,可以把ogstash.conf相关配置采用configmap方式挂载
# k8s在不同项目的名称空间中,可以创建不同的logstash,制定不同的索引
[root@hdss7-200 ~]# mkdir /etc/logstash/
[root@hdss7-200 ~]# vi /etc/logstash/logstash-test.conf
input {
kafka {
bootstrap_servers => "10.4.7.11:9092"
client_id => "10.4.7.200"
consumer_threads => 4
group_id => "k8s_test"
topics_pattern => "k8s-fb-test-.*"
}
}
filter {
json {
source => "message"
}
}
output {
elasticsearch {
hosts => ["10.4.7.12:9200"]
index => "k8s-test-%{+YYYY.MM.DD}"
}
}解释:
input { # logstash获取日志配置
bootstrap_servers => "10.4.7.11:9092" # logstash从那获取数据,从kafka(10.4.7.11:9092)
client_id => "10.4.7.200" # 在那个机器上启动logstash
consumer_threads => 4 # 4个线程
group_id => "k8s_dev" # test环境的logstash
topics_pattern => "k8s-fb-test-.*" # logstash过滤日志选项,从kafka中获取这些日志中,我只要k8s-fb-test-.*的日志。这里代表我只要test环境的日志
}output { # logstash输出日志配置
elasticsearch { # 输出到ES
hosts => ["10.4.7.12:9200"] # ES地址,如果是集群按逗号隔离
index => "k8s-dev-%{+YYYY.MM.DD}" # logstash把日志打包成什么样子,在传递给ES。ES接收后不做修改,直接显示,所以在ES中,就显示此处配置的名字。其中如果日志量大,在ES中一般会配置几天删除一份index索引(项目),并且建议在这配置天数(DD),因为配置天数后,每天都会在ES中产生一份项目,这样几天后,就可以删除第一份项目,比如第一天把日志都打到k8s-dev-2022.04.05,第二天都打到k8s-dev-2022.04.06,第三天就会删除第一天的k8s-dev-2022.04.05。但是如果不写天数,一个月生成一个项目,所有日志都往这里打,就算配置一天清除一份项目,也是一个月才能删除这份一份项目,比如k8s-dev-2022.04。毕竟一个月产生一份项目。
6.2.2、准备生产环境的logstash配置
[root@hdss7-200 ~]# vi /etc/logstash/logstash-prod.conf
input {
kafka {
bootstrap_servers => "10.4.7.11:9092"
client_id => "10.4.7.200"
consumer_threads => 4
group_id => "k8s_prod"
topics_pattern => "k8s-fb-prod-.*"
}
}
filter {
json {
source => "message"
}
}
output {
elasticsearch {
hosts => ["10.4.7.12:9200"]
index => "k8s-prod-%{+YYYY.MM.DD}"
}
}6.3、启动test环境的logstash
[root@hdss7-200 ~]# docker run -d --name logstash-test -v /etc/logstash/:/etc/logstash harbor.od.com:180/infra/logstash:v6.8.6 -f /etc/logstash/logstash-test.conf
- run -d 后台运行
- --name 起一个名字 logstash-test
- -v 数据卷映射, 宿主机/etc/logstash目录映射docker中/etc/logstash
- -f /etc/logstash/logstash-test.conf 指定配置
[root@hdss7-200 ~]# docker ps -a |grep logstash
7601a23dbd59 harbor.od.com:180/infra/kibana:v6.8.6 "/usr/local/bin/dock…" 36 seconds ago Up 35 seconds 5044/tcp, 9600/tcp logstash-test
6.4、验证ES里的索引
多刷新http://demo-test.od.com/hello?name=tomcat页面

查看ES中有没有索引,因为ES部署在hdss7-12上,所以curl http://10.4.7.12:9200/_cat/indices?v
其中(health status index uuid pri rep docs.count docs.deleted store.size pri.store.size)都是表头不是内容,过一阵子显示抓取到test环境下的日志k8s-dev-2020.02

七、部署Kibana
在运维主机HDSS7-200上部署
7.1、 准备镜像
[root@hdss7-200 ~]# docker pull kibana:6.8.6
docker image ls -a |grep kibana
kibana 6.8.6 adfab5632ef4 2 years ago 739MB
[root@hdss7-200 ~]# docker image tag adfab5632ef4 harbor.od.com:180/infra/kibana:v6.8.6
[root@hdss7-200 ~]# docker login harbor.od.com:180
[root@hdss7-200 ~]# docker image push harbor.od.com:180/infra/kibana:v6.8.67.2、准备资源配置清单
[root@hdss7-200 ~]# mkdir /data/k8s-yaml/kibana;cd /data/k8s-yaml/kibana
[root@hdss7-200 kibana]# vi dp.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: infra
labels:
name: kibana
spec:
replicas: 1
selector:
matchLabels:
name: kibana
template:
metadata:
labels:
app: kibana
name: kibana
spec:
containers:
- name: kibana
image: harbor.od.com:180/infra/kibana:v6.8.6
imagePullPolicy: IfNotPresent
ports:
- containerPort: 5601
protocol: TCP
env:
- name: ELASTICSEARCH_URL
value: http://10.4.7.12:9200
imagePullSecrets:
- name: harbor
securityContext:
runAsUser: 0
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
revisionHistoryLimit: 7
progressDeadlineSeconds: 600- containerPort: 5601 # Kibana 容器暴露5601端口
protocol: TCP
env:
- name: ELASTICSEARCH_URL # Kibana 连接那个ES
value: http://10.4.7.12:9200
[root@hdss7-200 kibana]# vi svc.yaml
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: infra
spec:
ports:
- protocol: TCP
port: 5601
targetPort: 5601
selector:
app: kibana[root@hdss7-200 kibana]# vi ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
namespace: infra
spec:
rules:
- host: kibana.od.com
http:
paths:
- path: /
backend:
serviceName: kibana
servicePort: 5601解析域名
[root@hdss7-11 ~]# vi /var/named/od.com.zone # 增加kibana域名解析,其他的不变
$ORIGIN od.com.
$TTL 600 ; 10 minutes
@ IN SOA dns.od.com. dnsadmin.od.com. (
2020010501 ; serial
10800 ; refresh (3 hours)
900 ; retry (15 minutes)
604800 ; expire (1 week)
86400 ; minimum (1 day)
)
NS dns.od.com.
$TTL 60 ; 1 minute
dns A 10.4.7.11
.....
kibana A 10.4.7.10[root@hdss7-11 ~]# systemctl restart named
[root@hdss7-11 ~]# dig -t A kibana.od.com @10.4.7.11 +short
10.4.7.10
7.3、 应用资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/kibana/dp.yaml
deployment.extensions/kibana created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/kibana/svc.yaml
service.extensions/kibana created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/kibana/ingress.yaml
ingress.extensions/kibana created
7.4、查看状态
访问http://kibana.od.com/ 点击Explore on my own
新版本的kibana带自动监控ES,点击Monitoring,点击Turn on Monitoring

Health is green 带包ES信息是绿的、健康的
Node: 1 代表有1个节点
indices: 5 代表有个5索引(Indices)
点击(indices: 5)后,如下图(k8s-test-2022.04.104)才是真正的业务索引

如何用Kibana显示索引中的日志信息呢?点击左侧management(创建不同环境的索引)

点击index Patterns
在index Patterns中,输入k8s-test-*,然后会显示检索到k8s-test-2022.04.104,但注意不是让你选择k8s-test-2022.04.104,就写k8s-test-*,因为以后索引会更新,比如是k8s-test-2020.01.123,一样能够匹配到,然后点击next
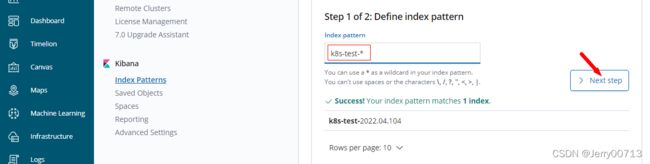
Time Filter field name 中填写默认时间戳(@timestamp),点击Create index pattern
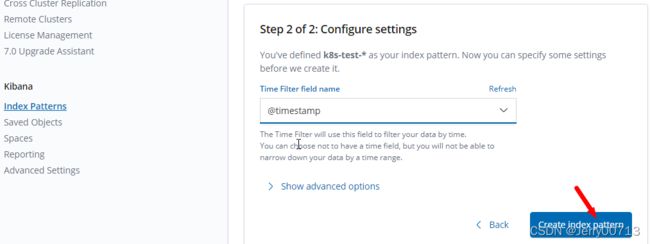 点击Discover,能看到k8s-test-2022.04.104索引中的日志,具体怎么看,需要通过选择器配置,先把prod环境交付后,再看
点击Discover,能看到k8s-test-2022.04.104索引中的日志,具体怎么看,需要通过选择器配置,先把prod环境交付后,再看

八、交付prod环境日志到 ELK
8.1、启动prod环境下的apollo、生产者
在prod命名空间下,先启动apollo.configservice让Eureka启动、在启动apollo.adminservice,在启动apollo-portal,查看test环境(FAT)下,apollo之前交付的参数是不是正常。在启动dubbo-demo-service让生产者去连接apollo,最后在交付tomcat形式消费者。
查看condig-prod.od.com中是否apollo.configservice、apollo.adminservice已经注册进来
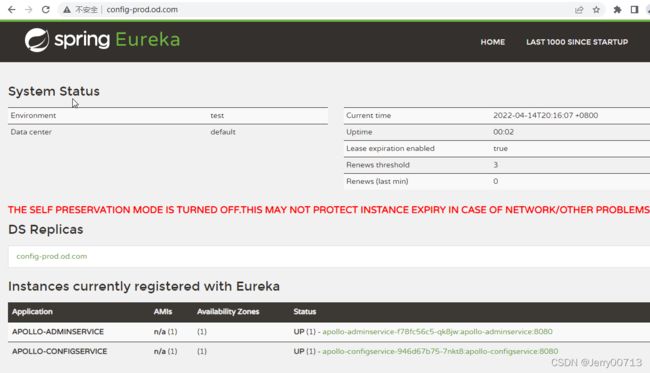
查看protal.od.com中,prod环境是不是已经加载进来
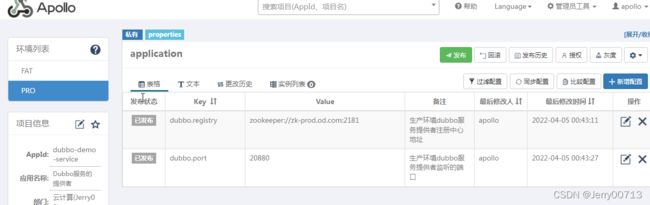
查看dubbo-demo-service日志是否正常
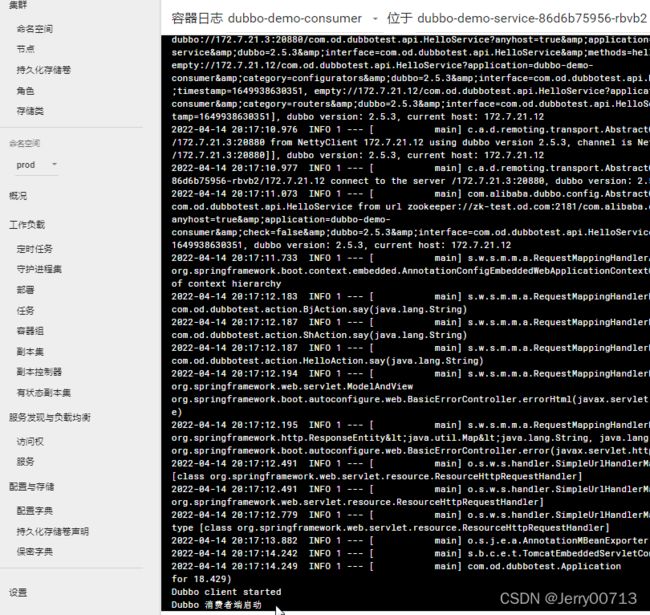
8.2、配置消费者资源配置清单
[root@hdss7-200 ~]# mkdir -p /data/k8s-yaml/prod/dubbo-demo-web-tomcat;cd /data/k8s-yaml/prod/dubbo-demo-web-tomcat
[root@hdss7-200 dubbo-demo-web-tomcat ]# vi dp.yaml
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: dubbo-demo-web-tomcat
namespace: prod
labels:
name: dubbo-demo-web-tomcat
spec:
replicas: 1
selector:
matchLabels:
name: dubbo-demo-web-tomcat
template:
metadata:
labels:
app: dubbo-demo-web-tomcat
name: dubbo-demo-web-tomcat
spec:
containers:
- name: dubbo-demo-web-tomcat
image: harbor.od.com:180/app/dubbo-demo-web-tomcat:tomcat_210310_0900
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
protocol: TCP
env:
- name: C_OPTS
value: -Denv=pro -Dapollo.meta=http://config-prod.od.com
volumeMounts:
- mountPath: /opt/tomcat/logs
name: logm
- name: filebeat
image: harbor.od.com:180/infra/filebeat:v7.5.1
imagePullPolicy: IfNotPresent
env:
- name: ENV
value: prod
- name: PROJ_NAME
value: dubbo-demo-web
- name: KAFKA_ADDR
value: '"10.4.7.11:9092"'
volumeMounts:
- mountPath: /logm
name: logm
volumes:
- emptyDir: {}
name: logm
imagePullSecrets:
- name: harbor
restartPolicy: Always
terminationGracePeriodSeconds: 30
securityContext:
runAsUser: 0
schedulerName: default-scheduler
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
revisionHistoryLimit: 7
progressDeadlineSeconds: 600[root@hdss7-200 dubbo-demo-web-tomcat ]# vim svc.yaml
kind: Service
apiVersion: v1
metadata:
name: dubbo-demo-web-tomcat
namespace: prod
spec:
ports:
- protocol: TCP
port: 8080
targetPort: 8080
selector:
app: dubbo-demo-web-tomcat[root@hdss7-200 dubbo-demo-web-tomcat ]# vim ingress.yaml
kind: Ingress
apiVersion: extensions/v1beta1
metadata:
name: dubbo-demo-web-tomcat
namespace: prod
spec:
rules:
- host: demo-prod.od.com
http:
paths:
- path: /
backend:
serviceName: dubbo-demo-web-tomcat
servicePort: 80808.3、应用资源配置清单
应用prod环境下的Dubbo消费者dubbo-demo-web-tomcat资源配置清单
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/prod/dubbo-demo-web-tomcat/dp.yaml
deployment.extensions/dubbo-demo-web-tomcat created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/prod/dubbo-demo-web-tomcat/svc.yaml
service/dubbo-demo-web-tomcat created
[root@hdss7-21 ~]# kubectl apply -f http://k8s-yaml.od.com/prod/dubbo-demo-web-tomcat/ingress.yaml
ingress.extensions/dubbo-demo-web-tomcat created
查看生产环境下http://demo-prod.od.com/hello?name=tomcat有无问题
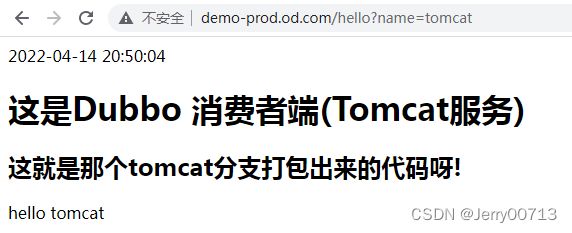
8.4、启动prod环境的logstash
由于在第五步部署filebeat的时候,已经编写了/etc/logstash/logstash-prod.conf,所以直接调用
[root@hdss7-200 ~]# docker run -d --name logstash-prod -v /etc/logstash:/etc/logstash harbor.od.com:180/infra/logstash:v6.8.6 -f /etc/logstash/logstash-prod.conf
- run -d 后台运行
- --name 起一个名字 logstash-prod
- -v 数据卷映射, 宿主机/etc/logstash目录映射docker中/etc/logstash
- -f /etc/logstash/logstash-prod.conf 指定配置
[root@hdss7-200 ~]# docker ps -a |grep logstash
1a7303534950 harbor.od.com:180/infra/logstash:v6.8.6 "/usr/local/bin/dock…" 3 minutes ago Up 3 minutes 5044/tcp, 9600/tcp logstash-prod
bb38cecdd3d5 harbor.od.com:180/infra/logstash:v6.8.6 "/usr/local/bin/dock…" 2 hours ago Up 2 hours 5044/tcp, 9600/tcp logstash-test
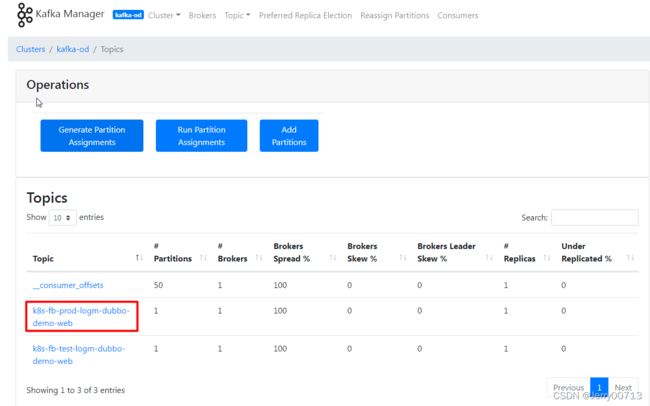
[root@hdss7-200 ~]# curl http://10.4.7.12:9200/_cat/indices?v # 查看ES是不是有k8s-prod日志
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .monitoring-kibana-6-2022.04.14 thmPVE0XTXKE5t_TwjEHZQ 1 0 678 0 206.8kb 206.8kb
green open k8s-prod-2022.04.104 eqFF_aj_RrCXG51fk0Kgmw 5 0 1 0 13.6kb 13.6kb
green open k8s-test-2022.04.104 dqptlV98RDu0PwaUReIstw 5 0 257 0 439.1kb 439.1kb
green open .monitoring-es-6-2022.04.14 vVzmBQy2Qh6WYcnT7E2C7w 1 0 6192 106 3.3mb 3.3mb
green open .kibana_task_manager BugSKm4SQa-BrP1NMjLRVQ 1 0 2 0 12.5kb 12.5kb
green open .kibana_1 ggB7DryxQ_O55IWVn6gakA 1 0 5 0 22.3kb 22.3kb
[root@hdss7-200 dubbo-demo-web-tomcat]#
8.5、kibana中配置prod环境的日志
点击左侧management(创建不同环境的索引)

点击index Patterns

点击Create index pattern
在index Patterns中,输入k8s-prod-*,然后会显示检索到k8s-prod-2022.04.104,但注意不是让你选择k8s-prod-2022.04.104,就写k8s-prod-*,因为以后索引会更新,比如是k8s-prod-2022.05.123,一样能够匹配到,然后点击next

Time Filter field name 中填写默认时间戳(@timestamp),点击Create index pattern
九、使用Kibana
Kibana主要是给测试、开发使用的
1、讲解四种选择器
1.1、时间选择器
点击Discover,右上角为显示多久的日志 ,为时间选择器

1、点击上图Last 15 minutes,其中Quick为快速选择
2、Relative 相对时间,就是从那个时间点后多少分钟到那个时间点结束
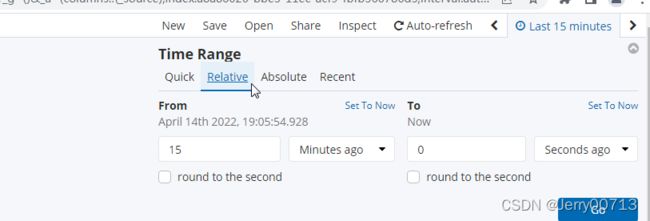
3、Absolute 绝对时间,就是何年何月什么时间,到何年何月什么时间

4、最近时间
一般最常使用的是Today,必须选择一个时间后才会显示数据
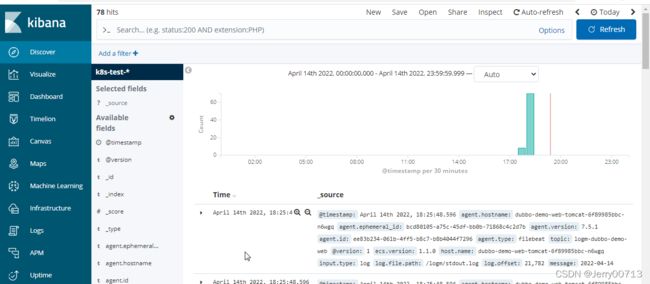
1.2、环境选择器
针对创建的index进行选择(测试、生产等等)
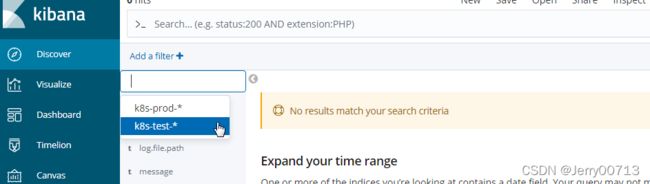
1.3、项目选择器
点击Add a filter
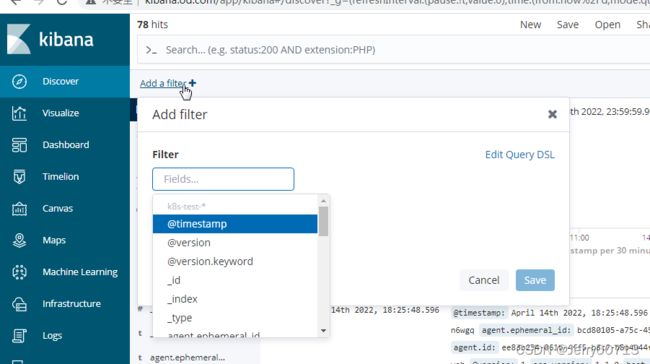
点击topic
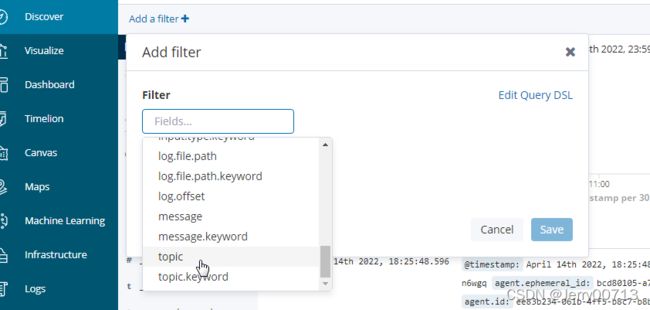

在topic里输入dubbo-demo-web,点击save,就能显示出都是dubbo消费者项目的日志
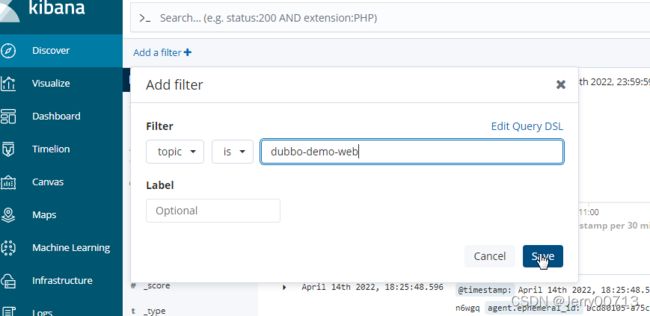
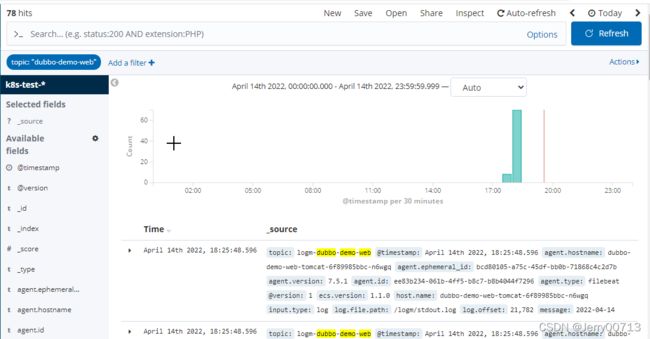
讲解:这里的topic就是kafka的topic,区分项目的,也就是说你在消费者的deployment资源清单下,定义filbeat容器的时候,给filbeat容器传递了一个环境变量(PROJ_NAME=dubbo-demo-web),然后这个变量被filbeat容器中docker-entrypoint.sh脚本中的PROJ_NAME所引用,脚本中说给filebeat获取的日志打一个标签(topic: logm-${PROJ_NAME}),也就是从此filebeat发出的日志都带logm-dubbo-demo-web标签,而这个标签其实在kafka中根本没用,kafka不识别你这个标签,那filebeat发出把日志发到kafka那个项目中呢?从(output.kafka: topic: k8s-fb-$ENV-%{[topic]})得知,$ENV就是你定义的环境变量test,%{[topic]}就是取topic变量的数值,也就是logm-dubbo-demo-web,所以它输出到kafka的k8s-fb-test-logm-dubbo-demo-web这个项目。而logstash按照自己的配置,获取(k8s-fb-test-)日志,也就是从kafka拿到(fb-test-logm-dubbo-demo-web)这个项目日志后,原封不动的输出给ES,给ES那个项目呢?从logstash配置中(output index => "k8s-test-%{+YYYY.MM.DD}")给ES的k8s-test-2019.12.12这个项目,然后Kibana引用ES的的符合k8s-test-*所有项目,因为考虑到项目是按年、月、日等更新,目前只有k8s-test-2019.12.12这个项目,明天就有k8s-test-2019.12.13这个项目。然后Kibana通过检索日志中的标签(topic: logm-${PROJ_NAME}),进而获得这个是那个消费者的项目日志,所以标签是Kibana或者ES用



1.4、关键字选择器
可以检索出日志的关键字,比如搜索OK、Exited、Error等等,为了实验我们在测试环境下,制造dubbo-demo-web-tomcat消费者故障,来查看日志
选中测试环境,topic选择topic is dubbo-demo-web(dubbo-demo-web-tomcat消费者项目)

把测试环境,dubbo-demo-service生产者项目缩容成0,消费者就会报错
多访问http://demo-test.od.com/hello?name=tomcat后,刷新页面,这样就会报错,日志就会被记录
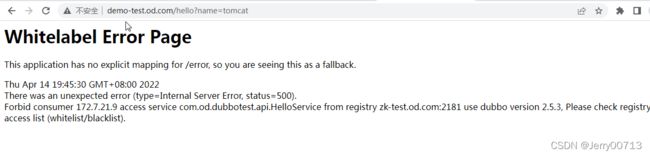
在Kibana中把时间选择Last 15 minutes
在Kibana中选择刷新
 在Kibana中点击message后的add ,把message(消息)放入最上面。第一个是time时间戳,第二个我们设置成message请求消息。
在Kibana中点击message后的add ,把message(消息)放入最上面。第一个是time时间戳,第二个我们设置成message请求消息。
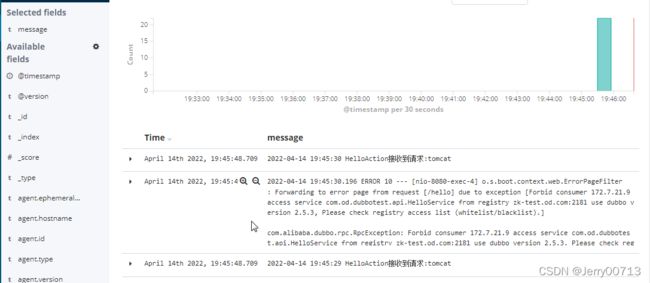
在Kibana中点击log.file.path后的add (log.file.path日志来源)
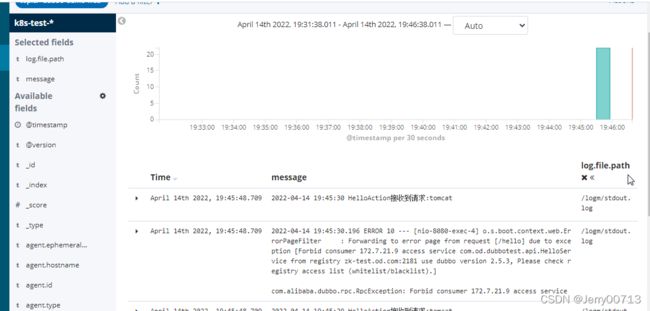
在Kibana中点击host.name后的add (显示容器的名字)
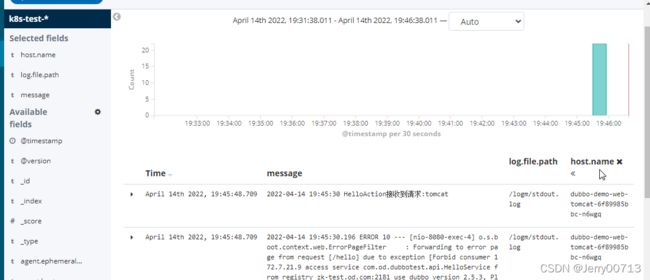
在Kibana中关键字搜索exception,在选择update

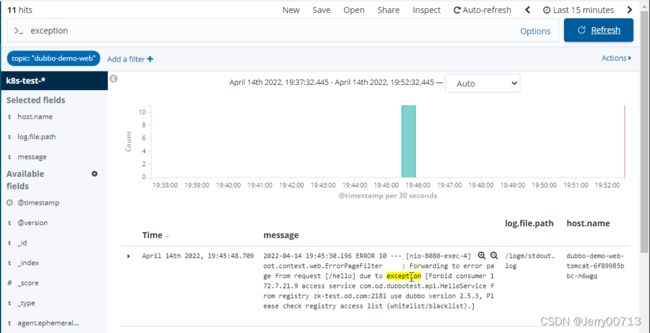
要看具体的,点击展开

这么多,是因为在filebeat做了多行匹配
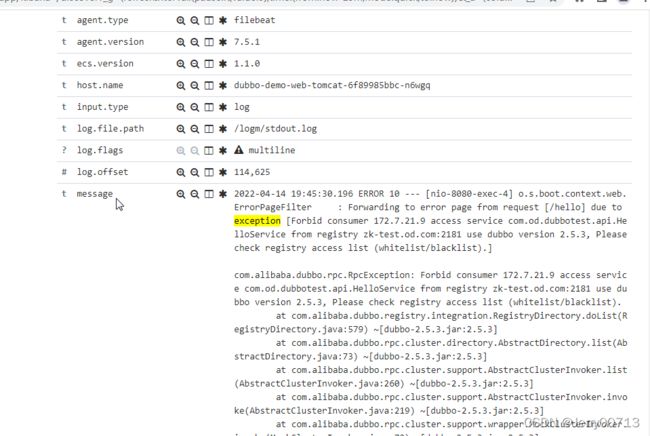
2、kibana可监控同资源所有POD
test环境下dubbo-demo-service恢复正常(扩容成1),test环境下dubbo-demo-web-tomcat(扩容成2)
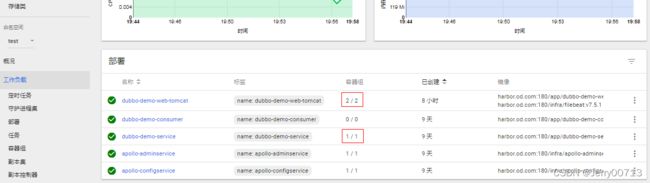
多访问刷新http://demo-test.od.com/hello?name=Jerry00713页面后,产生多日志
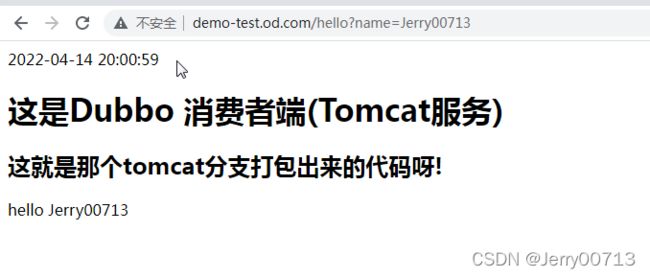
在Kibana中关键字搜索Jerry00713回车,在选择update,会发现把两方pod日志统统存入ES

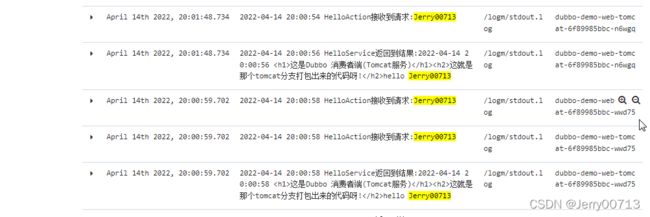
在Kibana中关键字搜索localhost,在选择update会显示localhost日志


十、如何收dubbo生产者日志
因为dubbo-demo-service的日志没有落盘,exec -jar 后日志在控制台输出没落盘
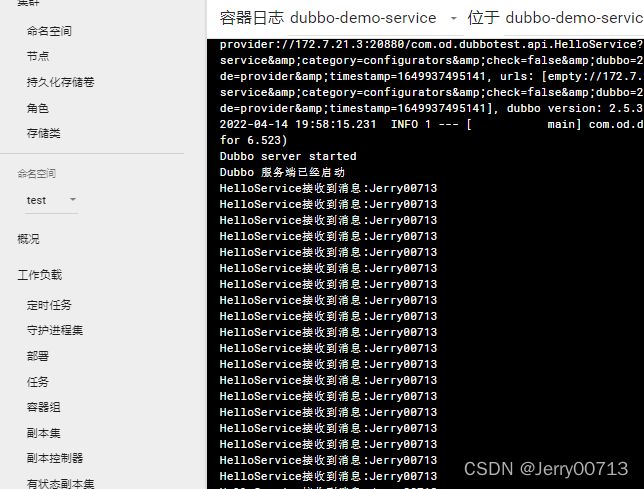
修改entrypoint.sh , 控制台输出2 >&1 >>一个文件
[root@hdss7-200 ~]# vi /data/dockerfile/jre8/entrypoint.sh
#!/bin/sh M_OPTS="-Duser.timezone=Asia/Shanghai -javaagent:/opt/prom/jmx_javaagent-0.3.1.jar=$(hostname -i):${M_PORT:-"12346"}:/opt/prom/config.yml" C_OPTS=${C_OPTS} JAR_BALL=${JAR_BALL} exec java -jar ${M_OPTS} ${C_OPTS} ${JAR_BALL} 2>&1 >>/opt/logs/stdout.log

然后重新build
[root@hdss7-200 jre8]# docker build . -t harbor.od.com:180/base/jre8:8u112_with_logs
[root@hdss7-200 jre8]# docker login harbor.od.com:180
[root@hdss7-200 jre8]# docker push harbor.od.com:180/base/jre8:8u112_with_logs
修改jenkins,使其增加底包
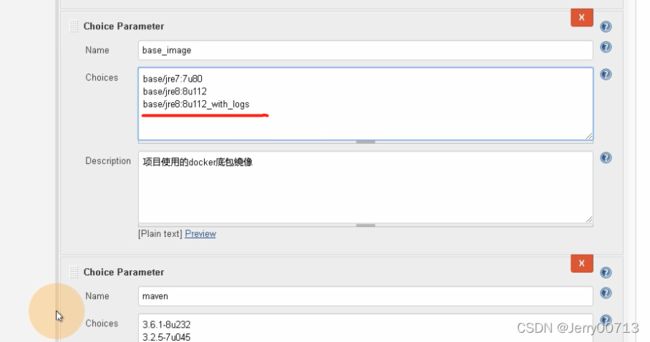
然后在拿jenkins重新build一版dubbo-demo-service,修改资源清单,挂载出/opt/logs,并边车filebeat,其中filebeat.yaml匹配规则改成一行一行收,应用清单后就可以收集