Rust实战系列-Rust介绍

“
学习资料:rust in action[1]
1. Rust 安装
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
source"$HOME/.cargo/env"
2. hello world
- 创建 hello 项目
mkdir rust_tmp && cd rust_tmp
cargo new hello
cd hello
cargo run

看到这样的输出,就表示已经成功运行了 Rust 项目,尽管还没写任何代码。接下来看看发生了什么。
- Cargo
Cargo 是一个同时提供项目构建和软件包管理功能的工具。也就是说,Cargo 执行 rustc(Rust 编译器)将 Rust 代码转换为可执行的二进制文件或共享库。cargo new会创建一个遵循标准模板的项目,目录结构如下:

Cargo.toml:描述项目的元数据信息(项目名,版本,依赖)
[package]
name = "hello"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[dependencies]
src:源码目录,Rust 的源码文件扩展名为 .rs
创建好项目后,运行 cargon run 命令启动项目,这个过程完成了很多工作。
当敲下 cargon run 命令准备 run 项目时,实际上并没有可以 run 的内容,因此,cargon 会以 debug 模式编译项目,编译生成的可执行文件位于:target/debug/hello,然后执行这个文件,输出我们看到的内容:“Hello, world!”。
编译之后,项目的目录结构发生了变化,在根目录多了 Cargo.lock 文件和 target 目录,它们都是通过 cargon 进行管理的,不需要人工修改。
“
Cargo.lock 指定了所有依赖项的确切版本号,这样,在 Cargo.toml 被修改之前,项目编译过程都会以相同的方式进行。
3. 第一个 Rust 项目
目标:输出不同语言的 hello world,理解 Rust 的两个特性:易于迭代和原生支持 Unicode。
直接修改 hello 项目中 src/main.rs 的内容:
fn main() {
println!("Hello, world!");
let southern_germany = "Grüß Gott!";
let japan = "ハロー・ワールド";
let china = "你好,世界!";
let regions = [southern_germany, japan, china];
for region in regions.iter() {
println!("{}", ®ion);
}
}
-
感叹号表示引用了一个宏
-
Rust 中的变量赋值,更恰当的称呼是变量绑定,使用 let 关键字
-
原生支持 Unicode,不需要考虑乱码问题
-
使用方括号表示数组
-
很多数据类型可以通过 iter()返回迭代器
-
&表示取出地址的值
修改后,项目的执行结果:

4. 文本处理
接下来,通过实例了解 Rust 的文本处理能力。主要包括以下特性:
-
常见的控制流机制:包括 for 循环和 continue 关键字
-
函数语法:虽然 Rust 不是面向对象的,因为它不支持继承,但它继承了面向对象语言的这个特点
-
高级编程:函数可以同时接受和返回函数。例如,实例第 19 行包括一个闭包,也被称为匿名函数或 λ(lambda)函数
-
类型注解:虽然用得不多,但偶尔也需要这些注解提示编译器(第 28 行)
-
有条件地编译:编译项目时,不会编译第 22-24 行的内容
-
隐式返回:Rust 提供了一个 return 关键字,但它通常被省略了
fn main() { // <1>
let penguin_data = "\
common name,length (cm)
Little penguin,33
Yellow-eyed penguin,65
Fiordland penguin,60
Invalid,data
";
let records = penguin_data.lines(); // <2>
for (i, record) in records.enumerate() { // <3>
if i == 0 || record.trim().len() == 0 { // <4>
continue;
}
let fields: Vec<_> = record // <5>
.split(',') // <6>
.map(|field| field.trim()) // <7>
.collect(); // <8>
ifcfg!(debug_assertions) { // <9>
eprintln!("debug: {:?} -> {:?}",
record, fields); // <10>
}
let name = fields[0]; // <11>
ifletOk(length) = fields[1].parse::() { // <12>
println!("{}, {}cm", name, length); // <13>
}
}
}
-
可执行项目必须有一个 main 函数
-
将字符串按行拆分成切片
-
遍历每行字符串,i 是下标,record 是 item
-
跳过表头和空行
-
Vec 类型是向量的简称,向量是一种数组,在需要时可以动态扩展。下划线要求编译器推断出向量的元素类型。即变量名 fields,类型为 Vec,Vec 中元素类型 Rust 推导。
-
将 record 拆分成子字符串数组(以 逗号 为分隔符)
-
对于循环,可以使用高级函数,这里去掉空白字符。map()对 split 出来的每个子字符串应用函数 term(),field 临时变量表示每个子字符串(个人理解,不一定对)
-
Collects 迭代的结果并保存到向量 fields 中
-
这个代码块是为了调试,感叹号 ! 表示宏调用,宏类似于函数,返回代码而不是值,通常用于简化常见的模式
-
打印到标准错误输出, {:?} 语法请求这两种数据类型的默认调试格式作为输出
-
Rust 支持用整数下标对集合进行索引
-
将字符串解析为 f32(单精度浮点数)类型,parse 可以将字符串解析为任何实现了 FromStr trait 的类型(在 Rust 中,为了安全起见,不允许隐式的数据类型转换),使用 Ok()函数是为了在 if 的条件中创建 length 变量并进行赋值操作
-
打印到 stdout,{} 语法表示 Rust 应该使用用户自定义的方法来输出字符串的值,而不是用 {:?} 来显示调试结果
运行项目的输出结果:
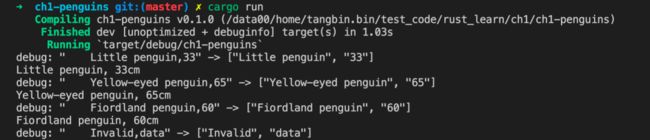
可以看到有输出以 debug 开头的行,通过 --release 参数去掉这部分调试内容。

可以通过 -q(quiet) 来进一步减少输出信息:

“
严格来说,rustc 才是 Rust 编译器,但我们并没有使用它来编译项目,cargon 代替我们调用 rustc ,简化编译过程。如果希望查看 rustc 编译过程的详细信息,使用 --verbose 或 -v 参数。(需要保证目标文件未被编译,如果已经编译则没有对应输出)
rustc:管理 Rust 源代码的编译
rustup:管理 Rust 的安装
5. Rust 的目标:安全
“
we need a safer systems programming language[2]
Rust 不受以下情况的影响:
-
空悬指针(dangling pointers):对程序运行过程中变得无效的数据进行实时引用(指针被释放后,仍然引用原来的内存)
-
数据竞争(data race):由于外部环境的变化,无法确定程序在运行过程中的行为(非线程安全的情况下,多线程对同一个地址空间进行写操作)
-
缓存溢出(Buffer overflow):试图访问一个只有 6 个元素数组的第 12 个元素
-
迭代器失效(Iterator invalidation):已经迭代的内容被中途修改后导致的问题(python 中遇到过这种问题)
当程序在调试模式下被编译时,Rust 也会对整数溢出进行保护。
“
什么是整数溢出:整数只能代表有限的一组数字;这些数字在内存中占用固定的长度。整数溢出是指当整数达到其极限时发生的情况。
- 空悬指针的示例代码
#[derive(Debug)]// <1>
enum Cereal { // <2>
Barley, Millet, Rice,
Rye, Spelt, Wheat,
}
fn main() {
letmut grains: Vec = vec![]; // <3>
grains.push(Cereal::Rye); // <4>
drop(grains); // <5>
println!("{:?}", grains); // <6>
}
-
允许 println! 打印 Cereal 枚举
-
枚举是一种有固定数量有效值的类型
-
初始化空的向量(数组)grains
-
向 grains 添加元素
-
删除向量 grains 和其中的内容
-
尝试访问被删除的值
代码中,Vec是用一个指向底层数组的内部指针实现的,尝试编译项目会出错:
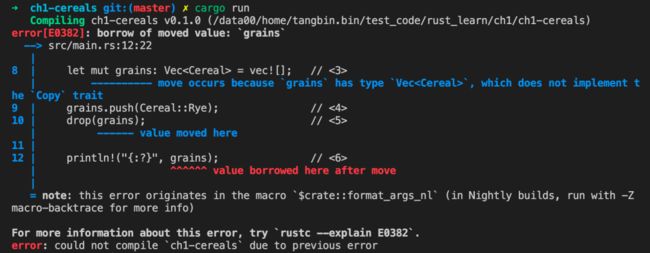
- 数据竞争的示例代码
use std::thread; // <1>
fn main() {
letmut data = 100;
thread::spawn(|| { data = 500; }); // <2>
thread::spawn(|| { data = 1000; }); // <2>
println!("{}", data);
}
-
导入 thread 标准库
-
thread::spawn() 产生一个新的线程,thread::spawn()的闭合由竖条和大括号表示(例如,|| {…})
使用 cargo 编译不会通过。
- 缓存溢出的示例代码
fn main() {
let fruit = vec!['', '', ''];
let buffer_overflow = fruit[4]; // <1>
assert_eq!(buffer_overflow, '') // <2>
}
-
这行代码会出现 panic
-
assert_eq!() 的两边必须相等,否则程序 panic
使用 cargo 编译不会通过。
- 迭代器失效的示例代码
fn main() {
letmut letters = vec![ // <1>
"a", "b", "c"
];
for letter in letters {
println!("{}", letter);
letters.push(letter.clone()); // <2>
}
}
-
初始化一个向量并允许修改(mut)
-
创建 letter 的副本并追加到 letters 的末尾
使用 cargo 编译不会通过。
6. Rust 的目标:生产力
在有选择的情况下,Rust 更倾向于选择对开发者来说最容易的选项。例如,在一个应该使用等于判断(==)的表达式中使用赋值(=)符号。
fn main() {
let a = 10;
if a = 10 {
println!("a equals ten");
}
}
这段代码是不能编译通过(C 语言没有这种能力)的,Rust 编译器会生成错误:

if 接收的不是一个整数,它接收的是一个赋值的结果。在 Rust 中,这是一个空白类型:()
Rust 提供了许多人性化的特点,包括泛型、复杂数据类型、模式匹配和闭包。
cargo 为 Rust 程序员提供了这些命令:
-
cargo init:创建一个 Rust 项目框架
-
cargo build:下载依赖项并编译代码
-
cargo run:功能与 cargo build 相同,编译好之后会运行生成的可执行文件
-
cargo doc:为当前项目中的每个依赖关系建立 HTML 文档
7. Rust 的目标:资源控制
从代码层面提升性能时,对内存访问、内存布局和特定 CPU 指令的控制都非常重要。
-
有时,必须要管理某些操作的方式
-
有时,数据存储在栈中而不是堆上可能很重要
-
有时,为一个共享值添加引用计数可能很有意义
-
通常,将引用传递给函数是有意义的
-
偶尔,为一个特定的访问模式创建一个自己的指针类型可能很有用
对于大多数情况,Rust 使用了合理的默认值,与它的 “零成本抽象”理念一致。
以下代码描述了多种创建整数值的方式,每种形式都提供了不同的语义和运行时特性:
use std::rc::Rc;
use std::sync::{Arc, Mutex};
fn main() {
let a = 10; // <1>
let b = Box::new(20); // <2>
let c = Rc::new(Box::new(30)); // <3>
let d = Arc::new(Mutex::new(40)); // <4>
println!("a: {:?}, b: {:?}, c: {:?}, d: {:?}", a, b, c, d);
}
-
存储在栈中
-
存储在堆中,也叫 boxed integer
-
boxed integer 被包裹在引用计数器中
-
整数被包裹在原子引用计数器中,并受到互斥锁的保护
8. Rust 的特征:性能
Rust 充分发挥计算机的可用性能,Rust 不依赖 GC(垃圾收集器)来保证内存安全。
硬件 CPU 的性能是固定的,因此,为了使软件的运行速度更快,需要减少 CPU 完成的工作,在 Rust 中,这个过程由编译器完成,尽可能减小程序的大小和运行速度。
-
默认提供有利于缓存的数据结构:通常,在 Rust 程序中使用数组保存数据,而不是由指针创建的深度嵌套树结构。这被称为面向数据编程。
-
先进的软件包管理器:cargo 的出现使我们很容易构建有许多依赖关系的大型项目。
-
函数静态调度:除非明确要求动态调度,函数默认静态调度,这使得编译器可以大量优化代码,有时甚至可以完全消除函数调用带来的开销。
9. Rust 的特征:并发
事实证明,要求计算机同时完成多件事情对软件工程师来说是很困难的。从操作系统层面考虑,如果程序员在并发访问的时候出现错误,会导致两个独立执行的线程可以任意破坏对方线程。Rust 对安全的强调跨越了独立线程的界限,允许程序员可以随意使用并发编程特性。
10. Rust 的特征:内存效率
Rust 使你能够创建需要最小内存的程序。如果需要,程序员可以使用固定大小的结构,并清楚地知道每个 byte 是如何被管理的。使用高级数据结构,如迭代和泛型,只会产生最小的运行开销。
11. Rust 的不足
- 循环数据结构
在 Rust 中很难对任意图结构这样的循环数据进行建模,实现一个双向链表是本科计算机科学水平的问题,但 Rust 的安全检查使得其很难实现。
- 编译时间
Rust 在编译代码时比它的同类语言要慢。它有一个复杂的编译器工具链,它接收多个中间表示,并向 LLVM 编译器发送大量代码。Rust 程序的“编译单元”不是一个单独的文件,而是一个完整的包。由于包可以包含多个模块,这些模块可以是非常大的编译单元。
- 严格性
在使用 Rust 编程时,除非一切都是正确的,否则程序不会编译。编译器是严格的,但很有帮助。
- 语言的尺寸
Rust 有一个复杂的类型系统,可以通过多种方式访问值,还有一个与强制转换对象生命期相匹配的权限系统。对于这些访问方式,程序员有选择负担。
- 炒作
用 Rust 编写的软件也不能完全避免安全问题。2015 年,随着 Rust 知名度的提高,SSL/TLS 的实现(即 OpenSSL 和苹果自己的 fork)被发现有严重的安全漏洞。这两个漏洞被非正式地称为 "Heartbleed “和 “goto fail”,为测试 Rust 声称的内存安全提供了机会。在这两个案例中,Rust 很可能起到了帮助作用,但仍然有可能写出存在类似问题的 Rust 代码。”
Heartbleed 是由于不正确地重复使用缓冲区造成的。缓冲区是内存中预留的用于接收输入数据的空间。如果缓冲区的内容在两次写入之间没有被清擦除,那么数据就会从前一次读取泄漏到下一次。如果缓冲区存储的是密钥等信息,将会对安全性造成严重破坏。
为什么会出现这种情况呢?为了追求性能,程序通常会重复使用缓冲区,从而减少向操作系统申请内存的频率。以下是示例代码:
let buffer = &mut[0u8; 1024]; // <1>
read_secrets(&user1, buffer); // <2>
store_secrets(buffer);
read_secrets(&user2, buffer); // <3>
store_secrets(buffer);
-
将一个引用(&)与一个包含 1024 个初始化为 0 的无符号 8 位整数(u8)的可变(mut)数组([…])绑定到变量缓冲区
-
用 user1 对象的字节来填充缓冲区
-
此时,buffer 仍然包含来自 user1 的数据,这些数据可能被 user2 覆盖,也可能不被覆盖
goto fail 是由程序员错误使用 C 语言设计造成的问题(C 编译器没有检查出这个缺陷)造成的。被设计用来验证加密密钥对的函数最终跳过了所有检查。以下是该函数的部分内容:
static OSStatus
// line break OK below? original exceeded 76 char limit
SSLVerifySignedServerKeyExchange(SSLContext *ctx, bool isRsa,
SSLBuffer signedParams,
uint8_t *signature, UInt16 signatureLen)
{
OSStatus err;
...
// need line break below at 55 char max (because line contains annotation)
if ((err = SSLHashSHA1.update(&hashCtx, &serverRandom)) != 0)
goto fail;
if ((err = SSLHashSHA1.update(&hashCtx, &signedParams)) != 0) // <1>
goto fail;
goto fail; // <2>
if ((err = SSLHashSHA1.final(&hashCtx, &hashOut)) != 0)
goto fail;
err = sslRawVerify(ctx,
ctx->peerPubKey,
dataToSign, /* plaintext \*/
dataToSignLen, /* plaintext length \*/
signature,
signatureLen);
if(err) {
sslErrorLog("SSLDecodeSignedServerKeyExchange: sslRawVerify "
"returned %d\n", (int)err);
goto fail;
}
fail:
SSLFreeBuffer(&signedHashes);
SSLFreeBuffer(&hashCtx);
return err; // <4>
}
-
第一个 goto 在 if 判断为 true 时执行
-
当第一个 goto 判断为 false 时,err 的值为 0,此时会执行第二个 goto 语句,从而跳过 SSLHashSHA1.final() 和对 sslRawVerify() 的调用(重要)
-
返回值为 0,通过验证(实际上没有执行 SSLHashSHA1.final() 和 sslRawVerify())
12. 应用场景
- 命令行程序
Rust 为创建命令行程序提供了三个主要优势:最小的启动时间、低内存消耗和容易部署。由于 Rust 不需要初始化解释器(Python, Ruby, …)或虚拟机(Java, C#, …),程序可以快速开始运行。
在 Rust 中,许多类型只作为编译器的提示而存在,在运行的程序中根本不占用内存。
用 Rust 编写的程序默认是作为静态二进制文件编译,避免了对共享库的依赖。
- 数据处理
由于对内存使用的控制和极短的启动时间,Rust 擅长处理文本和其他形式的数据内容。Rust 也是多个搜索引擎、数据处理引擎和日志解析系统的实现基础,提供了创建高吞吐量的数据管道的能力,而且内存占用率低且稳定。
- 扩展应用
Rust 非常适合扩展用动态语言编写的程序。这使得 JNI(Java Native Interface)扩展、C 扩展或 Rust 中的 Erlang/Elixir NIFs(本地实现的函数)成为可能。
- 资源受限的环境
物联网(IoT)时代的到来意味着数十亿不安全的设备暴露在网络中。通常情况下,物联网设备的固件更新频率很低,因此,从一开始就尽可能地保证这些设备的安全是至关重要的,Rust 可以发挥重要作用。
- 服务器端的应用
大多数用 Rust 编写的应用程序运行在服务器上,通常位于操作系统和应用程序之间。例如:npm 包注册表,sled(嵌入式数据库)
- 面向用户的软件
Rust 的设计中没有任何阻止其被部署到面向用户软件开发中内容。Servo,作为 Rust 早期开发的网络浏览器引擎,就是一个面向用户的应用程序。
- 桌面应用程序
桌面应用程序通常很复杂,难以设计,也难以支持。由于 Rust 的部署方式符合人机工程学原理,而且很严谨,很可能成为许多应用程序的选择。
- 移动端软件
Android 和 IOS 都提供了让 "本地应用程序"在系统上运行的能力,这是为了让用 C++编写的应用程序,如游戏,能够被部署到手机上。Rust 能够通过相同的接口与手机交互,没有额外的时间开销。
- web 网站
浏览器供应商正在开发一种叫做 WebAssembly(Wasm)的标准,有望成为许多语言的编译器目标,Rust 就是其中一个。将一个 Rust 项目移植到浏览器上只需要两个额外的命令行命令。
- 系统编程
许多大型程序都是用 Rust 实现的,包括编译器(Rust 本身)、视频游戏引擎和操作系统。Rust 社区包括解析器生成器、数据库和文件格式的开发者。
参考资料
[1] rust in action: https://livebook.manning.com/book/rust-in-action
[2] we need a safer systems programming language: https://msrc-blog.microsoft.com/2019/07/18/we-need-a-safer-systems-programming-language/
